1. Descripción general del modelo de memoria JVM
(1) ¿Por qué aparece el modelo de memoria JVM?
El modelo de memoria JVM es una especificación que describe la forma y las reglas para que la máquina virtual Java almacene datos y código del programa en la memoria de la computadora al ejecutar un programa Java. El modelo de memoria JVM define la estructura de memoria utilizada por la máquina virtual Java y la relación entre las áreas de memoria, lo que permite que los programas Java se ejecuten de manera más eficiente.
La máquina virtual Java es una máquina virtual basada en una arquitectura de pila, que es diferente a la de una máquina física 寄存器的架构. Por lo tanto, la máquina virtual Java requiere un modelo de memoria para manejar los datos y el código involucrados en un programa Java 存储, así como durante la ejecución 内存管理. La aparición del modelo de memoria JVM permite que los programas Java se ejecuten de manera más estandarizada, eficiente y flexible.
Diagrama del modelo de memoria JVM, como se muestra a continuación:

- Contador de programa (registro de contador de programa): cada subproceso tiene un contador de programa independiente, que se utiliza para almacenar la dirección de la instrucción de código de bytes actualmente ejecutada por el subproceso.
- Pila de máquina virtual Java (pila JVM): cada subproceso tiene una pila de máquina virtual Java independiente, que se utiliza para almacenar variables locales, pilas de operandos, valores de retorno y otra información.
- Pila de métodos nativos : similar a la pila de máquinas virtuales Java, pero se utiliza para ejecutar métodos nativos.
- Montón : se utiliza para almacenar instancias de objetos Java y es compartido por todos los subprocesos.
- Área de método : se utiliza para almacenar información estructural, variables estáticas, grupo constante y otra información de la clase, que es compartida por todos los subprocesos.
- Grupo constante de tiempo de ejecución : parte del área del método, que se utiliza para almacenar varios literales y referencias de símbolos generados durante la compilación.
- Memoria directa: una memoria que utiliza administración que no es JVM, pero la usa a través de la API de JVM y generalmente se usa para mejorar el rendimiento de las operaciones de E / S.
(2) ¿Por qué la memoria JVM se divide de esta manera? Los puntos principales son los siguientes:
-
Separe los datos del programa y las estructuras de datos internas de JVM : la máquina virtual Java necesita almacenar mucha estructura interna e información de estado, así como los datos y el código del programa Java. Para que estos diferentes tipos de estructuras de datos sean independientes entre sí, la máquina virtual Java las almacena en diferentes áreas de memoria.
-
Necesidades de gestión de memoria : JVM necesita gestionar y optimizar la memoria. Dividir diferentes áreas de memoria ayuda a la JVM a controlar con mayor precisión la asignación, el reciclaje, la clasificación y otras operaciones de memoria, mejorando así la eficiencia operativa y la estabilidad del programa. Por ejemplo, en los programas Java se crea y destruye una gran cantidad de objetos. Para evitar la recolección frecuente de basura, la JVM utiliza dos áreas: la nueva generación y la antigua generación. La nueva generación se utiliza para almacenar los objetos recién creados y La vieja generación se utiliza para almacenar objetos de vida, objetos con períodos largos. Además, la JVM también proporciona áreas como el área de métodos y la pila de máquinas virtuales, que se utilizan para almacenar información de clases e información del marco de la pila cuando se ejecutan subprocesos. Al dividir las áreas de memoria, la JVM puede controlar con mayor precisión la asignación y liberación de memoria, evitando problemas como pérdidas y fragmentación de memoria. Al mismo tiempo, este diseño también puede hacer que el algoritmo de GC sea más eficiente, porque diferentes áreas utilizan diferentes estrategias de GC, que pueden optimizarse de acuerdo con sus respectivas características para mejorar la eficiencia del GC y la velocidad de respuesta.
-
Gestión de memoria flexible : en diferentes escenarios de aplicación, la JVM necesita asignar espacios de memoria de diferentes tamaños y ciclos de vida a los programas Java. Dividir diferentes áreas de memoria permite que la JVM administre la memoria de manera más flexible para satisfacer diferentes necesidades.
-
Seguridad de la memoria : el modelo de memoria de la JVM tiene un poderoso mecanismo de seguridad que puede proteger los datos y el código de los programas Java para que no sean destruidos por programas maliciosos. Al dividir diferentes áreas de memoria, la JVM puede lograr mejor la seguridad de la memoria.
En resumen, la JVM divide diferentes áreas de memoria principalmente para almacenar los datos y el código del programa Java en diferentes áreas de memoria, administrar mejor la memoria, mejorar la eficiencia operativa y la estabilidad del programa y cumplir con los diferentes requisitos de memoria. Seguridad de la memoria del programa.
( 3) El recolector de basura de GC corresponde al algoritmo de reciclaje, como se muestra en la siguiente lista:
-
Recopilador en serie : utiliza un algoritmo de barrido de marcas.
-
Recopilador paralelo : utiliza un algoritmo de barrido de marcas o un algoritmo de clasificación de marcas.
-
Recolector de CMS : utiliza el algoritmo de barrido de marca y el algoritmo de clasificación de barrido de marca (el barrido de marca se usa en las fases de marca inicial y barrido concurrente de CMS, y la clasificación de barrido y marca se usa en las fases de marca y barrido concurrentes).
-
Recolector G1 : utiliza algoritmos de clasificación de marcas y algoritmos de copia (mover y limpiar objetos a través de copias de memoria entre regiones).
Cabe señalar que estos son solo algunos recolectores de basura comunes y sus algoritmos de reciclaje correspondientes. De hecho, existen muchos otros recolectores de basura y algoritmos de reciclaje, y diferentes recolectores de basura también pueden usar diferentes combinaciones para reciclar.
2. Descripción general del modelo de memoria JMM
JMM (Java Memory Model, denominado JMM) es un concepto abstracto que realmente no existe, es un conjunto de convenciones o especificaciones descritas, a través de este conjunto de especificaciones se determinan los métodos de acceso de lectura y escritura de cada variable del programa. definido y determinado. ¿Cuándo la lectura y escritura de variables compartidas de un hilo se vuelven visibles para otro hilo? El punto técnico clave gira en torno a las tres características de subprocesos múltiples 原子性, 可见性y 有序性. Qué es 原子性, 可见性y se analizan a continuación 有序性.
