reducción de la dimensionalidad de las características
1. Introducción
La reducción de la dimensionalidad de las características se refiere al proceso de asignación de datos de alta dimensión a un subespacio de baja dimensión mediante la reducción de las dimensiones en el espacio de características .
En el aprendizaje automático y el análisis de datos, la reducción de la dimensionalidad de las características puede ayudar a reducir la complejidad de los datos, reducir los costos computacionales, mejorar el rendimiento y la interpretabilidad del modelo y resolver problemas como la maldición de la dimensionalidad. La reducción de la dimensionalidad de las características generalmente se divide en dos enfoques principales: selección de características y extracción de características.
- Selección de funciones : la selección de funciones se refiere a seleccionar un subconjunto de las funciones más representativas e importantes de las funciones originales, mientras se ignoran otras funciones. Esto reduce el número de características y, por lo tanto, la dimensionalidad. Los métodos de selección de funciones pueden evaluar la importancia de las funciones en función de indicadores como pruebas estadísticas, ganancia de información y ponderaciones de modelos, y luego seleccionar las funciones mejor clasificadas.
- Extracción de características : la extracción de características consiste en asignar las características originales a un nuevo subespacio de baja dimensión a través de la transformación matemática, preservando así la información clave en los datos. Los métodos comunes de extracción de características incluyen análisis de componentes principales (PCA), análisis discriminante lineal (LDA), análisis de componentes independientes (ICA), etc. Estos métodos convierten datos de alta dimensión en representaciones de baja dimensión a través de mapeo lineal o no lineal, lo que hace que las nuevas características sean más expresivas.
Las ventajas de la reducción de la dimensionalidad de las características incluyen:
- Reducir el desastre de la dimensionalidad : El desastre de la dimensionalidad se refiere a problemas como el aumento de la escasez de datos y la falla de la medición de distancia en un espacio de alta dimensión. La reducción de la dimensionalidad de las características puede aliviar estos problemas, haciendo que los datos sean más fáciles de procesar y analizar.
- Reducir el costo computacional : el costo computacional de los datos de alta dimensión es alto, y la reducción de la dimensionalidad de las características puede reducir la complejidad computacional y mejorar la eficiencia del algoritmo.
- Mejorar el rendimiento del modelo : en algunos casos, la reducción de la dimensionalidad de las características puede mejorar el rendimiento del modelo, reducir el sobreajuste y mejorar la generalización.
- Visualización e interpretabilidad : el mapeo de datos en un espacio de baja dimensión permite una visualización e interpretación más sencillas, lo que ayuda a comprender patrones y relaciones en los datos.
La elección de la reducción de la dimensionalidad de las características depende de la naturaleza de los datos, las necesidades del problema y los requisitos del modelo. Los diferentes métodos de reducción de dimensionalidad son adecuados para diferentes situaciones y deben seleccionarse y aplicarse de acuerdo con problemas específicos.
2. Reducción de dimensionalidad
La reducción de dimensionalidad se refiere al proceso de reducir el número de variables aleatorias (características) bajo ciertas condiciones limitadas para obtener un conjunto de variables principales "no correlacionadas".
Reducir el número de variables aleatorias:

Característica correlacionada: correlación entre la humedad relativa y la precipitación
Es precisamente porque cuando entrenamos, todos usamos funciones para aprender. Si hay un problema con la función en sí o si la correlación entre las funciones es fuerte, tendrá un mayor impacto en la predicción de aprendizaje del algoritmo.
Dos formas de reducción de dimensionalidad: selección de características y análisis de componentes principales (se puede entender una forma de extracción de características)
3. Selección de características
3.1 Breve introducción
Definición: Los datos contienen variables redundantes o irrelevantes (o características, atributos, indicadores, etc.), con el objetivo de descubrir las características principales de las características originales.

