1. ¿Qué es Zookeeper?
ZooKeeper es un servicio de coordinación de aplicaciones distribuidas de código abierto. Es una implementación de código abierto de Chubby de Google. Es el administrador del clúster y supervisa el estado de cada nodo en el clúster. El siguiente paso es razonable según los comentarios enviados. por los nodos. En última instancia, se proporcionará a los usuarios una interfaz fácil de usar y un sistema con funciones estables y de alto rendimiento.
2. ¿Qué ofrece Zookeeper?
1) sistema de archivos
2) Mecanismo de notificación
3. Sistema de archivos Zookeeper
Cada elemento de subdirectorio, como NameService, se denomina znode. Al igual que el sistema de archivos, podemos agregar y eliminar libremente znodes, y agregar y eliminar sub-znodes bajo un znode. La única diferencia es que los znodes pueden almacenar datos.
Hay cuatro tipos de znodes:
1. PERSISTENTE: nodo de directorio persistente
Después de que el cliente se desconecta de zookeeper, el nodo sigue existiendo.
2. PERSISTENT_SEQUENTIAL: nodo de directorio de número secuencial persistente
Después de que el cliente se desconecta de Zookeeper, el nodo aún existe, pero Zookeeper numera secuencialmente el nombre del nodo
3. Nodo de directorio temporal EFÍMERO
Después de que el cliente se desconecta de zookeeper, el nodo se elimina
4. EPHEMERAL_SEQUENTIAL: nodo de directorio de número de secuencia temporal
Después de que el cliente se desconecta de Zookeeper, el nodo se elimina, pero Zookeeper numera secuencialmente el nombre del nodo

4. Mecanismo de notificación del cuidador del zoológico
El cliente se registra para escuchar los nodos de directorio que le interesan. Cuando los nodos de directorio cambian (los datos cambian, se eliminan, los nodos de subdirectorio se agregan o eliminan), zookeeper notificará al cliente.
5. ¿Qué hace Zookeeper?
1. Servicio de nombres 2. Gestión de configuración 3. Gestión de clústeres 4. Bloqueo distribuido 5. Gestión de colas
6. Servicio de nombres de cuidadores del zoológico
Cree un directorio en el sistema de archivos de zookeeper, que tiene una ruta única. Cuando usamos tborg para determinar la máquina de implementación del programa anterior, podemos acordar una ruta con el programa posterior, y podemos explorarnos y descubrirnos a través de la ruta.
Siete, gestión de configuración de Zookeeper
Los programas siempre deben configurarse.Si el programa se implementa en varias máquinas, se vuelve difícil cambiar la configuración una por una. Ahora coloque todas estas configuraciones en Zookeeper y guárdelas en un determinado nodo de directorio de Zookeeper, y luego todas las aplicaciones relacionadas monitorearán este nodo de directorio. Una vez que la información de configuración cambie, cada aplicación recibirá una notificación de Zookeeper. Luego obtenga la nueva información de configuración de Zookeeper y aplicarlo al sistema.
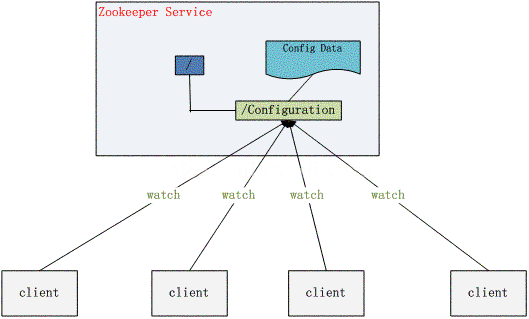
Ocho, gestión de clústeres de Zookeeper
La llamada gestión de clústeres no se preocupa por dos puntos: si hay máquinas saliendo y uniéndose, y eligiendo al maestro.
Para el primer punto, todas las máquinas acuerdan crear nodos de directorio temporales en el directorio principal GroupMembers y luego monitorear los mensajes de cambio de nodo secundario del nodo de directorio principal. Una vez que una máquina cuelga, la conexión entre la máquina y zookeeper se desconecta, el nodo de directorio temporal creado por ella se elimina y se notifica a todas las demás máquinas: se elimina un directorio hermano, para que todos lo sepan: está a bordo.
La adición de una nueva máquina es similar. Todas las máquinas reciben una notificación: se agrega un nuevo directorio hermano y el conteo alto vuelve a estar disponible. Para el segundo punto, lo cambiamos ligeramente. Todas las máquinas crean nodos temporales de directorio numerados en secuencia, y cada vez que la máquina con el número más pequeño se selecciona bien como maestra.
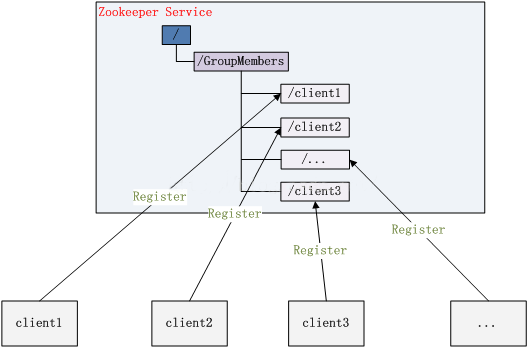
Nueve, cerradura distribuida Zookeeper
Con el sistema de archivos consistente de zookeeper, el problema del bloqueo se vuelve fácil. Los servicios de bloqueo se pueden dividir en dos categorías, una es para mantener la exclusividad y la otra es para controlar el tiempo.
Para la primera categoría, consideramos un znode en zookeeper como un bloqueo, que se realiza mediante createznode. Todos los clientes crean un nodo /distribute_lock y el cliente que se crea correctamente finalmente posee el bloqueo. Suelte el bloqueo después de eliminar el nodo distribuir_bloqueo creado por usted mismo.
Para la segunda categoría, /distribute_lock ha preexistido, y todos los clientes crean nodos de directorio temporales numerados secuencialmente debajo de él, que es lo mismo que seleccionar un maestro, el que tiene el número más pequeño adquiere el bloqueo y lo elimina cuando se usa arriba, lo cual es conveniente en orden.
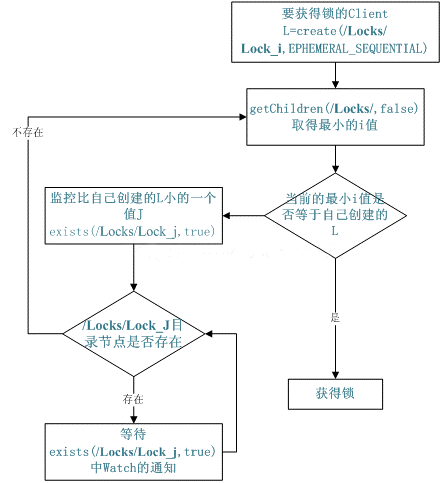
10. Gestión de colas de cuidadores del zoológico
Dos tipos de colas:
1. Cola síncrona, cuando todos los miembros de una cola están reunidos, la cola está disponible; de lo contrario, ha estado esperando a que lleguen todos los miembros.
2. La cola realiza operaciones de encolado y desencolado en modo FIFO.
La primera categoría es crear un nodo de directorio temporal bajo el directorio acordado y monitorear si el número de nodos es el número que necesitamos.
La segunda categoría es consistente con el principio básico del escenario de tiempo de control en el servicio de bloqueo distribuido.Las consultas están numeradas y las salidas de cola están numeradas.
11. Replicación distribuida y de datos
Zookeeper proporciona servicios de datos consistentes como un clúster Naturalmente, necesita replicar datos entre todas las máquinas. Beneficios de la replicación de datos:
1. Tolerancia a fallas: si un nodo falla, todo el sistema no dejará de funcionar y otros nodos pueden hacerse cargo de su trabajo 2.
Mejorar la escalabilidad del sistema: distribuir la carga a varios nodos o aumentar la carga del sistema agregando nodos 3. Mejore el rendimiento
: permita que el cliente acceda al nodo más cercano localmente para mejorar la velocidad de acceso del usuario.
Desde la perspectiva de la transparencia del acceso de lectura y escritura del cliente, el sistema de clúster de replicación de datos se divide en los dos tipos siguientes:
1. Write Master (WriteMaster): La modificación de los datos se envía al nodo designado. No existe tal límite para la lectura, y se puede leer cualquier nodo. En este caso, el cliente necesita distinguir entre lectura y escritura, comúnmente conocida como separación de lectura y escritura,
2. Write Any: La modificación de datos se puede enviar a cualquier nodo, al igual que la lectura. En este caso, el cliente es transparente a los roles y cambios de los nodos del clúster.