Dado que la entidad del programa en ejecución JVM es un subproceso, cuando se crea cada subproceso, la JVM creará una memoria de trabajo (llamada espacio de pila en algunos lugares) para almacenar datos privados de subprocesos, y el modelo de memoria Java estipula que todas las variables son almacenado En la memoria principal, la memoria principal es un área de memoria compartida a la que pueden acceder todos los subprocesos. Sin embargo, las operaciones de los subprocesos sobre variables (lectura y asignación de valores, etc.) deben realizarse en la memoria de trabajo. Primero, las variables deben copiarse desde la memoria principal a su propio espacio de memoria de trabajo. , y luego operar las variables. Una vez completada la operación, las variables se vuelven a escribir en la memoria principal. Las variables en la memoria principal no se pueden operar directamente. Una copia de las variables en la memoria principal se almacena en la memoria de trabajo. Diferentes subprocesos no pueden acceder a la memoria de trabajo de los demás. La comunicación (transferencia de valor) entre subprocesos debe completarse a través de la memoria principal. El breve proceso de acceso es el siguiente:
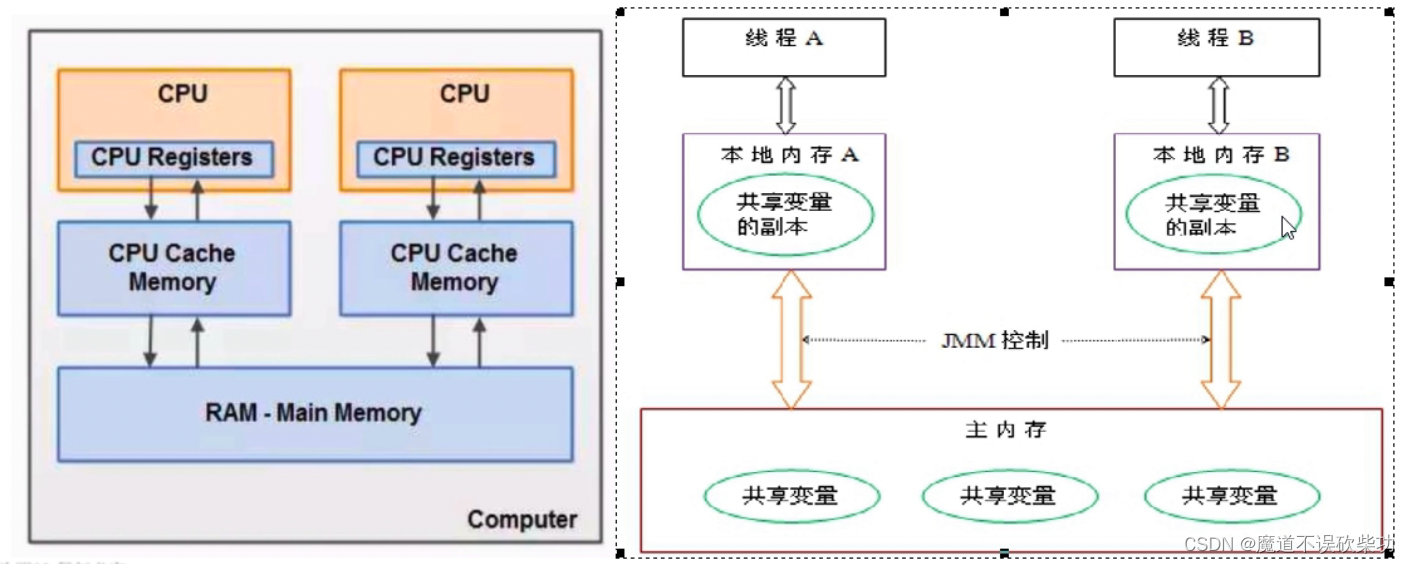
La ejecución del programa es impulsada por subprocesos, se puede decir que el portador del programa que se ejecuta es un subproceso.¿Para qué se puede utilizar la especificación JMM?
- Implementar la relación abstracta entre subprocesos y memoria principal a través de JMM
- Proteja las diferencias en el acceso a la memoria entre varias plataformas de hardware y sistemas operativos para lograr un acceso consistente a la memoria por parte de los programas Java en varias plataformas.
Supongamos que no existe ningún control JMMDebido a que no se puede acceder a las copias entre subprocesos y los datos compartidos están en realidad en la memoria principal. Si opera las variables de la manera anterior, inevitablemente habrá un problema de coherencia de los datos. Un ejemplo es el siguiente:

Hay una variable de conteo en la memoria principal con un valor inicial de 0. Ahora, si el hilo A quiere incrementarla en 1, primero debe leer la variable de conteo de la memoria principal y copiarla a la memoria privada, y luego incrementar la contar por 1. Cuando el subproceso A actualiza el valor de la variable de conteo en la memoria privada, está listo para sincronizarlo con la memoria principal, pero el tiempo no es fijo. Supongamos que el subproceso A no ha tenido tiempo de vaciar el recuento en la memoria principal y el subproceso B también copia el recuento anterior en su propia memoria privada. En este momento, el recuento sigue siendo el valor inicial 0 y también agrega 1 a y finalmente lo devuelve a la memoria principal. , el valor esperado es 2, pero como no hay garantía de visibilidad, el valor de recuento final es 1.
Esto es todo 线程数据脏读. Entonces se necesitan especificaciones (restricciones) JMM para resolver este problema 可见性. Su punto técnico clave se centra en las tres características del subproceso múltiple y Qué es y se 原子性analizan a continuación .可见性有序性原子性可见性有序性
3. Tres características principales de JMM
1. Visibilidad
La visibilidad se refiere a si otros subprocesos pueden conocer inmediatamente el cambio cuando un subproceso modifica el valor de una variable compartida. JMM estipula que todas las variables se almacenan en la memoria principal.
Generalmente, no está permitido que un hilo modifique directamente el valor en la memoria principal. El valor en la memoria principal debe copiarse a la memoria local del hilo actual. El hilo modifica esta copia de memoria compartida. Después de la modificación, se vuelve a escribir en la memoria principal a través del control JMM y luego notifica a otros subprocesos sobre la operación de cambio de esta variable. Los subprocesos no pueden acceder directamente a las variables en la memoria de trabajo de cada uno y la transferencia de valores de variables entre subprocesos se completa a través de la memoria principal.
