1. Introducción básica
Un árbol de decisión es una estructura de árbol similar a un diagrama de flujo, en el que cada nodo interno representa una prueba sobre un atributo, cada rama representa una salida de la prueba y cada nodo hoja (nodo terminal) almacena un resultado de clasificación.
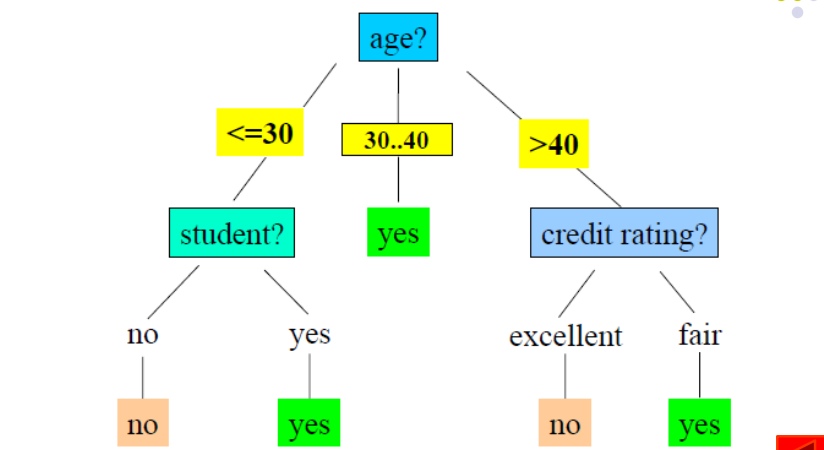
La imagen de arriba es un ejemplo de una decisión.
Después de construir el árbol de decisión, es fácil clasificar los registros de inspección. Comenzando desde el nodo raíz del árbol, aplique las condiciones de prueba a los registros de inspección y siga las ramas del árbol hasta los nodos hoja para obtener los resultados de la clasificación. .
2. Construcción del árbol de decisión
En principio, para un conjunto dado de atributos, hay muchos árboles de decisión que se pueden construir, entonces, ¿cómo construir un árbol de decisión con cierta precisión en un tiempo razonable? Se suelen utilizar algoritmos vorazes, es decir, al seleccionar atributos para dividir datos se utilizan una serie de decisiones localmente óptimas para construir un árbol de decisión.
El proceso de construcción del árbol de decisión debe considerar dos preguntas
(1) ¿Qué atributo elegir para dividir los datos? Es decir, cómo medir el impacto de este atributo en el conjunto de datos después de la división.
(2) Condiciones para detener la división.
Al mismo tiempo, también se deben considerar diferentes situaciones de atributos.
1. Método de medición de selección de atributos:
El algoritmo ID3/C4.5 elige la ganancia de información como método de medición : el algoritmo original solo es adecuado para atributos nominales y, después de la mejora, puede usarse en atributos continuos.
El algoritmo CART elige el índice de Gini como método de medición : el algoritmo original solo es adecuado para atributos continuos y, después de la mejora, puede usarse en atributos nominales.
Entropía de la información : la definición de entropía es la siguiente:

si una cosa es más cierta, la probabilidad de que ocurra es mayor y la entropía de la información es menor. Si una cosa es más incierta, la probabilidad de ocurrencia es menor y la entropía de la información es mayor.
Entropía de información esperada de todo el espacio de información :
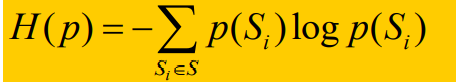
la medida de atributo utilizada por el algoritmo del árbol de decisión ID3 es la ganancia de información.La
ganancia de información se define de la siguiente manera:

Cuando la etiqueta de categoría tiene m valores diferentes, defina m clases diferentes Ci (i = 1, 2, ..., m), D es el conjunto de datos, sea Ci,d el conjunto de tuplas de la clase Ci en D , |D|, |Ci,d| son el número de tuplas en D y Ci,d respectivamente, entonces la entropía de información esperada de todo el espacio D del conjunto de datos es donde Pi = |Ci,d| / |D|, que
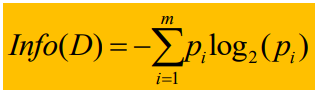
representa Probabilidades de diferentes clases en D. Info representa la cantidad promedio de información requerida para identificar las etiquetas de clase de las tuplas en D, también conocida como la entropía de información de D.
