Introducción a los modelos de generación de imágenes.
En el campo de la generación de imágenes, existen cuatro modelos generativos principales: modelo generativo adversario (GAN), codificador automático variacional (VAE), modelo basado en flujo y modelo de difusión.
A partir de 2022, el principal modelo de generación de imágenes popular será el Modelo de Difusión.
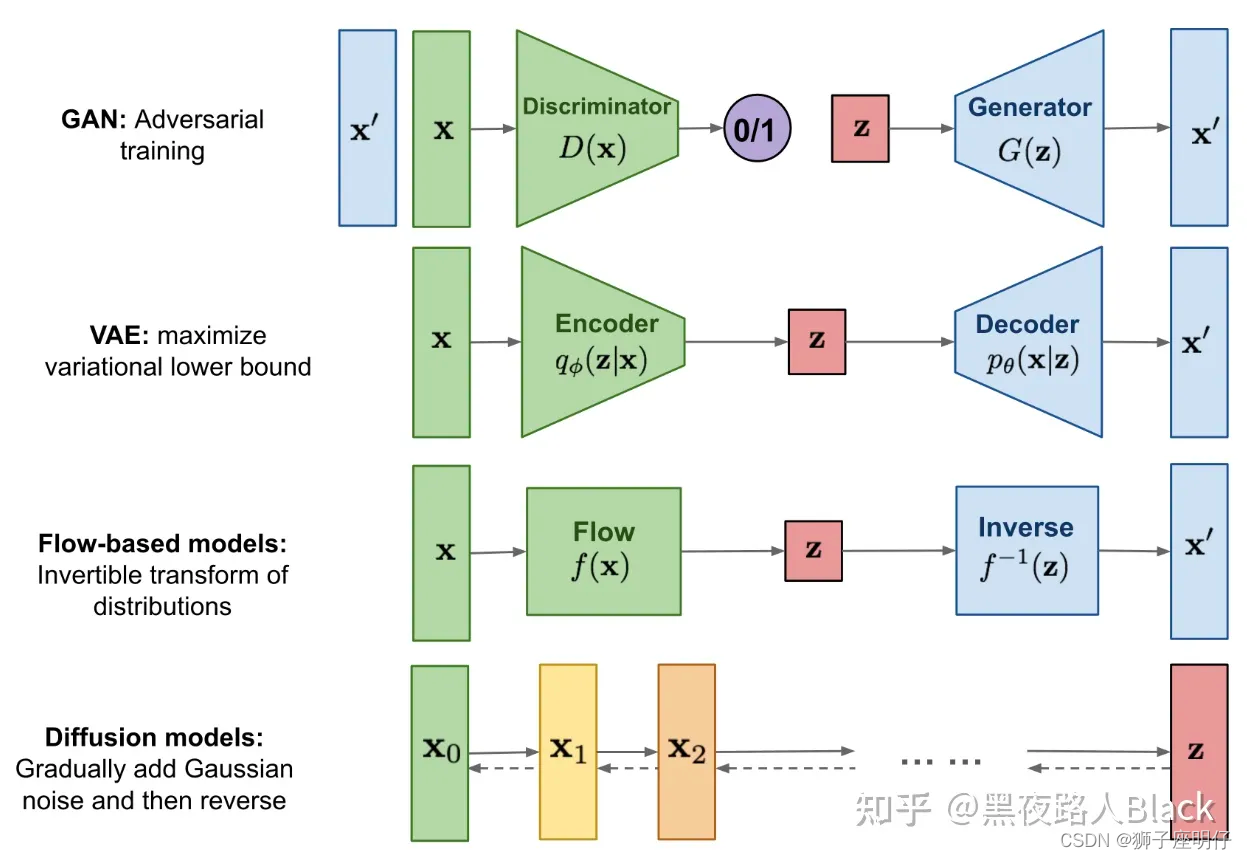
Modelo de Difusión: Modelo de Difusión. El núcleo de la actual generación de imágenes DALL-E, Midjourney y Difusión Estable es el Modelo de Difusión. Es un modelo de generación que espera obtener buenos resultados eliminando constantemente el ruido.

El modelo de difusión inicial no funcionó bien en la pintura con IA y tardó entre 10 y 15 minutos en generar una sola imagen. Más tarde, la compañía británica Stability AI mejoró el modelo y lo abrió, lo que mejoró en gran medida la estabilidad y la calidad de la generación de imágenes. y la velocidad de generación de imágenes se ha mejorado 100 veces, lo que significa que solo se necesitan de 6 a 10 segundos para generar una imagen, lo que antes tomaba de 10 a 15 minutos (600 a 900 segundos).
Antes de la aparición de Difusión estable (modelo de difusión estable), existía un modelo de difusión estable (Difusión latente), que era el modelo texto2imagen en el artículo de Difusión latente.
Modelo de difusión latente: el modelo de difusión latente es una variante del modelo de difusión. La mayor diferencia es que comprime y reduce la dimensión de la imagen. El espacio comprimido se llama espacio latente (espacio latente o espacio latente), que puede reducir en gran medida los cálculos. Con esta tecnología podemos generar imágenes en GPU normales. Además, el modelo Difusión no sólo puede generar imágenes, sino también audio y vídeo.

Stability Al mejora la difusión latente y el nuevo modelo se llama Difusión estable. Las mejoras incluyen:
(1) Datos de entrenamiento: la difusión latente se entrena con datos de laion-400M, mientras que la difusión estable se entrena con el conjunto de datos laion-2B.en. Obviamente, este último usa más datos de entrenamiento y el segundo también usa filtrado de datos para mejorar la calidad de los datos. como eliminar imágenes con marcas de agua y seleccionar imágenes con puntuaciones estéticas más altas
(2) codificador de texto: la difusión latente utiliza un transformador inicializado aleatoriamente para codificar el texto, mientras que la difusión estable utiliza un codificador de texto CLIP previamente entrenado para codificar el texto. Los modelos de texto previamente entrenados suelen ser mejores que los modelos entrenados desde cero.
(3) Tamaño de entrenamiento: la difusión latente solo se entrena con una resolución de 256x256, mientras que la difusión estable se entrena previamente con una resolución de 256x256 y luego se ajusta con precisión en una resolución de 512x512.
Resumen: la difusión estable utiliza un mejor codificador de texto para entrenar en un conjunto de datos más grande y puede generar imágenes de mayor resolución, por lo que el efecto de generación de imágenes actual de la difusión estable es mejor.
Proceso de razonamiento de difusión estable.

Proceso de razonamiento más detallado:
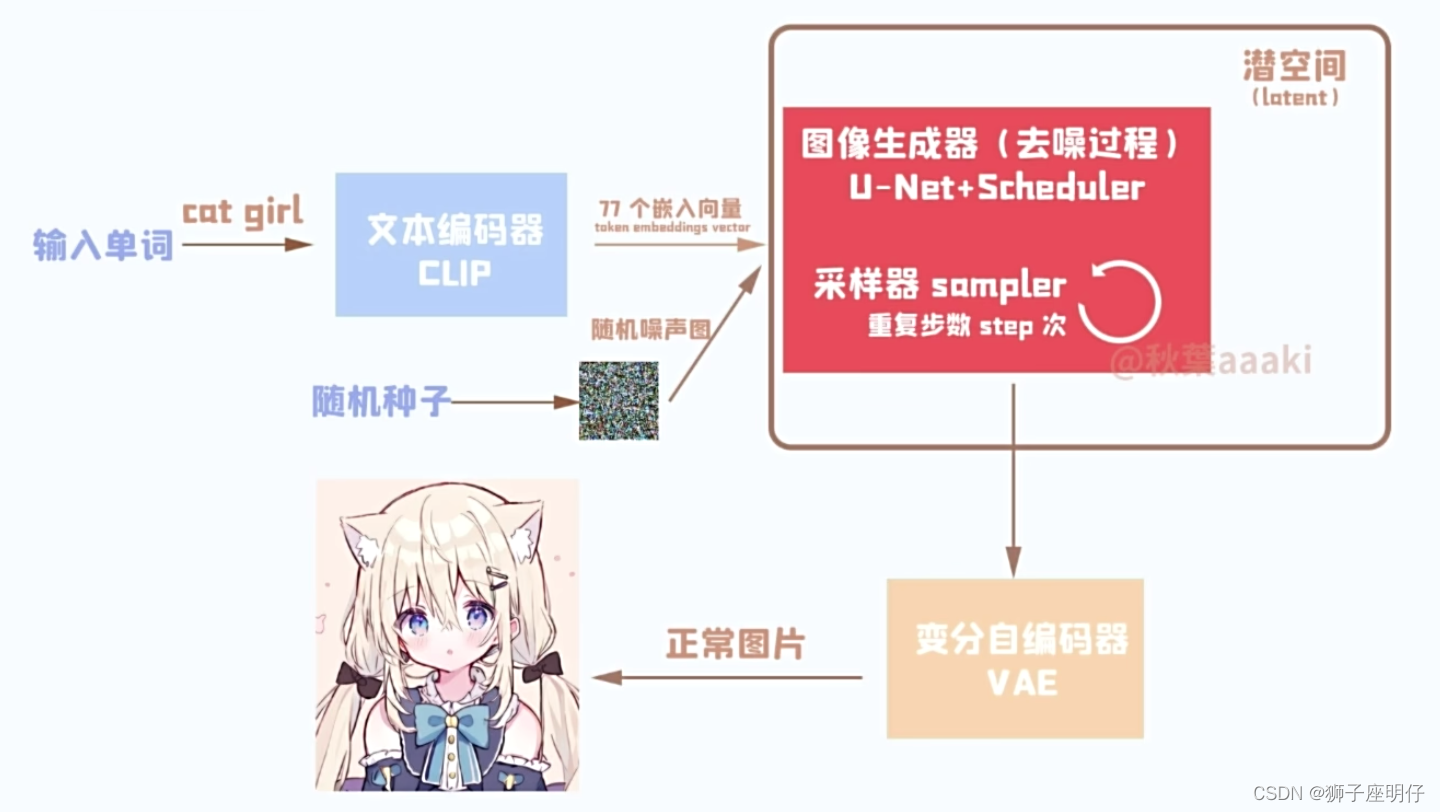
Descripción: texto rápido (niña gato) -> CLIP -> incrustación de texto -> difusión (U-Net + Scheduler) -> VAE -> generar imagen
El mecanismo de trabajo subyacente de la difusión estable.
Paso 1. Ingrese la palabra solicitada y analice la palabra solicitada: CLIP del codificador de imagen de texto
Paso 2. Generar representación de imágenes basada en la representación de palabras rápidas: proceso de difusión basado en U-Net (U-Net + Scheduler)
Paso 3. Procesamiento y conversión de entrada y salida de imágenes: VAE (el decodificador de imágenes es responsable de la generación de imágenes desde el espacio latente al espacio de píxeles)
Los principios de cada paso se analizan a continuación.
ACORTAR
CLIP (Preentrenamiento de lenguaje-imagen contrastante): modelo de preentrenamiento para aprendizaje contrastivo de imágenes y texto

CLIP no comprende completamente la semántica, solo piensa en una manera de hacer coincidir texto e imágenes:
La codificación de texto como incrustación de texto es solo un producto intermedio de CLIP.
Conjunto de entrenamiento CLIP:

Conjunto de entrenamiento: 400 millones de pares de imagen y texto (400 millones)
proceso de entrenamiento
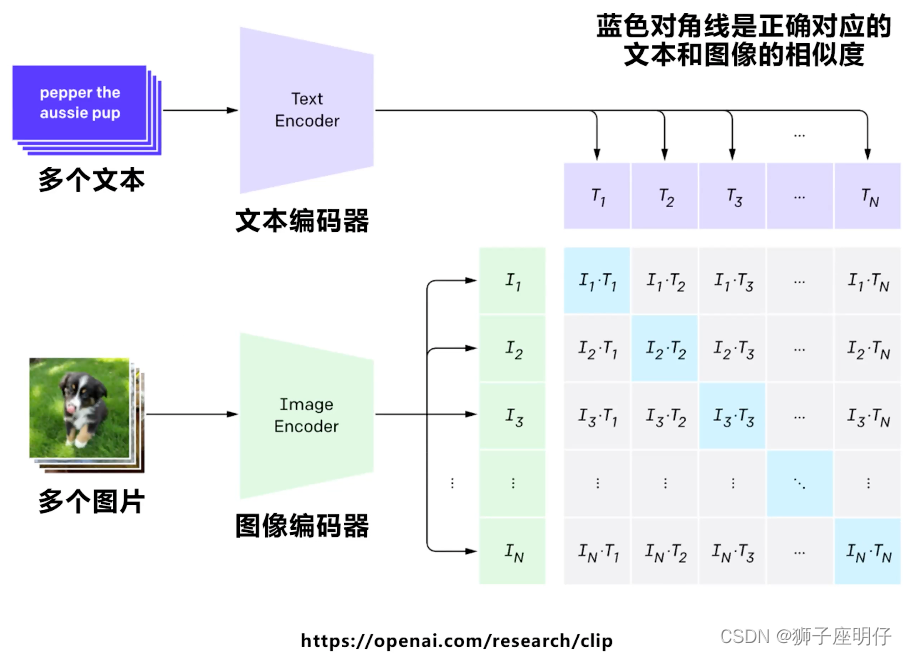
En el aprendizaje contrastivo en el mismo lote, las líneas diagonales son muestras positivas y las demás son muestras negativas. El objetivo de entrenamiento de CLIP es maximizar la similitud de N muestras positivas y minimizar la similitud de N ^ 2 - N muestras negativas.
Se espera que a través del aprendizaje contrastivo, el modelo pueda aprender la relación de coincidencia entre pares texto-imagen: pares sinónimos imagen-texto tendrán una puntuación alta y diferentes pares imagen-texto tendrán una puntuación baja.
En pocas palabras: consiste en colocar texto e imágenes en un espacio matricial para resolver el mapeo y la intersección de similitud de texto con imágenes, a fin de facilitar la búsqueda de la distribución de las imágenes correspondientes a través del texto.
Truco: cuanto mayor sea el lote, mejor será el efecto del entrenamiento.

¿Qué tamaño se necesita para un modelo CLIP?
论文:《Modelos fotorrealistas de difusión de texto a imagen con comprensión profunda del lenguaje》
documento: https://arxiv.org/abs/2205.11487

Descripción: Puntuación FID↓ CLIP ↑
Aumentar el tamaño del codificador del modelo de lenguaje mejora la alineación imagen-texto más que aumentar el tamaño del modelo de difusión de imágenes.
FID (Distancia de inicio de Fréchet)
artículo: https://arxiv.org/abs/1706.08500

FID mide la distancia entre la distribución de características (se supone que es una distribución gaussiana) de la imagen real y la imagen generada. Requiere muchas distribuciones de características (FID-10K son imágenes de 10K). Cuanto menor sea la puntuación FID, mejor. lo que significa que la imagen generada se parece más a la imagen real.
Modelo de difusión
Implementar DDPM (Modelos Probabilísticos de Difusión Denoising) basados en la idea de Modelo de Difusión.
DDPM aprende el proceso de eliminación de ruido agregando continuamente ruido a los datos para convertirlos en ruido real, y eliminando continuamente el ruido real y restaurándolo a los datos originales. Luego puede muestrear aleatoriamente el ruido real y restaurarlo (generarlo) en varias formas. variedad de datos.

El proceso directo (también llamado proceso de difusión) se refiere al proceso de agregar gradualmente ruido gaussiano a los datos hasta que los datos se conviertan en ruido aleatorio.
El proceso inverso es un proceso de eliminación de ruido. Si conocemos la distribución real de cada paso del proceso inverso, entonces comenzar desde un ruido aleatorio y eliminar gradualmente el ruido puede generar una muestra real, por lo que el proceso inverso El proceso es el proceso de generación de datos.
¿Por qué añadir ruido? ¿Por qué añadir ruido paso a paso?
1) La eliminación directa de píxeles provocará la pérdida de información y agregar ruido puede permitir que el modelo aprenda las características de la imagen;
2) El ruido aleatorio también puede aumentar la diversidad de generación de modelos;
3) Este proceso se puede controlar paso a paso mientras se proporciona estabilidad durante el proceso de eliminación de ruido.
¿Cuánto ruido se debe agregar en cada paso?
Esto se basa en el cronograma. Generalmente, es mejor comenzar con menos y luego con más. Las características de la imagen se irán perdiendo lentamente.

El proceso de eliminación de ruido se puede comparar con la escultura: Miguel Ángel dijo: La estatua está originalmente en la piedra, sólo elimino las partes innecesarias.
¿Como entrenar?
Agregue directamente ruido aleatorio a la imagen en pasos. Este proceso se llama proceso de difusión (también llamado proceso directo, adición de difusión/ruido). Cada paso tiene una imagen real del terreno y el modelo de entrenamiento restaura la imagen.
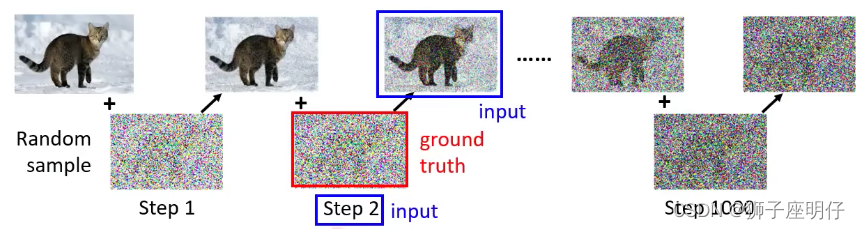
El proceso de restauración de imágenes:

1) Ingrese la imagen original (cubriendo el ruido del paso = 50) y el paso = 50, y use U-Net para predecir el ruido de la imagen. Cada paso aquí comparte el mismo U-Net.
2) Cuando hay mucho ruido, U-Net no puede predecir detalles precisos de la imagen, solo puede predecir el contorno aproximado del modelo.

3) Repetir la predicción de esta forma hasta obtener la imagen original.
El proceso real de adición de ruido de DDPM no requiere procesamiento paso a paso. El ruido gaussiano del paso especificado se puede agregar en el lugar de una vez y luego el ruido se puede predecir paso a paso.
论文:《Modelos probabilísticos de difusión y eliminación de ruido》
artículo: https://arxiv.org/abs/2006.11239

论文:《Comprensión de los modelos de difusión: una perspectiva unificada》
artículo: https://arxiv.org/abs/2208.11970
Esquema de muestreo de ruido.
El gran proceso del modelo de difusión radica en el muestreo del ruido. El muestreo del modelo debe comenzar a partir de imágenes de ruido puro y eliminar el ruido continuamente paso a paso para finalmente obtener una imagen clara. En este proceso, el modelo debe calcular al menos de 50 a 100 pasos en serie para obtener una imagen de mayor calidad, lo que hace que el tiempo necesario para generar una imagen sea de 50 a 100 veces mayor que el de otros modelos de generación profunda, lo que limita en gran medida el despliegue del modelo. e implementación.
Estos procesos de muestreo se asignan a Stable Diffusion principalmente como Programadores. La función principal del Programador en Stable Diffusion es generar los coeficientes de generación de ruido de imagen de acuerdo con el paso actual (Paso) de generación de ruido. Es una fórmula de cálculo simple. Es: (Ruido de imagen = ruido generado aleatoriamente * coeficiente de salida del programador).
Según los requisitos impulsores de frecuencia y velocidad de muestreo, el modelo de difusión es muy importante para agregar esquemas de muestreo de ruido y eliminación de ruido, incluidos DDPM, DDIM, PLMS, DPM-Solver, etc.
DDPM (modelo probabilístico de difusión de eliminación de ruido) utiliza un esquema de muestreo de ruido lineal (programa lineal) de forma predeterminada.
DDIM (Modelos implícitos de difusión de eliminación de ruido), DDIM y DDPM tienen los mismos objetivos de entrenamiento, pero ya no restringen el proceso de difusión a una cadena de Markav, lo que permite a DDIM utilizar una cantidad menor de pasos de muestreo para acelerar el proceso de generación, otra característica de DDIM es que el proceso de generación de muestras a partir de ruido aleatorio es un proceso determinista.
DPM-Solver (Solver de modelo de proceso de difusión) es propuesto por el equipo TSAIL dirigido por el profesor Zhu Jun de la Universidad de Tsinghua. Es un solucionador eficiente especialmente diseñado para modelos de difusión: este algoritmo no requiere ningún entrenamiento adicional y es aplicable tanto para discretos En los modelos de difusión de tiempo y tiempo continuo, la convergencia se puede lograr en 20 a 25 pasos, y el muestreo de muy alta calidad se puede obtener en sólo 10 a 15 pasos. En Difusión estable, la velocidad de muestreo se duplica.
Se agrega incrustación de texto al proceso de generación de imágenes.

