La última capacidad de generación de imágenes demostrada por el modelo de IA supera con creces las expectativas de las personas. Puede crear imágenes con efectos visuales sorprendentes directamente basándose en descripciones de texto. El mecanismo operativo detrás de esto parece muy misterioso y mágico, pero afecta la forma en que los humanos crean. arte Camino.
La última capacidad de generación de imágenes demostrada por el modelo de IA supera con creces las expectativas de las personas. Puede crear imágenes con efectos visuales sorprendentes directamente basándose en descripciones de texto. El mecanismo operativo detrás de esto parece muy misterioso y mágico, pero afecta la forma en que los humanos crean. arte Camino.
El lanzamiento de Stable Diffusion es un hito en el desarrollo de la generación de imágenes de IA. Equivale a proporcionar al público un modelo utilizable de alto rendimiento. No solo la calidad de la imagen generada es muy alta, sino que también funciona rápido. Bajos requisitos de recursos y memoria.
Creo que cualquiera que haya probado la generación de imágenes con IA querrá saber cómo funciona. Este artículo revelará el misterio de cómo funciona Stable Diffusion para usted.

La difusión estable incluye principalmente dos aspectos en términos de función:
1) Su función principal es generar imágenes basadas únicamente en mensajes de texto como entrada (text2img);
2) También puede usarlo para modificar imágenes según descripciones de texto (es decir, ingresar como texto + imagen).

A continuación se utilizarán ilustraciones para ayudar a explicar los componentes de Stable Diffusion, cómo interactúan entre sí y el significado de las opciones y parámetros de generación de imágenes.
Componente de difusión estable
Stable Diffusion es un sistema compuesto por múltiples componentes y modelos, no un solo modelo.
Cuando miramos dentro del modelo desde la perspectiva del modelo en su conjunto, podemos encontrar que contiene un componente de comprensión de texto para traducir información de texto a una representación numérica para capturar la información semántica en el texto.

Aunque todavía estamos analizando el modelo desde una perspectiva macro, y habrá más detalles del modelo más adelante, también podemos especular aproximadamente que este codificador de texto es un modelo de lenguaje Transformer especial (específicamente, el codificador de texto del modelo CLIP ) .
La entrada del modelo es una cadena de texto y la salida es una lista de números utilizados para representar cada palabra/token en el texto, es decir, cada token se convierte en un vector.
Luego, esta información se envía al generador de imágenes, que también contiene múltiples componentes.

El generador de imágenes consta principalmente de dos etapas:
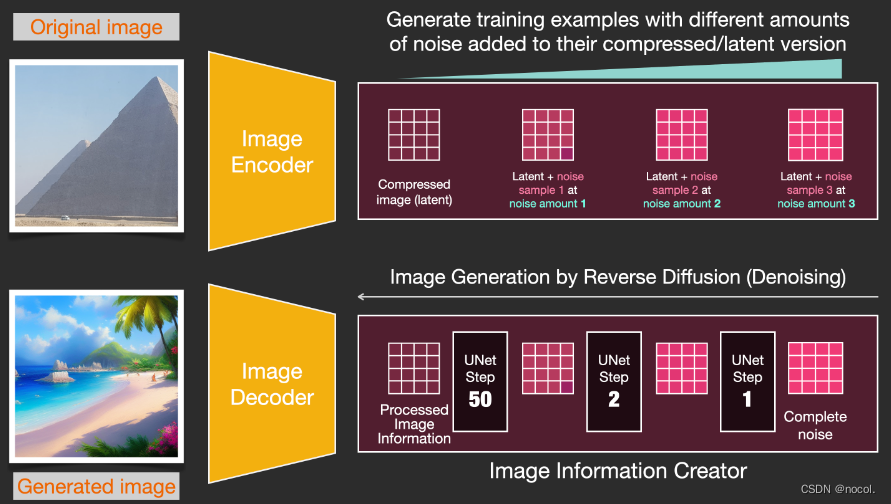
1. Creador de información de imágenes
Este componente es la salsa secreta exclusiva de Stable Diffusion y muchas de sus mejoras de rendimiento en comparación con modelos anteriores se logran aquí.
Este componente ejecuta varios pasos para generar información de imagen, donde los pasos también son parámetros en la interfaz y biblioteca de Stable Diffusion, generalmente con un valor predeterminado de 50 o 100 .
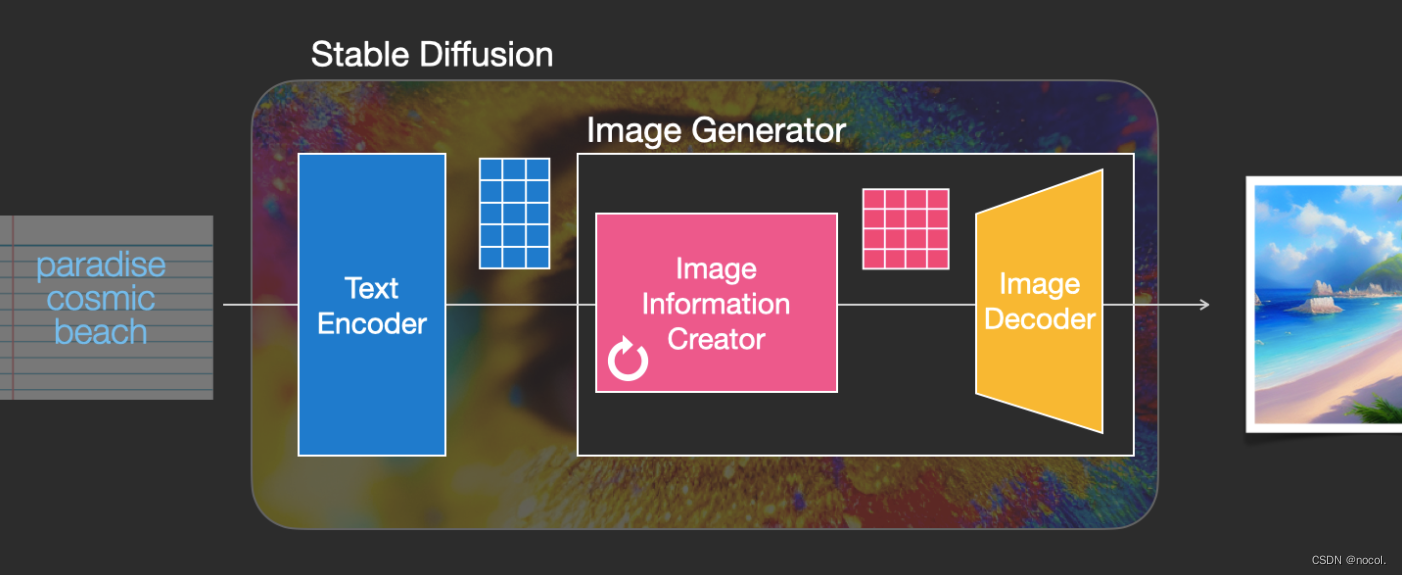
El creador de información de imagen opera completamente en el espacio de información de la imagen (o espacio latente), una característica que lo hace funcionar más rápido que otros modelos de Difusión que funcionan en el espacio de píxeles; técnicamente, este componente consta de una red neuronal UNet y un algoritmo de programación compuesto .
La palabra difusión describe lo que sucede durante el funcionamiento interno de este componente, es decir, la información se procesa paso a paso y finalmente el siguiente componente (el decodificador de imágenes) genera una imagen de alta calidad.
2. Decodificador de imágenes
El decodificador de imágenes dibuja una imagen basándose en la información obtenida del creador de información de la imagen, y todo el proceso se ejecuta solo una vez para generar la imagen de píxeles final.

