1. Información general
El objetivo del aprendizaje por transferencia es utilizar algunos datos irrelevantes para mejorar la tarea objetivo. Irrelevante incluye principalmente
- La tarea no está relacionada. Por ejemplo, uno es un clasificador de perros y gatos, y el otro es un clasificador de tigres y leones
- los datos no son relevantes. Por ejemplo, ambos son clasificadores de perros y gatos, pero uno es de fotos reales de gatos y perros, y el otro es de dibujos animados de gatos y perros.
Hay dos partes de datos en el aprendizaje por transferencia
- datos fuente. No está directamente relacionado con la tarea de destino, los datos etiquetados o no etiquetados son generalmente más fáciles de obtener y la cantidad de datos es grande. Puede utilizar algunos conjuntos de datos públicos, como ImageNet. Por ejemplo, en las tareas de traducción automática, la cantidad de datos chino-inglés es muy grande, que se puede utilizar como datos de origen.
- datos de destino. Los datos directamente relacionados con la tarea de destino, los datos etiquetados o no etiquetados son generalmente relativamente pequeños. Por ejemplo, en las tareas de traducción automática, la traducción del chino al portugués es relativamente menor.
De acuerdo con los datos de origen y los datos de destino, ya sea que contengan datos etiquetados, podemos dividirnos en cuatro categorías
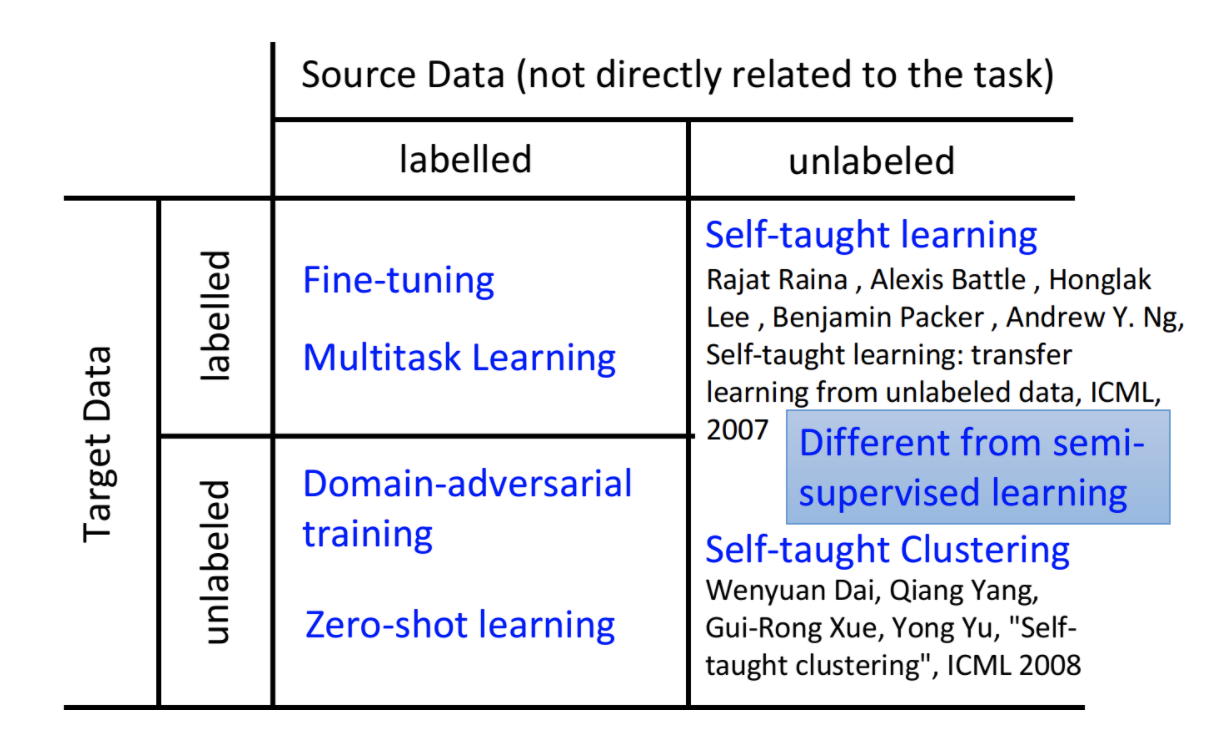
Aquí están los cuatro tipos de casos y sus métodos de procesamiento.
