Algoritmo de clasificación
- 1. Algoritmos de clasificación comunes
- 2. Implementación de algoritmos de clasificación comunes.
- 3. Complejidad y estabilidad de diversas clasificaciones.
1. Algoritmos de clasificación comunes
La clasificación se puede ver en todas partes de nuestras vidas. La llamada clasificación es la operación de organizar una serie de registros en orden creciente o decreciente según el tamaño de una o algunas palabras clave que contiene.
Los algoritmos de clasificación comunes se pueden dividir en cuatro categorías: clasificación por inserción, clasificación por selección, clasificación por intercambio y clasificación por fusión; entre ellos, la clasificación por inserción se divide en clasificación por inserción directa y clasificación Hill; la clasificación por selección se divide en clasificación por selección directa y clasificación por montón; la clasificación por intercambio se divide en clasificación de burbujas y clasificación rápida, la clasificación por fusión se clasifica en una categoría principal;
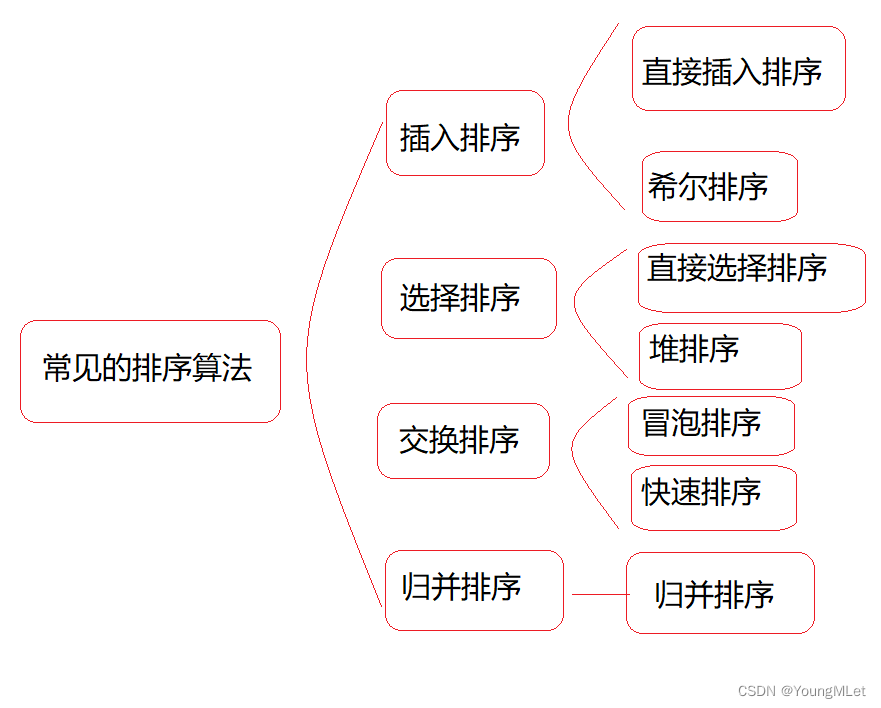
A continuación analizamos las ideas de algoritmo, ventajas, desventajas y estabilidad de cada algoritmo de clasificación uno por uno;
2. Implementación de algoritmos de clasificación comunes.
1. Clasificación por inserción directa
La ordenación por inserción directa es un método de ordenación por inserción simple. Su idea básica es insertar los registros a ordenar en una secuencia ya ordenada uno por uno según el tamaño de sus valores clave, hasta que se inserten todos los registros. , obtener una nueva secuencia ordenada .
//直接插入排序
void InsertSort(int* a, int n)
{
for (int i = 1; i < n; i++)
{
int tmp = a[i];
int end = i - 1;
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + 1] = a[end];
}
else
{
break;
}
end--;
}
a[end + 1] = tmp;
}
}
Al insertar el elemento i (i>=1), se han ordenado los anteriores a[0], a[1],...,a[i-1], es decir, se ha ordenado el rango desde 0 hasta el final. . En este momento, use el subíndice de a[i] para comparar con los subíndices de a[i-1], a[i-2],... comenzando desde el final y avanzando. Si encuentra la posición de inserción que cumple con las condiciones, se insertará un [i], los elementos en la posición original se mueven hacia atrás;
Como se muestra en la figura, solo hay un elemento en el intervalo con el subíndice 0 - final (0 - 0), es decir, ya está ordenado, i es el siguiente subíndice del final, y luego i comienza a comparar hacia adelante desde final, y cuando encuentre algo mejor que él mismo, el más grande seguirá caminando hasta encontrar un elemento más pequeño que él, y lo insertará en esta posición;
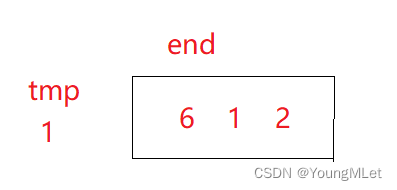
Resulta que el elemento en esta posición se mueve hacia atrás; tenga en cuenta que primero se mueve y luego se inserta; de lo contrario, los datos se sobrescribirán;

la segunda ronda de inserción:

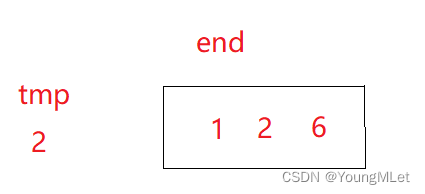
Como se muestra en la imagen, estos tres números están en orden;
La animación ordenada es la siguiente:

Resumen de características de la ordenación por inserción directa:
- Cuanto más cerca esté el conjunto de elementos del orden, más eficiente será el algoritmo de ordenación por inserción directa.
- Complejidad del tiempo: O (N ^ 2)
- Complejidad espacial: O (1), es un algoritmo de clasificación estable
- Estabilidad: estable
2. Clasificación de colinas
El método de clasificación Hill también se denomina método de incremento reductor. La idea básica del método de clasificación Hill es: primero seleccione un espacio entero, divida todos los registros del archivo que se van a ordenar en grupos de espacios y divida todos los registros con una distancia de espacio. en el mismo grupo (es decir, los intervalos se dividen en un grupo por espacio, y el número total de grupos de espacio es), y los registros dentro de cada grupo se ordenan. Luego repita el trabajo de agrupación y clasificación anterior. Cuando la brecha = 1, todos los registros se ordenan en el mismo grupo.