Como puedes ver, Stable Diffusion contiene un total de tres componentes principales , cada uno de los cuales tiene una red neuronal independiente:
1) Clip Text se utiliza para la codificación de texto.
Texto de entrada
Salida: 77 vectores de incrustación de tokens, cada uno de los cuales contiene 768 dimensiones
2) UNet + Scheduler procesa/difunde gradualmente información en el espacio de información (latente).
Entrada: incrustación de texto y una matriz multidimensional inicial de ruido (lista estructurada de números, también llamada tensor).
Salida: una serie de información procesada.
3) Autoencoder Decoder , un decodificador que utiliza la matriz de información procesada para dibujar la imagen final.
Entrada: matriz de información procesada con dimensiones (4, 64, 64)
Salida: Imagen resultante, cada dimensión es (3, 512, 512), es decir (rojo/verde/azul, ancho, alto)

¿Qué es la difusión?
La difusión es un proceso que ocurre en el componente creador de información de la imagen rosa en la figura siguiente. El proceso incluye la incrustación del token que representa el texto de entrada y la matriz de información de la imagen inicial aleatoria (también llamada latente). Este proceso también necesitará usar Decodificador de imágenes para dibujar la matriz de información de la imagen final.

Todo el proceso de ejecución es paso a paso y en cada paso se agregará información más relevante.
Para obtener una sensación más intuitiva de todo el proceso, puede mirar la matriz latente aleatoria hasta la mitad y observar cómo se convierte en ruido visual, donde se realiza la inspección visual a través del decodificador de imágenes.

Todo el proceso de difusión contiene múltiples pasos, cada uno de los cuales opera en función de la matriz latente de entrada y genera otra matriz latente para adaptarse mejor al "texto de entrada" y la "información visual" obtenida del conjunto de imágenes del modelo.

Visualizar estos latentes le permite ver cómo se suma esta información en cada paso.
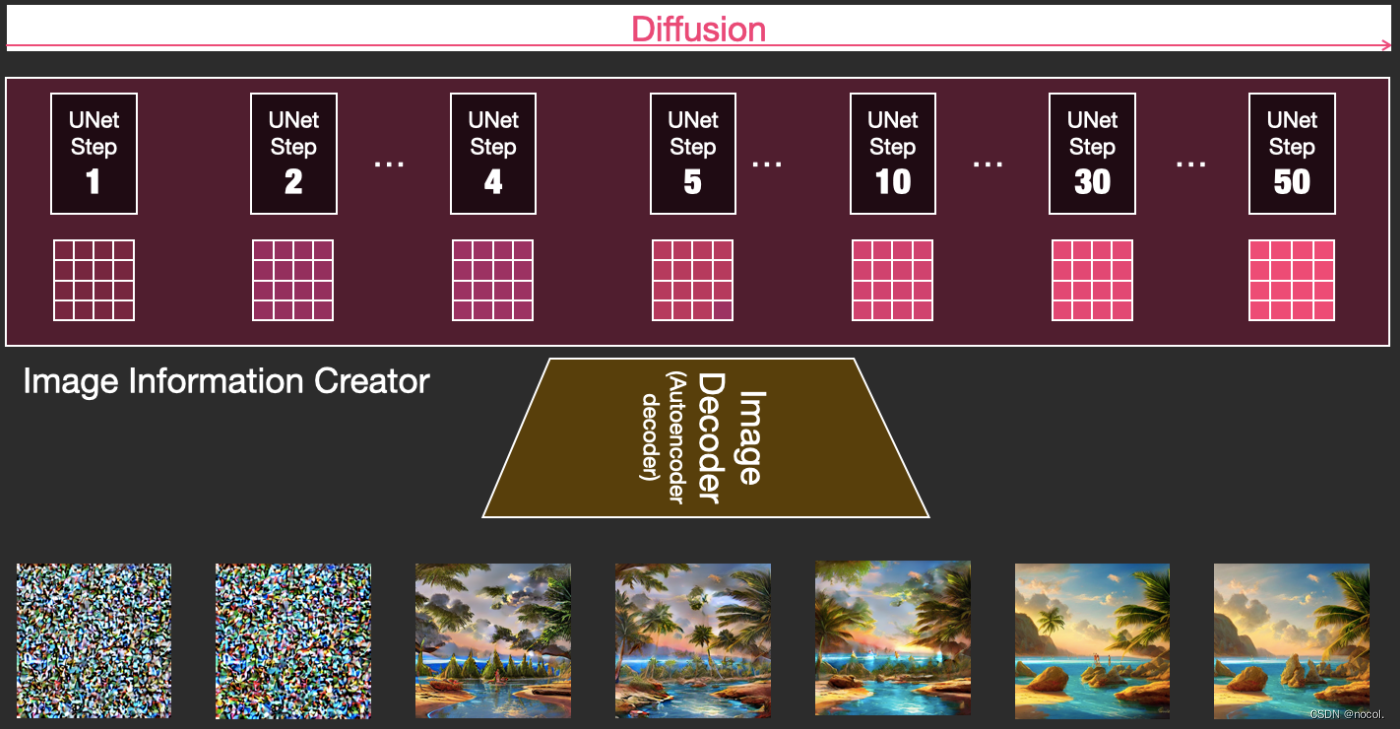
Todo el proceso es desde cero, lo que parece bastante emocionante.
https://jalammar.github.io/images/stable-diffusion/diffusion-steps-all-loop.webm
La transición del proceso entre los pasos 2 y 4 parece especialmente interesante, como si los contornos de la imagen emergieran del ruido.
Cómo funciona la difusión
Un modelo de difusión es un modelo generativo que se utiliza para generar datos similares a los datos de entrenamiento. En pocas palabras, los modelos de difusión funcionan agregando iterativamente ruido gaussiano para "corromper" los datos de entrenamiento y luego aprenden cómo eliminar el ruido para restaurar los datos.
Un modelo de difusión estándar tiene dos procesos principales: difusión directa y difusión inversa.
En la etapa de difusión directa, la imagen se destruye introduciendo ruido gradualmente hasta que la imagen se convierte en ruido completamente aleatorio.
En la etapa de retrodifusión, se utilizan una serie de cadenas de Markov para eliminar gradualmente el ruido de predicción y recuperar los datos del ruido gaussiano.
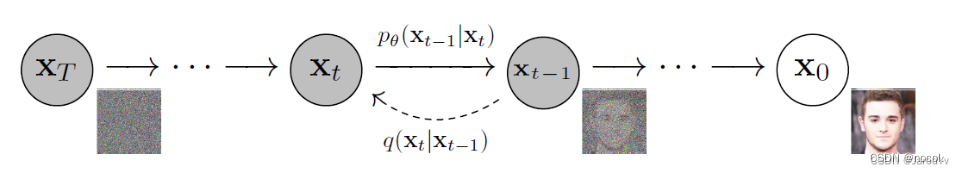
Cadena de Markov del proceso de difusión directa (inversa) de muestras generadas al agregar (eliminar) ruido lentamente (Crédito de la imagen: Jonathan Ho, Ajay Jain, Pieter Abbeel. 2020)
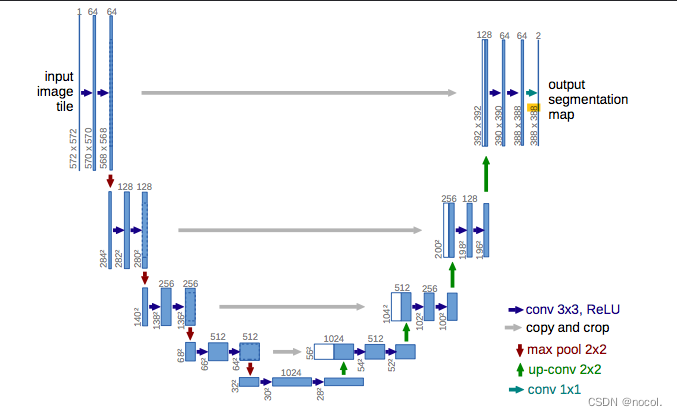
Para la estimación y eliminación de ruido, se utiliza más comúnmente U-Net. La arquitectura de esta red neuronal se parece a la letra U, de ahí su nombre. U-Net es una red neuronal convolucional totalmente conectada, lo que la hace muy útil para el procesamiento de imágenes. La característica de U-Net es que puede tomar una imagen como entrada y encontrar una representación de baja dimensión de esa imagen reduciendo el muestreo, lo que la hace más adecuada para procesar y encontrar atributos importantes, y luego restaurar la imagen aumentando muestreo.
Específicamente, la llamada eliminación de ruido es la transformación del período de tiempo t al período de tiempo t − 1, donde t es cualquier período de tiempo entre t 0 (sin ruido) y t_{max} (ruido completo). Las reglas de transformación son:
- Ingrese una imagen en el período de tiempo t, y hay un ruido específico en la imagen en este período de tiempo;
- Utilice U-Net para predecir la cantidad total de ruido;
- Luego se elimina "parte" del ruido total de la imagen del período de tiempo t, y se obtiene la imagen del período de tiempo t − 1 con menos ruido.