Supongamos que D se divide en D1, D2,..., Dv con diferentes valores del atributo A.
Entre ellos, para cualquier Dj, su valor de atributo A es Aj, y para el espacio después de que se divide el atributo A, la correspondiente entropía de información esperada
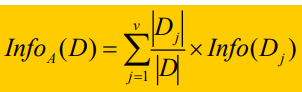
donde:
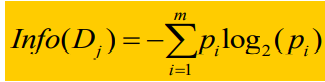
Entre ellos, |Dj| representa el número de tuplas Dj (es decir, el valor del atributo A es igual al número de tuplas de Aj), y |D| representa el número de ramas divididas según el atributo A.
Info(Dj) representa la entropía de información esperada del espacio cuando el atributo A = Aj.
Mi entendimiento es el siguiente:
todo el espacio del conjunto de datos se divide en diferentes espacios Dj de acuerdo con los diferentes valores de A (Aj). Para cada espacio Dj, también hay casos en los que las etiquetas de categoría son diferentes.
Por lo tanto, cuando se divide el espacio del conjunto de datos D, la entropía de información esperada del espacio de cálculo se divide en dos pasos. El primer paso es calcular Info(Dj) para cada subespacio Dj. El segundo paso es calcular todo el espacio según a la probabilidad de cada subespacio Dj.expectativas.
Entonces, la ganancia de información representa la diferencia entre la entropía de información original y la nueva entropía de información.
El algoritmo ID3 seleccionará el atributo con la mayor ganancia de información como el atributo de partición, es decir, el atributo de partición A seleccionado hará que el espacio después de la partición tenga el valor de entropía más pequeño, es decir, el más estable.
Desventajas del algoritmo ID3 :
(1) El algoritmo ID3 tiende a seleccionar atributos con más valores de atributo, porque cuando los valores de atributo son más, la entropía de información después de la división es menor y la ganancia de información correspondiente es mayor.
(2) El algoritmo ID3 solo puede manejar atributos discretos.
Para abordar la deficiencia 1, el algoritmo C4.5 ha realizado las siguientes mejoras:
seleccione el atributo con la mayor tasa de ganancia de información como el atributo dividido y
la fórmula para la tasa de ganancia es la siguiente:
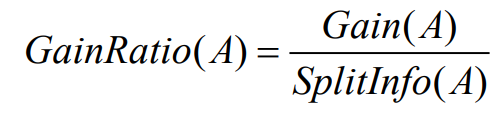
Entre ellos, Ganancia (A) es la igual que la definición del algoritmo ID3, y
la información dividida SplitInfo (A) se define como:
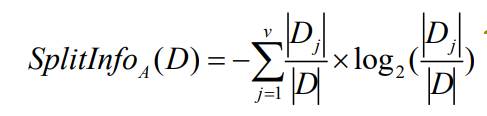
Para la desventaja 2 :
ordenar los valores de A en orden ascendente, y el punto medio de cada par de valores adyacentes se considera como un posible punto de división, por lo que dados los valores de V de A, es necesario calcular V-1 posibles divisiones
Para cada posible punto de división de A, calcule Info(D), donde el número de particiones es 2, y el punto de A con el mínimo requisito de información esperado se selecciona como el punto de división de A.
El algoritmo CART elige el índice de Gini como método de medición.Gini
(T) se define de la siguiente manera:
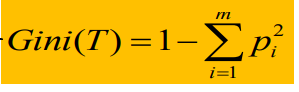
También se puede considerar que calcula la impureza, donde Pi representa la probabilidad de la etiqueta de categoría i.
Si el conjunto de datos se divide en dos subconjuntos T1 y T2 cuyos tamaños son N1 y N2 respectivamente por el atributo A. Entonces, el Gini después de la división se define como:

seleccione  el atributo con el valor más pequeño como atributo de división.
el atributo con el valor más pequeño como atributo de división.