La selección de características se refiere a seleccionar la parte más representativa e importante de las características del conjunto de características de los datos originales para su uso en la construcción de modelos, el análisis de datos o la resolución de problemas.
El objetivo de la selección de funciones es reducir la cantidad de funciones y, al mismo tiempo, preservar las partes más informativas de los datos, lo que reduce los costos computacionales, mejora el rendimiento del modelo, acelera el proceso de capacitación y mejora la interpretabilidad del modelo.
Las principales motivaciones para la selección de características son:
- Reducción de la dimensionalidad : la cantidad de características en un conjunto de datos de alta dimensión puede ser muy grande, lo que da como resultado una mayor sobrecarga de computación y almacenamiento y una menor eficiencia del algoritmo.
- Reducir el sobreajuste : demasiadas características pueden dar lugar a modelos demasiado complejos que tienden a funcionar bien en el conjunto de entrenamiento pero funcionan mal en los datos nuevos (sobreajuste).
- Mejorar el rendimiento del modelo : es posible que algunas funciones no contribuyan al rendimiento del modelo e incluso pueden generar ruido. Al seleccionar características importantes, se puede mejorar el rendimiento del modelo.
- Interpretabilidad mejorada : el uso de menos características hace que el modelo sea más fácil de entender e interpretar.
Los métodos de selección de funciones se pueden dividir en tres categorías principales:
- Métodos de filtro : al evaluar y clasificar las características antes de la selección de características, se seleccionan las características que están altamente correlacionadas con la variable de destino. Los métodos de filtrado comúnmente utilizados incluyen selección de varianza, coeficiente de correlación, información mutua, etc.
- Métodos de envoltorio : trate la selección de características como un problema de optimización y seleccione características en función del rendimiento del modelo. Los métodos comunes de empaquetado incluyen la eliminación recursiva de características (RFE) y la selección directa (selección directa).
- Métodos integrados : la selección de funciones se realiza durante el entrenamiento del modelo y las funciones se seleccionan optimizando el rendimiento del modelo. Por ejemplo, los árboles de decisión y los modelos lineales regularizados pueden reducir o restringir los pesos de las características durante el entrenamiento.
La elección del método de selección de características depende de la naturaleza de los datos, las necesidades del problema y los requisitos del modelo. Diferentes métodos son adecuados para diferentes situaciones y necesitan ser seleccionados y aplicados de acuerdo a problemas específicos. La selección de características es una parte importante del preprocesamiento de datos, que puede sentar las bases para construir modelos de aprendizaje automático más precisos, eficientes e interpretables.
3.2 Dos métodos
Filtro (filtro): explora principalmente las características de la característica en sí, la relación entre las características y las características y los valores objetivo
Método de selección de varianza: Filtrado de características de baja varianza
coeficiente de correlación
Incrustado (incrustado): el algoritmo selecciona características automáticamente (asociación entre características y valores objetivo)
Árbol de decisión: entropía de información, ganancia de información
Regularización: L1, L2
Aprendizaje profundo: circunvoluciones y más
Módulos a utilizar: sklearn.feature_selection
3.3, tipo de filtro
3.3.1 Filtrado de características de baja varianza
Elimine algunas características de baja varianza, el significado de la varianza se mencionó anteriormente. Combinado con el tamaño de la varianza para considerar el ángulo de este método.
La varianza de la característica es pequeña: el valor de la mayoría de las muestras de una característica es relativamente similar
Gran variación de características: los valores de muchas muestras de una característica son diferentes
API:
sklearn.feature_selection.VarianceThreshold(umbral = 0.0)
Quitar todas las funciones de varianza baja
Varianza.fit_transform(X)
X: datos en formato de matriz numpy [n_samples, n_features]
Valor de retorno: se eliminarán las características cuya diferencia de conjunto de entrenamiento sea inferior al umbral. El valor predeterminado es mantener todas las características de varianza distintas de cero, es decir, eliminar características con el mismo valor en todas las muestras.
Práctica de casos:
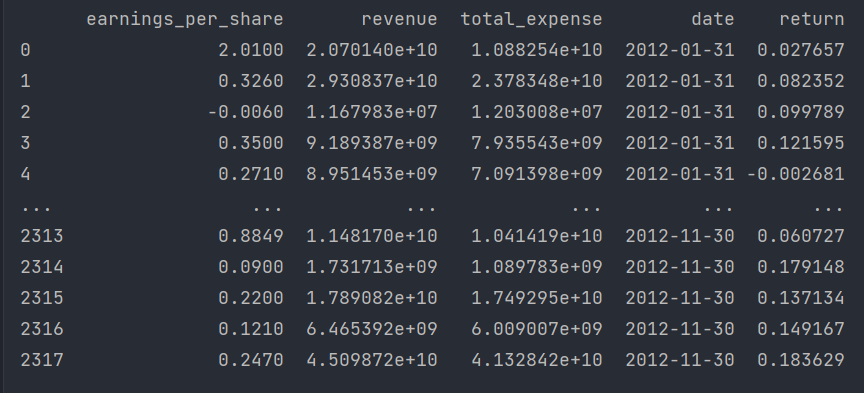
El cálculo de datos se realiza a continuación, realizamos un filtro entre las características del índice de algunas acciones y los datos requeridos se guardan en factor_returns.csvel archivo.
Las columnas 'índice', 'fecha', 'retorno' deben eliminarse (estos tipos no coinciden y no son los indicadores requeridos)