Para zookeeper, la forma en que lo usa es escribir arbitrariamente. Al agregar máquinas, su rendimiento de lectura y capacidad de respuesta son muy escalables, mientras que la escritura, a medida que aumenta la cantidad de máquinas, el rendimiento definitivamente disminuirá (es por eso que crea observadores), y la capacidad de respuesta depende de la implementación específica. consistencia o replicación inmediata para una respuesta rápida.
12. Descripción del rol de cuidador del zoológico
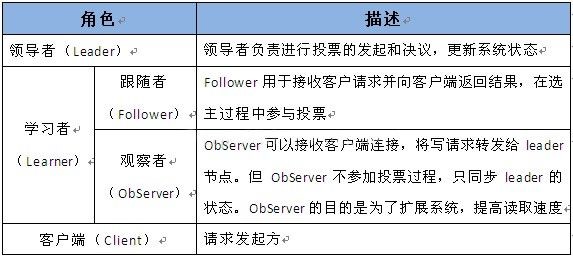
Trece, Zookeeper y cliente
.
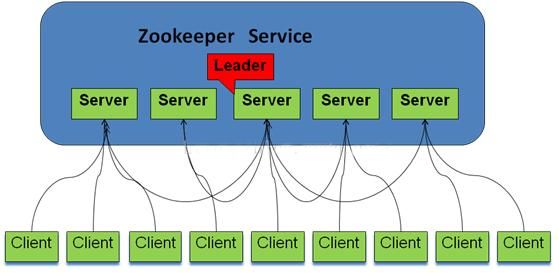
Catorce, propósito de diseño Zookeeper
1. Consistencia final: no importa a qué servidor se conecte el cliente, le mostrará la misma vista, que es el rendimiento más importante de zookeeper.
2. Confiabilidad: Tiene un rendimiento simple, robusto y bueno.Si un servidor acepta un mensaje, será aceptado por todos los servidores.
3. Tiempo real: Zookeeper garantiza que el cliente obtendrá la información de actualización del servidor o la información de la falla del servidor dentro de un intervalo de tiempo. Sin embargo, debido a retrasos en la red y otras razones, Zookeeper no puede garantizar que dos clientes puedan obtener los datos recién actualizados al mismo tiempo. Si se necesitan los datos más recientes, se debe llamar a la interfaz sync() antes de leer los datos.
4. Sin esperas: los clientes lentos o inválidos no deben interferir con las solicitudes de los clientes rápidos, para que cada cliente pueda esperar efectivamente.
5. Atomicidad: la actualización solo puede tener éxito o fallar, no hay un estado intermedio.
6. Secuencia: incluido el orden global y el orden parcial: el orden global significa que si el mensaje a se publica antes que el mensaje b en un servidor, el mensaje a se publicará antes que el mensaje b en todos los servidores; el orden parcial significa que si el mensaje b es publicado por el mismo remitente después del mensaje a, a debe estar delante de b.
15. Principio de funcionamiento de Zookeeper
El núcleo de Zookeeper es la transmisión atómica, que garantiza la sincronización entre servidores. El protocolo que implementa este mecanismo se denomina protocolo Zab. El protocolo Zab tiene dos modos, que son el modo de recuperación (elección maestra) y el modo de transmisión (sincronización). Cuando el servicio se inicia o después de que el líder falla, Zab ingresa al modo de recuperación. Cuando se elige al líder y la mayoría de los servidores completan la sincronización de estado con el líder, el modo de recuperación finaliza. La sincronización de estado garantiza que el líder y el servidor tengan el mismo estado del sistema.
Para garantizar la coherencia secuencial de las transacciones, zookeeper utiliza un número de identificación de transacción incremental (zxid) para identificar las transacciones. Todas las propuestas tienen zxid agregado cuando se proponen. En la implementación, zxid es un número de 64 bits, y sus 32 bits superiores se usan por época para identificar si la relación del líder ha cambiado. Cada vez que se elige un líder, tendrá una nueva época, que identifica el período de gobierno actual. de ese líder. Los 32 bits inferiores se utilizan para contar hacia adelante.
16. Estado de funcionamiento del servidor bajo Zookeeper
Cada servidor tiene tres estados durante el proceso de trabajo:
MIRANDO: El Servidor actual no sabe quién es el líder y lo está buscando
LÍDER: El Servidor actual es el líder elegido
SIGUIENTE: El líder ha sido elegido y el Servidor actual está sincronizado con él.