1) Para incorporar funciones de texto, U-Net agrega un mecanismo de atención (QKV) a la estructura de la red.
![]()
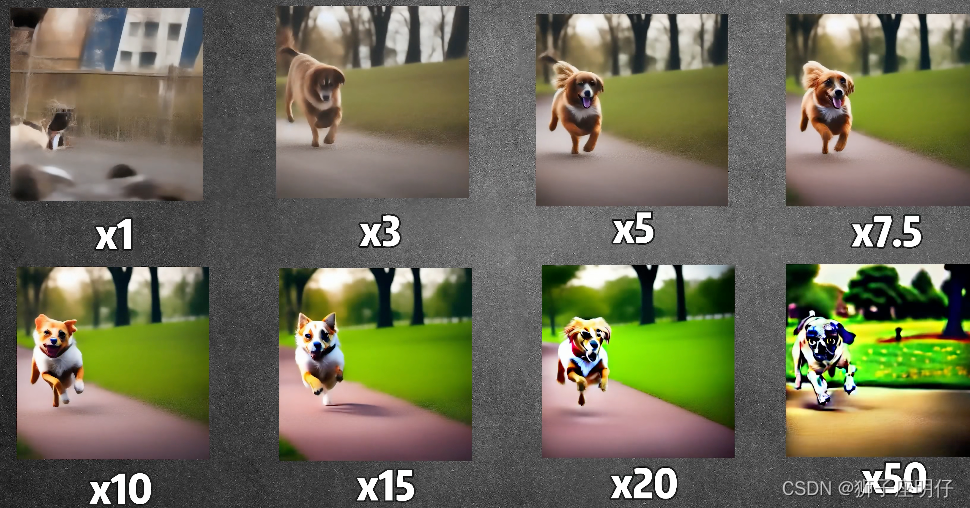
2) Para fortalecer el efecto de guía del texto, aquí se utiliza el método de guía libre de clasificador, el parámetro 7.5 aquí es la escala de guía.
Efectos de imagen de diferentes escalas de orientación:
El núcleo del modelo de difusión es entrenar el modelo de predicción de ruido . Dado que el ruido y los datos originales tienen la misma dimensión, podemos optar por utilizar la arquitectura AutoEncoder como modelo de predicción de ruido. El modelo utilizado por DDPM es un modelo U-Net basado en bloque residual y bloque de atención.
Unet es un modelo propuesto en "U-Net: Redes convolucionales para la segmentación de imágenes biomédicas" en 2015.
UNet es un modelo de segmentación semántica y su proceso de ejecución es:
Primero, se utiliza la convolución para reducir la resolución y luego se extraen capa tras capa de características, utilizando capa tras capa de características se realiza una ampliación de resolución y finalmente se obtiene una imagen en la que cada píxel corresponde a su tipo.
Estructura de red U-Net:
Ventajas de Unet:
1. El mapa de características obtenido de la capa de red más profunda tiene un campo de visión más amplio;
2. La convolución superficial se centra en las características de textura, mientras que las redes profundas se centran en las características esenciales, por lo que tanto las características profundas como las superficiales son significativas;
3. Los bordes de los mapas de características más grandes obtenidos mediante deconvolución carecen de información. Después de todo, cada vez que la reducción de resolución refina las características, algunas características de los bordes inevitablemente se perderán y las características perdidas no se pueden muestrear a mayor velocidad. Por lo tanto, la recuperación de las características de los bordes se logra mediante el empalme de características;
4. Unet es simple, eficiente, fácil de entender y fácil de construir, se puede construir a partir de pequeños conjuntos de datos y es simple y fácil de usar en modelos de difusión.
PIES
El papel de VAE: fácil de usar, puede interpolar y operar en espacio latente y controlar la generación de imágenes

El codificador y decodificador aquí no reducen ni amplían la imagen, sino que la codifican. Por ejemplo, la música se codifica en partituras y luego la música se reproduce a través de la partitura. Esto se puede comparar con la codificación del sonido en partituras.
Estructura de VAE

Durante el entrenamiento del codificador, VAE aprende cómo asignar los datos de entrada a una distribución de probabilidad en el espacio latente minimizando el error de reconstrucción.
Durante el entrenamiento del decodificador, VAE aprende cómo generar datos sin procesar a partir de vectores aleatorios en el espacio latente minimizando la divergencia KL.
VAE vs modelo de difusión:

El codificador de VAE aprende una distribución de probabilidad, por lo que VAE también puede muestrear y generar imágenes aleatoriamente, pero el efecto de restauración de imágenes de VAE es muy débil, la imagen generada es borrosa y el efecto no es tan bueno como el modelo de difusión.
Beneficios de VAE : reducción del tiempo de entrenamiento e inferencia, reducción de los requisitos de hardware de GPU
La imagen original es 512x512x3-> comprimida a 64x64x4. La difusión estable utiliza el VAE de KL-f8 y el coeficiente de reducción de resolución es 8, que se reduce 48 veces.

