https://blog.csdn.net/qq_42109740/article/details/104779538 Esta publicación de blog proporciona una explicación muy fácil de entender de los principios de las normas L0, L1 y L2 y su función en el aprendizaje automático. conceptos relevantes para los blogueros Autocomprensión, creo que los lectores que hayan leído este análisis serán de gran ayuda para comprender el papel de estas normas. Antes de leer, se recomienda leer la introducción más sistemática escrita por el blogger a continuación, y luego lea mi artículo; si comprende la aplicación de normas en el aprendizaje automático, puede leer directamente mi artículo. https://blog.csdn.net/qq_42109740/article/details/104779538 Lo anterior es el enlace al texto original, este artículo se reproduce para su conveniencia
1. Pon la conclusión primero
Creo que todos ya entienden la definición de las normas L0, L1, L2 y su papel en el aprendizaje automático, específicamente:
(1) La norma L0 se refiere al número de elementos distintos de cero en el vector. Su función puede mejorar la escasez de los parámetros del modelo, pero la norma L0 es difícil de optimizar y resolver.
(2) La norma L1 se refiere a la suma de los valores absolutos de cada elemento en el vector. Su función también puede mejorar la escasez de los parámetros del modelo, el efecto no es tan bueno como la norma L0, pero es más fácil de resolver y más comúnmente utilizado.
(3) La norma L2 se refiere a la suma de los cuadrados de los elementos del vector y luego la raíz cuadrada. Su función es reducir el tamaño de todos los parámetros del modelo, lo que puede evitar que el modelo se sobreajuste y también es muy utilizado.
2. Prólogo
En primer lugar, comprendamos el concepto de escasez. La explicación simple e intuitiva es que para un conjunto de datos (que se supone que es x1, x2, x3, ..., x1000), solo hay partes de él, como ( x100, x200 ..., x1000) El tamaño de estos diez conjuntos de datos El valor más grande es 1, y los otros son 0 o cerca de 0, lo que significa que este conjunto de datos es escaso. Entonces, ¿por qué deberíamos considerar la escasez de datos? Mucha gente también puede pensar en "detección comprimida", pero citaré un ejemplo intuitivo: si hay 100 indicadores de juicio para juzgar si un paciente tiene cierta enfermedad, pero 5 de ellos son muy importantes, si el médico debe juzgar si los 100 indicadores Considerar cada uno de ellos sin duda será una gran carga de trabajo, y mucho trabajo en los otros 95 indicadores es inútil, por lo que aquí solo necesitamos considerar esos 5 indicadores, que es un procesamiento de escasez de datos. Estas normas se pueden usar. A continuación, explicaré en detalle mi comprensión de las normas L0, L1 y L2 principalmente desde el aspecto de la escasez.
3. Análisis
Considere un problema de regresión lineal de primer orden:
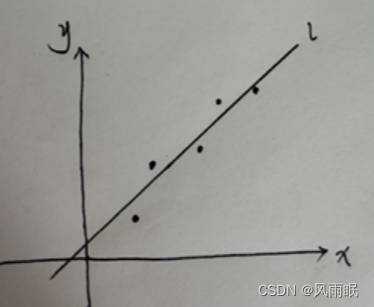
Para este tipo de problema, esperamos encontrar una ecuación de y=wx+b que se ajuste a estos puntos. El método también es muy simple. El método de los mínimos cuadrados es: min{∑(yiactual-yi)2} is min{ ∑(yi-(wxi+b))2}, para este sencillo problema se puede obtener una solución definida w0 y b0, y esto es para un parámetro w. En este momento, si la ecuación se establece como y= w1x+ w2x+b, es decir, los parámetros de w son w1 y w2. No hace falta decir que aquí habrá w0=w1+w2. ¡Es muy importante recordar esta ecuación!
En este momento, ¿qué pasa si necesito w1 y w2 para satisfacer la escasez? Es decir, lo mejor es tener uno como 0 y el otro como w0. Bien, sigamos considerando el uso de la ecuación de mínimos cuadrados para obtener los valores de w1 y w2: min{∑(yireal-(w1xi+w2xi+b))2}, de hecho, este resultado seguirá satisfaciendo w1+w2=w0 , no se puede determinar cuánto son iguales w1 y w2, y no se puede garantizar la escasez.