2 Tanto la fuente como el destino tienen etiquetas
En este momento, suele darse el caso de que ambos tengan etiquetas, pero la cantidad de datos de origen es relativamente grande y la cantidad de datos de destino es relativamente pequeña. Si el volumen de datos de destino en sí es relativamente grande, entonces podemos usar directamente los datos de destino para entrenar el modelo, sin usar datos de origen. En este momento se utilizan comúnmente dos métodos
- Realice un entrenamiento previo con los datos de origen y luego ajuste los datos de destino
- Combine las dos tareas de origen y destino para realizar un aprendizaje multitarea (MTL)
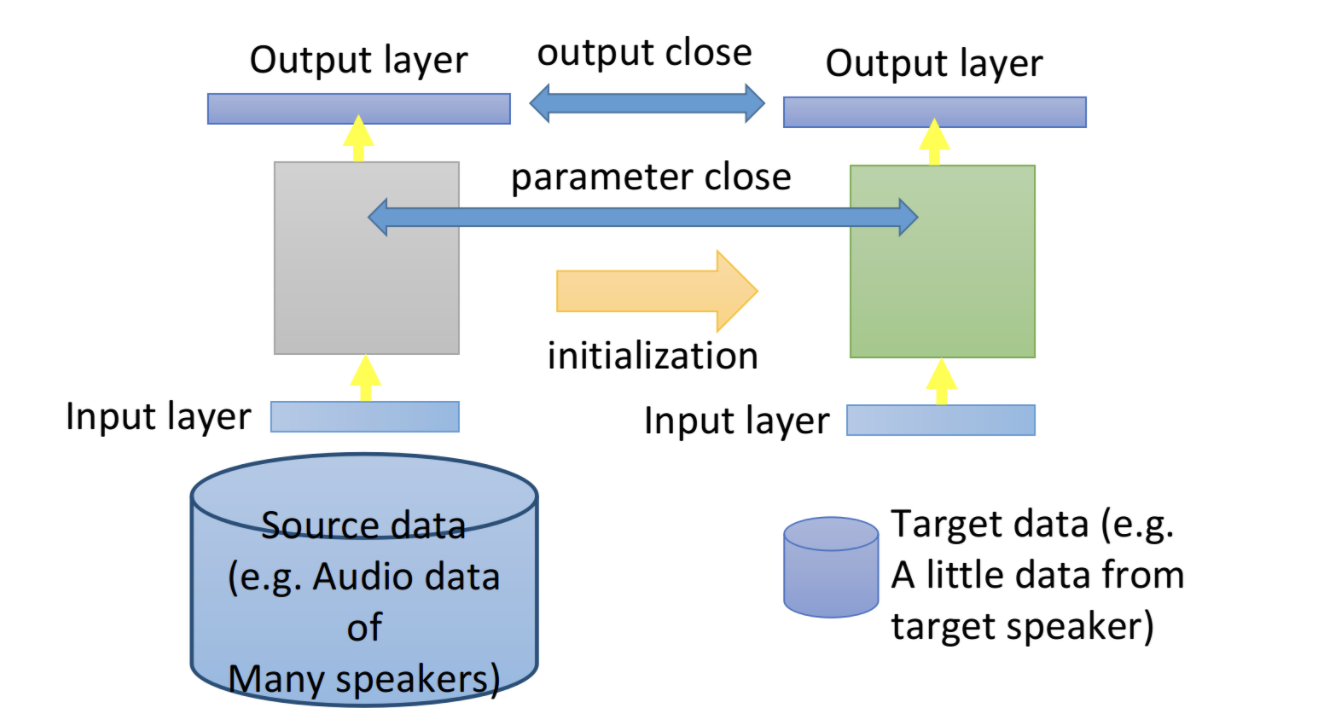
2.1 ajuste fino
La idea del ajuste fino del modelo es entrenar el modelo en los datos de origen y luego ajustarlo en los datos de destino. De esta manera, puede aprender mucho conocimiento de los datos de origen y adaptarse a tareas específicas de los datos de destino. Primero use los datos de origen para entrenar el modelo, luego use los parámetros del modelo para inicializar y luego continúe entrenando en los datos de destino. Cuando los datos de destino son particularmente pequeños, es necesario evitar que el ajuste fino se sobreajuste.
