La agrupación en clústeres es un método común de aprendizaje no supervisado, que es simplemente el proceso de agrupar muestras de datos similares en un grupo (clúster) y agrupar.
No sabemos qué es una determinada clase (generalmente sin información de etiqueta), y el objetivo que se debe lograr es agrupar muestras similares, es decir, usar la ley de distribución de los datos de muestra en sí.
En este artículo, presentaré el algoritmo de agrupamiento en detalle. Si le gusta este artículo, recuerde marcar, seguir y dar me gusta.
[Nota] La versión completa del código, los datos y el intercambio técnico se proporciona al final del artículo.
Los algoritmos de agrupamiento se pueden dividir aproximadamente en algoritmos de agrupamiento tradicionales y algoritmos de agrupamiento profundo :
-
El algoritmo de agrupamiento tradicional se basa principalmente en las características originales + en la división/densidad/jerarquía y otros métodos.

-
El método de agrupamiento profundo se basa principalmente en las características posteriores al aprendizaje de representación + algoritmo de agrupamiento tradicional.

ksignifica principio de agrupación
Se puede decir que el agrupamiento de Kmeans es el algoritmo de agrupamiento más común. Se agrupa según el método de partición. El principio es inicializar k centros de conglomerados primero y resumir las muestras en cada conglomerado en función de la distancia entre la muestra calculada y el centro. Lograr iterativamente el objetivo de minimizar la distancia entre la muestra y el centro del conglomerado al que pertenece (la siguiente función objetivo).
Los pasos del algoritmo de optimización son:
1. Seleccionar aleatoriamente k muestras como el centro del conglomerado inicial (k es un hiperparámetro que representa el número de conglomerados. El valor se puede determinar en base a conocimientos previos y métodos de verificación);
2. Calcule la distancia de cada muestra en el conjunto de datos a los k centros del conglomerado y asígnela a la clase correspondiente al centro del conglomerado con la distancia más pequeña;
3. Para cada grupo, vuelva a calcular su posición central del grupo;
4. Repita los pasos iterativos 2 y 3 anteriores hasta que se alcance una determinada condición de terminación (como el número de iteraciones, la posición del centro del clúster permanece sin cambios, etc.).

....
#kmeans算法是初始化随机k个中心点
random.seed(1)
center = [[self.data[i][r] for i in range(1, len((self.data)))]
for r in random.sample(range(len(self.data)), k)]
#最大迭代次数iters
for i in range(self.iters):
class_dict = self.count_distance() #计算距离,比较个样本到各个中心的的出最小值,并划分到相应的类
self.locate_center(class_dict) # 重新计算中心点
#print(self.data_dict)
print("----------------迭代%d次----------------"%i)
print(self.center_dict) #聚类结果{k:{
{center:[]},{distance:{item:0.0},{classify:[]}}}}
if sorted(self.center) == sorted(self.new_center):
break
else:
self.center = self.new_center
Se puede observar que el algoritmo iterativo de agrupamiento de Kmeans es en realidad el algoritmo EM El algoritmo EM resuelve el problema de estimación de parámetros cuando el modelo de probabilidad contiene variables ocultas que no se pueden observar.
La variable latente en Kmeans es la categoría a la que pertenece cada categoría. Después de cada confirmación del punto central en el paso iterativo del algoritmo Kmeans, márquelo nuevamente correspondiente al paso E en el algoritmo EM para encontrar la Expectativa bajo las condiciones del parámetro actual. Y de acuerdo con la marca para volver a encontrar el punto central correspondiente a los M pasos en el algoritmo EM cuando se maximiza la función de probabilidad (cuando la función de pérdida es la más pequeña), los parámetros correspondientes. La desventaja del algoritmo EM es que es fácil caer en los mínimos locales, razón por la cual Kmeans a veces obtiene una solución óptima local.
Elija una métrica de distancia
El algoritmo kmeans se calcula en función de la similitud de la distancia para determinar el punto central más cercano al que pertenece cada muestra. Las medidas de distancia comunes incluyen la distancia de Manhattan y la distancia euclidiana.
- Fórmula de la distancia de Manhattan:

- Fórmula de la distancia euclidiana:
 El método de cálculo de la distancia de Manhattan y euclidiana es muy simple, que consiste en calcular la distancia total entre cada característica i de dos muestras (x, y). Como se muestra en la figura a continuación (en el caso de características bidimensionales), la distancia de la línea azul es la distancia de Manhattan (imagine que está conduciendo de una intersección a otra en Manhattan. La distancia de conducción real es esta "Manhattan distancia", también conocida como la distancia de bloque de la ciudad), la línea roja es la distancia euclidiana:
El método de cálculo de la distancia de Manhattan y euclidiana es muy simple, que consiste en calcular la distancia total entre cada característica i de dos muestras (x, y). Como se muestra en la figura a continuación (en el caso de características bidimensionales), la distancia de la línea azul es la distancia de Manhattan (imagine que está conduciendo de una intersección a otra en Manhattan. La distancia de conducción real es esta "Manhattan distancia", también conocida como la distancia de bloque de la ciudad), la línea roja es la distancia euclidiana:

En cuarto lugar, la determinación del valor k.
kmeans se divide en k grupos, y el efecto del algoritmo puede ser muy diferente en diferentes k casos. La determinación del valor K se utiliza comúnmente: método a priori, método del codo y otros métodos.
- método a priori
El priori es relativamente simple, es decir, el valor de k se determina en base al conocimiento del negocio. Por ejemplo, para el conjunto de datos de la flor del iris, probablemente sabemos que hay tres categorías, que se pueden verificar agrupando según k=3. Como se puede ver en la figura a continuación, la predicción de agrupamiento comparativo es más consistente con las especies reales de iris.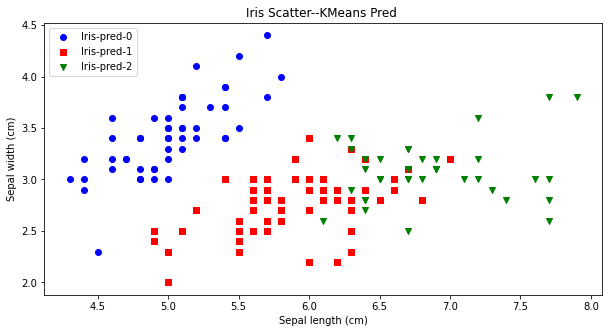

- método del codo
Se puede saber que cuanto mayor sea el valor de k, más conglomerados se dividirán, y menor será la suma de los cuadrados de las distancias de los puntos correspondientes al centro del conglomerado (distancia intraclase, WSS), podemos determine la curva que WSS disminuye con el aumento de K. Punto de inflexión, como el valor de K.
La desventaja del método del codo es que requiere el juicio humano y no está lo suficientemente automatizado.Existen otros métodos como:
-
Utilizando el método estadístico Gap, se determinó el valor de k.
-
Verifique el coeficiente de silueta promedio de diferentes valores de K, cuanto más cerca esté de 1, mejor será el efecto de agrupamiento.
-
Verifique la distancia intraclase/distancia interclase de diferentes valores de K, cuanto menor sea el valor, mejor.
-
Algoritmo ISODATA: se basa en el algoritmo k-means, agregando dos operaciones de "fusión" y "división" de los resultados de la agrupación para determinar el resultado final de la agrupación. Por lo tanto, no hay necesidad de especificar manualmente el valor de k.
5. Defectos de Ksignifica
5.1 El problema de inicializar el punto central
kmeans usa puntos centrales de inicialización aleatorios, y diferentes puntos centrales de inicialización tienen un mayor impacto en los resultados del algoritmo. Por lo tanto, el algoritmo Kmeans++ se actualizó en respuesta a este punto, y su idea de inicialización fue: los centros de cada grupo deben estar lo más alejados entre sí como sea posible. En función de los componentes de distancia desde cada punto hasta el punto central existente, se seleccionan aleatoriamente k elementos como el punto central en secuencia. Cuanto mayor sea la distancia desde el punto central del grupo identificado, más probable (probabilidad proporcional al cuadrado de la distancia) de ser seleccionado como el punto central de otro grupo. El siguiente código.
# Kmeans ++ 算法基于距离概率选择k个中心点
# 1.随机选择一个点
center = []
center.append(random.choice(range(len(self.data[0]))))
# 2.根据距离的概率选择其他中心点
for i in range(self.k - 1):
weights = [self.distance_closest(self.data[0][x], center)
for x in range(len(self.data[0])) if x not in center]
dp = [x for x in range(len(self.data[0])) if x not in center]
total = sum(weights)
#基于距离设定权重
weights = [weight/total for weight in weights]
num = random.random()
x = -1
i = 0
while i < num :
x += 1
i += weights[x]
center.append(dp[x])
center = [self.data_dict[self.data[0][center[k]]] for k in range(len(center))]
5.2 Kernel Ksignifica
Kmedias basadas en la distancia euclidiana asume que los datos de cada grupo de datos tienen la misma probabilidad previa y presenta una distribución esférica, pero esta distribución no es común en la vida real. En vista de la forma de distribución de datos no convexa, podemos introducir la función kernel para optimizar.En este momento, el algoritmo también se llama algoritmo kernel Kmeans, que es un tipo de método de agrupación de kernel. La idea principal del método de agrupación en clústeres del kernel es asignar los puntos de datos en el espacio de entrada al espacio de características de alto nivel a través de un mapeo no lineal y realizar la agrupación en el nuevo espacio de características. El mapeo no lineal aumenta la probabilidad de que los puntos de datos sean linealmente separables, de modo que cuando el algoritmo de agrupamiento clásico falla, se pueden lograr resultados de agrupamiento más precisos mediante la introducción de una función kernel.
5.3 Tipos de características
kmeans son características orientadas numéricamente, y se requieren métodos de codificación onehot u otros para las características categóricas. Además, existen algoritmos K-Modes y K-Prototypes que se pueden usar para agrupar tipos mixtos de datos.Para el centro de clase de clúster de características numéricas, obtenemos el valor medio de cada característica, mientras que el centro de características categóricas obtiene el modo, y la distancia de cálculo adopta la distancia de Hamming. , 0 de lo contrario 1.
5.4 Pesos de las características
