Directorio de artículos
Recientemente, ChatGPT ha sido popular y los estudiantes de PNL definitivamente se sentirán más profundamente. Es bueno que la aplicación de NLP se conozca y se implemente activamente, pero cada escenario de aplicación a nivel de aplicación es una tarea que el modelo SOTA ha superado continuamente en el dominio pasado. Pero desafortunadamente, en los últimos años, los avances en la resolución de una sola tarea a nivel de algoritmo se han ralentizado significativamente, pero el nivel de aplicación se ha acelerado.
pd: En la actualidad, la palabra "Skynet" no se ha mencionado en la información, hhhhhhh, en ese entonces, cuando VR y AR no tenían nada, las menciones de "Skynet" llegaban por todas las montañas y llanuras.
Aquí usamos un modelo de aprendizaje automático SVM relativamente simple y de uso común para ayudar a cronometrar y obtener rendimientos excesivos.

Aplicación de Machine Learning a Modelos Cuantitativos
Escenarios de aplicación de cuantificación de aprendizaje automático
La aplicación de aprendizaje automático y la estrategia cuantitativa resumidas por el blogger tienen los siguientes tres escenarios:
- Construya una estrategia cuantitativa con una tasa ganadora superior a 50. No importa si el modelo es explicable o no, al aumentar el número de transacciones, el resultado integral se desplazará hacia el promedio móvil para obtener el exceso de rendimiento esperado.
- En un marco lógico que puede obtener rendimientos excesivos, use el modelo de aprendizaje automático para optimizar los detalles, de modo que el rendimiento esperado promedio cambie a un rendimiento mayor bajo la bendición del modelo.
- Con base en el modelo de precios, obtenga rendimientos superiores del mercado revisado
Y cada escenario corresponde a diferentes ideas de cuantificación, y también corresponde al sistema de conocimiento de diferentes investigadores:
- El primer tipo es adecuado para los antecedentes de ingeniería con suficiente profesionalismo. La dificultad radica en la premisa de que "la historia no se repetirá". El modelo de demostración puede obtener rendimientos en exceso, y la obtención de rendimientos en exceso también es un evento de alta probabilidad. Principalmente alta- comercio de frecuencia
- El segundo tipo es adecuado para personal financiero con capacidad de programación, la dificultad radica en demostrar la cadena lógica que puede obtener rendimientos excedentes.
- El tercer tipo es adecuado para personal financiero con capacidad y experiencia en programación, la dificultad radica en identificar y eliminar información de ruido en el mercado, o corregir y optimizar el modelo de precios.
Pensando en la Eficacia de los Modelos Cuantitativos
El consenso actual es que la complejidad de las tareas de inversión está mucho más allá del alcance del aprendizaje automático, por lo que generalmente es necesario utilizar modelos de aprendizaje automático para optimizar dentro de un marco lógico enmarcado artificialmente.
Después de estudiar hasta ahora, he leído muchos libros y estrategias cuantitativas. El blogger tiene algunos pensamientos y quiere compartirlos con ustedes:
- De hecho, muchos estudiantes, como los blogueros, han pasado de informática a finanzas, por lo que la "cuantificación" es un buen punto de entrada para nosotros. Cuanto más nos inclinamos por el análisis de datos, más cómodo nos resulta. Pero humanos versus algoritmos:
- Las ventajas del ser humano son: quitarse el ruido, resumir y poder leer cada vez menos libros
- Las ventajas de las máquinas son: estadísticas, razonamiento y la capacidad de leer libros cada vez más gruesos.
El modelo econométrico, que se ha desarrollado durante más de medio siglo, ha demostrado que los "datos de resultados" de finanzas y precios son caóticos y aleatorios en su composición de información. Por lo tanto, es mejor no dejar que las máquinas "reemplacen a Think for yourself". ", los resultados del algoritmo solo pueden dar algo de inspiración a lo sumo, lejos de ayudar a pensar. Al mismo tiempo, no "tenga más funciones, mejor". Las funciones basura son la fuente del ruido, y las máquinas no pueden filtrarlas por sí mismas. Por lo tanto, los "humanos" primero deben entender las finanzas y tener lógica, y luego los "humanos". " construir algoritmos.