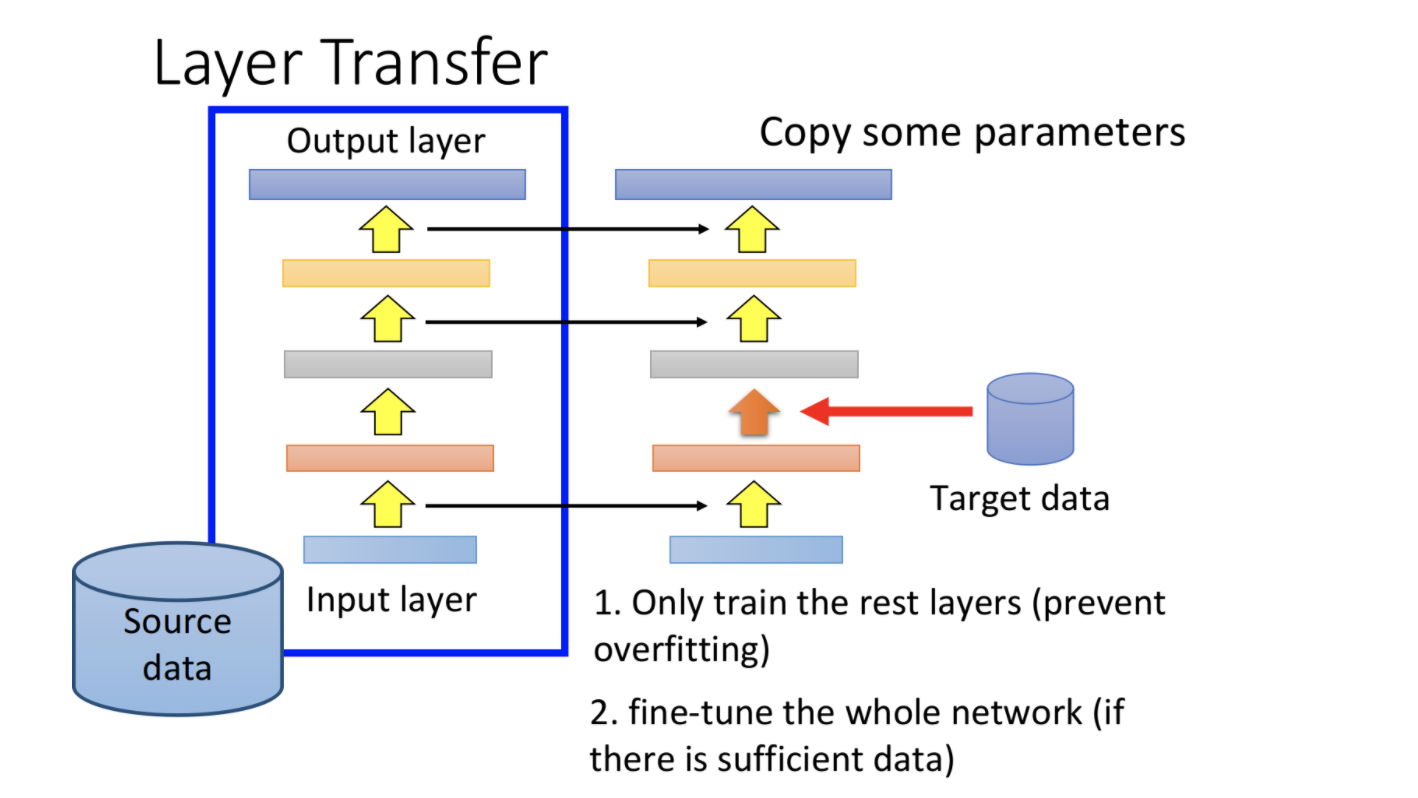
transferencia de capa
Cuando los datos del objetivo son particularmente pequeños, el ajuste fino también puede sobreajustarse. Puede utilizar la transferencia de capas en este momento.
- Primero use los datos de origen para entrenar un modelo
- Luego copie algunas capas del modelo directamente en el modelo de destino.
- Luego, use los datos de destino para entrenar las capas restantes del modelo de destino, y la capa copiada previamente puede congelarse y vivir
En este momento, solo se necesitan algunas capas del modelo de entrenamiento y el sobreajuste no es tan propenso.