Por ejemplo, el siguiente ejemplo:
public class VisibilityDemo {
private static boolean flag = true;
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new Thread(() -> {
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
flag = false;
System.out.println("Thread1 set flag to true");
});
Thread thread2 = new Thread(() -> {
while (flag) {
// 此处不断循环等待,直到flag变量被修改
}
System.out.println("Thread2 detected flag change");
});
thread1.start();
thread2.start();
}
}
En el código anterior, hay dos subprocesos que leen y escriben el indicador de variable compartida respectivamente. Estos dos subprocesos se inician en el subproceso principal. El subproceso subproceso1 establecerá el indicador en verdadero después de dormir durante 500 ms, mientras que el subproceso subproceso2 esperará en un bucle continuo a que se modifique la variable del indicador. Una vez que detecta que el indicador cambia a Es cierto, generará el cambio de bandera detectado por Thread2.
Sin embargo, dado que no existe un mecanismo de sincronización, es posible que el segundo subproceso nunca detecte la modificación de la variable compartida por parte del primer subproceso, porque la modificación de la variable compartida por parte del primer subproceso siempre puede existir en la caché local de ese subproceso sin ser oportuna. a la memoria principal, lo que hace que el segundo hilo no vea esta modificación. Por lo tanto, el resultado del programa puede ser una de dos cosas:
El programa no puede salir normalmente y permanece en estado de espera porque el segundo hilo no puede detectar las modificaciones del primer hilo.
Se genera el cambio de bandera detectado por Thread2, pero este no es un resultado que ocurre cada vez que se ejecuta, porque la modificación de la variable de bandera siempre puede existir en el caché local del primer subproceso y no se actualiza a la memoria principal a tiempo.
Para resolver este problema, necesitamos utilizar algún mecanismo de sincronización para garantizar la visibilidad, como el uso de synchronizedpalabras clave o volatilepalabras clave.
2. Orden
Para un código con subprocesos, podemos estar acostumbrados a pensar que se ejecuta de arriba a abajo y en orden, sin embargo, para mejorar el rendimiento, el compilador y el procesador realizarán modificaciones en el conjunto de instrucciones 重排序. Se puede garantizar la reorganización de las instrucciones 串行语义一致, peroNo hay obligación de garantizar una semántica coherente en varios subprocesos., es muy probable que ocurra 数据脏读. En otras palabras, cuando se ejecutan dos líneas de código no relacionadas, es posible que la primera no se ejecute primero y que no se ejecute de arriba a abajo. El orden de ejecución puede optimizarse. La optimización del conjunto de instrucciones puede ocurrir en las siguientes etapas, como se muestra a continuación:

1. Reordenamiento de optimización del compilador : el compilador puede reorganizar el orden de ejecución de las declaraciones sin cambiar la semántica del programa que se ejecuta en un entorno de un solo subproceso. El objetivo es reducir el número de registros de lectura y almacenamiento y reutilizar los datos de los registros.
Por ejemplo, hay tres códigos a continuación. Supongamos que A y B están en el mismo espacio de direcciones en la pila en este momento. Entonces B sobrescribirá el valor original de A. Cuando C usa A, necesita leer el valor de A nuevamente, lo que resulta en una degradación del rendimiento:
Paso 1: A = El valor del resultado de un determinado cálculo
Paso 2: B = El valor del resultado de un determinado cálculo
Paso 3: C = El valor del resultado de A debe usarse para el cálculo
Después de la optimización y reorganización, queda de la siguiente manera:
Paso 1: A = El valor del resultado de un cálculo
Paso 2: C = El valor del resultado de A debe usarse para realizar el cálculo
Paso 3: B = El valor del resultado de un cálculo
De esta forma, C puede reutilizar el valor A almacenado en el registro.
2. Reordenamiento paralelo a nivel de instrucción : El procesador ejecuta múltiples instrucciones en paralelo. Si no hay dependencia de datos, el procesador puede cambiar el orden de ejecución de las instrucciones correspondientes a las declaraciones.
Por ejemplo, las dos instrucciones siguientes no dependen en absoluto de los datos y se pueden ejecutar en paralelo para mejorar la eficiencia de la ejecución:
int a = 5
int b = 6
3. Reordenación del sistema de memoria : el procesador utiliza caché y buffers de lectura y escritura, lo que hace que las operaciones de carga y almacenamiento de datos parezcan estar desordenadas.

No hay nada que decir sobre un solo hilo: el resultado final de la ejecución es definitivamente el mismo que el resultado de la ejecución secuencial del código.
El procesador debe considerar instrucciones entre instrucciones al reordenar 数据依赖性, entonces, ¿qué es 数据依赖性?
Por ejemplo, el siguiente código:
public static synchronized void sop() {
int x = 15; // 语句1
int y = 20; // 语句2
x = x + 100;// 语句3
y = x * x; // 语句4
}
La declaración de ejecución se puede ejecutar de acuerdo con 1234, 2134 y 1324, pero no puede colocar la declaración 4 antes de la declaración 3 para su ejecución, porque la declaración 4 debe depender de la declaración 3 para ejecutarse primero y no puede poner el carro delante del caballo. , de lo contrario el resultado será incorrecto. Como existe entre las declaraciones 3 y 4 数据依赖性, siLa violación de las dependencias de datos debe prohibir el reordenamiento de instrucciones。
Definición de dependencia de datos: si dos operaciones acceden a la misma variable compartida y una de las dos operaciones es una operación de escritura, entonces existe una dependencia de datos entre las dos operaciones y no se permite la reordenación.
Las dependencias de datos se dividen en tres categorías: primero suponga que hay dos variables int ayb, y luego observe las categorías:
- Leer y luego escribir : leer una variable y luego escribir en la variable
a = b;
b = 1;
- Escribir después de escribir : escriba una variable y luego continúe escribiendo esta variable
a = 10;
a = 100;
- Leer después de escribir : después de escribir una variable, lea la variable
a = 10;
b = a;
Tenga en cuenta que no hay lectura tras lectura, porque las dependencias de datos deben tener una operación de escritura y estas instrucciones con dependencias de datos no se reordenarán.
2.1 ¿Qué es la semántica como si fuera serial?
Independientemente de si hay reordenamiento o no, y de cómo se realiza el reordenamiento, el resultado de la ejecución del programa no cambiará en un entorno de un solo subproceso. Los compiladores, JVM y procesadores deben implementar esta semántica. as-if-serialLa semántica garantiza que el resultado de la ejecución no se cambiará en un entorno de subproceso único y, lo que happens-beforees más importante, garantizará que el resultado de la ejecución no se cambiará en un entorno de subprocesos múltiples.
En un entorno de subprocesos múltiples, la ejecución alterna hacia arriba y hacia abajo. Debido a la existencia de una reorganización de optimización del compilador, no está claro si las variables utilizadas en los dos subprocesos pueden garantizar la coherencia y los resultados son impredecibles. Entonces, ¿cómo solucionar este problema? Puede seguir happens-beforelas reglas.
2.2 regla de sucede antes
En el modelo de memoria JMM, happens-beforese utiliza una regla para determinar el orden de ejecución entre dos operaciones. Si el resultado de la ejecución de una operación necesita afectar la ejecución de otra operación, entonces se debe satisfacer la relación entre las dos operaciones happens-beforepara garantizar el orden entre ellas.
Específicamente, si la operación A ocurre antes de la operación B, entonces los resultados de la ejecución de la operación A son visibles para la operación B, y el orden de ejecución de la operación A es anterior al orden de ejecución de la operación B. happens-beforeLas relaciones se pueden establecer de muchas maneras, como sincronización, variables volátiles, inicio y terminación de subprocesos, unión de subprocesos , etc.
En Java, las reglas de sucede antes incluyen los siguientes aspectos:
-
Reglas de orden del programa : en un hilo, de acuerdo con el orden del código del programa, la operación anterior ocurre antes de cualquier operación posterior.
-
Reglas de bloqueo : en un subproceso, todas las operaciones antes de liberar el bloqueo ocurren antes de todas las operaciones cuando los subprocesos posteriores adquieren el mismo bloqueo.
-
Reglas de variables volátiles : se produce una operación de escritura en una variable volátil, antes de una operación de lectura posterior en la variable.
-
Regla de transitividad : si A sucede antes de B y B sucede antes de C, entonces A sucede antes de C.
-
Reglas de inicio de subprocesos : dentro de un subproceso, el método start() del objeto Thread ocurre antes de cualquier operación en este subproceso.
-
Reglas de interrupción de subprocesos : se produce una llamada al método de interrupción () de un subproceso, antes de cualquier operación del subproceso interrumpido en ese subproceso.
-
Reglas de terminación de subprocesos : dentro de un subproceso, cualquier operación en el subproceso ocurre antes de que otros subprocesos verifiquen que el subproceso ha terminado.
-
Reglas de finalización de objetos : la inicialización de un objeto se completa (la ejecución del método constructor finaliza) ocurre antes del comienzo de su método finalize().
Estas reglas describen las relaciones entre operaciones en el modelo de memoria JMM happens-before.Corrección garantizada en programas concurrentes Java。
Dé un ejemplo para ilustrar el uso de ocho reglas:
private int value = 0;
public void setValue(int value){
this.value = value;
}
public void getValue(){
return this.value;
}
Supongamos que hay dos subprocesos A y B. El subproceso A elimina el método setValue () y el subproceso B llama al método getValue () ¿Cuál es el valor de retorno recibido por el subproceso B? Respuesta: No estoy seguro
Simplemente analice de acuerdo con las 8 happens-beforereglas anteriores (las reglas 5, 6, 7 y 8 se pueden ignorar y sus operaciones no están involucradas)
- Dado que los dos métodos son llamados por subprocesos diferentes y no están en el mismo subproceso, no está satisfecho.
程序次序规则 - Ambos métodos no utilizan cerraduras y no son satisfactorios.
锁定规则 - La variable no se modifica con la palabra clave volátil, que no se cumple.
volatile 变量规则 传递规则Aún más insatisfecho
Por lo tanto, del principio de "sucede antes" no se puede deducir que el subproceso A sucede antes que el subproceso B, por lo que este código no es seguro. ¿Cómo solucionar este código?
- Puede agregar bloqueos sincronizados a los métodos getValue() y setValue().
- Defina la variable de valor como palabra clave volátil
有序性Problema: si todo en el modelo de memoria JMM se basa volatileen synchornizedpalabras clave, muchos programas se volverán muy detallados. happens-beforePero en términos generales, no agregamos estas dos palabras clave todo el tiempo cuando escribimos código. Se usan principalmente en programación concurrente, debido a las principales restricciones y regulaciones del principio JMM en el lenguaje Java.
Para resumir lo que sucede antes , hay dos principios generales:
1. Si una operación ocurre antes de otra operación, entonces el resultado de la ejecución de la primera operación será visible para la segunda operación, y el orden de ejecución de la primera operación será antes de la segunda ejecución (para el programador una restricción) .
2. La existencia de una relación de "sucede antes" entre dos operaciones no significa que deban ejecutarse en el orden de "sucede antes" de la ejecución atómica. Si el reordenamiento puede dar un mejor rendimiento, el resultado de la ejecución se ejecutará de acuerdo con el "sucede antes" relación Los resultados son consistentes. Entonces este reordenamiento no es ilegal. Por ejemplo: 1+2 = 2+1, o turno de trabajo, etc. El resultado final es consistente (una restricción en el reordenamiento del compilador y el procesador) .
2.3 ¿Comprender la semántica volátil?
Con respecto a los problemas de visibilidad y orden causados por la reorganización de instrucciones, el modelo de memoria JMM define un conjunto de los ocho principios anteriores happens-beforepara garantizar la atomicidad, la visibilidad y el orden entre dos operaciones en un entorno de subprocesos múltiples. Además de los ocho principios anteriores, los desarrolladores también reciben volatilepalabras clave synchornizedpara resolver la atomicidad, la visibilidad y el orden. volatileOtro papel muy importante es 禁止指令重排序.
Se puede resumir en dos frases de la siguiente manera:
1. Al escribir una variable volátil, JMM actualizará inmediatamente la variable local correspondiente al hilo a la memoria principal
2. Al leer una variable volátil, JMM invalidará la variable local correspondiente al hilo y la leerá directamente desde la memoria principal memoria variables compartidas
2.3.1 volatileImplementación de la semántica de la memoria:
1. Nivel de código de bytes
volatile se usa para modificar variables y se agregará una bandera ACC_VOLATILE en el nivel de código de bytes.