Eso es elegir 
el atributo más grande como el atributo de partición.
2. Ejemplo de cálculo
Tema:
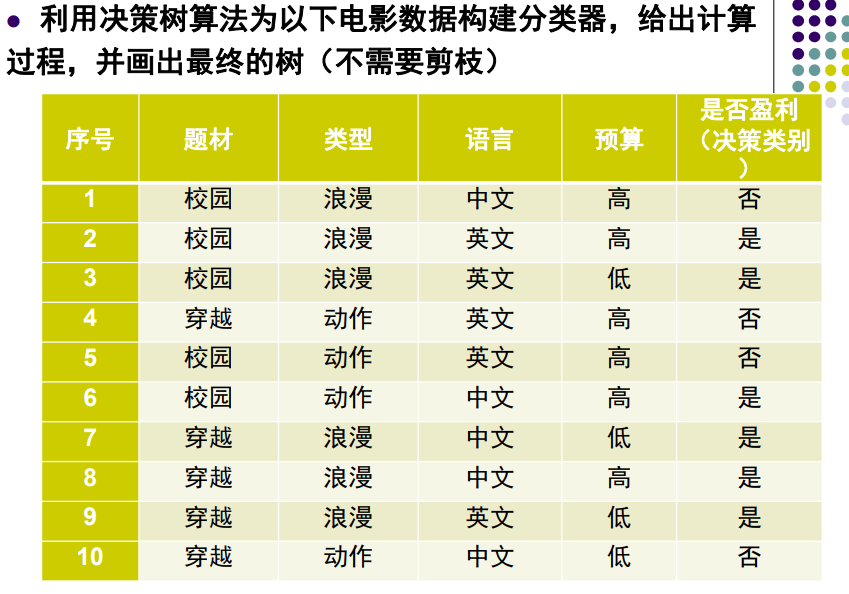
Use el algoritmo ID3 para construir un árbol de decisión.
Calcule Infor (D) y la entropía de información correspondiente a cada atributo,
y luego seleccione el atributo con la mayor ganancia de información como atributo dividido.
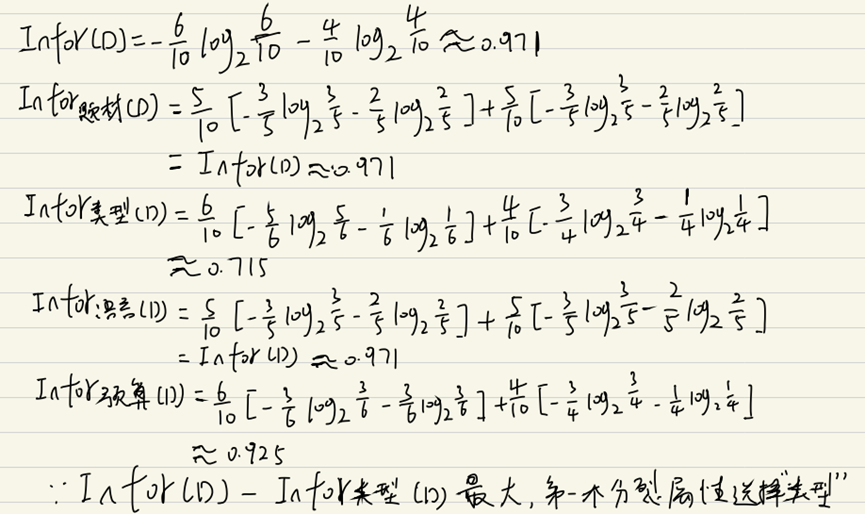
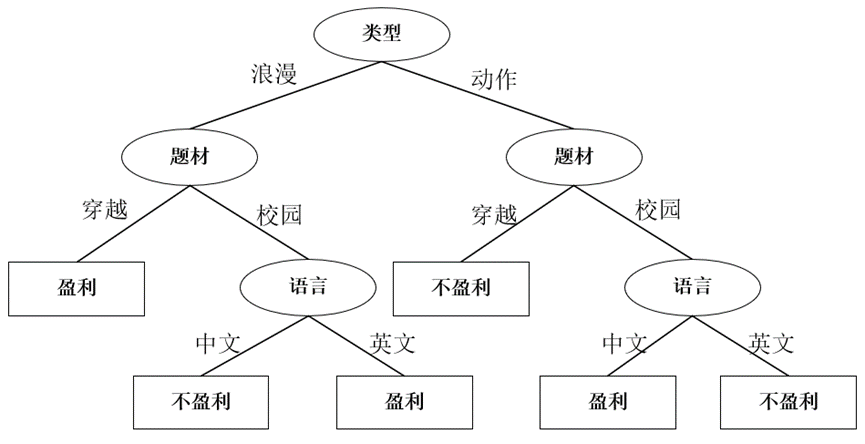
El primer atributo selecciona "tipo" como el atributo de división, y el árbol de decisión es el siguiente:
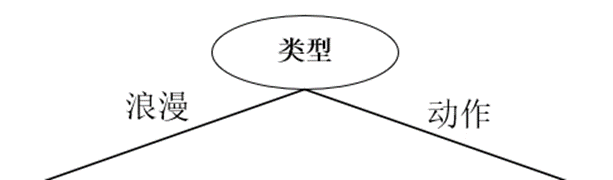
Luego, para el subárbol izquierdo del nodo 'tipo', cuando tipo == 'romántico', los datos son los siguientes:
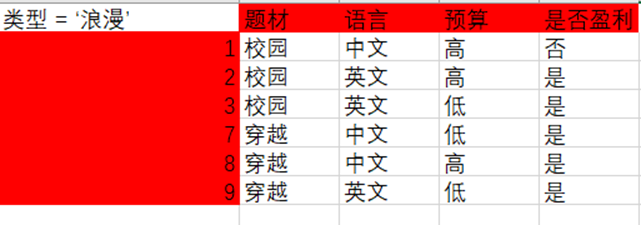
calcular la ganancia de información nuevamente

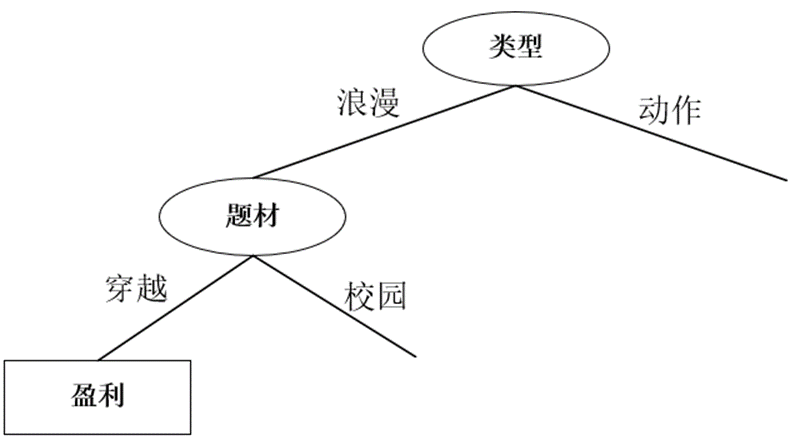
y seleccione el tema como el atributo de división, y tome la decisión. El árbol es el siguiente:
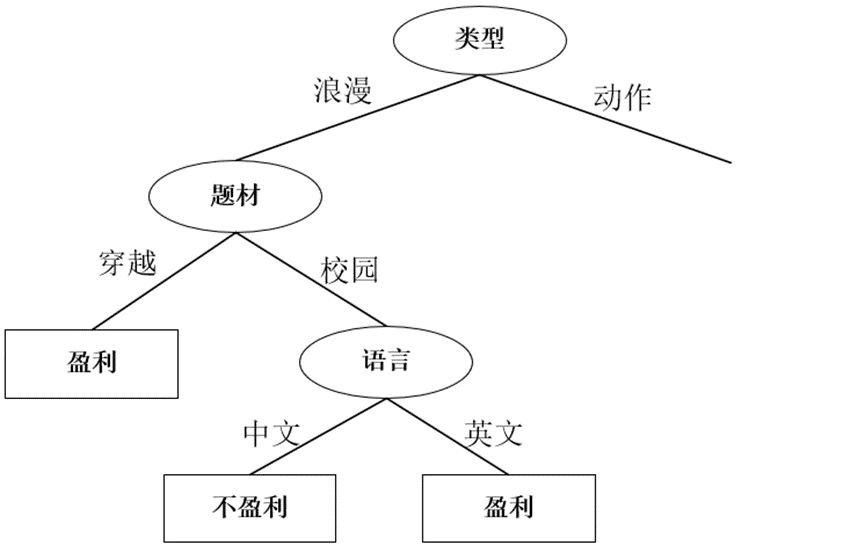
Para el subárbol derecho del nodo 'tema', cuando escriba == 'romántico' y tema == 'campus', la tabla es como siguiente: Calcule la

ganancia de información nuevamente.