- Además de los parámetros de ajuste, generalmente hay dos efectos de mejorar los modelos de aprendizaje automático:
- Secuencias de características construidas artificialmente que pueden resistir el escrutinio lógico
- No elimine previamente las características de acuerdo con las reglas inherentes del análisis de datos.
Experiencia, como el modelo de bosque aleatorio comúnmente utilizado por los bloggers, cuando desea mejorar el efecto solo ajustando características y datos sin ajustar parámetros, en primer lugar, no elimine esta característica en función de una distribución sesgada o algo así. Debido a que cada característica es una perspectiva, algunas perspectivas son más precisas, pero algunas perspectivas son claras y extrañas. Pero cada perspectiva es valiosa. En este momento, necesitamos la participación humana para construir algunas perspectivas adecuadas para que coincidan con estas características y reprocesar las características. Cuanto menos importante sea la característica, mayor será la fuente de inspiración, ¡mayor será el margen de mejora! Sería una gran pérdida eliminarlo de antemano.
- La diferencia de conocimientos profesionales hará que miremos el mundo desde otra perspectiva, como dice el refrán, “todo el que aprende se convierte en personaje”. Los estudiantes que se especialicen en finanzas pondrán la "gestión de riesgos" en primer lugar y, al mismo tiempo, tendrán un reconocimiento casi instintivo de los incidentes de "sesgo de supervivencia", ¡lo cual es muy poderoso! Sin embargo, según mi observación, con el fin de perseguir la "media teórica", muchas estrategias cuantitativas se basarán en la teoría de datos y se adaptarán al modelo, lo que requiere una atención especial.
Este blog solo usa el modelo SVM para los cálculos. Para obtener más modelos de aprendizaje automático, consulte: https://blog.csdn.net/weixin_35757704/article/details/89280669
Aplicación de Modelos de Machine Learning en Timing Cuantitativo
Proceso de Entrenamiento y Predicción
El uso del aprendizaje automático generalmente tiene los siguientes pasos:
- limpieza de datos
- Conjunto de entrenamiento dividido y conjunto de prueba
- Usando el conjunto de entrenamiento, valide de forma cruzada la estabilidad del modelo
- El conjunto de prueba juzga la eficacia del modelo.
- Cálculo del modelo de aplicación y backtesting
Por lo tanto, dividimos el tiempo en las siguientes dos partes:
- Tiempo de datos de entrenamiento y prueba: 2015-01-01 a 2020-01-01
- Cálculo del modelo de aplicación y tiempo de backtest: 2020-01-01 a 2023-01-01
Construcción de funciones de datos de entrenamiento
Aquí construimos una característica más simple para su conveniencia:
- Tasa de rotación promedio en los últimos 5 días
- Tasa de rotación promedio en los últimos 10 días
- Cambio en los últimos 5 días
- Cambio en los últimos 10 días
- Indicador MACD Valor DIF
- Indicador MACD Valor DEA
- valor MACD
- Indicador Aroon (un indicador de impulso) Valor DOWN
- Valor UP del índice de Aroon
Modelo y cálculo de SVM
Entrenamiento y predicción de SVM
Por lo general, después de obtener los datos, el modelo con el ingreso final como objetivo tiene principalmente los siguientes objetivos de capacitación:
- Predecir directamente la tasa de rendimiento para un período de tiempo en el futuro
- Pronostique el rango de ganancias para un período de tiempo en el futuro
Debido al rendimiento limitado del modelo de aprendizaje automático, cuando el objetivo final suele ser la tasa de rendimiento, optará por "predecir el rango de ganancias para un período de tiempo en el futuro".
Por lo tanto, entrenamos y predecimos de acuerdo con las siguientes reglas:
- El 70 % de los datos se utiliza como conjunto de entrenamiento y el 30 % de los datos se utiliza como conjunto de prueba.