2.Nivel JMM
Dónde insertar 内存屏障指令y qué insertar 内存屏障指令. Consulte la tabla de reglas de variables volátiles de la siguiente manera:
2.1 reglas de variables volátiles:
| primera operación | La segunda operación: lectura y escritura ordinaria. | La segunda operación: lectura volátil. | La segunda operación: escritura volátil. |
|---|---|---|---|
| Lectura y escritura ordinarias. | Se puede reorganizar | Se puede reorganizar | No se puede reorganizar |
| lectura volátil | No se puede reorganizar | No se puede reorganizar | No se puede reorganizar |
| escritura volátil | Se puede reorganizar | No se puede reorganizar | No se puede reorganizar |
-
Cuando la primera operación es
volatileuna lectura, la segunda operación no permite ningún reordenamiento, lo que garantiza quevolatilelas operaciones posteriores a la lectura no se pondrán en colavolatileantes de la lectura. -
Cuando la segunda operación es
volatileuna escritura, la primera operación no permite reordenar sin importar cuál sea, lo que garantiza quevolatilelas operaciones antes de la escritura no se reordenaránvolatiledespués de la escritura. -
Cuando la primera operación es
volatileescribir y la segunda operación esvolatileleer, no es posible reordenar.
2.2 Estrategia de inserción de instrucciones de barrera:
La razón por la que se produce el efecto anterior es porque volatilela capa inferior de palabras clave volatileinserta automáticamente las cuatro variables principales anteriores en las operaciones de lectura y escritura 内存屏障指令:loadload、storestore、loadstore、storeload. La estrategia de inserción específica es la siguiente:
-
Escrituras volátiles : inserte una barrera de almacenamiento antes de cada operación de escritura volátil y una barrera de carga de almacenamiento después de cada operación de escritura volátil .
-
Operaciones de lectura volátil : inserte una barrera de carga después de cada operación de lectura volátil y una barrera de almacenamiento de carga después de cada operación de lectura volátil .
¿Por qué insertarlo así? Te lo explicamos a continuación:
Primero veamos por qué se inserta una barrera de almacenamiento antes de cada operación de escritura volátil y una barrera de carga de almacenamiento después de cada operación de escritura volátil . Como se muestra abajo:

Después de ver por qué se inserta una barrera de carga después de cada operación de lectura volátil , se inserta una barrera de almacenamiento de carga después de cada operación de lectura volátil . Como se muestra abajo:

Pero, ¿por qué no está volatileprohibido reordenar entre lecturas y escrituras ordinarias?
(1) Escritura volátil : apunta a volatilela variable modificada por. Al escribir, volatileel valor de la variable se actualiza desde la memoria de trabajo a la memoria principal.
(2) Lectura normal: Lo que se lee no debe ser volatilela variable modificada.
Por lo tanto, la lectura normal no afectará el valor de las variables volátiles. Tampoco afecta a la memoria correspondiente. No destruirá la semántica de la memoria volátil.
En una oración simple: volatileal escribir, se devuelve directamente a la memoria principal y al leer, se recupera directamente de la memoria principal. Entonces, ¿cómo garantiza la palabra clave volátil la visibilidad y el orden del programa? ¿ 内存屏障指令Qué es exactamente a través de la implementación de la capa inferior 内存屏障指令?
3. Nivel de procesador
Cuando la CPU ejecuta instrucciones de la máquina, utiliza lockla ejecución de prefijo para implementar volatilela función.
(1) Primero bloquee el bus/caché, luego ejecute las instrucciones posteriores y, finalmente, libere el bloqueo y actualice los datos de la caché a la memoria principal.
(2) Cuando el bloqueo bloquea el bus/caché, las solicitudes de lectura y escritura de otras CPU se bloquearán hasta que se libere el bloqueo. Las operaciones de escritura después del bloqueo invalidarán los datos correspondientes en los cachés de otras CPU, de modo que cuando las CPU posteriores lean datos, deberán cargar los datos más recientes de la memoria principal.
Suplemento: la línea de caché se refiere a la unidad de almacenamiento más pequeña en el caché, generalmente un bloque de datos de 64 bytes (o más), también llamado bloque de caché. Cuando el procesador necesita acceder a una dirección de memoria, primero comprobará si existe la línea de caché correspondiente. Si existe, el procesador leerá directamente los datos de la línea de caché. Esta situación se denomina acierto de caché; si no existe El procesador primero debe leer el bloque de datos correspondiente de la memoria y colocarlo en el caché, proceso que se denomina error de caché. Dado que el tamaño de la línea de caché es generalmente relativamente grande, se pueden obtener varios datos en una lectura, lo que mejora la eficiencia de la lectura. Al mismo tiempo, la velocidad de acceso al caché es mucho más rápida que la de la memoria, por lo que el uso del caché puede reducir efectivamente la cantidad de accesos a la memoria por parte del procesador y mejorar la eficiencia de ejecución del programa.
2.4 Instrucciones de la barrera de la memoria
Veamos primero un ejemplo. Por ejemplo, durante las vacaciones, nadie controla el Lago del Oeste y se ve muy caótico. Algunas personas pueden caer al río, como se muestra en la siguiente imagen:

Como no hay control, no se puede garantizar el orden, por lo que es necesario establecer reglas para prohibir el desorden: el muro humano de aislamiento en Shanghai y Nanjing, como se muestra a continuación:

Esto puede evitar que las personas de arriba y las de abajo corran juntas. Este muro humano es equivalente a la barrera de la que estamos hablando ahora, pero ahora está en la memoria, por eso se llama 内存屏障. Por tanto, la palabra clave volátil se utiliza para 内存屏障garantizar la visibilidad y el orden.
Memory Barrier se refiere a un grupo 处理器指令utilizado para implementar restricciones secuenciales en las operaciones de memoria. Las barreras de la memoria se pueden dividir en muchos tipos, incluidas 读屏障, 写屏障, 全屏障etc.
En Java, las barreras de memoria se utilizan ampliamente para implementar reglas de visibilidad de la memoria y de sucede antes. El modelo de memoria Java estipula que insertar instrucciones de barrera de memoria apropiadas antes o después de realizar una operación puede garantizar la corrección del programa y garantizar que las operaciones de cada subproceso en variables compartidas se puedan realizar en un orden determinado.
Por ejemplo, para una operación de escritura en una variable volátil, el modelo de memoria Java requiere que se inserte una barrera de escritura (barrera de almacenamiento) después de la operación de escritura para garantizar que los resultados de la operación sean visibles para otros subprocesos. Para operaciones de lectura de variables volátiles, se debe insertar una barrera de lectura (barrera de carga) antes de la operación de lectura para garantizar que la operación de lectura vea el último valor.
En resumen, las barreras de memoria son una tecnología de compilación y hardware muy importante que desempeña un papel clave en la implementación de la programación multiproceso y la memoria compartida.
2.5 Clasificación de la barrera de la memoria
Las barreras de la memoria se pueden dividir en muchos tipos, incluidos 读屏障, 写屏障, 全屏障.