La clasificación Hill es en realidad una optimización de la clasificación por inserción directa. Cuando la brecha> 1, se ordena previamente (los datos del grupo de brechas se insertan y clasifican por separado). El propósito es acercar la matriz al orden; cuando la brecha == 1, es decir, cada elemento es un grupo independiente, que se convierte en tipo de inserción directa;
El valor de selección de la brecha no es seguro. Seleccionamos el valor de acuerdo con aproximadamente un tercio de la longitud de la matriz, por ejemplo, {6,1,2,7,9,3,4,5,10,8,0} En esta matriz, seleccionamos el valor de la brecha de acuerdo con la brecha = brecha / 3 + 1. La matriz se divide en la brecha == 4 grupos, y el intervalo de elementos entre cada grupo es la brecha == 4 elementos. Como se muestra en la figura, el Los segmentos de línea de diferentes colores representan diferentes grupos de espacios:
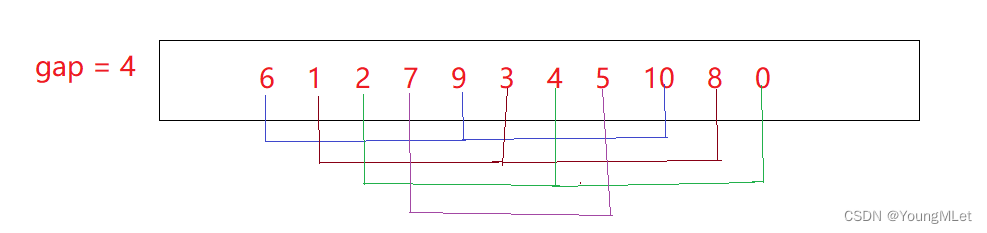
la matriz ordenada de cada grupo de espacios es como se muestra en los datos superiores de la matriz original:
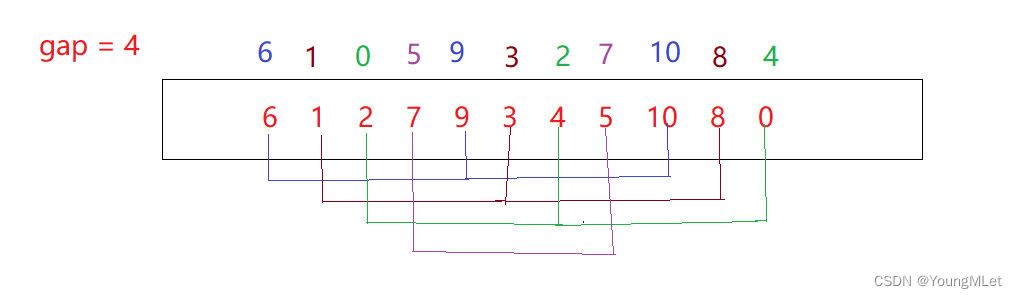
Luego, la brecha continúa calculándose de acuerdo con el método de valor anterior. La brecha es 2. Según la agrupación de la brecha == 2, se divide en los siguientes grupos. Hay dos grupos en total. El intervalo de elementos entre cada grupo es la brecha == 2 elementos:

La matriz ordenada para cada grupo de espacios se muestra en los datos superiores de la matriz original:
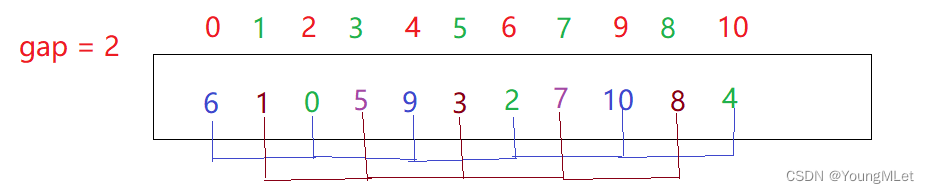
Se puede ver en la disposición actual de la matriz que la matriz está muy cerca del orden. En este momento, solo necesitamos continuar tomando el valor de la brecha de acuerdo con el método del valor de la brecha, y obtendremos la brecha == 1, es decir, clasificación por inserción directa, para que ordenemos Bueno, hay una matriz; la razón por la que el valor de la brecha toma el valor de acuerdo con la brecha = brecha / 3 + 1 es porque el último + 1 puede garantizar que el valor de la última brecha debe ser 1, es decir, la última clasificación definitivamente realizará una clasificación por inserción directa;
El código implementado es el siguiente:
//希尔排序
void ShellSort(int* a, int n)
{
int gap = n;
while (gap > 1)
{
// +1保证最后一次一定是1
gap = gap / 3 + 1;
// 多组并排
// i < n - gap 保证与数组的长度有 gap 的距离,不会越界;并分成了 gap 组;
for (int i = 0; i < n - gap; i++)
{
// 以 gap 为间距直接进行插入排序,多个组同时进行插入排序
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (a[end] > tmp)
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}
La complejidad temporal de la clasificación Hill es difícil de calcular porque hay muchas formas de valorar la brecha, lo que dificulta el cálculo. La complejidad temporal general es O (NlogN) ~ O (N ^ 2), y el mejor de los casos es el tiempo. la complejidad es O(N^1.3), la complejidad espacial es O(1) porque no se utiliza espacio adicional, la estabilidad de la clasificación Hill es inestable;
3. Clasificación por selección directa
La idea de la clasificación por selección es seleccionar el elemento más pequeño (o más grande) de los elementos de datos que se van a ordenar cada vez y almacenarlo al comienzo de la secuencia hasta que se agoten todos los elementos de datos que se van a ordenar.