Seleccione el idioma como el atributo dividido, el árbol de decisión es el siguiente:
Luego, para el subárbol derecho del nodo 'tipo', cuando el tipo == 'acción', el gráfico se convierte en el siguiente:
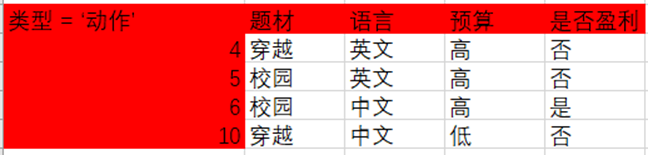
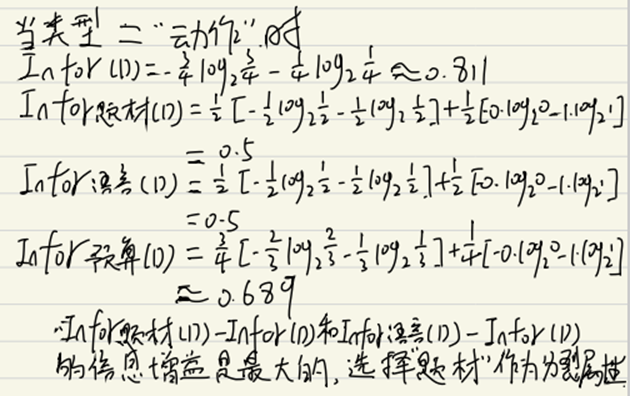
Dado que el La ganancia de información de seleccionar el tema y el idioma es igual y es la más grande al mismo tiempo, está bien elegir cualquiera como atributo de división.Selecciono Asunto como atributo de división. El árbol de decisión es el siguiente: 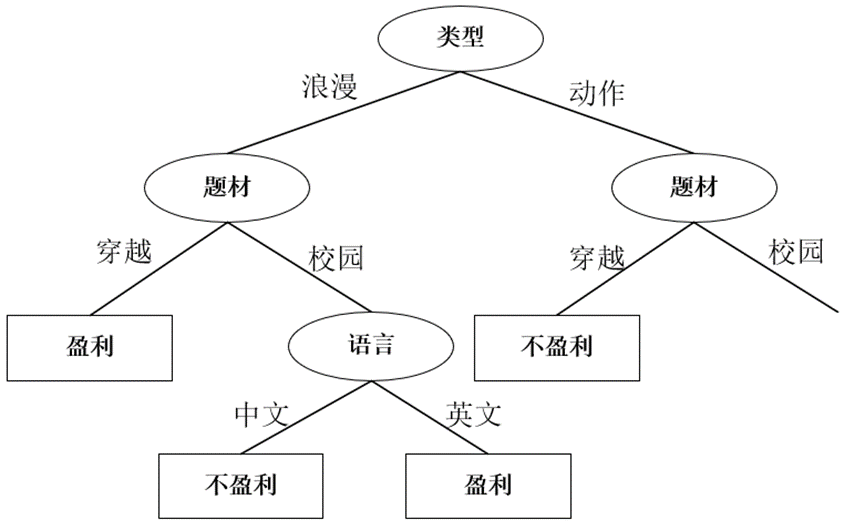
Para el subárbol derecho del nodo 'asunto', cuando tipo = 'acción' y asunto = 'campus', la tabla es la siguiente:


seleccione el idioma como atributo dividido, el árbol de decisión es el siguiente :