-
Barrera de lectura (barrera de carga) : inserte una barrera de lectura antes de una operación de lectura para garantizar que todas las operaciones de escritura antes de la operación de lectura sean visibles para la operación de lectura, es decir, la operación de lectura ve los últimos resultados de la operación de escritura. En otras palabras, esta instrucción de lectura invalidará directamente los datos en su memoria de trabajo/caché de CPU y volverá a leer los datos más recientes de la memoria principal.
-
Barrera de escritura (barrera de almacenamiento) : insertar una barrera de escritura después de una operación de escritura garantiza que la operación de escritura sea visible para las operaciones de lectura de otros subprocesos, es decir, otros subprocesos ven los últimos resultados de la operación de escritura. En otras palabras, esta instrucción de escritura obligará a que los datos del área de caché se devuelvan a la memoria principal.
-
Barrera completa (fullFence) : la barrera completa es una combinación de barrera de lectura y barrera de escritura. No solo garantiza que la operación de escritura sea visible para las operaciones de lectura de otros subprocesos, sino que también garantiza que la operación de lectura vea la última escritura. resultados de la operación.
Cabe señalar que es 内存屏障necesario utilizarlo con precaución, ya que un uso excesivo afectará el rendimiento del programa.
Veamos 内存屏障cómo se ve:
- El código fuente de Unsafe.java es el siguiente: Hay tres métodos nativos modificados en clases inseguras en Java , todos los cuales llaman al código JVM para su ejecución.
public final class Unsafe {
@HotSpotIntrinsicCandidate
public native void loadFence();
@HotSpotIntrinsicCandidate
public native void storeFence();
@HotSpotIntrinsicCandidate
public native void fullFence();
}
- El código fuente de Unsafe.cpp se muestra a continuación: En el código fuente de HotSport, la capa inferior llama a los métodos OrderAccess::acquire (), OrderAccess::release () y OrderAccess::fence () respectivamente.

- Continúe ingresando el método de clase OrderAccess , como se muestra a continuación:

Los cuatro anteriores son de los que hablamos a menudo.四大内存屏障指令: loadload、storestore、loadstore、storeload
- Continúe siguiendo
orderAccess_linux_x64.inline.hpplos archivos del sistema operativo Linux, como se muestra a continuación:

2.6 Instrucciones de la barrera de la memoria
¿ Qué significan los cuatro comandos de barrera loadload, storestorevistos arriba ? De hecho , están ordenados y combinados para formar cuatro grupos .loadstorestoreload写屏障前后顺序读屏障前后顺序屏障指令
| tipo de barrera | Ejemplo de instrucción | ilustrar |
|---|---|---|
| cargarcargar | cargar1;cargacargar;carga2 | 1. Deshabilite el reordenamiento: asegúrese de que la operación de lectura load1 ocurra antes que 后续las operaciones de carga2 y lectura. 2. Loadload aquí es equivalente a uno 读屏障. Necesita saber qué sucederá si se inserta una barrera de lectura antes de una instrucción de lectura (load2). Tendrá una función de barrera de lectura (garantizando que los datos en la memoria caché de trabajo de Load2 serán invalidado directamente y leído desde el maestro nuevamente. Leer los últimos datos en la memoria) Aquí surge una pregunta, ¿por qué solo se garantiza la carga2 posterior y no la carga1 anterior? Si se ejecuta de acuerdo con la secuencia del programa, siempre hay un comienzo para ejecute la adquisición de datos. Al principio, no hay ningún dato en el caché de carga1, solo se puede obtener de la memoria principal, por lo que solo cuando lo lea por segunda vez, deberá invalidar su caché y volver a leerlo. -leer los datos de la memoria principal. |
| tiendatienda | tienda1;tiendatienda;tienda2 | 1. Está prohibido reordenar: antes de que store2 escriba y 后续realice operaciones, debe asegurarse de que store1 se haya devuelto a la memoria principal. 2. El store aquí es equivalente a uno . Debe saber qué sucederá si se inserta una barrera de escritura después 写屏障 una instrucción de escritura (store1) efecto, tendrá la función de una barrera de escritura (para garantizar que los datos escritos por la instrucción store1 sean devueltos a la memoria principal) |
| almacén de carga | cargar1;cargaralmacén;almacenar2 | 1. Deshabilite el reordenamiento: antes de la operación de escritura y 后续operación de store2, debe asegurarse de que se haya leído load1 2. Esta instrucción es justo opuesta al orden de barrera de lectura y escritura, por lo que no tiene la función de barrera de lectura y escritura, solo la función de reordenamiento está prohibida. |
| carga de tienda | almacenar1;almacenarcargar;cargar2 | 1. Prohibir el reordenamiento: asegúrese de que la operación de escritura de store1 se haya devuelto a la memoria principal y que se 后续puedan ejecutar las operaciones de lectura y load2 . 2. La instrucción storeload es muy poderosa. Si observa de cerca, encontrará que tiene tales características. Se inserta después de la operación de escritura (store1) 写屏障. Se inserta antes de la operación de lectura (load2) 读屏障, entonces debe tener las funciones de lo anterior 读屏障y写屏障 |
Se puede encontrar en la tabla anterior que storeloadlas instrucciones de barrera son relativamente pesadas: loadload es equivalente a una barrera de lectura, storestore es equivalente a una barrera de escritura, loadstore solo tiene la función de deshabilitar el reordenamiento, porque el orden de las barreras de lectura y escritura es exactamente lo contrario, solo storeload tiene barreras de lectura, barreras de escritura y desactivación. La función de reordenamiento interactúa mucho con la memoria, tiene un gran retraso de interacción y consume muchos recursos.
Extensión: estas instrucciones de barrera no son instrucciones de ejecución reales del procesador, sino instrucciones multiplataforma definidas por JMM. Debido a que diferentes hardware implementan barreras de memoria de diferentes maneras, JMM abstrae estas instrucciones de barrera de memoria para proteger las diferencias en las plataformas de hardware subyacentes. Cuando se ejecuta, la JVM genera el código de máquina correspondiente para diferentes plataformas. Estas instrucciones de barrera de memoria se pueden optimizar en diferentes plataformas de hardware, de modo que solo se admitan algunas instrucciones de barrera de memoria JMM. Por ejemplo, en máquinas x86, solo las instrucciones de barrera de memoria son válidas, y otras no son compatibles y se reemplazan por nop storeload. es decir, no hay operación.