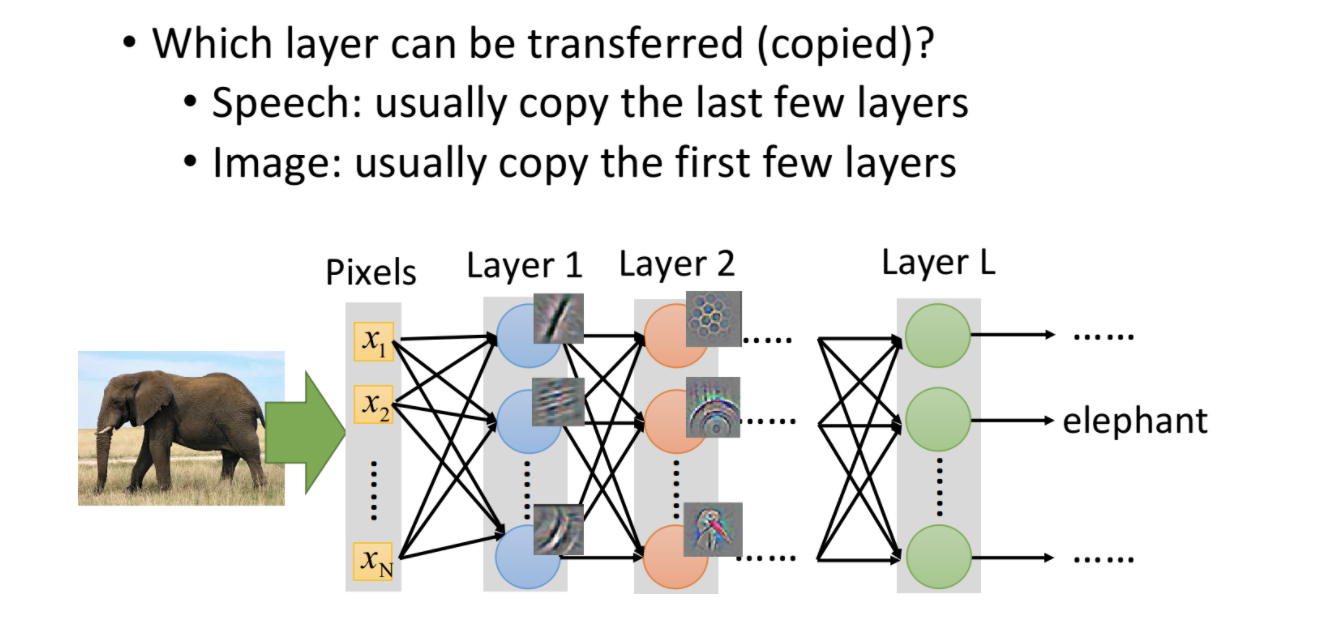
Entonces, la pregunta ahora es qué capas deben copiarse directamente y cuáles deben ajustarse. Esto debe basarse en diferentes tareas.
- En el reconocimiento de voz, las últimas capas generalmente se copian directamente y las primeras capas de ajuste fino se copian. Esto se debe a que la pronunciación de diferentes personas, debido a la diferente estructura oral, las características de bajo nivel son bastante diferentes, mientras que las características de alto nivel como la semántica y los modelos de lenguaje son similares.
- En la tarea de imagen, las primeras capas generalmente se copian directamente y las siguientes capas de ajuste fino se copian. Esto se debe a que las características de bajo nivel, como la iluminación y las sombras en la imagen, generalmente tienen poca diferencia, mientras que las características de alto nivel (como la trompa del elefante) son muy diferentes entre sí.
2.2 aprendizaje multitarea Aprendizaje multitarea
El ajuste fino solo necesita considerar el efecto del modelo en los datos de destino, mientras que el aprendizaje de múltiples tareas requiere que el modelo funcione mejor en la fuente y el destino.
- Si las características de entrada de origen y destino son relativamente similares, las primeras capas se pueden compartir y las últimas capas se pueden procesar por separado en diferentes tareas.
- Si las características de entrada de origen y destino son diferentes, las primeras capas y las últimas capas se pueden separar y compartir las capas intermedias.
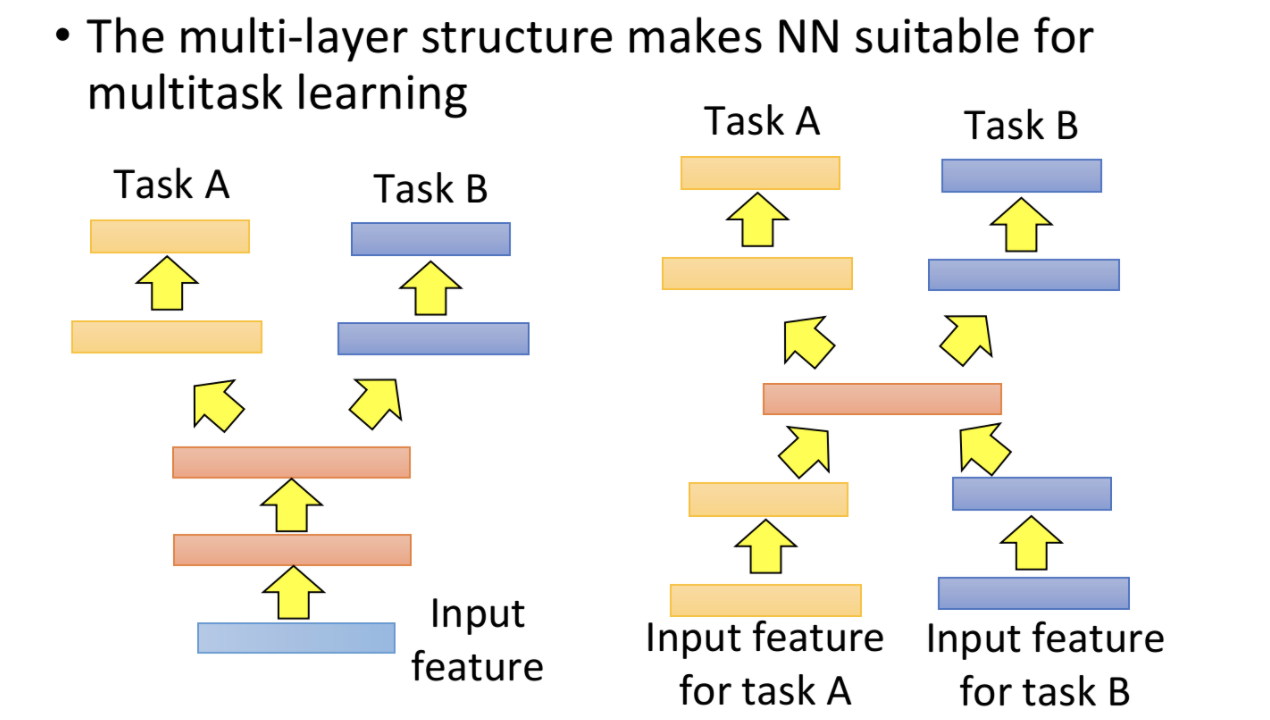
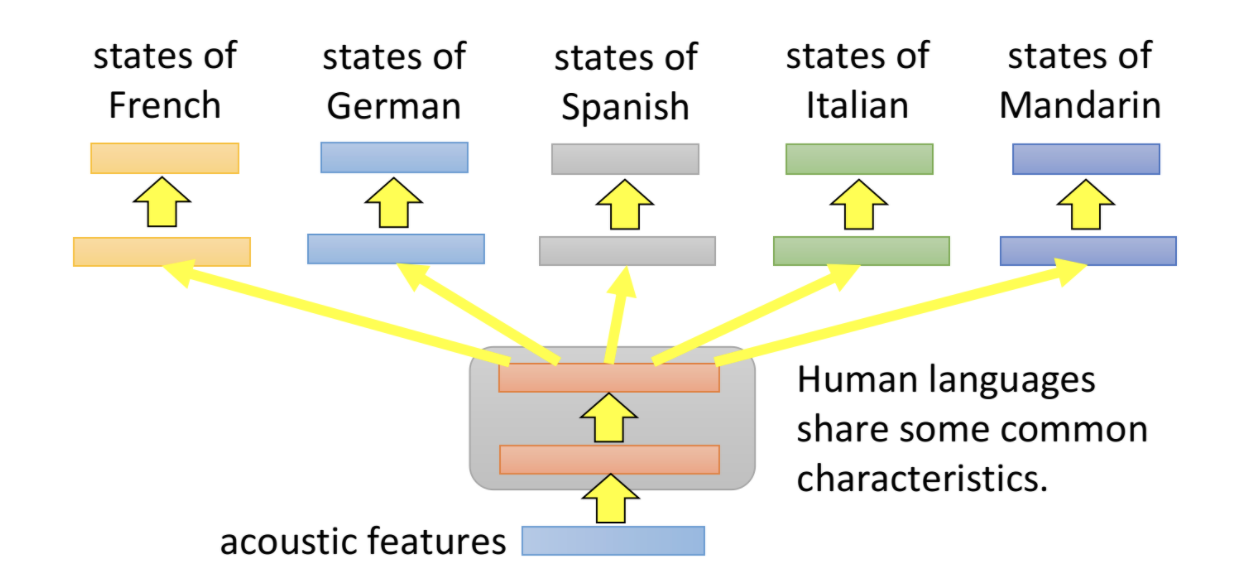
El siguiente es un ejemplo de aprendizaje multitarea en traducción automática.
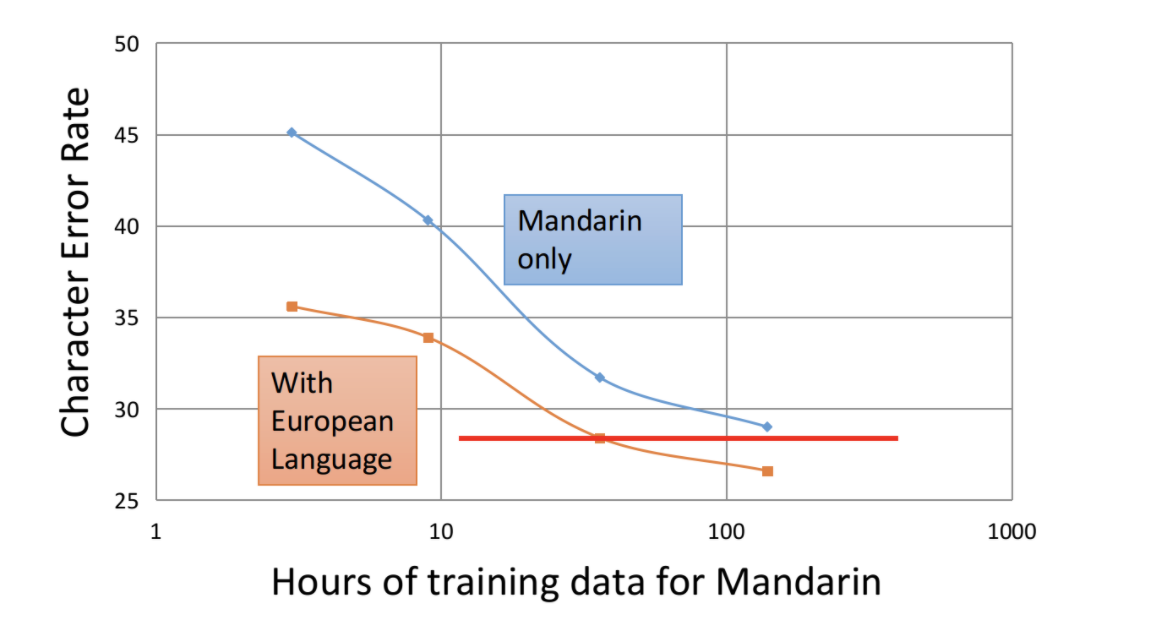
La siguiente figura demuestra que el uso del aprendizaje multitarea puede reducir en gran medida la tasa de error con la misma cantidad de datos. Al mismo tiempo, en el caso de menos de la mitad del volumen de datos, aún se puede lograr el efecto de una sola tarea. Reduce en gran medida la dependencia del modelo de los datos y, al mismo tiempo, mejora el rendimiento del modelo.
3 El destino no tiene etiqueta, pero la fuente tiene una etiqueta
En este momento, puede usar dominios para luchar contra la migración y el aprendizaje de muestra cero.
3.1 Entrenamiento de dominio-adversario
Las primeras capas de la red neuronal se utilizan generalmente para la extracción de características. Las últimas capas implementan las tareas correspondientes, como la clasificación. Nuestro objetivo es que el extractor de características no sea sensible a diferentes datos de dominio, elimine información específica del dominio y mantenga la información común tanto como sea posible.
Como el reconocimiento de escritura a mano sobre fondo blanco y negro y el reconocimiento de escritura a mano sobre fondo de color. Los dos dominios son bastante diferentes y el modelo de origen se usa directamente para predecir los datos de destino y el efecto es muy pobre. Principalmente afectado por diferentes colores de fondo. Necesitamos extractores de funciones que no sean sensibles al fondo y realmente puedan capturar la información común de los números.

Cómo hacer un entrenamiento de confrontación de dominio, puede aprender de la idea de GAN. Como se muestra en la figura siguiente, toda la red consta de tres partes
- Extractor de funciones extractor de funciones. Se utiliza para extraer características de diferentes datos de dominio.
- El predictor de la etiqueta del predictor. Se utiliza para predecir la etiqueta de los datos de origen.
- Clasificador de dominio. Se utiliza para distinguir si los datos provienen del origen o del destino.
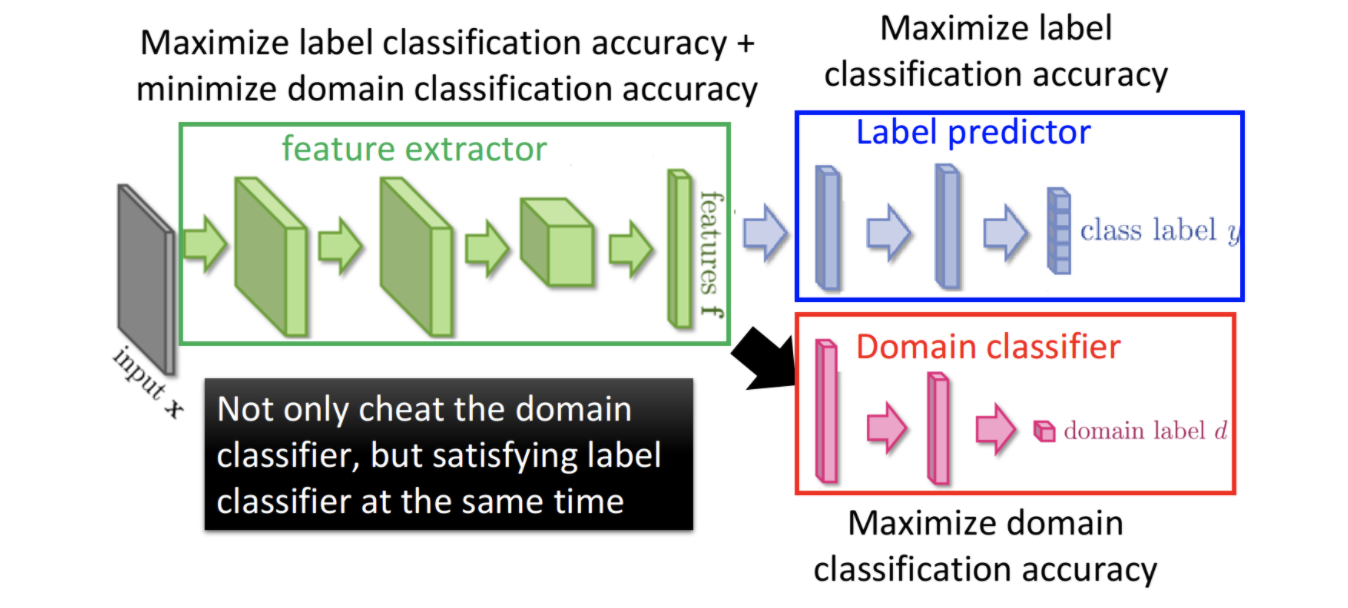
Tenemos dos metas
- Maximice el ACC de la predicción de etiquetas, para garantizar que el efecto del modelo en la tarea real no sea malo
- Minimice el ACC del clasificador de dominio para que el modelo no pueda distinguir de qué dominio provienen los datos. Esto asegura que el extractor de características no sea sensible a diferentes dominios. No extraiga las características privadas del dominio, intente extraer las características comunes de diferentes dominios.
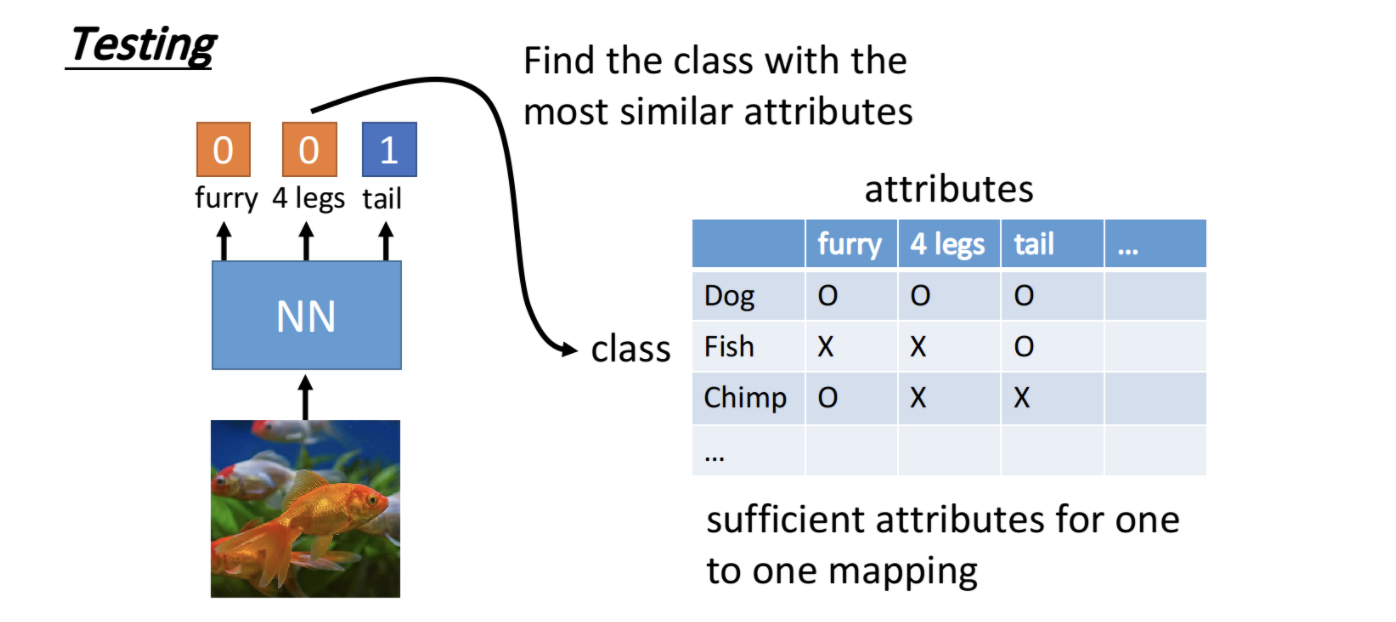
3.2 aprendizaje zero-shot
Por ejemplo, la fuente es clasificar gatos y perros, mientras que los monos aparecen en los datos de destino. Obviamente, es inútil utilizar el modelo fuente directamente, porque incluso falta la etiqueta del mono. En este punto, podemos usar el aprendizaje zero-shot, no aprendiendo directamente la categoría, sino los atributos de la categoría. Por ejemplo, podemos crear una tabla con atributos como el número de patas, si hay colas, si hay cuernos, si hay pelos, etc., y en base a estos atributos se pueden determinar las categorías como gatos, perros y monos. Aprendemos a predecir estos atributos a través de la fuente y luego usamos la tabla de búsqueda de atributos para adivinar qué categoría es.
4 la fuente no tiene etiqueta, el destino tiene etiqueta
En este momento, puede referirse al aprendizaje semi-supervisado, pero todavía hay una gran diferencia con el semi-supervisado. En datos semi-supervisados, hay poca diferencia en el dominio. Nuestro origen y destino aquí tienen una cierta diferencia de dominio. La gran cantidad de datos de origen se puede utilizar para construir tareas de aprendizaje auto-supervisadas para aprender expresiones de características. Algunos ejemplos típicos son varios modelos de preentrenamiento en PNL. Utilice el aprendizaje auto-supervisado para construir Auto-Encoder y entrenar el modelo de preentrenamiento en la fuente. Luego, realice un ajuste fino en la tarea de destino. Ver
Aprendizaje automático 10 - Aprendizaje semi-supervisado
Aprendizaje automático 13: aprendizaje no supervisado autónomo
5 Ni la fuente ni el destino tienen etiqueta
En este momento, es principalmente la categoría de agrupamiento, que generalmente se encuentra menos, por lo que no hablaré de eso.