Diecisiete, proceso principal de selección de Zookeeper baiscpaxos
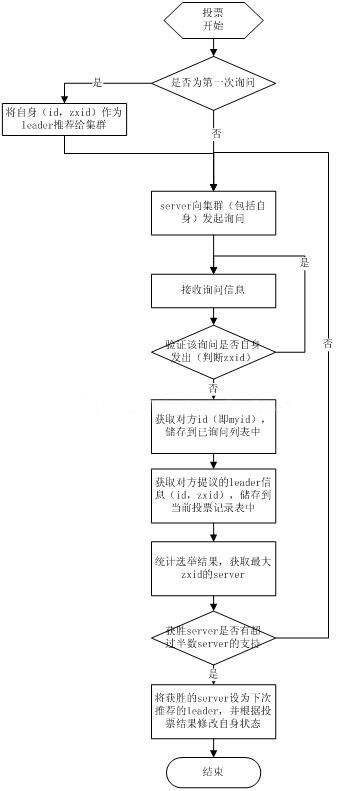
Cuando el líder falla o el líder pierde a la mayoría de los seguidores, zk ingresa al modo de recuperación en este momento, y el modo de recuperación debe volver a elegir un nuevo líder para restaurar todos los servidores a un estado correcto. Hay dos algoritmos de elección de Zk: uno se basa en paxos básicos y el otro se basa en el algoritmo de paxos rápidos. El algoritmo de elección por defecto del sistema es fast paxos.
1. El hilo de elección es el hilo iniciado por el servidor actual, su función principal es contar los resultados de la votación y seleccionar el servidor recomendado;
2. El subproceso de elección primero inicia una consulta a todos los servidores (incluido él mismo);
3. Después de que el subproceso de elección recibe la respuesta, verifica si es la consulta iniciada por sí mismo (verifica si el zxid es consistente), luego obtiene la identificación (myid) de la otra parte y la almacena en la lista de objetos de consulta actual , y finalmente obtiene la información relacionada con el líder propuesta por el otro partido (id, zxid), y almacena esta información en la tabla de registro de votación de la elección actual;
4. Después de recibir las respuestas de todos los servidores, calcule el servidor con el zxid más grande y configure la información relevante de este servidor como el servidor para votar la próxima vez;
5. El hilo establece el servidor actual con el zxid más grande como el líder recomendado por el servidor actual. Si el servidor ganador obtiene n/2 + 1 votos de servidor en este momento, establezca el líder recomendado actualmente como el servidor ganador, y estará relacionado con el servidor ganador.El mensaje establece su propio estado, de lo contrario, el proceso continúa hasta que se elige un líder. Mediante el análisis del proceso, podemos concluir que: para que el Líder obtenga el apoyo de la mayoría de los Servidores, la cantidad total de Servidores debe ser un número impar 2n+1, y la cantidad de Servidores supervivientes no debe ser inferior a n+ 1. El proceso anterior se repetirá después de que se inicie cada servidor. En el modo de recuperación, si el servidor acaba de recuperarse de un bloqueo o acaba de iniciarse, también recuperará datos e información de la sesión de la instantánea del disco.ZK registrará el registro de transacciones y tomará instantáneas periódicamente para facilitar la recuperación del estado durante la recuperación. El diagrama de flujo específico de la elección es el siguiente:
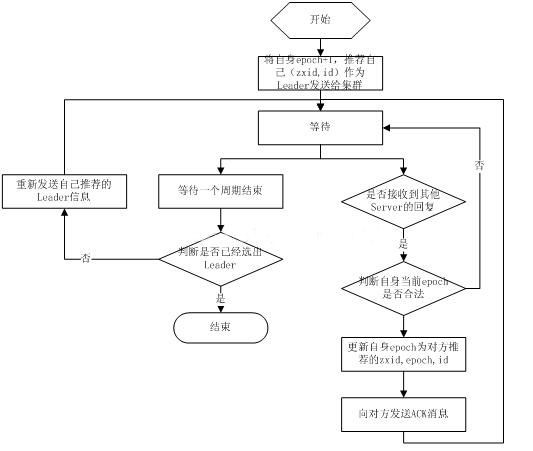
18. Proceso principal de selección del cuidador del zoológico fastpaxos
El proceso fast paxos es que durante el proceso de elección, un servidor primero propone a todos los servidores que quiere convertirse en líder, cuando otros servidores reciben la propuesta, resuelven el conflicto entre epoch y zxid, aceptan la propuesta de la otra parte y luego envíe a la otra parte un mensaje de propuesta de aceptación completa, repita este proceso y finalmente se elegirá un líder.