Matemáticamente hablando, tiene más sentido realizar este método anterior T veces en lugar de intentar eliminar todo el ruido. Al repetir este proceso, el ruido se va eliminando poco a poco y conseguimos una imagen "más limpia". Por ejemplo, para imágenes con ruido, agregamos ruido completo a la imagen inicial y luego lo eliminamos iterativamente para generar una imagen sin ruido. El efecto es mejor que eliminar directamente el ruido de la imagen original.
En los últimos años, los modelos de difusión han mostrado un rendimiento sobresaliente en tareas de generación de imágenes y han reemplazado a las GAN en muchas tareas, como la síntesis de imágenes. Dado que el modelo de difusión es capaz de mantener la estructura semántica de los datos, no se ve afectado por el colapso del esquema.
Sin embargo, existen algunas dificultades a la hora de implementar un modelo de difusión. Debido a que todos los estados de Markov deben mantenerse en la memoria para la predicción, esto significa que se deben mantener en la memoria múltiples instancias de redes grandes y profundas, lo que hace que el modelo de difusión consuma mucha memoria. Además, los modelos de difusión pueden quedar atrapados en complejidades imperceptiblemente finas en los datos de imágenes, lo que hace que los tiempos de entrenamiento sean demasiado largos (de días a meses). Paradójicamente, la generación de imágenes de grano fino es una de las principales ventajas de los modelos de difusión y no podemos evitar esta "dulce molestia". Debido a que el modelo de difusión tiene requisitos computacionales muy altos, el entrenamiento requiere cantidades muy grandes de memoria y energía, lo que hizo imposible para la mayoría de los investigadores implementar el modelo en la realidad.
Difusión estable
El mayor problema del modelo de difusión es que es extremadamente "caro" tanto en tiempo como en costes económicos. La aparición de la Difusión Estable tiene como objetivo resolver los problemas anteriores. Si queremos generar una imagen de tamaño 1024 × 1024 1024, U-Net utilizará ruido de tamaño 1024 × 1024 1024 y luego generará la imagen a partir de él. La cantidad de cálculo necesaria para realizar la difusión en un solo paso aquí es muy grande, sin mencionar la necesidad de iterar varias veces hasta alcanzar el 100%. Una solución es dividir una imagen grande en varias imágenes de menor resolución para el entrenamiento y luego usar una red neuronal adicional para generar una imagen de mayor resolución (difusión de superresolución).
El modelo de difusión latente lanzado en 2021 ofrece un enfoque diferente. El modelo de Difusión Latente no opera directamente sobre la imagen, sino en el espacio latente. Al codificar los datos originales en un espacio más pequeño, U-Net puede agregar y eliminar ruido en la representación de baja dimensión (el principio central de la difusión estable es la difusión latente).
La idea central de utilizar modelos de difusión para generar imágenes todavía se basa en potentes modelos de visión por computadora existentes: siempre que se ingrese un conjunto de datos lo suficientemente grande, estos modelos pueden aprender operaciones arbitrariamente complejas.
Supongamos que ya tenemos una imagen , generamos algo de ruido y lo agregamos a la imagen, y luego tratamos la imagen como un ejemplo de entrenamiento.
Los ejemplos de entrenamiento se generan generando ruido y agregando una cierta cantidad de ruido al conjunto de datos de entrenamiento (difusión directa)
Utilizando la misma operación, se puede generar una gran cantidad de muestras de entrenamiento para entrenar los componentes centrales en el modelo de generación de imágenes.

El ejemplo anterior muestra una serie de niveles de ruido seleccionables, que van desde la imagen original (nivel 0, sin ruido) hasta todo el ruido agregado (nivel 4), lo que facilita el control de cuánto ruido se agrega a la imagen.
De modo que podemos distribuir este proceso en docenas de pasos y generar docenas de muestras de entrenamiento para cada imagen del conjunto de datos.

