Nivel 1: use la URL para obtener el archivo de hipertexto y guárdelo localmente
Código de implementación:
# -*- codificación: utf-8 -*-
importar urllib.request como req
importarnos
importar hashlib
# Universidad Nacional de Tecnología de Defensa Admisión de pregrado Red de información Puntaje de admisión URL de la página web:
url = 'http://www.gotonudt.cn/site/gfkdbkzsxxw/lqfs/index.html' # URL de la página de puntuación de admisión
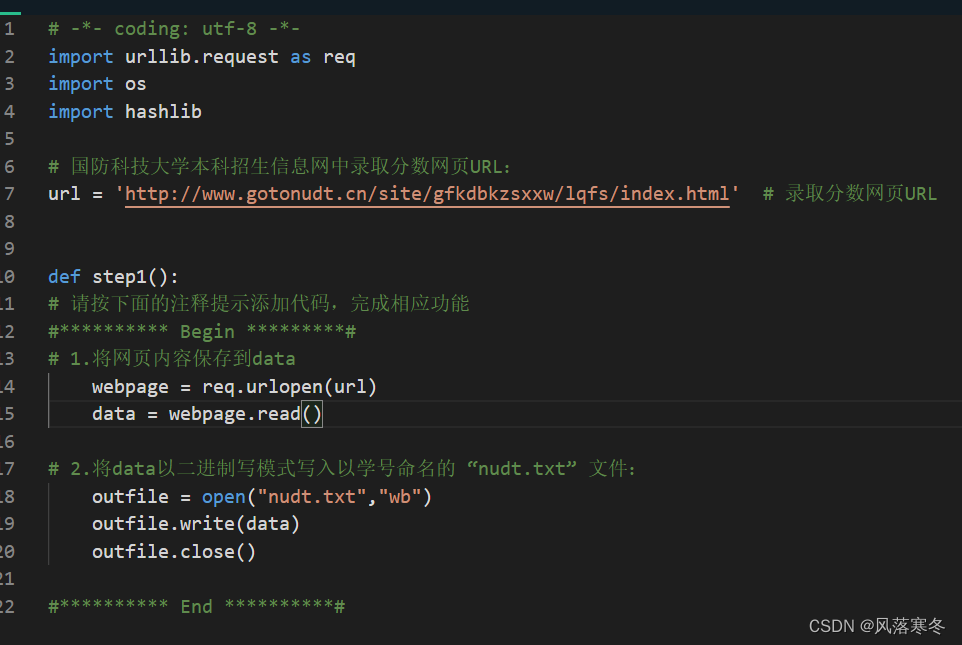
def paso1():
# Siga el comentario a continuación para agregar código para completar la función correspondiente
#********** Comenzar *********#
# 1. Guarde el contenido de la página web en datos
página web = req.urlopen(url)
datos = pagina web.leer()
# 2. Escriba los datos en modo de escritura binaria en el archivo "nudt.txt" que lleva el nombre del número de estudiante:
archivo de salida = abrir("nudt.txt","wb")
outfile.escribir(datos)
archivo de salida.cerrar()
#********** Fin **********#
Paso 2: Extraer subenlaces
Código de implementación:
# -*- codificación: utf-8 -*-
importar urllib.request como req
# Universidad Nacional de Tecnología de Defensa Admisión de pregrado Red de información Puntaje de admisión URL de la página web:
url = 'http://www.gotonudt.cn/site/gfkdbkzsxxw/lqfs/index.html' # URL de la página de puntuación de admisión
página web = req.urlopen(url) # Abre la página web como un archivo de clase
data = webpage.read() # Leer todos los datos de la página web a la vez
data = data.decode('utf-8') # Decodifica los datos de tipo byte en una cadena (de lo contrario, se procesarán por separado más adelante)
def paso2():
# Cree una lista vacía de URL para guardar las URL de las subpáginas
URL = []
# Siga el comentario a continuación para agregar código para completar la función correspondiente
#********** Comenzar *********#
# Extraiga la dirección del subsitio de línea de fracción de 2016 a 2012 para cada año de los datos y agréguelo a la lista de URL
años = [2016, 2015, 2014, 2013,2012]
por año en años:
index = data.find("Universidad Nacional de Tecnología de Defensa %s año estadísticas de puntaje de admisión" %año)
href = data[index-80:index-39] # Extraer subcadenas de URL según cada cadena característica
sitio web = 'http://www.gotonudt.cn'
urls.append(sitio web+href)
#********** Fin **********#
direcciones URL de retorno

Nivel 3: análisis de datos de páginas web
Código de implementación:
# -*- codificación: utf-8 -*-
importar urllib.request como req
importar re
# URL de la página web de puntaje de admisión de 2016 en la Red de información de admisión de pregrado de la Universidad Nacional de Tecnología de Defensa:
url = 'http://www.gotonudt.cn/site/gfkdbkzsxxw/lqfs/info/2017/717.html'
página web = req.urlopen(url) # Visite la página web vinculada según el hipervínculo
data = webpage.read() # leer los datos de la página web del hipervínculo
data = data.decode('utf-8') # decodificar tipo de byte a cadena
# Obtener todo el contenido de la primera tabla de la página web:
tabla = re.findall(r'<tabla(.*?)</tabla>', datos, re.S)
firsttable = table[0] # Obtener la primera tabla en la página web
# Limpieza de datos, eliminar , \u3000 y espacios en la tabla
primeratabla = primeratabla.replace(' ', '')
primeratabla = primeratabla.replace('\u3000', '')
primeratabla = primeratabla.reemplazar(' ', '')
def paso3():
puntuación = []
# Agregue el código de acuerdo con el comentario a continuación para completar la función correspondiente. Para ver el código html detallado, puede abrir la URL en el navegador para ver el código fuente de la página.
#********** Comenzar *********#
# 1. Presione la etiqueta tr para obtener todas las filas de la tabla y guardarlas en las filas de la lista:
filas = re.findall(r'<tr(.*?)</tr>', primeratabla, re.S)
# 2. Iterar sobre todos los elementos en las filas, obtener los datos en la etiqueta td de cada fila, formar los datos en una lista de elementos y agregar cada elemento a la lista de puntuación:
lista de puntajes = []
por fila en filas:
artículos = []
tds = re.findall(r'<td.*?>(.*?)</td>', fila, re.S)
para td en tds:
rightindex = td.find('</span>') # return -1 significa no encontrado
índiceizquierdo = td[:índicederecho].rfind('>')
items.append(td[índiceizquierdo+1:índicederecho])
scorelist.append(elementos)
# 3. Guarde la lista de 7 elementos que consta de provincias y puntuaciones (si la puntuación no existe, reemplácela con \) como un elemento en la nueva lista de puntuación, no guarde información redundante
para registro en la lista de puntajes[3:]:
grabar.pop()
score.append(registro)
#********** Fin **********#
puntuación de retorno