2.7 Proceso de lectura y escritura volátil: 8 métodos atómicos
JMM define 8 tipos de operaciones atómicas para garantizar que las operaciones en variables compartidas sean atómicas en un entorno de subprocesos múltiples, es decir, cuando un subproceso realiza esta operación, otros subprocesos no pueden realizar esta operación al mismo tiempo, lo que garantiza la coherencia de los datos. .
Estas 8 operaciones atómicas incluyen:
lock : Actúa sobre variables en la memoria principal, marcando una variable como exclusiva de un hilo.
desbloquear : Actúa sobre una variable en la memoria principal, liberando una variable que está en estado bloqueado, después de ser liberada puede ser bloqueada por otros subprocesos.
leer : actúa sobre las variables en la memoria principal, transfiriendo el valor de una variable de la memoria principal a la memoria de trabajo del subproceso para su uso en operaciones de carga posteriores.
cargar : Actúa sobre las variables en la memoria de trabajo del hilo, colocando el valor de la variable obtenido de la memoria principal mediante la operación de lectura en una copia de la variable en la memoria de trabajo.
uso : Actúa sobre las variables en la memoria de trabajo del hilo y pasa el valor de una variable en la memoria de trabajo al motor de ejecución.
asignar (asignación): Actúa sobre una variable en la memoria de trabajo del hilo, asignando un valor recibido del motor de ejecución a una variable en la memoria de trabajo.
store (almacenamiento): actúa sobre las variables en la memoria de trabajo del hilo, pasando el valor de una variable en la memoria de trabajo a la memoria principal para su uso en operaciones de escritura posteriores.
escribir : actúa sobre las variables en la memoria principal, escribiendo el valor de la variable obtenido de la memoria de trabajo mediante la operación de almacenamiento en la variable en la memoria principal.
Mediante la combinación de estas operaciones atómicas, se puede garantizar que el acceso y modificación de variables compartidas sean atómicos, evitando así el problema de la inconsistencia de los datos.
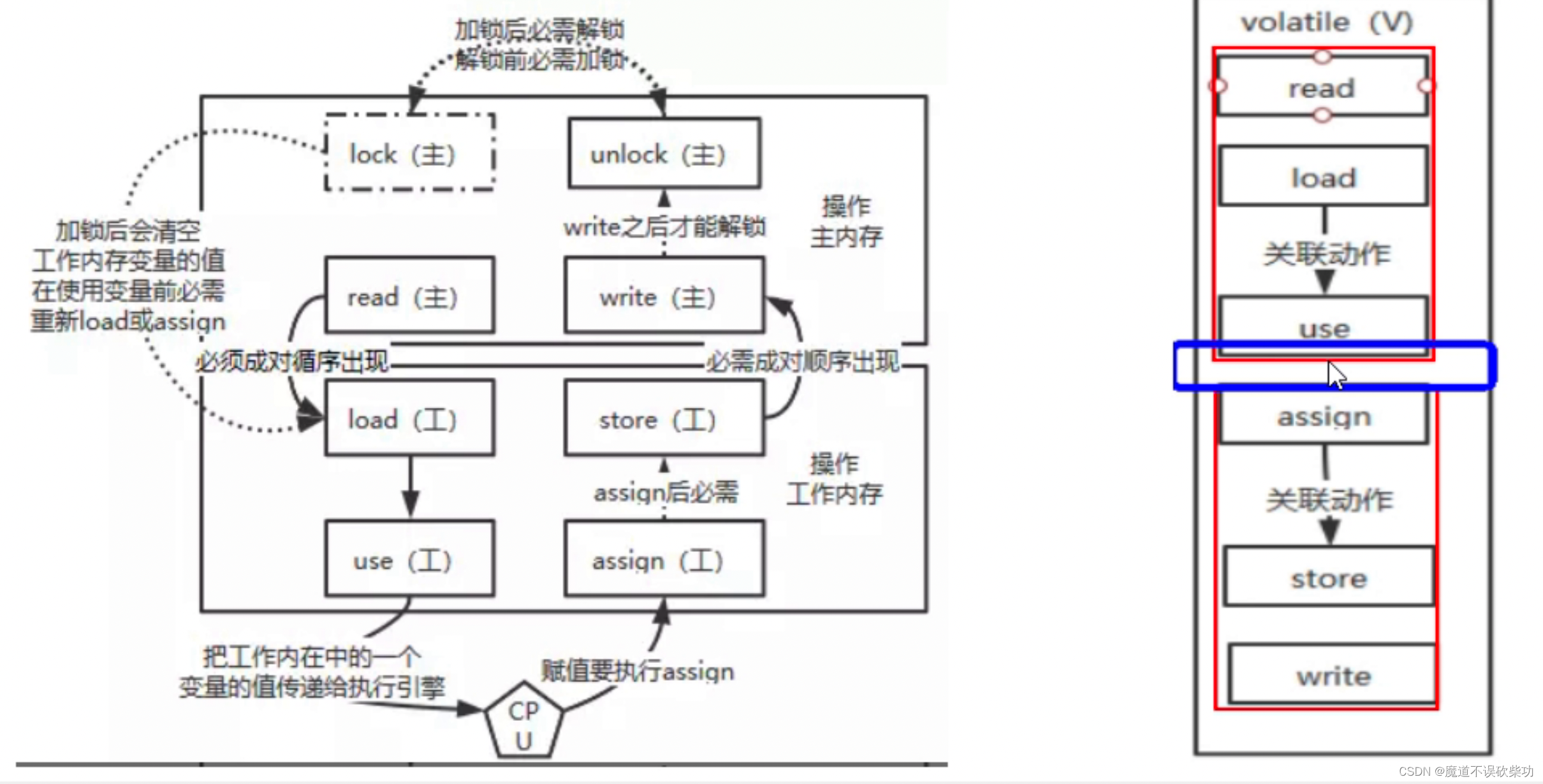
Aviso: Sin embargo, la competencia de subprocesos ocurrirá en la brecha entre el uso y la asignación (en el motor de ejecución de la CPU). Por ejemplo, la capa inferior de la operación i++ en realidad se compone de tres conjuntos de instrucciones. La ejecución de estas tres declaraciones entre el uso y la asignación no puede garantizar la atomicidad de la ejecución del subproceso, por lo que también se requiere el bloqueo para garantizar que el subproceso sea atómico y que los datos no estén libres de errores .