La animación es la siguiente. La idea proporcionada por la animación es seleccionar solo un elemento más pequeño a la vez y colocarlo en el extremo izquierdo de la matriz. Nuestra idea es seleccionar el elemento más grande y el elemento más pequeño al mismo tiempo, colocar el elemento más grande en el más a la derecha y el elemento más pequeño en el más lejano. A la izquierda, esta es una pequeña optimización;

Por ejemplo, en la matriz {5, 3, 4, 1, 2}, el comienzo y el final registran la cabeza y la cola de la matriz, maxi y mini registran los subíndices del elemento más grande y del elemento más pequeño, excepto los elementos ordenados, como como se muestra a continuación, En este momento, el inicio y el final mantienen esta matriz. Actualmente, esta matriz está desordenada. Tanto maxi como mini comienzan a recorrer desde el inicio para encontrar los subíndices del elemento más grande y del elemento más pequeño respectivamente; luego, primero a[maxi] y a[end] Realice el intercambio, coloque el elemento más grande al final, luego intercambie a[mini] y a[begin], coloque el elemento más pequeño al frente, finalmente comience++, final- -, reduzca el rango de la matriz;
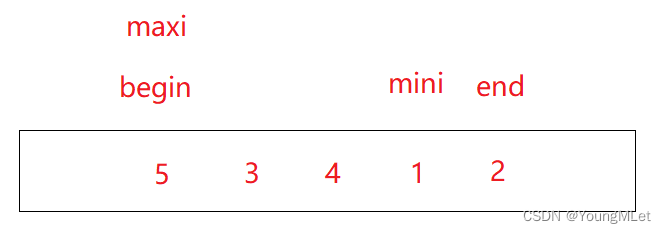
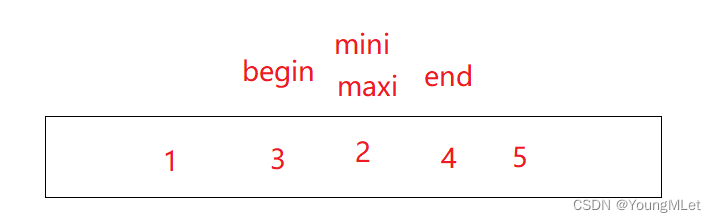
Realice la segunda clasificación de selección. En este momento, mini y end se superponen. Si a[maxi] y a[end] se intercambian primero, el a[mini] original es el elemento más pequeño y, después del intercambio, se convertirá en el original. a[maxi]. Es decir, el a[end] actual se ha convertido en el elemento más grande (porque end y mini se superponen), por lo que es necesario hacer un juicio en este momento. Si mini y end se superponen, significa que el mini original Ahora se ha movido a la posición de maxi. Por lo tanto, es necesario realizar la operación mini = maxi;
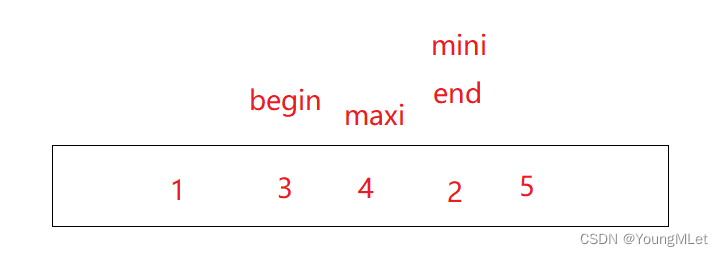
después del intercambio: 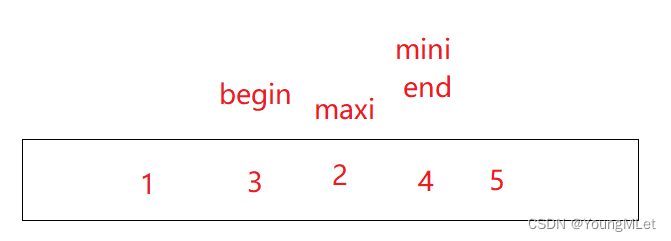
después de la corrección:
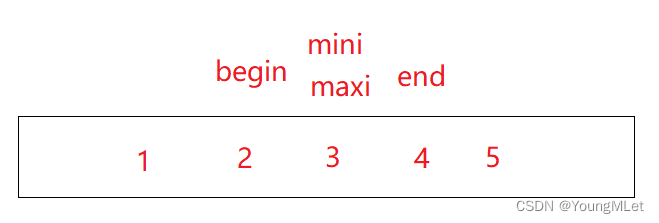
finalmente ordenado:
Aquí está el código de referencia:
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
//选择排序
void SelectSort(int* a, int n)
{
int begin = 0, end = n - 1;
while (begin < end)
{
int maxi = begin, mini = begin;
for (int i = begin; i <= end; i++)
{
if (a[i] > a[maxi])
{
maxi = i;
}
if (a[i] < a[mini])
{
mini = i;
}
}
Swap(&a[end], &a[maxi]);
//end 和 mini 重合
if (mini == end)
mini = maxi;
Swap(&a[begin], &a[mini]);
begin++;
end--;
}
}
Resumen de características del tipo de selección directa:
- La clasificación por selección directa es fácil de entender, pero la eficiencia no es muy buena y rara vez se utiliza en la práctica.
- Complejidad del tiempo: O (N ^ 2)
- Complejidad espacial: O (1)
- Estabilidad: inestable
4. Ordenación del montón
Heapsort se refiere a un algoritmo de clasificación diseñado utilizando una estructura de datos como un árbol apilado (montón), que es un tipo de clasificación por selección. Selecciona datos a través del montón. Cabe señalar que una pila grande debe construirse en orden ascendente y una pila pequeña en orden descendente.
Por ejemplo, una matriz {5, 2, 1, 3, 7, 6, 4}, la estructura de árbol de esta matriz es la siguiente:
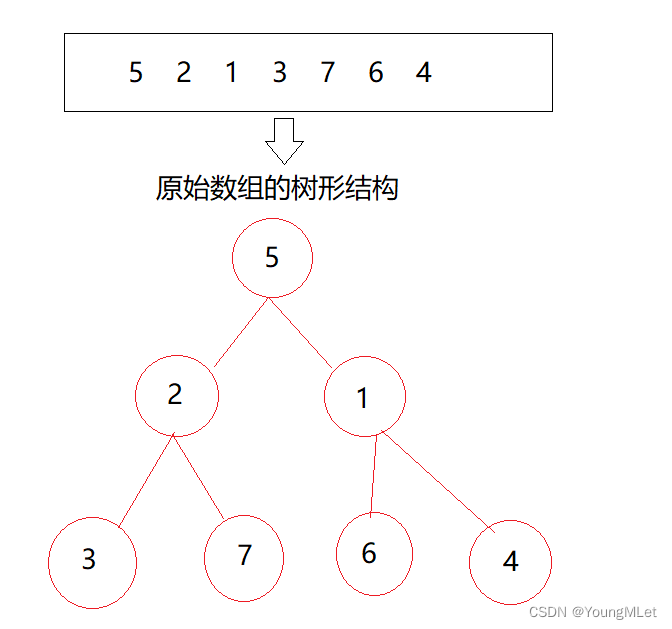
Constrúyalo en un montón grande. La idea de construir un montón no se explicará aquí. Para obtener más detalles, consulte el enlace del blog anterior Árbol binario—Heap . El montón construido es el siguiente:
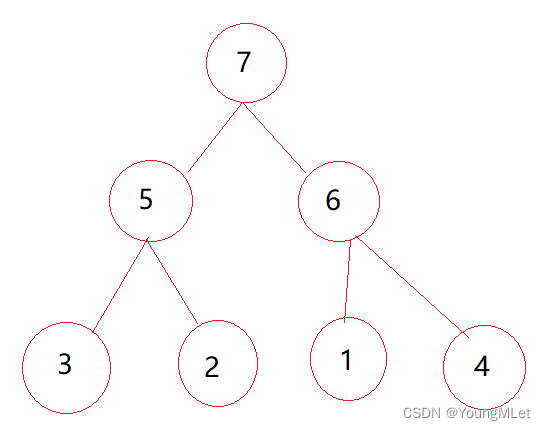
La idea de la clasificación del montón es construir primero un montón. Ahora que se ha establecido un montón grande, se debe construir un montón grande en orden ascendente, porque en el montón grande, los más grandes están al frente. , Se comparan los valores de los datos en la parte superior del montón y los datos al final del montón.Swap, después del intercambio, la longitud se reduce en uno, lo que equivale a poner el más grande al final. y sin moverse, y luego ajustando hacia abajo desde la parte superior del montón, el siguiente más grande se ajusta a la parte superior del montón, y luego se intercambia con el valor del penúltimo dato... Hasta que la longitud se reduce a 0, el se completa la clasificación;
Por ejemplo, en el montón grande en la imagen de arriba, el tamaño disminuye después del intercambio de 7 y 4. En la superficie, la estructura lógica del montón que operamos es un montón. De hecho, operamos una matriz, por lo que después del intercambio, 7 se intercambia hasta el final de la matriz y 7 es el elemento más grande, por lo que reducir la longitud en uno significa que un elemento ha sido ordenado. Después de ordenar un elemento, continúe ajustándolo hacia abajo desde la parte superior del montón, porque a excepción de los elementos en la parte superior del montón, ya es un montón, por lo que puede comenzar directamente desde la parte superior del montón y ajustar el algoritmo hacia abajo para continuar construyendo el montón;
El código de referencia es el siguiente:
//向下调整算法
void AdjustDown(int* a, int n, int parent)
{
int child = 2 * parent + 1;
while (child < n)
{
if (child + 1 < n && a[child] < a[child + 1])
{
child++;
}
if (a[child] > a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = 2 * parent + 1;
}
else
{
break;
}
}
}
//堆排序
void HeapSort(int* a, int n)
{
//建堆
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, n, i);
}
// 交换数据后调整堆顶的数据
while (n)
{
Swap(&a[0], &a[n - 1]);
n--;
AdjustDown(a, n, 0);
}
}
Resumen de características de la clasificación de montón:
- La clasificación del montón utiliza el montón para seleccionar números, lo cual es mucho más eficiente.
- Complejidad del tiempo: O (N * logN), el consumo de complejidad del tiempo es principalmente para encontrar el segundo valor más grande/segundo más pequeño en la parte superior del montón después de intercambiar datos; porque después de intercambiar datos, excepto el último elemento y los elementos en En la parte superior del montón, otros elementos ya están en el montón, por lo que para encontrar el segundo elemento más grande/segundo más pequeño en la parte superior del montón, la complejidad del tiempo es O (logN), y hay N elementos en total, por lo que el la complejidad del tiempo general es O(N*logN);
- Complejidad espacial: O (1)
- Estabilidad: inestable
5. Clasificación de burbujas
La idea de la clasificación de burbujas es comparar dos por dos y colocar el elemento más grande al final. Hasta que se recorra la matriz, el elemento más grande se coloca al final, luego se realiza una segunda comparación y el siguiente elemento más grande se coloca en la parte posterior. El elemento se coloca en la penúltima posición. Suponiendo que hay n elementos, se deben comparar un total de n veces y cada uno de los n elementos se debe comparar en pares, por lo que la complejidad temporal de la clasificación de burbujas es O (N^2);
La animación de clasificación de burbujas es la siguiente:

El código de referencia es el siguiente:
//冒泡排序
void BubbleSort(int* a, int n)
{
// 每一趟
for (int i = 0; i < n; i++)
{
// 每一趟的两两比较
// flag 标记,如果这一趟没有进行交换,说明数组已经是有序的,提前跳出循环
int flag = 1;
for (int j = 1; j < n - i; j++)
{
if (a[j - 1] > a[j])
{
Swap(&a[j],&a[j - 1]);
flag = 0;
}
}
if (flag)
break;
}
}
Aquí hay una pequeña optimización, que es para matrices que ya están ordenadas, marcadas con el indicador 1. Si no se realiza ningún intercambio en esta pasada, significa que la matriz ya está en orden y no hay necesidad de intercambiar, y no No es necesario comparar, así que salte del bucle directamente de antemano;
Resumen de características del tipo de burbuja:
- La clasificación de burbujas es una clasificación muy fácil de entender, adecuada para que la comprendan los principiantes y tiene importancia didáctica;
- Complejidad del tiempo: O (N ^ 2)
- Complejidad espacial: O (1)
- Estabilidad: estable
6. Clasificación rápida
6.1 Implementación recursiva de clasificación rápida
La idea básica de la clasificación rápida es: tomar cualquier elemento de la secuencia de elementos que se van a ordenar como valor de referencia y dividir el conjunto que se va a ordenar en dos subsecuencias de acuerdo con el código de clasificación. Todos los elementos de la subsecuencia izquierda son menores que el valor de referencia, y todos los elementos en la subsecuencia derecha son más pequeños que el valor de referencia. Todos los elementos son mayores que el valor de referencia, y luego el proceso se repite para las subsecuencias izquierda y derecha hasta que todos los elementos estén organizados en sus posiciones correspondientes.
En términos simples, es seleccionar una clave de valor relativamente centrada en la matriz, colocar los elementos más pequeños que la clave a la izquierda de la clave y colocar los elementos más grandes que la clave a la derecha de la clave; y seleccionar la matriz intervalo a la izquierda de la clave Para el nuevo valor central (clave) de este intervalo, repita la operación anterior y luego repita la operación en el lado derecho de la clave. Finalmente, los lados izquierdo y derecho de la clave están en orden , Y la matriz está naturalmente en orden, por supuesto, el valor seleccionado de la clave tiene Presta atención, déjame analizarlo uno por uno a continuación;
En primer lugar, primero encontramos una manera de seleccionar el valor de cada clave y dividir el valor de la clave seleccionada. Aquí hay tres ideas para su referencia:
Idea 1. versión ronca
Primero echemos un vistazo a la versión ronca de la idea de animación:

Obviamente, la idea es definir la clave como el elemento más a la izquierda cada vez, y luego definir dos subíndices L y R, L encuentra elementos más grandes que la clave, R encuentra elementos más pequeños que la clave e intercambiar los subíndices L y R después de encontrar los elementos; luego, a través Con esta idea, podemos obtener el siguiente código:
// 快排排单趟 --- hoare法
int PartSort1(int* a, int left, int right)
{
int keyi = left;
while (left < right)
{
while (left < right && a[right] >= a[keyi])
{
right--;
}
while (left < right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
Swap(&a[keyi], &a[left]);
return left;
}
Entonces todos deben tener una pregunta: ¿cómo podemos garantizar la precisión del último intercambio?
En primer lugar, definimos clave como el elemento más a la izquierda. De hecho, también se puede definir como el elemento más a la derecha. Depende de su elección. Si definimos clave como el elemento más a la izquierda, entonces definitivamente esperamos que el último intercambio con la clave será más largo que la clave. Los elementos pequeños, porque los elementos más pequeños que la clave deben colocarse a la izquierda, entonces, ¿cómo garantizar que la posición donde se encuentran L y R debe ser más pequeña que la clave?
Esto está relacionado con quién va primero, L o R. Supongamos que dejamos que L vaya primero, por ejemplo, la matriz {6, 1, 2, 7, 9, 3, 4, 5, 10, 8} en la animación anterior, Como se muestra a continuación, deje que L vaya primero:

Como se puede ver en la imagen, la posición final donde se encuentran L y R es 9, que no es un valor menor que la clave que queremos, y en la primera imagen animada, R va primero y R va primero. El resultado final nos satisface requerido ¿cuál es el motivo de esta situación?
La razón es simple. L básicamente busca un valor mayor que la clave, mientras que R busca un valor menor que la clave. Si L va primero, R va segundo. Después de encontrar el intercambio de valor correspondiente, L comienza un nuevo 1. Una ronda de búsqueda, buscando un valor mayor que la clave, y después de la ronda de intercambio anterior, el elemento que actualmente se encuentra en L tiene un valor mayor que la clave, si L no encuentra un valor mayor que la clave antes Si se encuentra con R, entonces L eventualmente La posición de parada debe ser donde está R, y debido a que ya se encontraron, R ya no puede moverse, por lo que el valor intercambiado con la clave es un valor mayor que la clave, lo que no cumple con nuestro Expectativas;
Por el contrario, si R va primero y L va después, después de una ronda de intercambio, la posición donde permanece L es un valor menor que la clave, y la posición donde permanece R es un valor mayor que la clave. , R también irá primero. , si no se encuentra ningún valor menor que key antes de encontrar L, entonces el punto de encuentro de R y L debe ser un valor menor que key; incluso si R encuentra un valor menor que key antes de encontrar L, como L se mueve, L definitivamente se encontrará con R, y su punto de encuentro debe ser más pequeño que la clave, por lo que el punto de encuentro y el intercambio de claves cumplen con nuestras expectativas;
Lo anterior es la idea de la versión ronca, a continuación presentamos otra idea;
Idea 2: método de excavación
Como es la vieja regla, primero veamos la idea de la animación:

la idea es muy simple, es decir, considerar el elemento más a la izquierda como la clave, vaciar la posición de la clave y luego definir dos subíndices L y R. Encuentre L más grande que el elemento clave, R busca elementos más pequeños que la clave, porque primero ahuecamos el elemento más a la izquierda y esperamos que todos los elementos de la izquierda sean más pequeños que la clave, por lo que también dejamos que R vaya primero y busque elementos más pequeños. que la llave. Luego colóquelo en el hoyo, formando un nuevo hoyo por sí mismo, luego camine L, encuentre un elemento más grande que la clave, póngalo en el hoyo y forme un nuevo hoyo por sí mismo. Repita este paso hasta que L y R se encuentren , y el punto de encuentro es el foso, simplemente vuelva a colocar la llave en el foso, el código de referencia es el siguiente:
// 快排排单趟 --- 挖坑法
int PartSort2(int* a, int left, int right)
{
int key = a[left];
int hole = left;
while (left < right)
{
// 右边找比 key 小的
while (left < right && a[right] >= key)
{
right--;
}
a[hole] = a[right];
hole = right;
// 左边找比 key 大的
while (left < right && a[left] <= key)
{
left++;
}
a[hole] = a[left];
hole = left;
}
a[hole] = key;
return hole;
}
Idea tres, método de puntero frontal y posterior
Hay otra idea llamada método del puntero delantero y trasero. Veamos primero la idea de la animación:

como se puede ver en la figura, la idea del método del puntero delantero y trasero también es fácil de entender. dos punteros prev y cur, y también consideran el elemento más a la izquierda como clave, cur encuentra un elemento más pequeño que la clave y lo intercambia con la última posición de prev, de modo que los elementos desde la clave + 1 hasta la anterior son todos elementos más pequeños que la clave, y los elementos desde prev + 1 hasta cur son todos elementos más grandes que key, hasta que cur esté vacío, la posición de prev debe ser un elemento más pequeño que key, y finalmente las posiciones de key y prev se pueden intercambiar;
El código de referencia es el siguiente:
// 快排排单趟 --- 前后指针法
int PartSort3(int* a, int left, int right)
{
int keyi = left, cur = left + 1, prev = left;
while (cur <= right)
{
if (a[cur] < a[keyi] && ++prev != cur)
{
Swap(&a[prev], &a[cur]);
}
cur++;
}
Swap(&a[prev], &a[keyi]);
keyi = prev;
return keyi;
}
Las anteriores son nuestras tres ideas para la segmentación clave, entonces, ¿cómo deberíamos implementar la clasificación rápida?
Dado que la operación de división es un poco como el recorrido de preorden en el árbol binario que aprendimos anteriormente, la clave es como el nodo raíz, por lo que podemos usar el pensamiento recursivo para implementarlo;
// 快排 --- 递归实现
void QuickSort(int* a, int left, int right)
{
if (left >= right)
return;
int keyi = PartSort3(a, left, right - 1);
QuickSort(a, left, keyi);
QuickSort(a, keyi + 1, right);
}
Como se puede ver en el código, tomamos el método del puntero frontal y posterior como ejemplo: primero sacamos el subíndice keyi de la clave y luego dividimos los intervalos izquierdo y derecho por clave, es decir, los repetimos y finalmente detenerse cuando esté a la izquierda >= derecha Recursión.
De esta manera, se realiza nuestra clasificación rápida, pero todavía hay algunos defectos en esta clasificación rápida: imagínese, nuestra clave se selecciona de acuerdo con el valor más a la izquierda cada vez, si el valor más a la izquierda es relativamente pequeño en esta matriz cada vez que los elementos, Se realizará una recursión innecesaria y la eficiencia disminuirá. Por lo tanto, para resolver este problema, tenemos la idea de seleccionar la clave entre tres números . El código de referencia para esta idea es el siguiente:
//快排优化:三数取中
int GetMidIndex(int* a, int left, int right)
{
int mid = (left + right) / 2;
if (a[left] < a[mid])
{
if (a[mid] < a[right])
{
return mid;
}
if (a[left] < a[right])
{
return right;
}
else
{
return left;
}
}
// a[left] > a[mid]
else
{
if (a[mid] > a[right])
{
return mid;
}
if (a[left] > a[right])
{
return right;
}
else
{
return left;
}
}
}
Tomamos el subíndice medio mid para los subíndices izquierdo y derecho, luego comparamos estos tres elementos dos por dos y devolvemos el subíndice del elemento en el tamaño medio, lo que aumenta en gran medida la aleatoriedad de la selección de claves;
Entonces, ¿cómo deberíamos utilizar esta función?