Con base en el conjunto de datos anterior, podemos entrenar un predictor de ruido con un rendimiento excelente . Cada paso de entrenamiento es similar al entrenamiento de otros modelos. Cuando se ejecuta en una determinada configuración, el predictor de ruido puede generar imágenes.
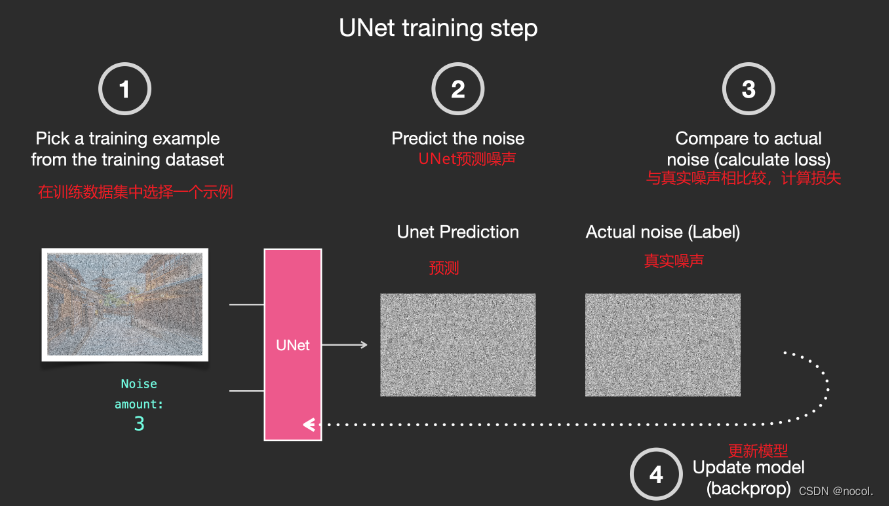
Eliminar ruido y dibujar imágenes.
Un predictor de ruido capacitado puede eliminar el ruido de una imagen con ruido agregado y también puede predecir la cantidad de ruido agregado.
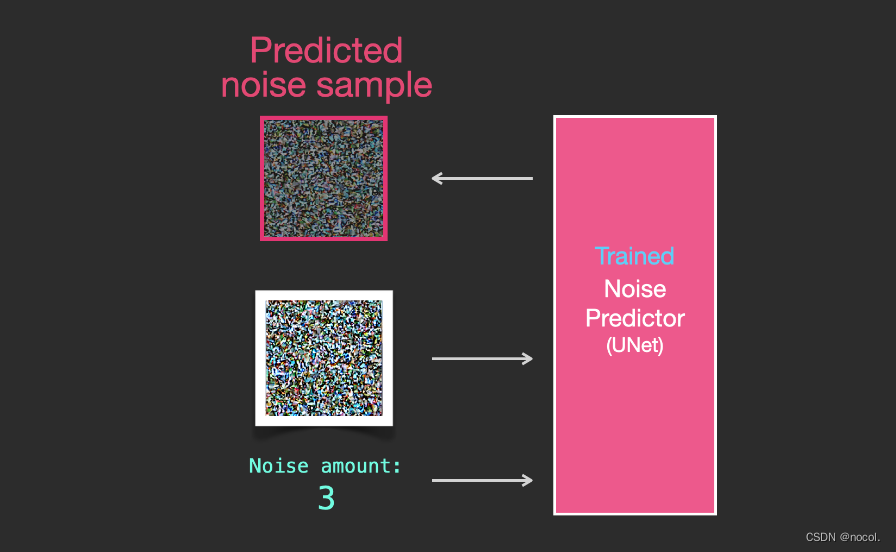
Dado que el ruido de las muestras es predecible, si el ruido se resta de la imagen, la imagen final estará más cerca de la imagen con la que se entrenó el modelo.
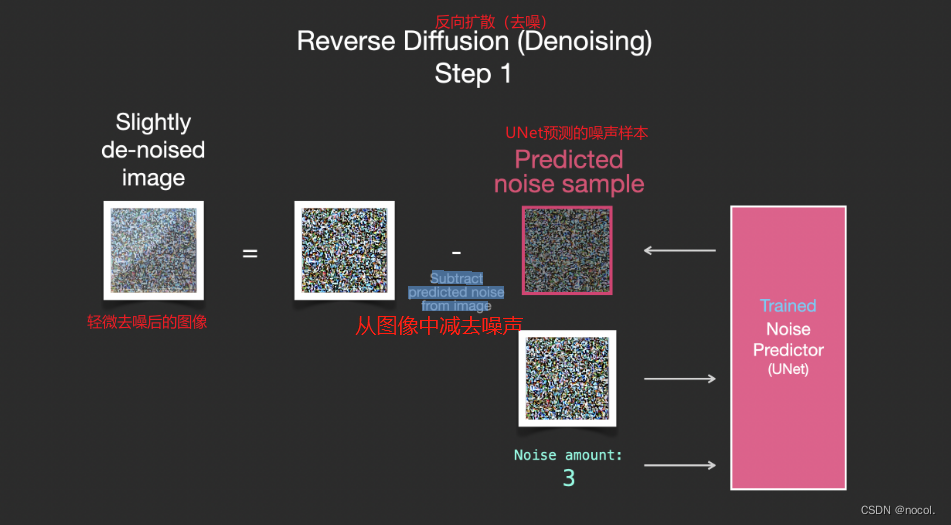
La imagen resultante no es una imagen original exacta, sino una distribución, es decir, la disposición de los píxeles en el mundo. Por ejemplo, el cielo suele ser azul, las personas tienen dos ojos, los gatos tienen orejas puntiagudas, etc. La imagen específica generada El estilo depende completamente del conjunto de datos de entrenamiento.
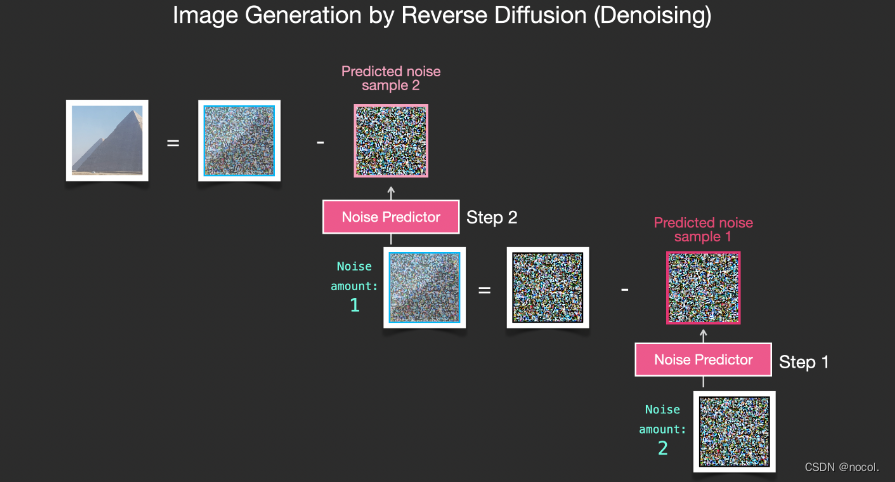
No solo Stable Diffusion realiza la generación de imágenes mediante eliminación de ruido, sino también DALL-E 2 y el modelo Imagen de Google.
Es importante señalar que el proceso de difusión descrito hasta ahora no utiliza ningún dato de texto para generar imágenes . Entonces, si implementamos este modelo, puede generar imágenes atractivas, pero el usuario no tiene forma de controlar lo que se genera.
En las siguientes secciones, describimos cómo incorporar texto condicional en el proceso para controlar el tipo de imágenes generadas por el modelo.
Aceleración: Difusión de datos comprimidos
Espacio latente
El espacio latente es simplemente una representación de datos comprimidos. La compresión se refiere al proceso de codificar información con menos bits que la representación original. Por ejemplo, utilizamos un canal de color (negro, blanco y gris) para representar una imagen originalmente compuesta de tres colores primarios RGB. En este momento, el vector de color de cada píxel cambia de 3 dimensiones a 1 dimensión. La reducción de dimensionalidad perderá algo de información, pero en algunos casos, la reducción de dimensionalidad no es algo malo. Mediante la reducción de dimensionalidad, podemos filtrar información menos importante y retener solo la información más importante.