Desventajas de VAE : si comprime y luego restaura, se perderán los detalles de la imagen.
Estructura de difusión estable

Difusión latente的论文:《Síntesis de imágenes de alta resolución con modelos de difusión latente》
documento: https://arxiv.org/abs/2112.10752
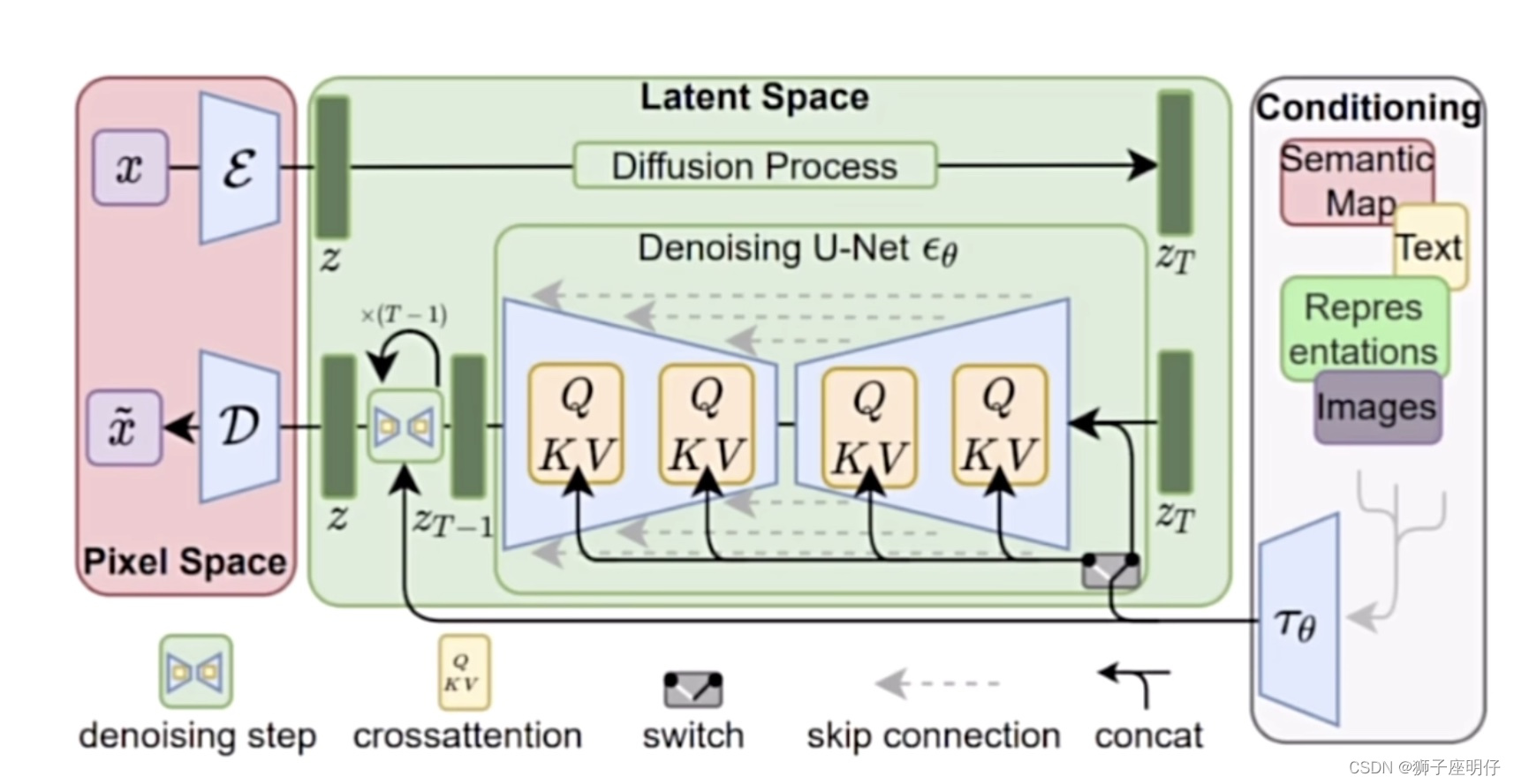
Explicación dividida:
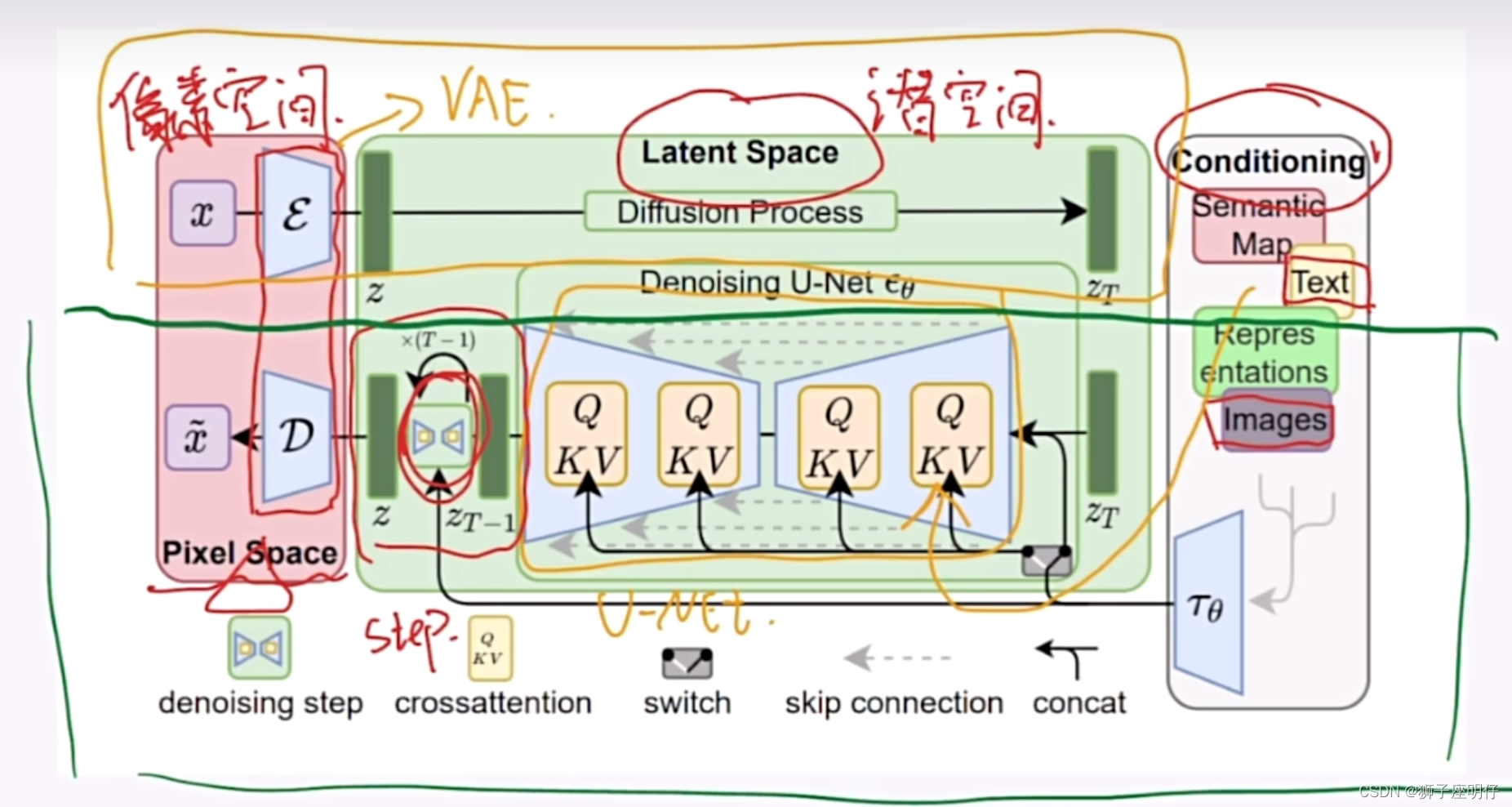
El marco general de los modelos de difusión latente es como se muestra en la figura. Primero, debe entrenar un modelo de codificación automática (AutoEncoder, que incluye un codificador E y un decodificador D). De esta manera, podemos