Árbol de decisión (activado)
ID3, algoritmo C4.5 para clasificación
I. Resumen
Toda la generación del modelo de árbol de decisión se completa en tres pasos: selección de características, generación del árbol de decisión y poda.
Definición de fórmula:
Entropía H(D):
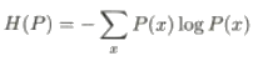
Entropía condicional H(D|A):

Ganancia de información:
![]()
Relación de ganancia de información:
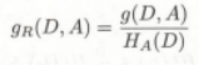
Ha(D) es la entropía condicional H(D|A)
Estrategia de generación de árboles de decisión:
Utilice la función que más reduzca la entropía del conjunto de datos, es decir, la función con la mayor ganancia de información o relación de ganancia de información para dividir el conjunto de datos, y repita esta operación hasta lograr la precisión deseada.
Estrategia de poda del árbol de decisión:
Construya una función de pérdida para un árbol de decisión con regularización:
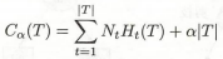
El número de nodos hoja del árbol T es |T | , t es el nodo hoja del árbol T , y el nodo hoja tiene N t puntos de muestra, H t (T) es la entropía empírica en el nodo hoja t , a ≥0 es un parámetro.
Supongamos que hay N tk puntos muestrales de clase k , k = 1,2,…,K , entonces la entropía empírica del aprendizaje del árbol de decisiones se define como

Los nodos de hoja se cortan gradualmente de abajo hacia arriba, y la pérdida del nuevo árbol de decisión generado al cortar cada vez se compara con el árbol de decisión sin podar para mantener el árbol de decisión con una pequeña pérdida hasta que se encuentra el árbol de decisión que minimiza la pérdida. .
2. Contenido principal
Un modelo de árbol de decisión de clasificación es una estructura de árbol que describe la clasificación de instancias. Un árbol de decisión consta de nodos ( nodo ) y aristas dirigidas ( arista dirigida ). Hay dos tipos de nodos: nodos internos ( nodo interno ) y nodos hoja ( nodo hoja ). Un nodo interno representa una característica o atributo, y un nodo hoja representa una clase.
Utilice la clasificación del árbol de decisión, comience desde el nodo raíz, pruebe una determinada característica de la instancia y asigne la instancia a sus nodos secundarios de acuerdo con los resultados de la prueba; en este momento, cada nodo secundario corresponde a un valor de la característica. Las instancias se prueban y asignan recursivamente hasta que se alcanza un nodo hoja. Finalmente, las instancias se dividen en las clases de los nodos hoja.
Se puede ver que el algoritmo de aprendizaje del árbol de decisión incluye la selección de características, la generación del árbol de decisión y el proceso de poda del árbol de decisión. Dado que un árbol de decisión representa una distribución de probabilidad condicional, los árboles de decisión con diferentes profundidades corresponden a modelos de probabilidad de diferente complejidad. La generación del árbol de decisión corresponde a la selección local del modelo y solo considera el óptimo local, es decir, solo considera la clasificación óptima de los datos del conjunto de entrenamiento La poda del árbol de decisión corresponde a la selección global del modelo y considera el óptimo global, es decir, el conjunto de entrenamiento y la máquina de prueba, todos tratan de ser los mejores.
La figura 5.1 es un diagrama esquemático de un árbol de decisión. Los círculos y cuadros de la figura representan nodos internos y nodos hoja, respectivamente.


Selección de características:
La selección de características es para determinar qué característica se utiliza para dividir los datos.
Elegir diferentes divisiones de características dará como resultado diferentes resultados de clasificación.
La pregunta es: ¿Qué característica es mejor elegir? Esto requiere la determinación de criterios para seleccionar características. Intuitivamente, si una función tiene una mejor capacidad de clasificación, o en otras palabras, divide el conjunto de datos de entrenamiento en subconjuntos de acuerdo con esta función, de modo que cada subconjunto tenga la mejor clasificación en las condiciones actuales, entonces se debe seleccionar esta función. La ganancia de información ( information gain ) bien puede representar este criterio intuitivo.
//=============== Conocimientos preliminares =================//

//======================================//
Entropía, entropía condicional, ganancia de información, relación de ganancia de información
La fórmula para calcular la entropía es:

La fórmula para calcular la entropía condicional es:

Ganancia de información:

La comprensión de la ganancia de información es: la entropía del conjunto de datos original, es decir, la incertidumbre es H(D).Después de que ocurre el evento A, por ejemplo, se usa una determinada característica para dividir el conjunto de datos, y la entropía de el conjunto de datos se convierte en la entropía condicional H(D|A), por lo que la ganancia de información g(D,A)=H(D)-H(D|A).Esto significa que el cambio en la incertidumbre del conjunto de datos antes y después de que la ocurrencia del evento A se registre como g(D,A), la ganancia de información es grande, lo que indica que este evento es más efectivo para dividir el conjunto de datos.
Relación de ganancia de información:

Estrategia:
El aprendizaje del árbol de decisiones aplica el criterio de ganancia de información para seleccionar características. Dado un conjunto de datos de entrenamiento D y características A , la entropía empírica H(D) representa la incertidumbre de clasificar el conjunto de datos D. Y la entropía condicional empírica H(D|A) representa la incertidumbre de clasificar el conjunto de datos D dada la condición de la característica A. Entonces su diferencia, es decir, la ganancia de información, representa el grado en que la incertidumbre de la clasificación del conjunto de datos D se reduce debido a la característica A. Obviamente, para el conjunto de datos D , la ganancia de información depende de las características y, a menudo, diferentes características tienen diferentes ganancias de información. Las características con gran ganancia de información tienen una mayor capacidad de clasificación.
El método de selección de funciones de acuerdo con el criterio de ganancia de información es: para el conjunto (o subconjunto) de datos de entrenamiento D , calcule la ganancia de información de cada función, compare sus tamaños y seleccione la función con la mayor ganancia de información.
algoritmo:

Algoritmo ID3:

Algoritmo C4.5:
Similar al algoritmo ID3, la relación de ganancia de información se utiliza para determinar las características de la segmentación.
Poda:
Un algoritmo de generación de árbol de decisión genera recursivamente un árbol de decisión hasta que no puede avanzar más. El árbol generado de esta manera suele ser muy preciso en la clasificación de datos de entrenamiento, pero no tan preciso en la clasificación de datos de prueba desconocidos, es decir, se produce un sobreajuste. El motivo del sobreajuste es que se presta demasiada atención a cómo mejorar la clasificación correcta de los datos de entrenamiento durante el aprendizaje, lo que genera un árbol de decisiones demasiado complejo. La solución a este problema es simplificar el árbol de decisión generado considerando la complejidad del árbol de decisión.
El proceso de simplificación del árbol generado en el aprendizaje del árbol de decisión se denomina poda . Específicamente, la poda elimina algunos subárboles o nodos de hoja del árbol generado y usa su nodo raíz o nodo principal como un nuevo nodo de hoja, lo que simplifica el modelo de árbol de clasificación.
Ideas de algoritmos de poda:

La primera parte de la fórmula es la entropía de todo el árbol de decisión, que es la suma de la entropía de todos los subconjuntos multiplicada por un coeficiente, que es similar a la entropía utilizada en la generación del árbol de decisión anterior, excepto que la entropía de cada subconjunto se multiplica por El número de muestras en su propio subconjunto se utiliza como coeficiente. Todo el proceso de generación del árbol de decisión es para minimizar la entropía general de la parte anterior. Lo que sigue es un término de penalización. También provocó la reducción de la parte delantera y el posible aumento de la parte trasera para evitar el sobreajuste.

En la fórmula ( 5.14 ), C(T) representa el error de predicción del modelo sobre los datos de entrenamiento, es decir, el grado de ajuste entre el modelo y los datos de entrenamiento, |T| representa la complejidad del modelo y el parámetro a≥0 controla la influencia entre los dos. Una a más grande fomenta la selección de modelos más simples (árboles) y una a más pequeña fomenta la selección de modelos más complejos (árboles). a = 0 significa que solo se considera el grado de ajuste del modelo y los datos de entrenamiento, y no se considera la complejidad del modelo.
La poda consiste en seleccionar el modelo con la función de pérdida más pequeña cuando se determina a , es decir, el subárbol con la función de pérdida más pequeña. Cuando se determina el valor de a , cuanto mayor sea el subárbol, mejor será el ajuste con los datos de entrenamiento, pero mayor será la complejidad del modelo; por el contrario, cuanto menor sea el subárbol, menor será la complejidad del modelo, pero a menudo con los datos de entrenamiento no encaja bien. La función de pérdida expresa exactamente el equilibrio entre los dos.
Se puede ver que la generación del árbol de decisión solo considera un mejor ajuste a los datos de entrenamiento al aumentar la ganancia de información (o la relación de ganancia de información). La poda del árbol de decisión también considera reducir la complejidad del modelo mediante la optimización de la función de pérdida. La generación de árboles de decisión aprende un modelo local, mientras que la poda de árboles de decisión aprende un modelo global.
Algoritmo de poda:
