DDPM: Modelo probabilístico de difusión de eliminación de ruido, modelo de probabilidad de difusión de eliminación de ruido
Referencia en este artículo: Un vídeo para comprender la derivación del principio del modelo de difusión DDPM | Modelo subyacente de pintura de IA_哔哩哔哩_bilibili
1. Principio general
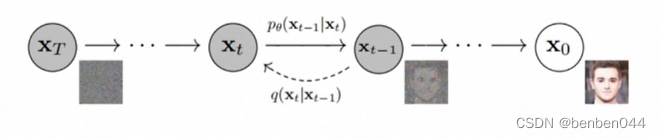
De derecha a izquierda está el proceso de adición de ruido directo y de izquierda a derecha
está el proceso de reducción de ruido inverso.
Continuamente agregando ruido en el proceso de avance, después de T veces , esperamos
De esta manera, durante la inferencia, podemos sacarlo del azar
(agregue ' para indicar que se trata de un valor nuevo).
Si podemos aprender el método de reducción de ruido, finalmente podremos pasar
la nueva imagen.
2. ¿Qué predice el método de reducción de ruido del modelo de difusión?
Ahora es necesario aprender el método de reducción de ruido
. El algoritmo DDPM no es un método para aprender directamente el valor predicho , sino la
distribución de probabilidad condicional
predicha y luego el valor obtenido tomando el valor de la distribución
. Este método es similar al método de predicción profunda en el sentido de que se predicen distribuciones en lugar de valores.
Entonces, ¿por qué predecir distribuciones en lugar de valores exactos?
Debido a que la distribución se puede muestrear , el modelo tiene aleatoriedad.
Además, si lo obtienes , puedes obtenerlo mediante muestreo , para que puedas obtenerlo paso a paso . Por tanto, lo que queremos aprender es la distribución de p, no una gráfica exacta.
Conclusión: Todo el proceso de aprendizaje consiste en predecir la distribución p .
Más adelante veremos que el modelo predice ruido, que no es el ruido entre y , sino el ruido involucrado en el cálculo
de la distribución normal p .
Entonces, lo obtenemos por predicción
y luego obtenemos p. También verificó nuestra conclusión, es decir, todo el proceso de aprendizaje predice la distribución p .
3. Desmontaje de la distribución de probabilidad condicional.
Fórmula 1 :la distribución de probabilidad condicional original se transforma de acuerdo con la fórmula bayesiana y la nueva fórmula contiene 3 distribuciones de probabilidad.
(1) Cálculo de la primera p
La primera p es:
Desde hasta
la distribución de probabilidad en el proceso de agregar ruido, debido a que el proceso de agregar ruido se define de antemano, también se puede definir la distribución de probabilidad p.
Ahora definimos el proceso de rampa de la siguiente manera:
Ecuación 2 :, donde
el ruido,
.
Porque , así es
. (ps: la varianza debe elevarse al cuadrado)
Puede verse como la variación del ruido; debe ser muy pequeña, cercana a 0. Sólo cuando el ruido añadido es pequeño, las direcciones de avance y retroceso obedecen a la distribución normal.
Derivación adicional, a saber:
Fórmula 3: .
(2) Cálculo de la tercera p
La tercera p es: , que es similar a la segunda p. Si encuentra un método de cálculo para uno, entonces el otro se puede obtener de manera similar.
En el paso anterior, obtuvimos la fórmula 2 de cada paso del proceso de agregar ruido y la fórmula 3 de la distribución de probabilidad condicional de cada paso de agregar ruido.
Para el proceso de agregar ruido, se puede
utilizar
.
Transformación de la fórmula 1:
Fórmula 4:
Debido a que el proceso de calentamiento es un proceso de Markov, solo está relacionado con el paso anterior y no tiene nada que ver con el paso anterior, es decir, la suma
no tiene nada que ver, entonces
Se obtiene paso a
paso
, por lo que no es posible una mayor simplificación. Además, la Ecuación 4 se simplifica a:
Fórmula 5 :
Ahora comience a calcular nuevamente el valor de la nueva tercera p y deduzcalo de la fórmula 2 de la siguiente manera (ps: los corchetes indican que algunos parámetros están incluidos pero no escritos, y se omite información sin importancia):
Finalmente, tras una derivación imprecisa, damos el resultado oficial:
Ecuación 6 :, que
representa la multiplicación continua.
(3) Solución de fórmula de difusión
Si se obtuvo en el paso anterior , también se puede obtener de manera similar
.
El resultado oficial de la fórmula 4 se da directamente:
Fórmula 7 :
Entre ellos se encuentra el hiperparámetro,
la fórmula es la siguiente:
Fórmula 8 :
Debido a que es fija,
la tarea de buscar se convierte en búsqueda
.
Si es así , entonces el valor de inferencia previsto se puede obtener de acuerdo con la siguiente fórmula:
Fórmula 9 :,
Si toma uno directamente
, el proceso no se puede derivar (al ingresar directamente el valor medio y el valor de la varianza a través del paquete Python), entonces hay un problema con el proceso inverso, por lo que se puede convertir. a la fórmula 9 a través de la técnica de parámetros pesados.Fórmula guiada para expresar
.
En la etapa de inferencia está el valor que finalmente queremos, el cual se desconoce, por lo que se necesita una fórmula para convertirlo a un factor conocido.
La ecuación 6 se transforma mediante la técnica de parámetros pesados de la siguiente manera:
Fórmula 10 :y luego obtienes:
Fórmula 11 :, donde t es el número actual de etapas de adición de ruido, que cambiarán. Al mismo tiempo, este
es el valor del parámetro del proceso intermedio y no puede usarse como el valor predicho final, porque el proceso p de razonamiento debe seguir el proceso de Markov, por lo que debe derivarse paso a paso
.
En la Fórmula 7, el valor desconocido es , y el valor desconocido en el valor es
, y
el valor desconocido en es
, que no se puede calcular ni derivar mediante fórmulas existentes .
Entonces usamos la red UNet, entrada , salida
.
Sustituyendo la Ecuación 11 en la Ecuación 8, obtenemos:
Ecuación 12 : , donde entre
otras cosas se conocen.
Lo predice la red UNet, que puede expresarse como
un
parámetro del modelo UNet.
*************El proceso del modelo de difusión para obtener la imagen predicha a través de la red UNet*************** :
Lo anterior es la lógica más importante del modelo de difusión DDPM .
4. Entrenamiento modelo
Según la Ecuación 12, se puede ver que la red UNet está entrenada con ruido normalmente distribuido .
Pregunta 1: ¿Cuál es la entrada y la salida durante el entrenamiento del modelo?
Respuesta: entrada , salida
.
Pregunta 2: Entonces, ¿qué proceso realiza el entrenamiento de los parámetros de la red UNet?
Respuesta: el proceso de adición de ruido. El proceso de eliminación de ruido es la fase de entrenamiento y el proceso de eliminación de ruido es la fase de inferencia.
De acuerdo con la fórmula 2, el ruido del proceso de adición de ruido está definido por la implementación, por lo que podemos comparar el ruido predicho y la
divergencia KL real para calcular el valor de pérdida. En la descripción oficial, la fórmula de divergencia KL se puede simplificar para calcular el dos El valor mse de un valor.
Pregunta 3: ¿Se deduce paso a paso durante el entrenamiento?
Respuesta: No es necesario. Durante el proceso de entrenamiento , según la fórmula 10 ,
se puede calcular mediante
,,, estos cuatro valores.
Puede calcularse de antemano y almacenarse en la memoria,
que es el conjunto de imágenes de entrada,
el ruido de entrada
y el número de etapas que agregan ruido.
Por lo tanto, cada paso en la dirección de avance puede obtener directamente el valor.
5. Implementación de pseudocódigo de entrenamiento e inferencia.
(1) Etapa de formación

Interpretación:
Representa tomar fotografías del conjunto de datos.
Indica que se seleccionan aleatoriamente varias etapas de adición de ruido. Como se mencionó anteriormente, no es necesario realizar el proceso de adición de ruido paso a paso.
para
(2) Etapa de razonamiento

Interpretación:
Significa que el proceso inverso debe realizarse paso a paso.
El cálculo complejo del paso 4 corresponde a la Ecuación 9, y la primera fórmula del cálculo corresponde a la Ecuación 12.