usar el codificador para comprimir la imagen y luego realizar una operación de difusión en el espacio de representación potencial. Finalmente, podemos usar el decodificador para restaurar el espacio de píxeles original. El artículo llama a este método compresión perceptiva (compresión) .
Método de control de difusión estable.
Inversión textual
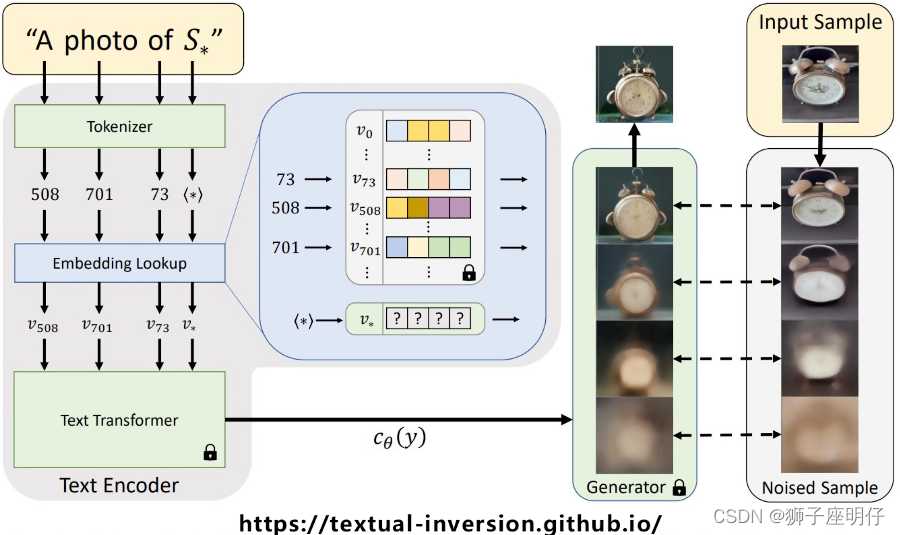
Ajuste CLIP para que genere características de texto que coincidan con nuevas imágenes, como el despertador con campana binaural y Ultraman Tiga. Solo necesita guardar las características aprendidas.
ControlNet