Es muy simple, suponiendo que tomamos el método del puntero frontal y posterior como ejemplo, simplemente agregue esta función al comienzo de la función del método del puntero frontal y posterior; pase los subíndices izquierdo y derecho a la función GetMidIndex, obtenga el subíndice midi del elemento numérico del medio, y luego simplemente intercambie los elementos subíndices left y midi;
// 快排排单趟 --- 前后指针法
int PartSort3(int* a, int left, int right)
{
int midi = GetMidIndex(a, left, right);
Swap(&a[left], &a[midi]);
int keyi = left, cur = left + 1, prev = left;
while (cur <= right)
{
if (a[cur] < a[keyi] && ++prev != cur)
{
Swap(&a[prev], &a[cur]);
}
cur++;
}
Swap(&a[prev], &a[keyi]);
keyi = prev;
return keyi;
}
La clasificación rápida recursiva anterior es relativamente perfecta, pero no se ha resuelto para algunos casos especiales. Por ejemplo, cuando se trata de una gran cantidad de elementos idénticos, es muy probable que se obtenga el mismo elemento en la búsqueda de tres números. . También se repetirá la recursión innecesaria, lo que reduce en gran medida la eficiencia. La solución a este problema se llama división de tres vías . Si está interesado, puede aprenderlo usted mismo.
Resumen de funciones de clasificación rápida:
- El rendimiento integral general y los escenarios de uso de la clasificación rápida son relativamente buenos, por lo que se denomina clasificación rápida.
- Complejidad del tiempo: O (N*logN)
- Complejidad del espacio: O (logN) (la recursión consume el espacio del marco de la pila)
- Estabilidad: inestable
6.2 Implementación no recursiva de clasificación rápida
La idea básica de la clasificación rápida no recursiva es: usar la pila para simular operaciones recursivas. Estrictamente hablando, no simula la implementación recursiva, sino que usa la pila para implementar operaciones recursivas;
Por ejemplo, en la matriz {6, 1, 2, 7, 9, 3, 4, 5, 10, 8}, supongamos que usamos la más a la izquierda como clave cada vez, como se muestra en la siguiente figura. a continuación solo se ejecuta hasta la segunda vez para obtener el valor de keyi:

como se muestra en la imagen de arriba, cuando obtiene el valor de keyi por segunda vez, en realidad repite la operación al comienzo de la imagen de arriba y continúa presionando hacia la izquierda. y rangos derechos en la pila. De acuerdo con las características de la pila, el último en entrar, el primero en salir, la pila procesará el último en entrar primero. El subíndice del elemento de, simulamos el intervalo izquierdo de keyi hacia atrás, por lo que la pila procesará primero el intervalo izquierdo de keyi y luego procese el intervalo derecho de keyi;
En segundo lugar, para implementar la simulación de pila, primero necesitamos tener una pila. Según la revisión anterior, utilizamos directamente la pila implementada anteriormente. Consulte los enlaces de pila y cola para obtener más detalles .
El código de referencia es el siguiente:
// 快排 --- 非递归
void QuickSortNonR(int* a, int begin, int end)
{
ST st;
STInit(&st);
// 一开始先将两边的元素入栈
STPushTop(&st, end - 1);
STPushTop(&st, begin);
// 栈不为空就继续
while (!STIsEmpty(&st))
{
// 取一次,出一次栈
int left = STTop(&st);
STPopTop(&st);
// 取一次,出一次栈
int right = STTop(&st);
STPopTop(&st);
// 取出 keyi 的值
int keyi = PartSort3(a, left, right);
// 在符合的区间内就继续将其左右区间入栈
if (keyi + 1 < right)
{
STPushTop(&st, right);
STPushTop(&st, keyi + 1);
}
if (left < keyi - 1)
{
STPushTop(&st, keyi - 1);
STPushTop(&st, left);
}
}
STDestroy(&st);
}
7. Combinar clasificación
7.1 Implementación recursiva de clasificación por fusión
Idea básica: Merge sort es un algoritmo de clasificación eficaz basado en operaciones de fusión. Este algoritmo es una aplicación muy típica del método divide y vencerás. Combine las subsecuencias ordenadas para obtener una secuencia completamente ordenada, es decir, primero ordene cada subsecuencia y luego ordene los segmentos de la subsecuencia. Si dos listas ordenadas se fusionan en una lista ordenada, se denomina fusión bidireccional.
Observe la idea de animación a continuación:

Por ejemplo, la matriz {10, 6, 7, 1, 3, 9, 2, 4}, observe la animación más intuitiva: 
según las ideas anteriores, primero pensamos que su idea es un poco como el recorrido posterior al orden. en un árbol binario, primero, sus subsecuencias se organizan en orden y, finalmente, las dos subsecuencias relativamente ordenadas se fusionan, por lo que también podemos usar ideas recursivas aquí para implementar operaciones similares al recorrido posterior al orden;
Primero necesitamos una subfunción para dividir y ordenar la subsecuencia:
// 归并的区间划分
void PartOfMergeSort(int* a, int begin, int end, int* tmp)
{
if (begin == end)
return;
// 小区间优化
if (end - begin + 1 < 10)
{
InsertSort(a + begin, end - begin + 1);
return;
}
int mid = (begin + end) / 2;
// 划分的区间为:
// [begin,mid] [mid + 1,end]
PartOfMergeSort(a, begin, mid, tmp);
PartOfMergeSort(a, mid + 1, end, tmp);
// 对每个区间进行归并排序
int begin1 = begin, end1 = mid;
int begin2 = mid + 1, end2 = end;
int pos = begin;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] <= a[begin2])
tmp[pos++] = a[begin1++];
else
tmp[pos++] = a[begin2++];
}
while (begin1 <= end1)
tmp[pos++] = a[begin1++];
while (begin2 <= end2)
tmp[pos++] = a[begin2++];
// 将这段已经排序好的空间拷贝回原数组
memcpy(a + begin, tmp + begin, sizeof(int) * (end - begin + 1));
}
En la función anterior, cada vez que ingresa a la función, se tomará el subíndice medio, se dividirá el área y se recurrirá a sus subrangos izquierdo y derecho. La condición para detener la recursividad al final es comenzar == finaliza y luego regresa al nivel de recursividad anterior. Las subsecuencias de un nivel se fusionan y ordenan. Después de ordenar cada subsecuencia, se copia nuevamente a la matriz original y luego continúa regresando al nivel anterior para ordenar las subsecuencias. del nivel anterior hasta que regrese al primer nivel, al regresar al primer nivel, las subsecuencias izquierda y derecha están La secuencia ha sido ordenada, simplemente realice la última ordenación por combinación;
En segundo lugar, podemos ver que agregamos una pequeña optimización a la función anterior, es decir, cuando los elementos en el intervalo son menores de 10, elegimos la ordenación por inserción directa, porque cuando los elementos en el intervalo son menores de 10 , continuar con la recursividad consumirá Para obtener más espacio y eficiencia, es mejor reemplazar esta recursividad innecesaria con ordenación por inserción directa;
// 归并 --- 递归
void MergeSort(int* a, int n)
{
// 需要一段空间进行临时拷贝
int* tmp = (int*)malloc(sizeof(int) * n);
PartOfMergeSort(a, 0, n - 1, tmp);
free(tmp);
}
7.2 Implementación no recursiva de clasificación por fusión
La implementación no recursiva de la clasificación por fusión, la idea básica es controlar el valor de la brecha y considerar 2 * brecha como una subsecuencia. Después de ordenar la subsecuencia de esta ronda de brecha, la brecha * = 2 y luego fusionar la siguiente subsecuencia, termina hasta que el valor de la brecha sea mayor que la longitud de la matriz;
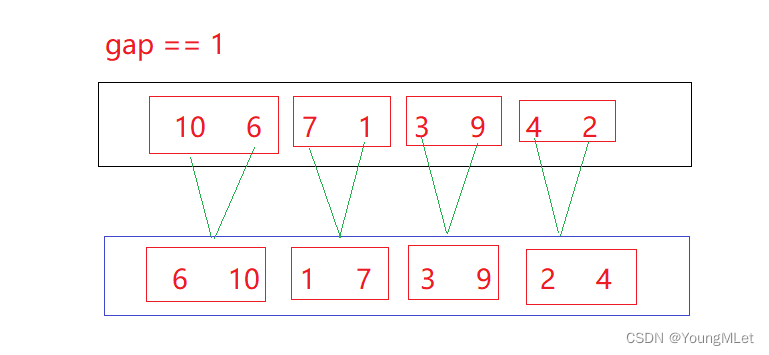
Por ejemplo, la matriz {10, 6, 7, 1, 3, 9, 4, 2},
cuando la brecha == 1:
cuando la brecha == 2:
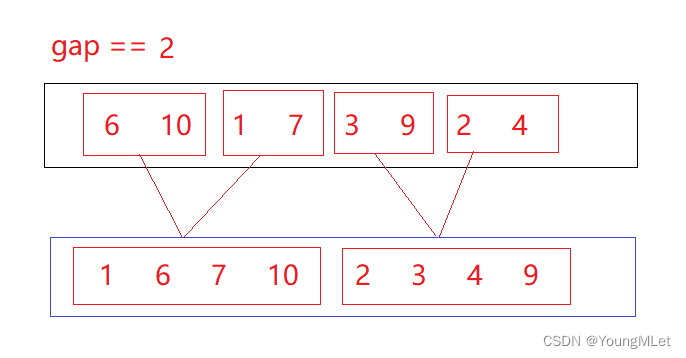
cuando la brecha == 4:
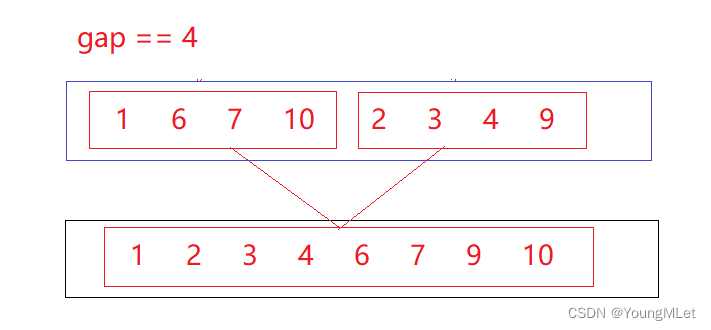
como se muestra arriba, cuando la brecha == 4 , la matriz tiene Después de ordenar, simplemente copie la matriz nuevamente a la matriz original; el código de referencia es el siguiente:
// 归并 --- 非递归
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
assert(tmp);
int gap = 1;
while (gap < n)
{
int pos = 0;
for (int i = 0; i < n; i += 2 * gap)
{
// 给定两个归并区间的范围
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
// 有一个区间结束就结束
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] <= a[begin2])
{
tmp[pos++] = a[begin1++];
}
else
{
tmp[pos++] = a[begin2++];
}
}
// 判断两个区间是否都结束了
while (begin1 <= end1)
{
tmp[pos++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[pos++] = a[begin2++];
}
}
// 更新 gap
gap *= 2;
}
}
En este momento tenemos que enfrentarnos a una pregunta, cuando sumamos 1 a 2 datos, ¿el resultado será el mismo? Podemos verlo haciendo un dibujo. Cuando la matriz es {10, 6, 7, 1, 3, 9, 4, 2, 0}, es decir, se agrega un 0 a la matriz anterior. El dibujo es el siguiente : De la
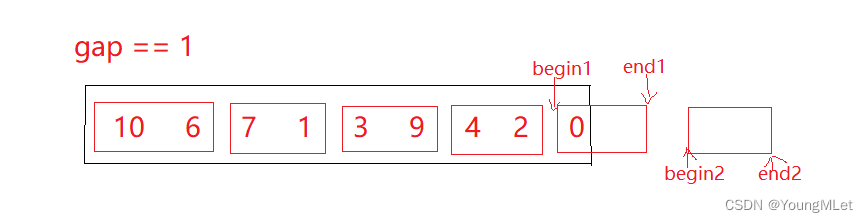
figura se puede ver que cuando la brecha == 1, el problema ya ocurrió, end1, begin2, end2 están todos fuera de los límites;
Algunas personas piensan que un número impar de elementos no funcionará, y cuando la matriz es {10, 6, 7, 1, 3, 9, 4, 2, 0, 5}, es decir, se agrega un elemento adicional a la La matriz anterior, en este momento tiene 10 elementos, y el dibujo es el siguiente:

cuando el número de elementos es par, todavía cruza el límite, en este momento tenemos que enfrentar un problema, es decir, al dividir el rango , el intervalo de límite puede enfrentar el problema de cruzar el límite. En este momento necesitamos corregir el alcance del límite. Hay dos opciones de corrección:
Opción 1 : Debido a que comenzar1 == i e i no pueden cruzar el límite, comenzar1 no puede cruzar el límite y final1, comenzar2 y final2 pueden cruzar el límite. En este momento, podemos hacer las siguientes correcciones:
// 修正边界值(方法一:适用归并一组拷贝一组)
if (end1 >= n || begin2 >= n)
{
break;
}
if (end2 >= n)
{
end2 = n - 1;
}
Agréguelo a la función de la siguiente manera:
// 归并 --- 非递归
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
assert(tmp);
int gap = 1;
while (gap < n)
{
int pos = 0;
for (int i = 0; i < n; i += 2 * gap)
{
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
// 修正边界值(方法一:适用归并一组拷贝一组)
if (end1 >= n || begin2 >= n)
{
break;
}
if (end2 >= n)
{
end2 = n - 1;
}
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] <= a[begin2])
{
tmp[pos++] = a[begin1++];
}
else
{
tmp[pos++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[pos++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[pos++] = a[begin2++];
}
// 归并一组,拷贝一组
memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));
}
gap *= 2;
}
}
Tenga en cuenta que la solución uno requiere fusionar un grupo y copiar un grupo. Su solución es saltar del bucle directamente cuando comienza2 o final1 cruza el límite. Este intervalo no se moverá en la matriz original;
Opción 2 : agréguelo directamente a la función de la siguiente manera:
// 归并 --- 非递归
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
assert(tmp);
int gap = 1;
while (gap < n)
{
int pos = 0;
for (int i = 0; i < n; i += 2 * gap)
{
// 给定两个归并区间的范围
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
// 修正边界值(方法二:适用归并完当前 gap 再拷贝)
if (end1 >= n)
{
end1 = n - 1;
// 将第二个区间变成不存在的区间
begin2 = n;
end2 = n - 1;
}
else if (begin2 >= n)
{
// 变成不存在的区间
begin2 = n;
end2 = n - 1;
}
else if (end2 >= n)
{
end2 = n - 1;
}
// 有一个区间结束就结束
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] <= a[begin2])
{
tmp[pos++] = a[begin1++];
}
else
{
tmp[pos++] = a[begin2++];
}
}
// 判断两个区间是否都结束了
while (begin1 <= end1)
{
tmp[pos++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[pos++] = a[begin2++];
}
}
// 归并完当前 gap 全部拷贝
memcpy(a, tmp, sizeof(int) * n);
gap *= 2;
}
}
La idea de la segunda opción es modificar todos los valores de límite fuera del borde, y solo es necesario modificarlos para comenzar2> final2; esta opción de modificación puede fusionar directamente el grupo de espacio actual sin fusionar ni copiar un grupo. Luego, cópielo nuevamente a la matriz original de inmediato;
Lo anterior es un análisis de las ideas de ordenación por fusión y un resumen de las características de la ordenación por fusión:
- La desventaja de la fusión es que requiere una complejidad espacial O (N). La idea de fusionar y ordenar se trata más de resolver el problema de clasificación externa en el disco.
- Complejidad del tiempo: O (N*logN)
- Complejidad espacial: O (N)
- Estabilidad: estable
* 8. Clasificación por conteo
La clasificación por conteo es una clasificación no comparativa: utiliza otro hash de matriz para registrar el número de apariciones de elementos en la matriz que se va a ordenar, luego atraviesa la matriz hash una vez, coloca los elementos que aparecen en la matriz en orden y disminuye después. cada ubicación Una vez, hasta que el número de apariciones de elementos que han aparecido se reduzca a 0, lo que equivale a ordenar;
Este algoritmo de clasificación solo necesita ser entendido porque tiene grandes limitaciones y dos fallas principales:
Defecto 1 : depende del rango de datos y es adecuado para matrices en el rango;
Defecto 2 : solo se puede usar para dar forma;
Por lo tanto, no analizaré demasiado aquí y los socios interesados pueden aprenderlo por sí mismos;
el código de referencia es el siguiente:
// 计数排序
void CountSort(int* a, int n)
{
// 找出最大的元素和最小的元素
int max = a[0], min = a[0];
for (int i = 0; i < n; i++)
{
if (a[i] > max)
{
max = a[i];
}
if (a[i] < min)
{
min = a[i];
}
}
// 计算这个数组的最大值和最小值的范围
// 计算相对范围
int range = max - min + 1;
// 开辟空间,长度就是相对的范围
int* hash = (int*)malloc(sizeof(int) * range);
assert(hash);
// 将空间初始化为 0
memset(hash, 0, sizeof(int) * range);
// 统计某个元素在相对位置出现的次数
for (int i = 0; i < n; i++)
{
hash[a[i] - min]++;
}
// 遍历相对范围,如果相对位置不为 0,说明出现过,就将这个元素的相对值放入元素中覆盖即可,然后出现的次数自减
int pos = 0;
for (int i = 0; i < range; i++)
{
while (hash[i] != 0)
{
a[pos++] = i + min;
hash[i]--;
}
}
}
3. Complejidad y estabilidad de diversas clasificaciones.
Primero que nada, necesitamos entender un concepto: ¿qué es estabilidad?
Estabilidad : Supongamos que hay varios registros con la misma palabra clave en la secuencia de registros que se va a ordenar. Si se ordenan, el orden relativo de estos registros permanece sin cambios, es decir, en la secuencia original, r[i] = r[j], y r[i] está antes de r[j], y en la secuencia ordenada, r[i] todavía está antes de r[j], entonces este algoritmo de clasificación se llama estable; de lo contrario, se llama inestable.
Por lo tanto, después del análisis, obtuvimos la complejidad temporal, la complejidad espacial y la estabilidad de varios algoritmos de clasificación de la siguiente manera: Lo anterior es
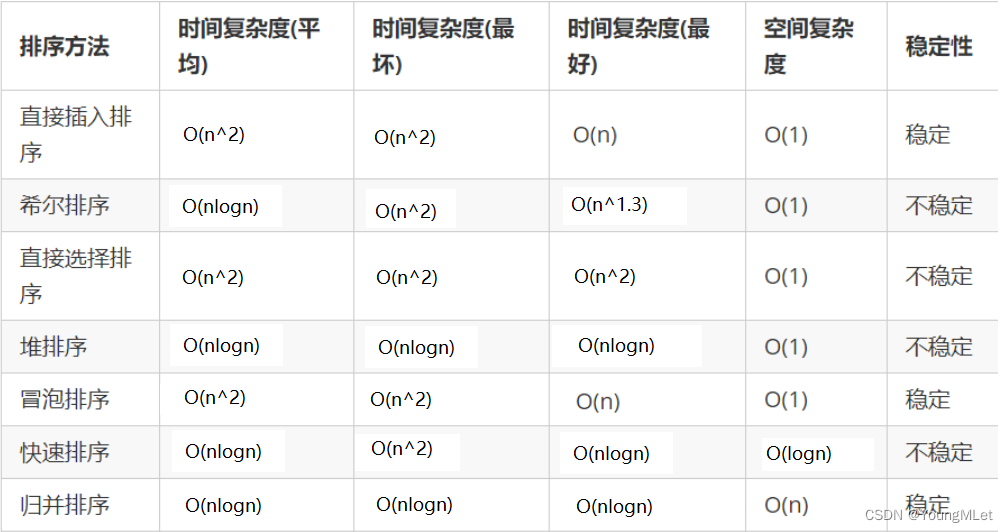
mi idea de clasificación común, si hay algo incorrecto o que se pueda modificar, gracias ¡Señale!