Supongamos que entrenamos un modelo de clasificación de imágenes a través de una red neuronal convolucional completamente conectada. Cuando decimos que el modelo está aprendiendo, queremos decir que está aprendiendo las propiedades específicas de cada capa de la red neuronal, como bordes, ángulos, formas, etc... Siempre que el modelo aprende usando datos (imágenes ya existentes), la imagen se reduce primero y luego se restaura al tamaño original. Finalmente, el modelo utiliza un decodificador para reconstruir la imagen a partir de los datos comprimidos mientras aprende toda la información relevante previa. Por tanto, el espacio se hace más pequeño para poder extraer y retener los atributos más importantes. Por eso el espacio latente es adecuado para los modelos de difusión.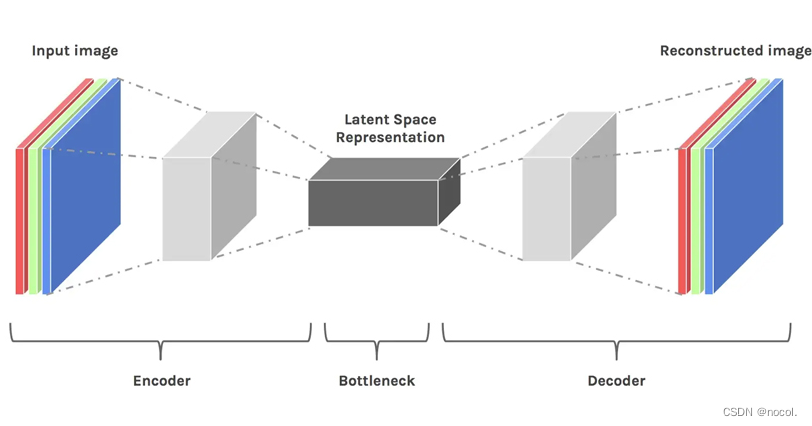
Hay dos etapas principales en cualquier método de aprendizaje generativo: compresión perceptiva y compresión semántica:
En la etapa de aprendizaje de compresión perceptiva, el método de aprendizaje debe eliminar detalles de alta frecuencia para encapsular los datos en una representación abstracta. Este paso es necesario para construir una representación estable y sólida del medio ambiente. Las GAN destacan en la compresión perceptual, que logran proyectando datos redundantes de alta dimensión desde el espacio de píxeles a un hiperespacio de espacio latente. Un vector latente en el espacio latente es una forma comprimida de la imagen de píxeles original y puede reemplazar efectivamente la imagen original.
Más específicamente, la compresión perceptiva se captura utilizando una arquitectura Auto Encoder. El codificador de un codificador automático proyecta datos de alta dimensión en un espacio latente y el decodificador recupera la imagen del espacio latente.
compresión semántica
En la segunda etapa de aprendizaje, el método de generación de imágenes debe ser capaz de capturar la estructura semántica presente en los datos. Esta estructura conceptual y semántica garantiza la preservación del contexto y las interrelaciones de varios objetos en la imagen. Transformer es bueno para capturar estructuras semánticas en texto e imágenes. La combinación de las capacidades de generalización del Transformer y las capacidades de preservación de detalles del modelo de difusión proporciona lo mejor de ambos mundos y proporciona una manera de generar imágenes detalladas y muy detalladas al tiempo que se preserva la estructura semántica de la imagen (el Transformer en la estructura UNet principalmente para la compresión semántica).
pérdida percibida
Los codificadores automáticos en modelos de difusión latente capturan la estructura perceptiva de los datos proyectándola en un espacio latente. Los autores del artículo utilizan una función de pérdida especial para entrenar este codificador automático llamada "pérdida de percepción". Esta función de pérdida garantiza que la reconstrucción se limite a la variedad de imágenes y reduce la borrosidad que se produce cuando se utilizan pérdidas de espacio de píxeles (como las pérdidas L1/L2).