- Tome el [aumento y caída en los próximos 5 días] como el objetivo de pronóstico y, al mismo tiempo, divida los datos en contenedores y divídalos en:
- Rango de rendimiento: [menos infinito, -1]
- Intervalo de rendimiento: [-1, 1]
- Rango de rendimiento: [1, infinito positivo]
- En el conjunto de entrenamiento, haz 10 veces de validación cruzada
- El equipo de prueba calcula la matriz de confusión y la visualiza
La "validación cruzada" anterior es para juzgar el problema del sobreajuste y el ajuste insuficiente. Muchos artículos tienden a culpar al "sobreajuste" por los malos resultados, pero obviamente hay un problema. Para sobreajuste y ajuste insuficiente, consulte: https://blog.csdn.net/weixin_35757704/article/details/123931046
Medición del efecto
El proceso de cálculo es el siguiente:
- Recoge todas las acciones que no sean ST desde 2015-01-01 hasta 2020-01-01
- Luego, de acuerdo con la tendencia del precio de las acciones de las acciones individuales, construya las 9 características anteriores
- Según el 70% de los datos como conjunto de entrenamiento, el 30% de los datos como conjunto de prueba
- Haz 10 validaciones cruzadas en el conjunto de entrenamiento
De acuerdo con las reglas anteriores para el entrenamiento y la predicción, se obtienen los siguientes resultados del modelo:
-
Calculado de acuerdo con el proceso de cálculo anterior, la tasa de precisión en el conjunto de prueba es 0.4751
-
La matriz de confusión normalizada es la siguiente:
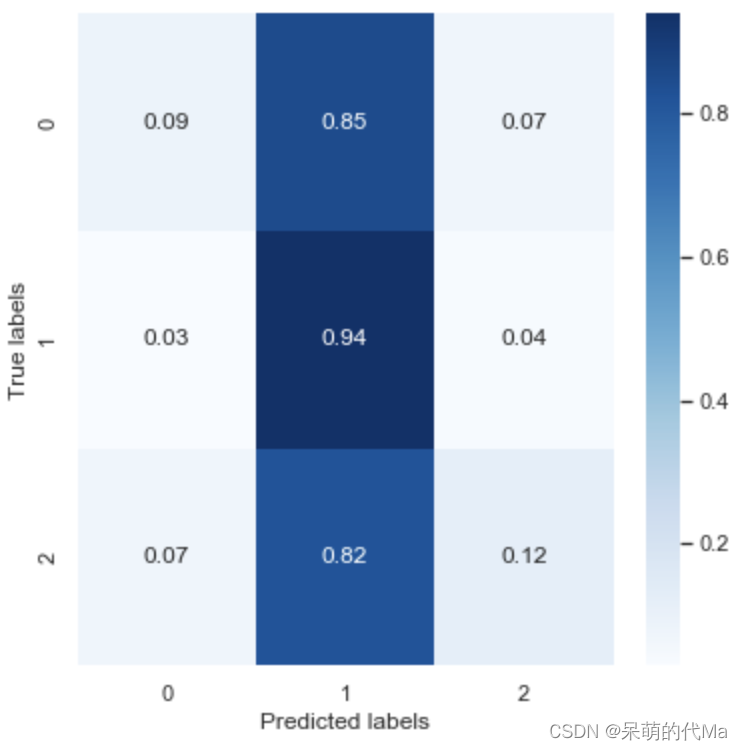
-
Los resultados utilizando la validación cruzada de 10 veces son los siguientes:
| Efecto de precisión | 0.492502 | 0.488092 | 0.478529 | 0.473529 | 0.485882 | 0.477647 | 0.477059 | 0.484118 | 0.480882 | 0.486176 |
|---|
En el uso real, juzgaremos de acuerdo con el efecto lógico del modelo: si el modelo predice un rendimiento positivo, compraremos, si el modelo predice un rendimiento negativo, venderemos;
Análisis de efectividad
- El efecto de la validación cruzada es similar al efecto de predicción del conjunto de prueba, lo que indica que el rendimiento del modelo SVM es relativamente estable
- SVM predice casi ninguna diferencia en categorías como 0, 1 y 2 como categoría 1, y la tasa de precisión para calcular 0 y 2 es solo del 10 %, independientemente de la categoría en sí.
Este efecto es bastante satisfactorio, porque no hay optimización, ajuste o características estructurales subjetivas, el efecto del modelo desnudo es casi el mismo efecto...