Las ocho operaciones atómicas definidas por JMM incluyen tres operaciones: lectura, escritura y lectura-modificación-escritura en una variable, y tres operaciones: lectura, escritura y lectura-modificación-escritura en una matriz. Estas operaciones garantizan que cada operación sea atómica cuando se ejecute, pero solo en una única variable (booleana) o un único elemento.
En el desarrollo real, las operaciones compuestas (como i ++) generalmente implican la modificación de múltiples variables o múltiples elementos. En este caso, las operaciones atómicas proporcionadas por JMM no pueden garantizar la atomicidad y deben usarse métodos de sincronización como sincronizado o Lock para garantizar A salvo de amenazas. Por lo tanto, las ocho operaciones atómicas definidas por JMM no pueden garantizar completamente la atomicidad.
Por ejemplo, el siguiente ejemplo de referencia:
public class VolatileNotAtomicExample {
private volatile int count = 0;
public void increment() {
count++;
}
public int getCount() {
return count;
}
public static void main(String[] args) throws InterruptedException {
final int THREADS_COUNT = 1000;
final int INCREMENT_COUNT = 1000;
VolatileNotAtomicExample example = new VolatileNotAtomicExample();
Thread[] threads = new Thread[THREADS_COUNT];
for (int i = 0; i < THREADS_COUNT; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < INCREMENT_COUNT; j++) {
example.increment();
}
});
threads[i].start();
}
for (int i = 0; i < THREADS_COUNT; i++) {
threads[i].join();
}
System.out.println("Count: " + example.getCount());
}
}
En el código anterior, 1000 subprocesos realizan 1000 operaciones de acumulación en la misma variable volátil al mismo tiempo. En teoría, el valor del recuento debería ser 1000 * 1000 = 1000000, pero el resultado real de la ejecución puede ser menor que este valor, porque los volátiles pueden Solo garantiza visibilidad, la atomicidad no está garantizada.
Las instrucciones subyacentes de count++ son las siguientes:
0: iconst_0
1: istore_1
2: iinc 1, 1
5: return
La ejecución de estas tres declaraciones entre uso y asignación no puede garantizar la atomicidad de la ejecución del subproceso.
2.8 volátil se utiliza en DCL
DCL (bloqueo de doble verificación) es una implementación del modo singleton que logra la seguridad de los subprocesos y la optimización del rendimiento mediante bloqueos de doble verificación. El uso de volátiles garantiza la seguridad de los subprocesos de la implementación de DCL.
El siguiente es un código de muestra que utiliza volátil para implementar DCL:
public class Singleton {
private static volatile Singleton instance;
private Singleton() {
}
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
En el ejemplo anterior, la variable de instancia se declara volátil, lo que garantiza que la instancia sea visible para todos los subprocesos. Sin una modificación volátil, un subproceso puede almacenar en caché la instancia en la memoria local en lugar de leerla desde la memoria principal, lo que hace que otro subproceso no vea el último valor de la variable. Al mismo tiempo, el uso del bloqueo de doble verificación puede evitar bloquear todo el método getInstance(), mejorando así el rendimiento.
Si no se agrega el modificador volátil, cuando un hilo accede al método getInstance () por primera vez, si las instrucciones se reorganizan a juicio de instancia == nulo, ocurrirá la siguiente situación:
El hilo A crea un objeto Singleton y asigna el objeto a la instancia.
El subproceso B llama al método getInstance() y encuentra esa instancia! = nula, por lo que devuelve la instancia directamente, pero esta instancia aún no se ha inicializado.
Agregar el modificador volátil puede prohibir el reordenamiento de instrucciones, lo que garantiza la visibilidad de la instancia para todos los subprocesos, y otros subprocesos no pueden acceder al objeto de la instancia antes de que se complete la creación de instancias de la instancia. Esto garantiza la seguridad de los subprocesos de la implementación DCL.
3. Atomicidad
En Java, la atomicidad significa que una operación no se puede interrumpir ni dividir, es decir, la operación se ha ejecutado por completo o aún no se ha ejecutado. En pocas palabras, la atomicidad significa que una operación se ejecuta completamente con éxito o falla por completo, y no existe la ejecución a medias.
En la programación de subprocesos múltiples, la atomicidad es un concepto muy importante, porque varios subprocesos pueden acceder y modificar los mismos datos al mismo tiempo. Si no se garantiza la atomicidad, pueden ocurrir inconsistencias de datos u otras anomalías.
En Java, las operaciones sobre algunos tipos de datos básicos, como operaciones simples como asignación, suma, resta, multiplicación y división, son todas atómicas, es decir, estas operaciones no serán interrumpidas por otros subprocesos. Para algunas operaciones complejas, como la combinación de múltiples operaciones, es necesario utilizar mecanismos de sincronización como synchronizedAtomic` Lock、para garantizar la atomicidad y evitar problemas de seguridad de los subprocesos.
Supongamos que dos subprocesos agregan 1 a un contador compartido al mismo tiempo, el código es el siguiente:
public class Counter {
private int count = 0;
public void increment() {
count++;
}
public int getCount() {
return count;
}
}
public class MyThread implements Runnable {
private Counter counter;
public MyThread(Counter counter) {
this.counter = counter;
}
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
counter.increment();
}
}
}
public class Main {
public static void main(String[] args) throws InterruptedException {
Counter counter = new Counter();
Thread thread1 = new Thread(new MyThread(counter));
Thread thread2 = new Thread(new MyThread(counter));
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println("Count: " + counter.getCount());
}
}
En el código anterior, hay una clase Counter que representa un contador. Tiene un método increment() para sumar 1 al contador y un método getCount() para obtener el valor actual del contador.
A continuación, defina una clase MyThread para representar un hilo, que contiene un objeto Contador y repite la operación de sumar 1 al contador 10.000 veces.
Finalmente, inicie dos subprocesos en la clase principal y espere a que completen la ejecución y finalmente genere el valor del contador.
Sin embargo, dado que dos subprocesos modifican el contador al mismo tiempo, se producirán problemas de seguridad de subprocesos sin ningún mecanismo de sincronización, lo que hará que el valor del contador no sea necesariamente correcto.
Por lo tanto, podemos utilizar la clase atómica AtomicInteger proporcionada por Java para garantizar la atomicidad del contador:
public class Counter {
private AtomicInteger count = new AtomicInteger(0);
public void increment() {
count.getAndIncrement();
}
public int getCount() {
return count.get();
}
}
Esto garantiza que la operación de incremento del contador sea atómica, evitando así problemas de seguridad de los subprocesos.