19. Proceso de sincronización de Zookeeper
Después de seleccionar el líder, zk ingresa al proceso de sincronización de estado.
- El líder espera la conexión del servidor;
2. El seguidor se conecta con el líder y envía el zxid más grande al líder;
3. El líder determina el punto de sincronización según el zxid del seguidor;
4. Una vez completada la sincronización, notifique al seguidor que se ha convertido en un estado actualizado;
5. Después de que el seguidor recibe el mensaje de actualización, puede aceptar la solicitud de servicio del cliente nuevamente.

20. Líder del flujo de trabajo de Zookeeper
1. Restaurar datos;
2. Mantener el latido del corazón con el alumno, recibir la solicitud del alumno y juzgar el tipo de mensaje de solicitud del alumno;
3. Los tipos de mensajes del alumno incluyen principalmente mensajes PING, mensajes de SOLICITUD, mensajes de ACK y mensajes de REVALIDAR, y se realiza un procesamiento diferente según los diferentes tipos de mensajes.
El mensaje PING se refiere a la información de los latidos del corazón del alumno;
El mensaje de SOLICITUD es la información de la propuesta enviada por el seguidor, incluida la solicitud de escritura y la solicitud de sincronización;
El mensaje ACK es la respuesta del seguidor a la propuesta, si pasa más de la mitad de los seguidores, la propuesta será comprometida;
El mensaje REVALIDAR se usa para extender el tiempo efectivo de SESIÓN.
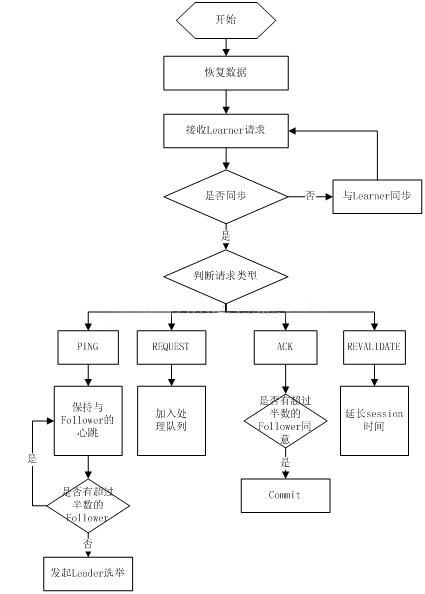
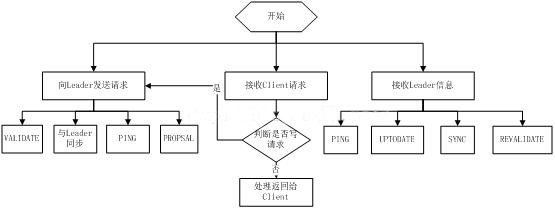
21. Seguidor de flujo de trabajo de Zookeeper
El seguidor tiene cuatro funciones principales:
1. Enviar una solicitud al Líder (mensaje PING, mensaje SOLICITUD, mensaje ACK, mensaje REVALIDAR);
2. Recibir el mensaje del Líder y procesarlo;
3. Recibir la solicitud del Cliente, si es una solicitud por escrito, enviarla al Líder para votación;
4. Devolver el resultado del Cliente.
El bucle de mensajes del seguidor procesa los siguientes mensajes del líder:
1. Mensaje PING: mensaje de latido;
2. Mensaje de PROPUESTA: Una propuesta iniciada por el Líder, que requiere que los Seguidores voten;
3. Mensaje COMMIT: la información de la última propuesta en el lado del servidor;
4.Mensaje UPTODATE: indica que se completó la sincronización;
5. REVALIDAR mensaje: De acuerdo al resultado de REVALIDAR del Líder, cerrar la sesión a ser revalidada o permitirle aceptar mensajes;
6. Mensaje SYNC: Devuelve el resultado SYNC al cliente Este mensaje lo inicia inicialmente el cliente para forzar la última actualización.
El artículo es de mi blog personal: http://www.iotjike.com/article/34