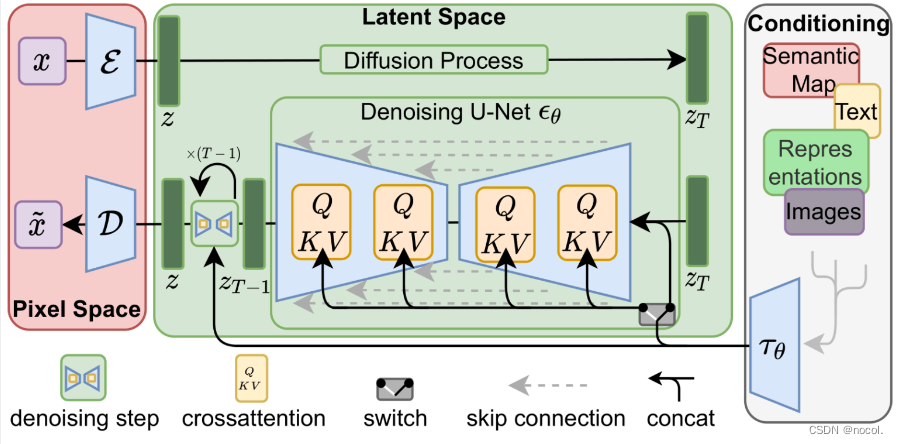
Para acelerar el proceso de generación de imágenes, Stable Diffusion no eligió ejecutar el proceso de difusión en la imagen de píxeles en sí , sino que eligió ejecutarlo en la versión comprimida de la imagen , que también se denomina "Salida al espacio latente" en el papel.
Todo el proceso de compresión, incluida la descompresión posterior y el dibujo de la imagen, se completa a través del codificador automático , que comprime la imagen en el espacio latente y luego solo usa el decodificador para reconstruirla utilizando la información comprimida.
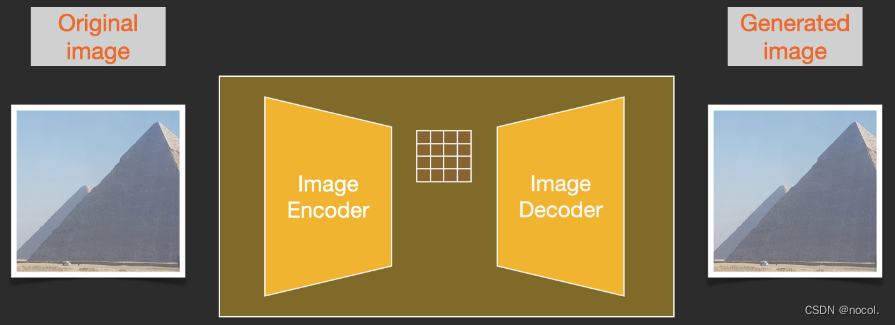
El proceso de difusión directa se completa en las latentes comprimidas y los cortes de ruido se aplican al ruido de las latentes, no a la imagen de píxeles, por lo que el predictor de ruido en realidad está entrenado para predecir la representación comprimida (ruido latente en el espacio).