Entonces, las características requeridas son las siguientes: pe_ratio, pb_ratio, market_cap, return_on_asset_net_profit, du_return_on_equity, ev, gains_per_share, Revenue, Total_Expense
Analice de la siguiente manera:
1. Inicialice VarianceThreshold y especifique la variación del umbral
2. Llame a fit_transform
# -*- coding: utf-8 -*-
# @Author:︶ㄣ释然
# @Time: 2023/8/16 10:01
import pandas as pd
from sklearn.feature_selection import VarianceThreshold # 低方差特征过滤
'''
sklearn.feature_selection.VarianceThreshold(threshold = 0.0)
删除所有低方差特征
Variance.fit_transform(X)
X:numpy array格式的数据[n_samples,n_features]
返回值:训练集差异低于threshold的特征将被删除。默认值是保留所有非零方差特征,即删除所有样本中具有相同值的特征。
'''
def variance_demo():
"""
删除低方差特征——特征选择
:return: None
"""
data = pd.read_csv("data/factor_returns.csv")
print(data)
# 1、实例化一个转换器类
transfer = VarianceThreshold(threshold=1)
# 2、调用fit_transform
data = transfer.fit_transform(data.iloc[:, 1:10])
print("删除低方差特征的结果:\n", data)
print("形状:\n", data.shape)
if __name__ == '__main__':
# 设置 Pandas 输出选项以展示所有行和列的内容
pd.set_option('display.max_columns', None)
variance_demo()El resultado es el siguiente:



3.3.2 Coeficiente de correlación
Coeficiente de correlación de Pearson (Coeficiente de correlación de Pearson): indicador estadístico que refleja la cercanía de la correlación entre variables
El coeficiente de correlación de Pearson (Coeficiente de correlación de Pearson), también conocido como coeficiente de correlación de Pearson o coeficiente de correlación de Pearson, es una estadística utilizada para medir la fuerza y la dirección de la relación lineal entre dos variables continuas. Mide el grado de correlación lineal entre dos variables.
El valor del coeficiente de correlación está entre –1 y +1, es decir, –1≤ r ≤+1 . Sus propiedades son las siguientes:
- Cuando r>0, significa que las dos variables están correlacionadas positivamente, y cuando r<0, las dos variables están negativamente correlacionadas.
- Cuando |r|=1, significa que las dos variables están completamente correlacionadas, y cuando r=0, significa que no hay correlación entre las dos variables.
- Cuando 0<|r|<1, significa que existe cierto grado de correlación entre las dos variables. Y cuanto más cerca esté |r| de 1, más estrecha será la relación lineal entre las dos variables; cuanto más cerca esté |r| de 0, más débil será la relación lineal entre las dos variables
- Generalmente, se puede dividir en tres niveles: |r|<0.4 es correlación baja; 0.4≤|r|<0.7 es correlación significativa; 0.7≤|r|<1 es correlación lineal alta
oficial:

Los parámetros son los siguientes:
n: número de observaciones.
∑: símbolo de suma, lo que significa sumar todas las observaciones.
x e y: representan respectivamente los valores observados de las dos variables.
API:
de scipy.stats importar pearsonr
x : (N,) tipo_arreglo
y : (N,) array_like Devuelve: (coeficiente de correlación de Pearson, valor p)
Caso: Cálculo de Correlación de Índices Financieros de Acciones
Para el cálculo de correlación de estos indicadores de las acciones que acabamos de mencionar, asumiendo que usamos factor = ['pe_ratio','pb_ratio','market_cap','return_on_asset_net_profit','du_return_on_equity','ev','earnings_per_share','revenue','total_expense']dos de estas características para calcular, podemos obtener algunas características con alta correlación.
Análisis: Cálculo de correlación entre dos características
import pandas as pd
from scipy.stats import pearsonr # 皮尔逊相关系数
'''
from scipy.stats import pearsonr
x : (N,) array_like
y : (N,) array_like Returns: (Pearson’s correlation coefficient, p-value)
'''
def pearsonr_demo():
"""
相关系数计算
"""
data = pd.read_csv("data/factor_returns.csv")
factor = ['pe_ratio', 'pb_ratio', 'market_cap', 'return_on_asset_net_profit', 'du_return_on_equity', 'ev',
'earnings_per_share', 'revenue', 'total_expense']
for i in range(len(factor)):
for j in range(i, len(factor) - 1):
print("指标%s与指标%s之间的相关性大小为%f" % (factor[i], factor[j + 1], pearsonr(data[factor[i]], data[factor[j + 1]])[0]))
if __name__ == '__main__':
# 设置 Pandas 输出选项以展示所有行和列的内容
pd.set_option('display.max_columns', None)
pearsonr_demo()resultado:
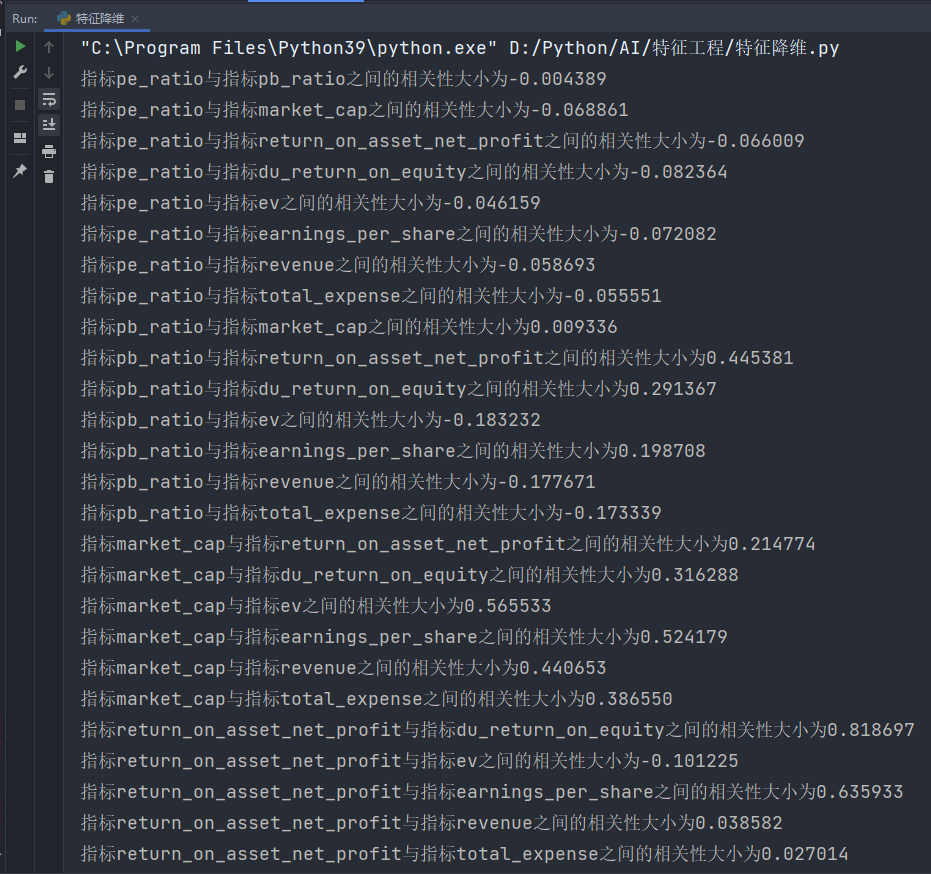
De esto se sigue que:

La correlación entre el indicador ingresos y el indicador total_gastos es 0.995845
La correlación entre el indicador return_on_asset_net_profit y el indicador du_return_on_equity es 0,818697
Dibujo:


La correlación entre estos dos pares de indicadores es relativamente grande y se puede realizar un procesamiento posterior, como sintetizar estos dos indicadores.