3.1 Norma L0:
Si agrega restricciones en este momento: min{∑(yiactual-(w1xi+w2xi+b))2+λ||w||0}, donde ||w||0 es la norma L0 de w, y λ es la restricción Coeficiente del elemento, es decir, para resolver min{∑(yiactual-(w1xi+w2xi+b))2+λ("el número de valores distintos de cero en w1 y w2")} en este momento, si desea asegúrese de que sea mínimo, necesita lo anterior Ambos términos son relativamente mínimos Para el segundo término, el mejor resultado es satisfacer uno de los parámetros w es 0, es decir, w1 o w2 es 0, y el otro parámetro es igual a w0 (en realidad, de acuerdo con la fórmula anterior, es ligeramente menor que w0. Se supone aquí y más adelante que es igual a w0, lo que no afecta el análisis). Entonces, la norma L0 logra la escasez de parámetros.
3.2 norma L1
De la misma manera, la fórmula del método de los mínimos cuadrados después de usar la norma L1 es: min{∑(yiactual-(w1xi+w2xi+b))2+λ(|w1|+|w2|)}, he aquí un imagen para entender:
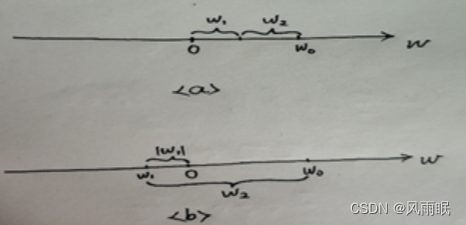
Para el caso a, es decir, tanto w1 como w2 son positivos, en este momento la fórmula anterior se convierte en: min{∑(yireal-(w1xi+w2xi+b))2+λ(w1+w2)}, ya que w0=w1+ w2, por lo que es min{∑(yiactual-(w1xi+w2xi+b))2+λw0}, donde w0 es un valor fijo, por lo que no juega un papel en la escasez de parámetros, pero para el caso b, es un Uno es positivo y el otro es negativo, lo que hace que (|w1|+|w2|) sea más grande, y para hacerlo el más pequeño, el resultado es que w1 es 0, w2=w0, por lo que también juega un papel de escasez.
3.3 norma L2
De igual manera, luego de introducir la norma L2, se obtiene la fórmula del método de los mínimos cuadrados: min{∑(yireal-(w1xi+w2xi+b))2+λ(w12+w22)1/2}, luego de convertir la fórmula en :min{∑(yireally-(w1xi+w2xi+b))2+λ((w1+w2)2-2w1w2)1/2}, trae w0=w1+w2, igual a: min{∑(yi In fact -(w1xi+w2xi+b))2+λ(w02-2w1w2)1/2}, para hacer el segundo término: λ(w02-2w1w2)1/2 el más pequeño, es necesario satisfacer el mínimo de w02-2w1w2, y también Es decir, -w1w2 es el más pequeño, sea w2=w0-w1 y obtenga -w1w2=w12-w1w0. Consulte la siguiente figura para comprender:
Se puede ver que cuando w1 es igual a w0/2, se satisface su mínimo, es decir, el mayor efecto de la norma L2 es distribuir uniformemente el valor del parámetro de w0 a w1 y w2 para hacer los parámetros más pequeños. Cuando el número de w es grande, que es equivalente a lo que dijeron otros bloggers, tiende a 0, pero no es igual a 0.
El análisis está aquí, sigamos viendo las propiedades de la norma L3, por qué solo vemos el análisis de la norma L0, 1, 2, pero no la norma L3, sigamos usando el método anterior, la fórmula de minimización es: min {∑ (yi real-(w1xi+w2xi+b))2+λ(w13+w23)1/3}, transformado en: min{∑(yi real-(w1xi+w2xi+b))2+λ(( w1+ w2)3-3w1w2(w1+w2))1/3}, para el segundo elemento: ((w0)3-3w1w2(w0))1/3, podemos continuar transformando para encontrar: -3w1w2(w0) valor mínimo, Eso es encontrar el valor mínimo de -w1w2, que vuelve al problema de la norma L2.
4. Resumen
Después de la derivación y comprensión anteriores, se puede ver que L0 reduce directamente el número de parámetros efectivos. Para L1, solo los parámetros con símbolos diferentes pueden hacer que algunos de los parámetros se conviertan en 0. Tanto las normas L0 como L1 pueden hacer que los parámetros del modelo disperso. ; Para L2, el parámetro no se puede establecer en 0, pero el valor general se puede reducir.