La agrupación se calcula en función de la distancia entre las características. Al calcular la distancia, debe prestar atención a la diferencia de las dimensiones de la característica. Cuanto mayor sea la dimensión, mayor será el peso de la característica. Suponiendo que cada muestra tiene dos variables características de edad y salario, por ejemplo, al calcular la distancia euclidiana, el valor de (edad 1-edad 2)² es mucho menor que (salario 1-salario 2)², lo que significa que el no se utiliza el escalado de características En el caso de , la distancia está dominada por la variable salario (un valor grande). Por lo tanto, necesitamos usar el escalado de características para unificar todos los valores a un orden de magnitud para resolver este problema. La solución habitual es "normalizar" o "normalizar" los datos, unificando todas las características numéricas a un rango estándar como 0~1.
Las características normalizadas son pesos uniformes y, a veces, necesitamos asignar pesos más grandes a diferentes características. Supongamos que queremos que el peso de la función 1 sea 1 y el peso de la función 2 sea 2, después de normalizar de 0 a 1, al realizar un cálculo similar a la distancia euclidiana (sin el signo de la raíz),  multiplicamos el valor de la función 2 por la raíz No .2 es suficiente, de modo que el resultado del cálculo de la fórmula anterior correspondiente a la función 2 se duplique, de modo que la ponderación se pueda lograr fácil y rápidamente. Si se usa la distancia de Manhattan, la característica se multiplica directamente por el peso de 2, que es 2.
multiplicamos el valor de la función 2 por la raíz No .2 es suficiente, de modo que el resultado del cálculo de la fórmula anterior correspondiente a la función 2 se duplique, de modo que la ponderación se pueda lograr fácil y rápidamente. Si se usa la distancia de Manhattan, la característica se multiplica directamente por el peso de 2, que es 2.
Si la función de categoría se pondera después de la incrustación, por ejemplo, la incrustación es de 256 dimensiones, luego de normalizar el resultado de la incrustación de 0 a 1, cada dimensión incrustada se multiplica por la raíz cuadrada de 1/256, de modo que todas las incrustaciones de esta categoría se multiplican por 1/256. La contribución del cálculo de la distancia se reduce a 1, lo que evita que el tamaño de incrustación sea demasiado grande, por lo que los resultados de agrupación de kmeans dependen mucho de la característica de incrustación, que es esencialmente una sola dimensión de la categoría.
5.5 Selección de funciones
En esencia, kmeans solo determina la clase de clúster a la que pertenece en función de la distancia entre las características de la muestra (distribución de la muestra). Las diferentes características afectarán significativamente los resultados de la agrupación. ¡Cuando se utilizan funciones no representativas, los resultados pueden ser muy diferentes de lo esperado! Por ejemplo, si desea agrupar y calificar la calidad de los clientes bancarios: los tiempos de transacción y el monto del depósito son características importantes, mientras que el género y la edad del cliente pueden ser ruidosos. ¡Usar características de género y edad obtendrá clientes con género y edad similares!
Para la selección de características para el agrupamiento no supervisado:
-
Por un lado, puede combinar el significado comercial y seleccionar características que estén cerca del escenario comercial.
-
Por otro lado, los métodos de selección de características comunes (reducción de dimensiones) como la tasa de pérdida, la similitud y el PCA se pueden combinar para eliminar el ruido, reducir el cálculo y evitar la explosión de dimensiones. Además, si la tarea tiene información de etiqueta, también es un método para combinar la importancia de la función de la función con la etiqueta (como la importancia de la función de xgboost, el valor IV de la función).
-
Finalmente, la representación de características de la red neuronal (es decir, la idea de agrupamiento profundo. Se hará una introducción especial más adelante), por ejemplo, word2vec se puede usar para representar el espacio vectorial de palabras de alta dimensión como un espacio de vector de palabra de baja dimensión. vector distribuido dimensional.
artículo recomendado
-
El curso de mandarín "Aprendizaje automático" de Li Hongyi (2022) ya está aquí
-
Alguien hizo una versión china del aprendizaje automático y el aprendizaje profundo del Sr. Wu Enda
-
Soy adicto, y recientemente le di a la compañía una gran pantalla visual (con código fuente)
-
Tan elegantes, los artefactos de análisis de datos automáticos de 4 Python son realmente fragantes
Intercambio de Tecnología
¡Bienvenido a reimprimir, coleccionar, dar me gusta y apoyar!

En la actualidad, se ha abierto un grupo de intercambio técnico, con más de 2000 miembros . La mejor manera de comentar al agregar es: fuente + dirección de interés, que es conveniente para encontrar amigos de ideas afines.
- Método 1. Envíe la siguiente imagen a WeChat, mantenga presionada para identificarla y responda en segundo plano: agregar grupo;
- Método ②, agregar microseñal: dkl88191 , nota: de CSDN
- Método ③, cuenta pública de búsqueda de WeChat: aprendizaje de Python y extracción de datos , respuesta en segundo plano: agregar grupo