El proceso directo, es decir, utiliza el codificador en el codificador automático para entrenar el predictor de ruido. Una vez que se completa el entrenamiento, se pueden generar imágenes ejecutando el proceso inverso (el decodificador en el codificador automático).
Los procesos hacia adelante y hacia atrás se muestran a continuación. La figura también incluye un componente de acondicionamiento para describir las indicaciones de texto que el modelo debe generar para la imagen .

Codificador de texto: un modelo de lenguaje transformador
El componente de comprensión del lenguaje en el modelo utiliza el modelo de lenguaje Transformer, que puede convertir indicaciones de texto de entrada en vectores de incrustación de tokens. El modelo de difusión estable publicado utiliza ClipText (un modelo basado en GPT). En este artículo, se elige el modelo BERT por conveniencia de explicación.
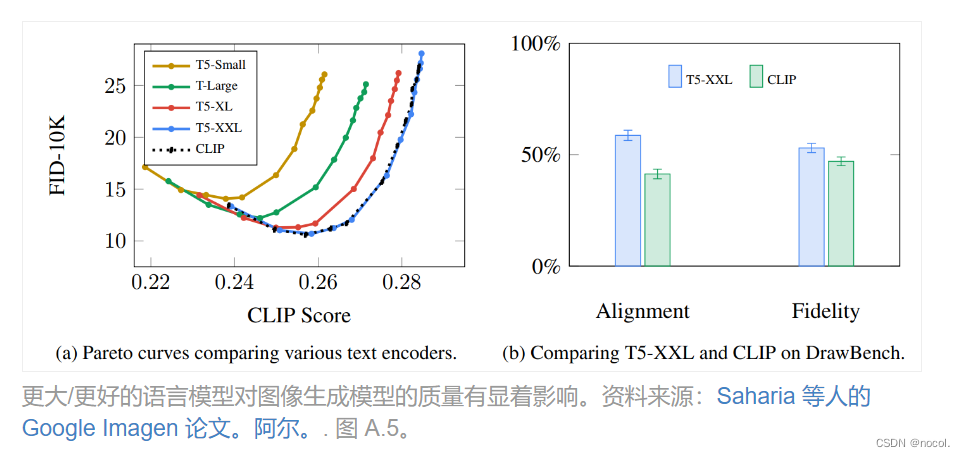
Los experimentos en el artículo de Imagen muestran que un modelo de lenguaje más grande puede traer más mejoras en la calidad de la imagen que elegir un componente de generación de imágenes más grande.
El modelo inicial de Stable Diffusion utilizó el modelo ClipText previamente entrenado lanzado por OpenAI, pero en Stable Diffusion V2, cambió a la variante del modelo CLIP más grande recientemente lanzada, OpenClip.
¿Cómo se entrena CLIP?
Los datos requeridos por CLIP son imágenes y sus títulos, y el conjunto de datos contiene aproximadamente 400 millones de imágenes y descripciones.

El conjunto de datos se recopila a partir de imágenes extraídas de la web y su correspondiente texto de etiqueta "alt".
CLIP es una combinación de codificador de imágenes y codificador de texto. Su proceso de entrenamiento se puede simplificar para tomar imágenes y descripciones de texto y utilizar dos codificadores para codificar los datos por separado.
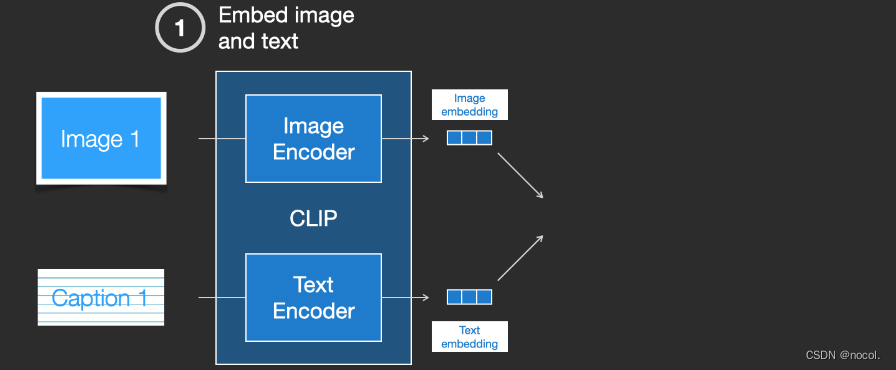
Las incrustaciones resultantes se comparan utilizando la distancia del coseno . Al comienzo del entrenamiento, incluso si la descripción del texto y la imagen coinciden, la similitud entre ellas es definitivamente muy baja.
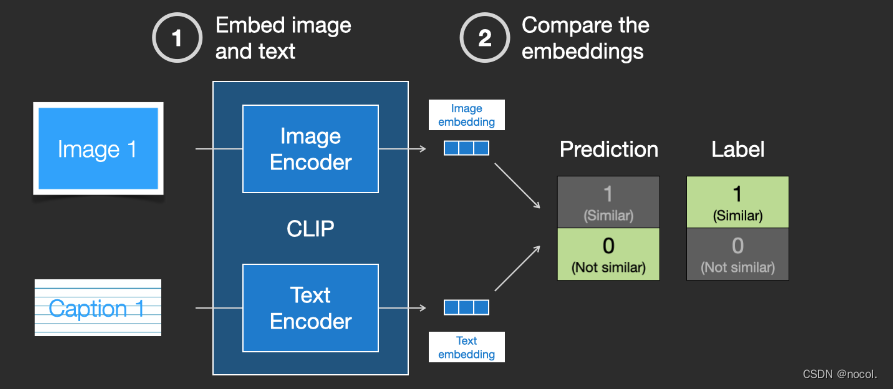
A medida que el modelo se actualiza continuamente, las incrustaciones obtenidas por el codificador que codifica imágenes y texto se volverán gradualmente similares en etapas posteriores.
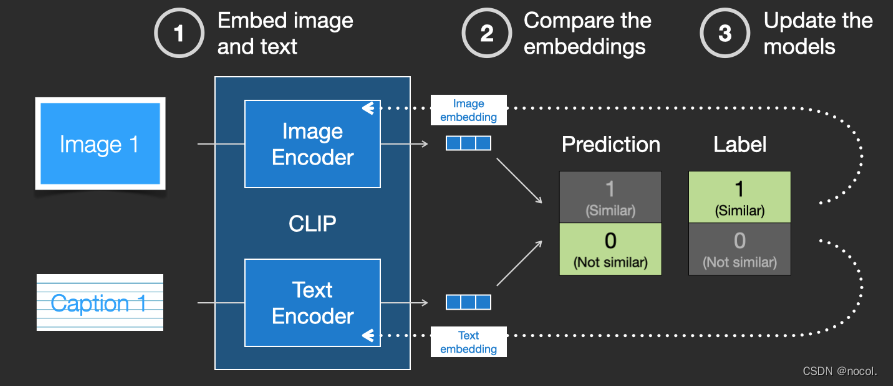
Al repetir este proceso en todo el conjunto de datos y utilizar un codificador con un tamaño de lote grande, finalmente podemos generar un vector de incrustación donde la imagen del perro es similar a la oración "imagen de un perro".
Al igual que en word2vec, el proceso de capacitación también debe incluir ejemplos negativos de imágenes y leyendas que no coinciden, y el modelo debe asignarles puntuaciones de similitud más bajas.
La información de texto se introduce en el proceso de generación de imágenes:
Síntesis de texto-imagen: en la implementación de Python, podemos usar la última implementación oficial usando LDM v4 para generar imágenes. En la síntesis de texto a imagen, el modelo de difusión latente utiliza el modelo CLIP 3 previamente entrenado, que proporciona incrustaciones universales basadas en Transformer para múltiples modalidades, como texto e imágenes. La salida del modelo Transformer luego se ingresa en una API de Python del modelo de difusión latente llamada "difusores", junto con la posibilidad de establecer algunos parámetros (por ejemplo, número de pasos de difusión, semilla de número aleatorio, tamaño de imagen, etc.).
Para incorporar el acondicionamiento de texto como parte del proceso de generación de imágenes, la entrada al predictor de ruido debe adaptarse para que sea texto .
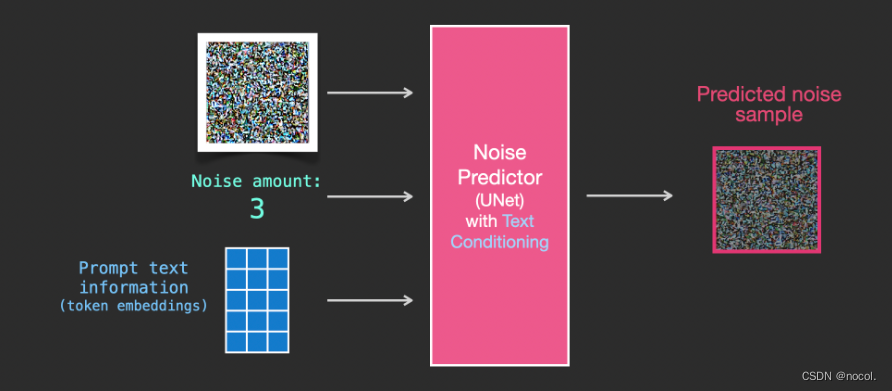
Todas las operaciones se realizan en el espacio latente , incluido el texto codificado, las imágenes de entrada y el ruido de predicción.

