Directorio de artículos
1. Conceptos básicos
La agrupación en clústeres es el proceso de dividir un objeto de datos en múltiples grupos o clústeres, de modo que la similitud de los objetos dentro de un clúster es muy alta, mientras que la similitud de los objetos entre los clústeres es muy baja.
El agrupamiento es un método de clasificación no supervisado.
Los principales métodos de agrupamiento incluyen principalmente: métodos basados en particiones, métodos basados en jerarquías, métodos basados en densidad, métodos basados en cuadrículas y métodos basados en modelos.
2. Método basado en particiones
1. La idea de división
Dada una colección de n objetos de datos, los métodos basados en particiones construyen k agrupaciones de datos, donde cada agrupación representa un grupo.
Para un número dado de grupos k, el algoritmo primero dará un método de agrupación inicial y luego cambiará la agrupación a través de un método iterativo, de modo que la distancia dentro del mismo grupo se acerque y la distancia entre diferentes grupos se aleje cada vez más. .
Los algoritmos basados en ideas de partición incluyen k-medias y k-puntos centrales.
Si desea lograr el óptimo global, debe enumerar exhaustivamente todas las particiones posibles, lo que requiere una gran cantidad de cálculos Puede utilizar métodos heurísticos, como k-means y k-center points, para mejorar gradualmente la calidad de la partición y acercarse a la solución óptima local.
2.K-medias
Pasos del algoritmo:
(1) En el conjunto de n objetos de datos, seleccione aleatoriamente k puntos como los centros de k grupos.
(2) Calcular las distancias entre los puntos restantes y los puntos centrales de los k conglomerados, y dividirlo en el conglomerado correspondiente si es el más cercano al punto central del conglomerado.
(3) Para cada grupo, vuelva a calcular el punto central del grupo.
(4) Continúe repitiendo hasta que se alcance la condición de terminación del algoritmo.
Selección de centroides iniciales :
el método más común es seleccionar aleatoriamente los centroides iniciales, y el algoritmo se puede ejecutar varias veces para obtener mejores resultados.
Métrica de distancia :
use la métrica de distancia euclidiana para puntos en el espacio euclidiano
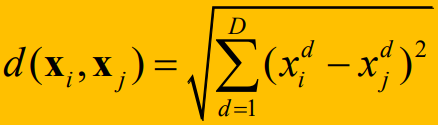
y la métrica de similitud de coseno para documentos
Método de cálculo del centro del conglomerado :
en el paso 3, cómo volver a calcular el centro del conglomerado, tomando la media aritmética de cada dimensión de todos los objetos en el conglomerado.
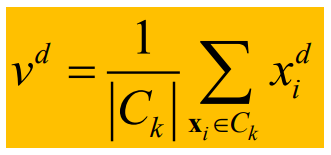
Donde d representa la dimensión, v representa el nuevo punto de coordenadas del centro del clúster, |Ck| representa el número de puntos en el clúster.
Función objetivo : la función objetivo para la agrupación se basa en la proximidad de los puntos a los centroides de las agrupaciones, utilizando la suma de errores cuadráticos (SSE) como función objetivo para medir la calidad de la agrupación.
La definición es la siguiente:
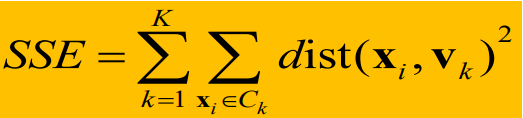
primero calcule la suma cuadrada de las distancias desde cada punto de datos xi hasta el centro del grupo vk en cada grupo, y luego sume las distancias de todos los grupos.
Los pasos (2) y (3) minimizan SSE, pero solo pueden garantizar que se encuentre una solución local óptima.
Condiciones de parada del algoritmo :
(1) Establecer el número de iteraciones.
(2) Los centros de racimo ya no cambian.
(3) Los cambios de SSE de los dos resultados de agrupamiento antes y después son muy pequeños.
Ventajas y
desventajas : Ventajas: La complejidad de K-significa O(tkn), donde n es la cantidad de objetos de datos, k es la cantidad de grupos y t es la cantidad de iteraciones, generalmente t y k son mucho más pequeños que n Desventajas: Necesidad
de dar Si se obtiene el valor de k, no puede manejar datos con ruido y valores atípicos, y su robustez es pobre, por lo que no es adecuado para encontrar clústeres no esféricos.
Algoritmo centroide 3.k
Dado que K-means no puede manejar datos ruidosos y valores atípicos, el algoritmo del punto central k es una mejora de k-manes. Después de la mejora, puede manejar puntos de ruido y valores atípicos.
PAM es un algoritmo k-medoid.
Los puntos de mejora son los siguientes:
al actualizar el centro del clúster, en lugar de calcular la media aritmética de todos los puntos del clúster como el nuevo punto central del clúster, se selecciona el punto con la distancia más pequeña de todos los puntos como el nuevo punto central.
PAM usa el estándar de error absoluto para medir la calidad del agrupamiento
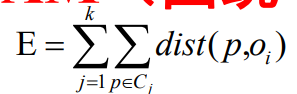
donde k representa k grupos, p representa objetos no representativos en el grupo Ci y Oi representa objetos representativos en el grupo Ci.
Los pasos son los siguientes:
(1) En el conjunto de n objetos de datos, seleccione al azar k puntos como los centros de k grupos.
(2) Calcular las distancias entre los puntos restantes y los puntos centrales de los k conglomerados, y dividirlo en el conglomerado correspondiente si es el más cercano al punto central del conglomerado.
(3) Para cada conglomerado, cada punto del conglomerado se toma como un objeto representativo a su vez, y luego el punto con el estándar de error absoluto más pequeño se selecciona como el punto central del conglomerado.
(4) Continúe repitiendo hasta que se alcance la condición de terminación del algoritmo.
3. Enfoque basado en capas
Los métodos basados en jerarquía se pueden dividir en aglomeración y clasificación.
Clasificación jerárquica aglomerativa: de abajo hacia arriba, cada objeto se considera como un grupo al principio, y luego los grupos similares se combinan gradualmente hasta que se alcanza la condición de terminación.
Clasificación Agrupación jerárquica: de arriba a abajo, todos los objetos están en un grupo al principio y luego se dividen continuamente hasta que se alcanza la condición de terminación.
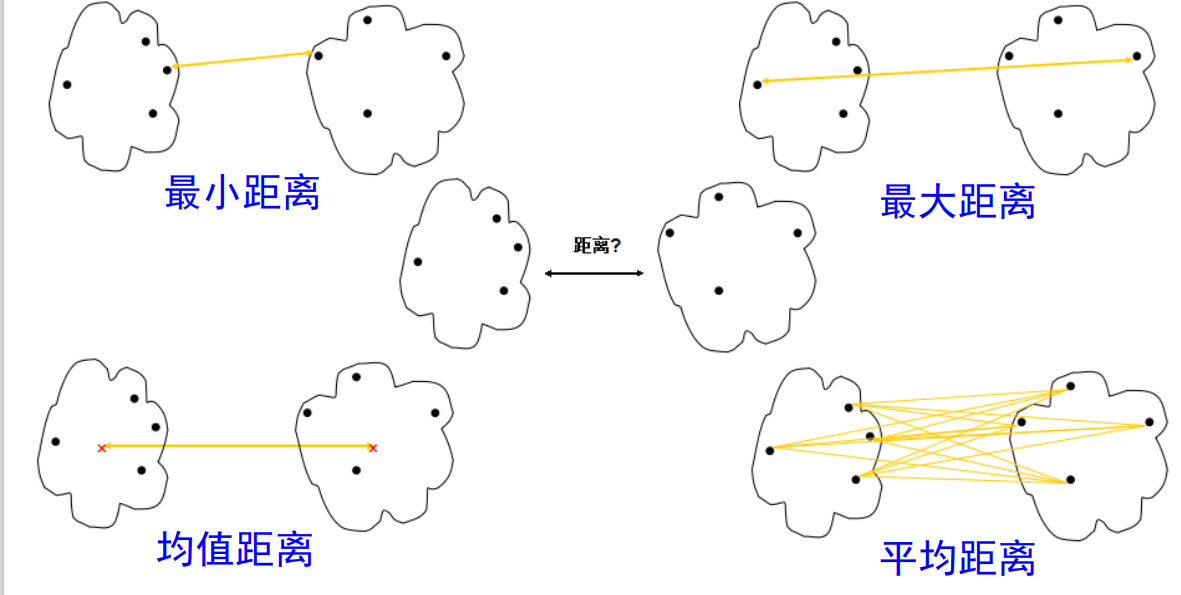
1. Distancia entre grupos:
Independientemente del método que se utilice, es necesario medir la distancia entre los grupos. De acuerdo con los diferentes métodos de medición, el agrupamiento jerárquico se puede dividir en conexión única, conexión completa y conexión promedio.
Entre ellos, la distancia mínima se usa para una sola conexión,
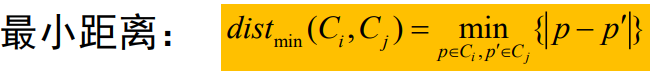
la distancia máxima se usa para
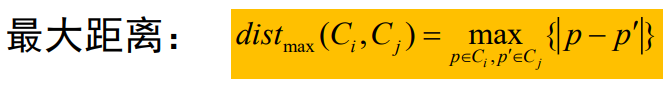
una conexión completa y la distancia promedio se usa para una conexión promedio.Además
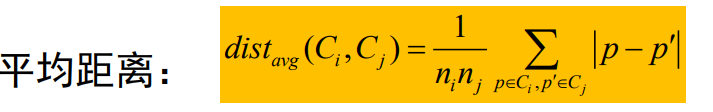
, también existe la

distancia mínima de la distancia media:
la distancia máxima entre los Los dos puntos más cercanos entre diferentes conglomerados : Representa
la distancia promedio entre los dos puntos más lejanos entre diferentes conglomerados Distancia : Representa la distancia entre los puntos centrales de diferentes conglomerados
Distancia promedio : Representa la distancia promedio entre todos los puntos de diferentes conglomerados
El diagrama esquemático de las cuatro distancias anteriores es el siguiente:
2.AGNES
El algoritmo utiliza el método de conexión única y la matriz de distancia, luego fusiona los puntos diferentes con la distancia más pequeña, continúa calculando una nueva matriz de distancia y continúa fusionando los puntos diferentes con la distancia más pequeña. hasta alcanzar el número de racimos.
Un ejemplo es el siguiente:
hay los siguientes cinco puntos en un espacio bidimensional, que se agrupan utilizando el algoritmo de conexión única.
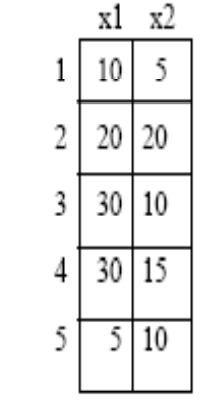
El primer paso: Calcular la matriz de distancia
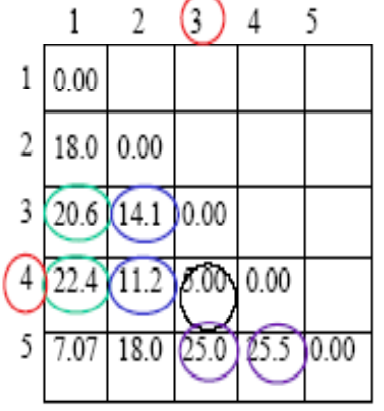
Se puede obtener que la distancia 5 entre 3 y 4 es la más pequeña, por lo que 3 y 4 se agrupan en una clase.
Paso 2: Vuelva a calcular la matriz de distancia
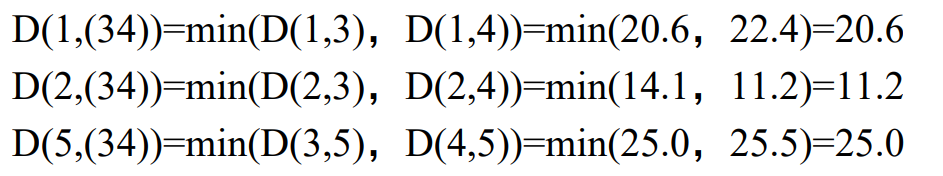
La distancia original entre los grupos 1, 2 y 5 permanece sin cambios, pero la distancia entre 1, 2, 5 y el grupo (3, 4) cambia. La matriz de distancia actualizada es la siguiente:
se puede obtener que la distancia 1,07 entre el clúster 1 y el clúster 5 es la más pequeña, por lo que los clústeres 1 y 5 en una sola clase.
Paso 3: Recalcular la matriz de distancia
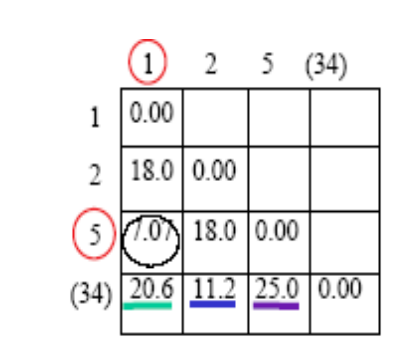
Es necesario calcular la distancia entre el clúster 2 y el clúster (1, 5) y el clúster (3, 4). La matriz de distancia actualizada es la siguiente:
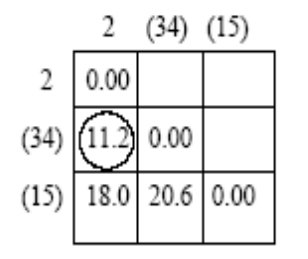
la distancia entre el grupo 2 y el grupo (3, 4) es la más pequeña, por lo que el grupo 2 y el grupo (3, 4) se agrupan en una clase.
Paso 4: Vuelva a calcular la matriz de distancia
Solo
se necesita calcular la distancia entre los conglomerados (2, 3, 4) y los conglomerados (1, 5).
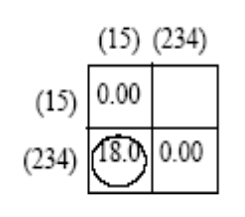
Finalmente agrupar (1,5) y agrupar (2,3,4) en una clase.
La distancia del algoritmo de conexión única se refiere a la distancia mínima.
Si se establece una condición de terminación, saldrá a la mitad.
Se describe visualmente con un dendrograma de la siguiente manera:

el usuario puede definir el número deseado de grupos como condición de terminación.
La métrica min-max es sensible a valores atípicos y datos ruidosos.
El uso de distancias medias y promedio es un compromiso que supera el problema de la sensibilidad de los valores atípicos.
4. Métodos basados en la densidad
Tanto los métodos basados en partición como en jerarquía tienen como objetivo descubrir grupos esféricos y no pueden descubrir grupos de forma arbitraria. Mientras que los métodos de agrupación en clústeres basados en la densidad pueden descubrir clústeres de forma arbitraria, los clústeres pueden verse como regiones densas en el espacio de datos separadas por regiones dispersas.
1. Algoritmo DBSCAN
Entorno EPS : un punto especifica un área circular con un radio r.
Minpts : El número mínimo de puntos incluidos.
Punto central : el número de puntos en la vecindad de este punto excede el umbral especificado MinPoints.
Punto límite : un punto límite es un punto ubicado dentro del punto central y, al mismo tiempo, no hay puntos nuevos sin marcar dentro de la vecindad EPS del punto.
Puntos atípicos : Ni puntos límite ni puntos centrales.
Accesibilidad de densidad directa : dado un conjunto de objetos D, si p está en la vecindad Eps de q, y q es un objeto central, entonces se dice que el objeto p es de densidad alcanzable desde el objeto q.
Densidad alcanzable : si hay una cadena de objetos, p1, p2, ..., pn, p1 = q, pn = p, y para cualquier pi, pi+1 es directamente alcanzable por densidad, entonces el objeto p comienza desde el objeto q es la densidad alcanzable.
Conectado por densidad : si existe un objeto O tal que tanto el objeto p como el objeto q son accesibles por densidad desde O, entonces el objeto p y el objeto q están conectados por densidad.
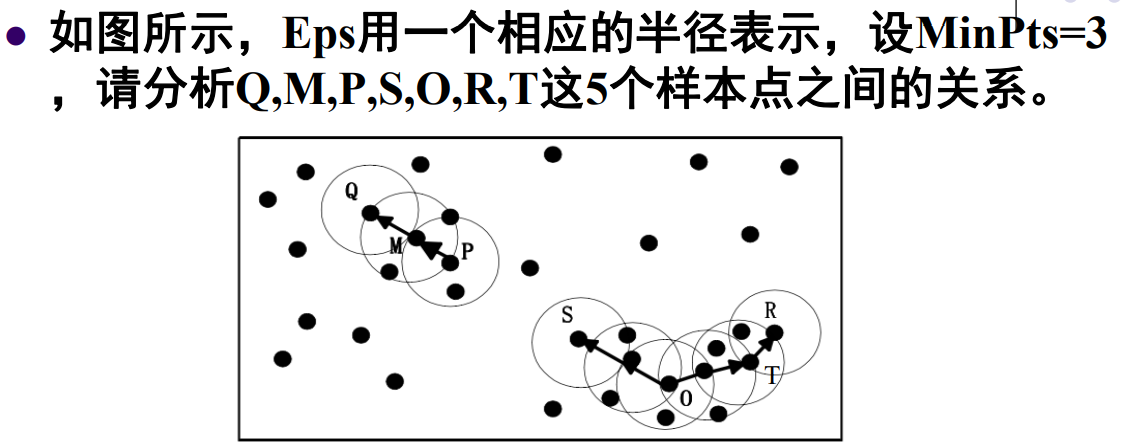
Dado que MinPts = 3,
M, P son puntos centrales y Q no es un punto central.
O, T es el punto central, S, R no es el punto central.
Dado que M está en la vecindad de P, y P es el punto central, M es directamente accesible por densidad desde P.
Dado que Q está en la vecindad de M, y M es el punto central, Q es directamente alcanzable por densidad desde M, y Q es accesible por densidad desde P.
De manera similar, S es alcanzable por densidad desde O, y R es accesible por densidad desde O, por lo que S y R están conectados por densidad.
Pasos del algoritmo :

Como puede ver, DBSCAN encontrará el conjunto de puntos conectados con la densidad máxima.
Ventajas :
basado en la definición de densidad, no es sensible al ruido y puede encontrar grupos de forma arbitraria
Desventajas :
cuando la densidad del grupo no es uniforme, la calidad del grupo no es buena.
Cuando la cantidad de datos es grande y la dimensión de los datos es alta, es fácil desbordar la memoria.
5. Evaluación del conglomerado
La evaluación de agrupamiento incluye principalmente las siguientes tareas:
estimación de tendencias de agrupamiento, determinación del número de agrupamientos en el conjunto de datos
y determinación de la calidad del agrupamiento
1. Estimación de tendencias de agrupamiento
El análisis de conglomerados solo tiene sentido cuando hay una estructura no aleatoria en el conjunto de datos.
(1) Si el error de agrupamiento no cambia significativamente con el número de categorías de conglomerados, significa que los datos se distribuyen aleatoriamente, es decir, no existe una estructura no aleatoria.
(2) Estadísticas de Hopkins:
en el primer paso, muestree uniformemente n puntos p1, p2, p3, ..., pn en el conjunto de datos D. Para cada punto, calcule el punto más cercano en el conjunto de datos D y registre su distancia como xi.
En el segundo paso, muestree uniformemente n puntos q1, q2, q3, ..., qn en el conjunto de datos D. Para cada punto, calcule el punto más cercano en el conjunto de datos D y registre su distancia como yi.
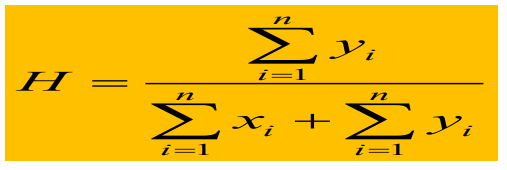
Si D se distribuye aleatoriamente, H es aproximadamente 0, 5.
Si la tendencia de agrupamiento es obvia, el valor de H está cerca de 1 o 0.
Generalmente, H> 0, 75, la confianza del agrupamiento puede ser del 90 %.
2. Determinación del número de conglomerados
Método empírico : el número de conglomerados p es aproximadamente
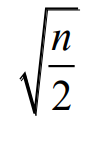
el método del punto de inflexión : dibuje la varianza intraconglomerado y la curva sobre el número de conglomerados, y el número de conglomerados en el punto de inflexión es el número establecido de conglomerados.
Método de validación cruzada : divide un conjunto de datos dado en m partes, usa m-1 partes para construir un modelo de agrupamiento, usa la parte restante para probar la calidad del agrupamiento, selecciona el modelo de agrupamiento con la calidad de agrupamiento más alta y usa su K como el número de conglomerados.
3. Determinación de la calidad del agrupamiento:
Métodos extrínsecos : métodos supervisados, entropía, pureza, precisión, recuperación, medida F. Consulte el libro de texto para obtener fórmulas específicas.
Métodos intrínsecos : métodos no supervisados que examinan la separación entre grupos y la compacidad dentro de los grupos.
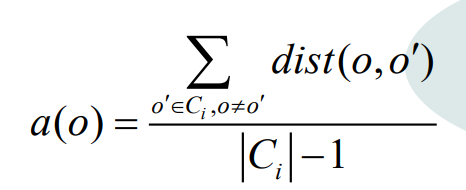
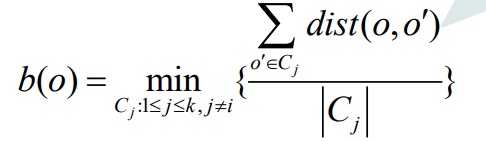
Coeficiente de silueta S(O)
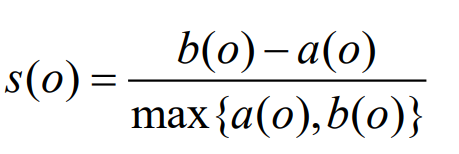
donde el conjunto de datos D se divide en k grupos, a saber, C1, C2, C3,..., Ck, para cada objeto de datos O a(O)
representa O y todos los demás puntos del grupo donde O se encuentra a media distancia.
b(O) representa la distancia promedio mínima entre O y todos los demás grupos donde no se encuentra O.
El valor de a(O) refleja la compacidad dentro del grupo, y cuanto más pequeño es el valor, más compacto es. El valor de b(O) refleja el grado de separación entre los conglomerados, y cuanto mayor sea el valor, más separados.
Cuando el valor del coeficiente de silueta S(O) del conglomerado o está más cerca de 1, el conglomerado donde se encuentra O es compacto y alejado de otros conglomerados.