Entrene una nueva red para ajustar el bloque resnet de U-Net. Esta nueva red puede ingresar imágenes utilizadas como condiciones de control, como dibujos lineales astutos, diagramas de esqueleto, etc.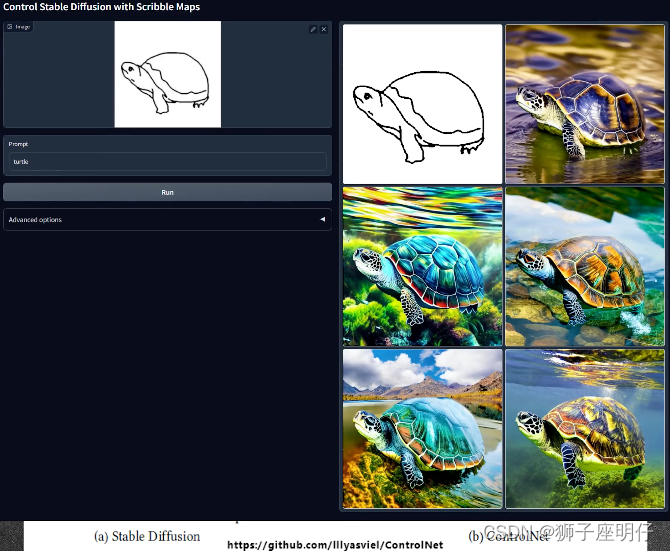
en conclusión
El modelo de difusión es diferente de los mecanismos de modelos de generación comunes como GAN, VAE y Flow en el pasado. Gradualmente "muestrea" una distribución especial del ruido gaussiano de acuerdo con ciertas condiciones. A medida que aumenta el número de rondas de "muestreo", Finalmente se genera la imagen. En otras palabras, el proceso de síntesis del modelo de difusión consiste en extraer la imagen requerida del ruido mediante iteración tras iteración. A medida que aumenta el número de pasos de iteración, la calidad de la síntesis es cada vez mejor.
Los beneficios de este mecanismo son obvios, ya que la relación entre la calidad de la síntesis y la velocidad de la síntesis se vuelve controlable. Cuando hay tiempo suficiente, se pueden obtener muestras sintéticas de alta calidad mediante iteraciones de rondas altas, mientras que la síntesis rápida en rondas más bajas también puede producir muestras sintéticas sin defectos evidentes. No es necesario volver a entrenar el modelo entre iteraciones altas y bajas, y solo es necesario ajustar manualmente algunos parámetros relacionados con la ronda.
Esto suena un poco extraño, pero detrás de esto hay una fuerte lógica matemática. Estas matemáticas son principalmente la cadena de Markov y la fórmula de Langevin.
referencias
Inglés
Documento de difusión latente: https://arxiv.org/pdf/2112.10752.pdf
Fórmula detallada de los modelos de difusión: ¿ Qué son los modelos de difusión? | Lil'Log
Comparación de varios métodos de ajuste del modelo: https://www.youtube.com/watch?v=dVjMiJsuR5o
El cuadro comparativo del programador proviene del artículo: https://arxiv.org/pdf/2102.09672.pdf
Fuente del diagrama de estructura de VAE: https://towardsdatascience.com/vae-variational-autoencoders-how-to-employ-neural-networks-to-generate-new-images-bdeb216ed2c0
El diagrama del corgi proviene del artículo DALLE2: https://cdn.openai.com/papers/dall-e-2.pdf
Introducción al modelo CLIP: https://github.com/openai/CLIP
OpenCLIP: https://github.com/mlfoundations/open_clip
Inversión textual: una imagen vale más que una palabra: personalización de la generación de texto a imagen mediante la inversión textual
Documento LoRA: https://arxiv.org/pdf/2106.09685.pdf
Documento de Dreambooth: https://arxiv.org/pdf/2208.12242.pdf
Documento de ControlNet: https://arxiv.org/pdf/2302.05543.pdf
Explicación simple y fácil de entender del Modelo de Difusión: https://www.youtube.com/watch?v=1CIpzeNxIhU
Más información sobre Difusión estable: La difusión estable ilustrada – Jay Alammar – Visualización del aprendizaje automático, un concepto a la vez.
También excelente SD explicada: https://medium.com/@steinsfu/stable-diffusion-clearly-explained-ed008044e07e
Documento GLIDE: https://arxiv.org/abs/2112.10741
GUÍA DE DIFUSIÓN SIN CLASIFICADOR 论文: https://arxiv.org/pdf/2207.12598.pdf
Chino
Estructura UNET de difusión estable: Estructura UNET de difusión estable - Zhihu
Experiencia en la aplicación LoRA: ¿ Realmente sabes cómo utilizar LORA? Explicación súper detallada del control jerárquico LORA - Zhihu
Gran explicación de la difusión estable: modelo de difusión [Traducción]_Blog de Yu Jianmin-Blog de CSDN
Una introducción muy detallada a Stable Diffusion: [Original] Un artículo extenso de 10,000 palabras que explica los principios técnicos básicos de la pintura de IA de Stable Diffusion - Zhihu
Explicación relacionada con el modelo de difusión: https://www.youtube.com/watch?v=hO57mntSMl0