Para comprender mejor cómo se utilizan los tokens de texto en Unet, primero debe comprender el modelo de Unet.
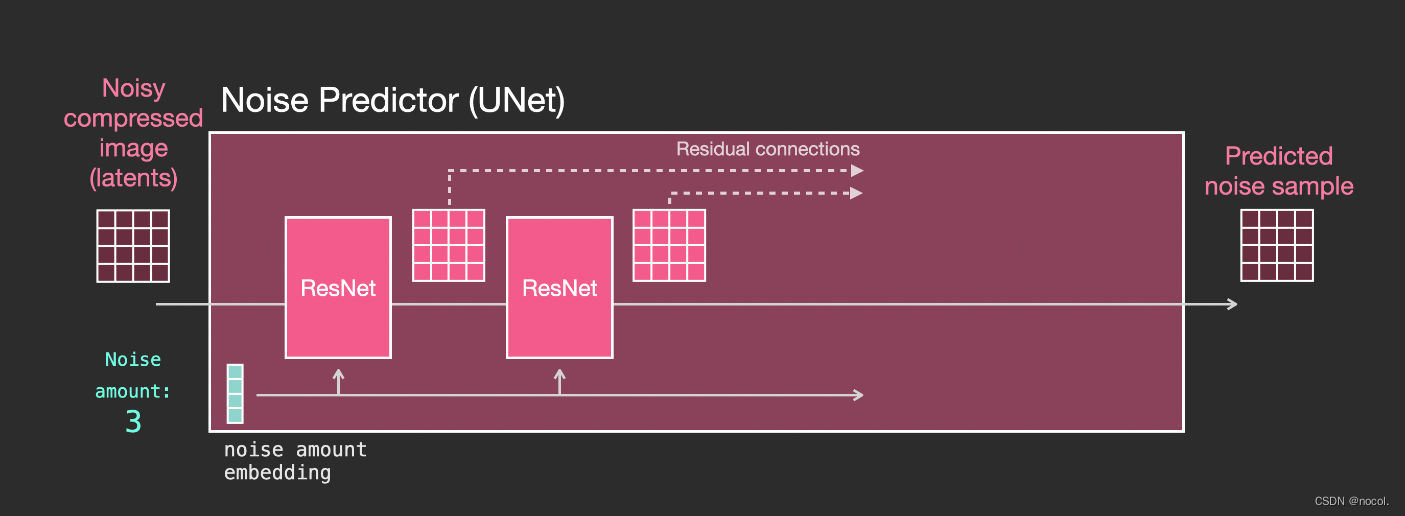
Capas en el predictor de ruido Unet (sin texto)
Un Unet de difusión que no utiliza texto, su entrada y salida son las siguientes:
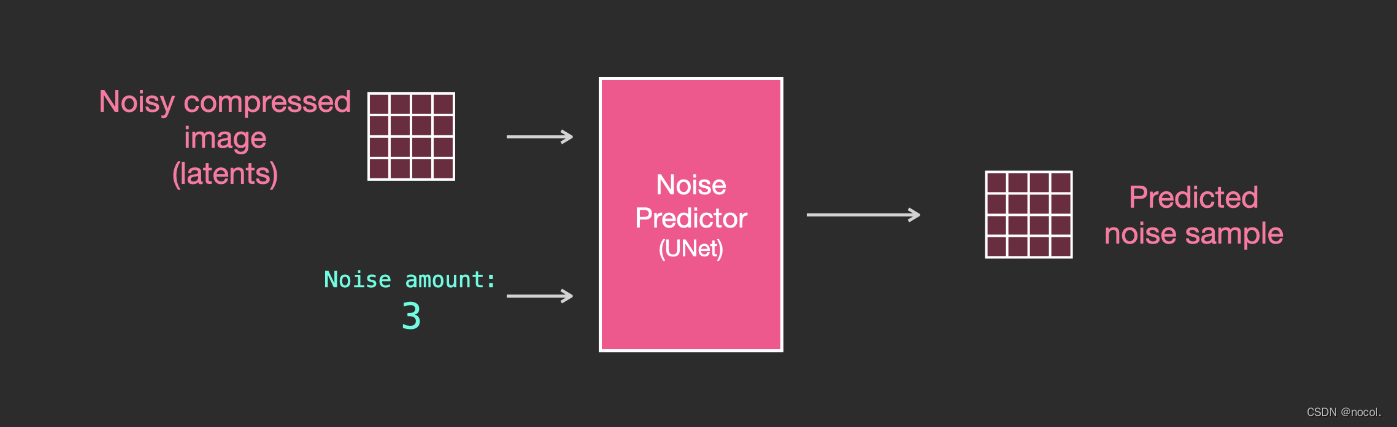
Dentro del modelo, puedes ver:
1. Las capas del modelo Unet se utilizan principalmente para convertir latentes;
2. Cada capa opera sobre la salida de la capa anterior;
3. Ciertas salidas (a través de conexiones residuales) las introducen en el procesamiento detrás de la red.
4. Convierta pasos de tiempo en vectores de incrustación de pasos de tiempo, que se pueden usar en capas.
Capas en el predictor de ruido Unet (con texto)
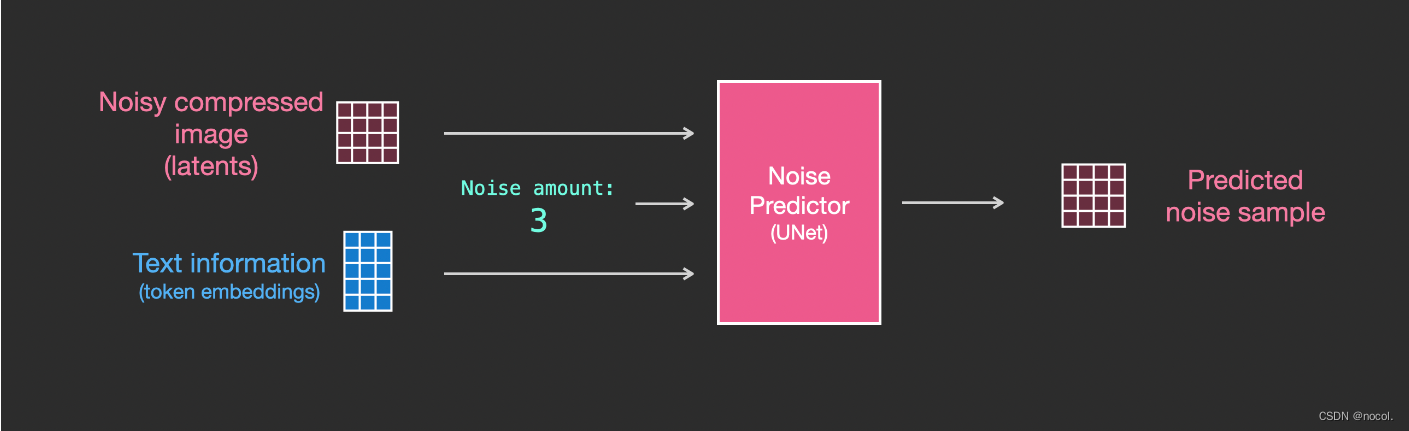
Ahora es necesario convertir el sistema anterior a una versión de texto.
difusión condicional
Los modelos de difusión son modelos condicionales que se basan en antecedentes. En las tareas de generación de imágenes, el prior suele ser texto, imagen o mapa semántico. Para obtener una representación latente a priori, es necesario utilizar un transformador (por ejemplo, CLIP) para incrustar el texto/imagen en el vector latente τ\tauτ. Por lo tanto, la función de pérdida final depende no sólo del espacio latente de la imagen original, sino también de la incrustación latente de las condiciones.
La modificación principal es agregar soporte para entrada de texto (término: acondicionamiento de texto) agregando una capa de atención entre los bloques ResNet .
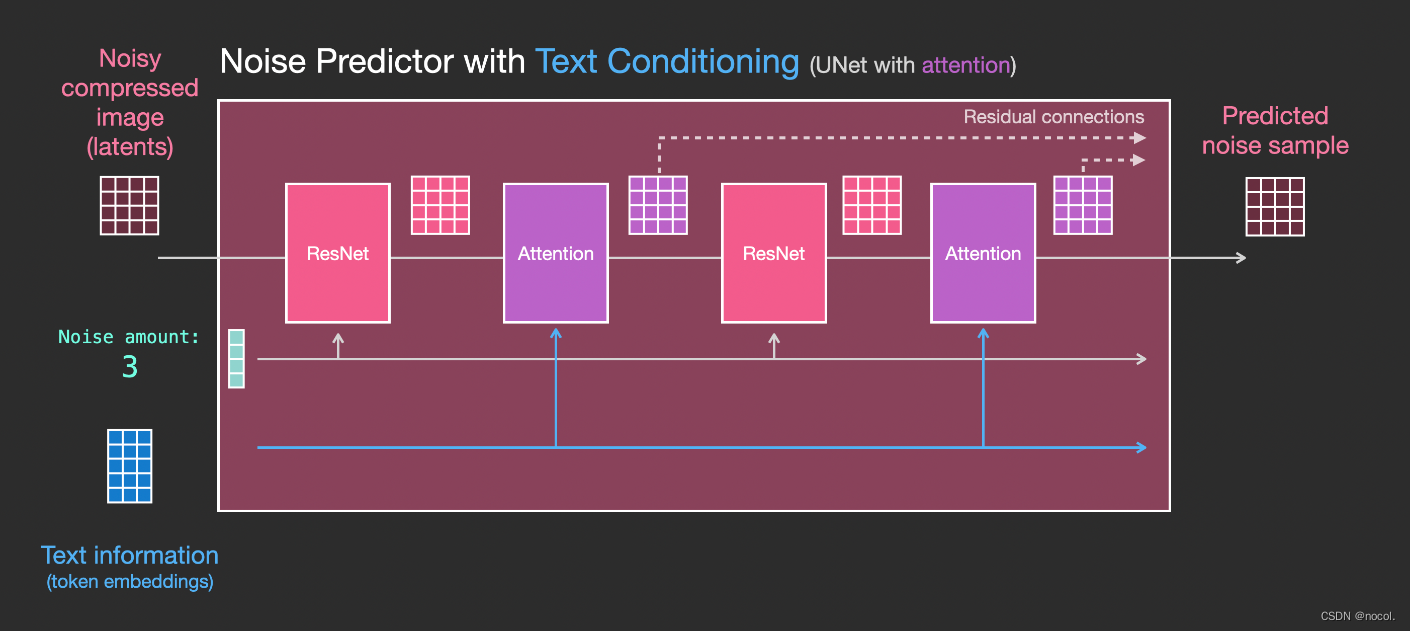
Cabe señalar que el bloque ResNet no ve directamente el contenido del texto, sino que fusiona la representación del texto latente a través de la capa de atención, y luego el siguiente ResNet puede utilizar la información del texto superior en este proceso.
Referencias:
https://jalammar.github.io/illustrated-stable-diffusion/
https://www.reddit.com/r/MachineLearning/comments/10dfex7/d_the_illustrated_stable_diffusion_video/