Principio del árbol de decisiones
El árbol de decisión es un algoritmo de aprendizaje automático multifuncional, que puede realizar tareas de clasificación y regresión, e incluso tareas de salida múltiple. Son potentes y pueden adaptarse a conjuntos de datos complejos.
- -Ventajas: simple e intuitiva, básicamente sin procesamiento previo, sin necesidad de conferencias, manejo de valores perdidos, alta precisión, insensible a valores atípicos, sin suposiciones de entrada de datos. Puede manejar valores discretos o continuos, y puede manejar problemas de clasificación de salida multidimensional
- Desventajas: alta complejidad computacional, fácil de sobreajustar y poca capacidad de generalización.Es posible que la estructura del árbol cambie drásticamente debido a una pequeña modificación de la muestra, y la complejidad del espacio es alta.
- Rango de datos aplicable: tipo numérico y tipo nominal.
La función de pseudocódigo createBranch () que crea una bifurcación es la siguiente:
Detecta si cada subelemento en el conjunto de datos pertenece a la misma categoría:
If so return 类标签;
Else
寻找划分数据集的最好特征
划分数据集
创建分支节点
for 每个划分的子集
调用函数createBranch并增加返回结果到分支节点中
return 分支节点
El pseudocódigo createBranch anterior es una función recursiva que se llama directamente a sí misma en la penúltima línea.
El principio de funcionamiento es muy simple. El diagrama de flujo que se muestra en la figura es un árbol de decisión. El rectángulo representa el bloque de decisión y la elipse representa el bloque de terminación. Las flechas izquierda y derecha dibujadas desde el módulo de evaluación se denominan ramas, que pueden alcanzar otro módulo de evaluación o terminar el módulo.
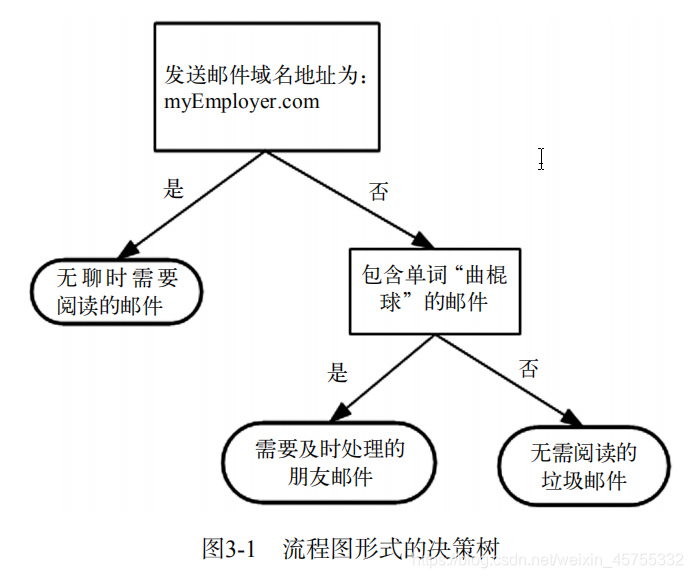
El algoritmo vecino k-más cercano puede completar muchas tareas de clasificación, pero su mayor desventaja es que no puede dar el significado inherente de los datos. La principal ventaja del árbol de decisión es que el formulario de datos es muy fácil de entender. El árbol de decisión requiere muy poco trabajo de preparación de datos, en particular, no hay necesidad de escalamiento o concentración de características.
(1) 收集数据:可以使用任何方法。
(2) 准备数据:树构造算法只适用于标称型数据,因此数值型数据必须离散化。
(3) 分析数据:可以使用任何方法,构造树完成之后,我们应该检查图形是否符合预期。
(4) 训练算法:构造树的数据结构。
(5) 测试算法:使用经验树计算错误率。
(6) 使用算法:此步骤可以适用于任何监督学习算法,而使用决策树可以更好地理解数据
的内在含义。
Hacer predicciones
Tomando la clasificación del iris como ejemplo (hay cuatro características y tres categorías), el límite de decisión del árbol de decisión se muestra en la figura. La línea en negrita indica el límite de decisión del nodo raíz (profundidad 0): longitud del pétalo = 2,45 cm. Debido a que el área de la izquierda es pura (solo iris Setosa), no se puede dividir. Pero el área a la derecha es impura, por lo que el nodo a la derecha de la profundidad 1 se divide nuevamente en el ancho del pétalo = 1.75 cm (mostrado por la línea punteada). Debido a que la profundidad máxima max_depth se establece en 2, el árbol de decisión se detiene aquí. Pero si establece max_depth en 3, entonces dos nodos con profundidad 2 generarán cada uno otro límite de decisión (mostrado por líneas punteadas).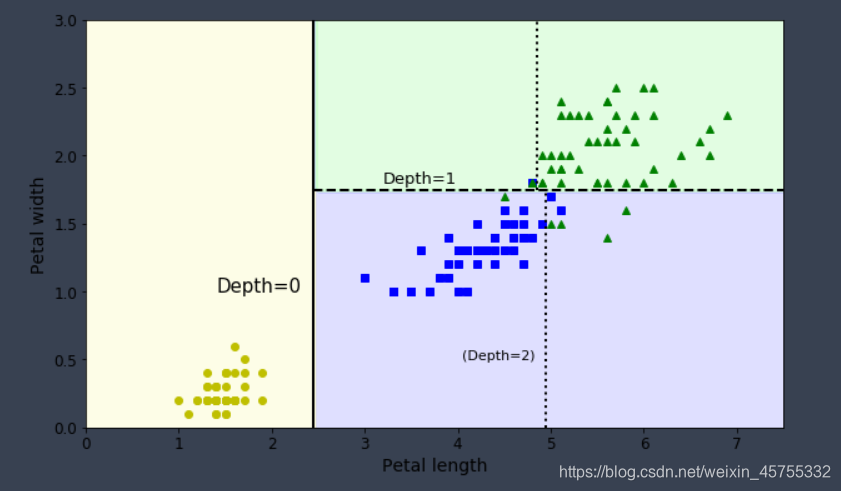
Clasificación del árbol de decisión
Algoritmo 1.CLS
El algoritmo de aprendizaje CLS (Concept Learning System) fue propuesto por Hunt.EB y otros en 1966. Primero propuso el uso de árboles de decisión para el aprendizaje de conceptos. Más tarde, muchos algoritmos de aprendizaje del árbol de decisiones pueden considerarse como la mejora y actualización del algoritmo CLS. La idea principal de CLS es comenzar desde un árbol de decisión vacío y mejorar el árbol de decisión original agregando nuevos nodos de decisión hasta que el árbol pueda clasificar correctamente los ejemplos de capacitación. El proceso de construcción del árbol de decisión es también el proceso de asumir la especialización, por lo que CLS puede considerarse como un algoritmo de aprendizaje con un solo operador. Esta operación se puede expresar como: Especialización de la hipótesis actual al agregar una nueva condición de decisión (nuevo nodo de decisión). El algoritmo CLS llama a este operador de forma recursiva, actuando sobre cada nodo hoja para construir un árbol de decisión.
2. algoritmo ID3
El algoritmo ID3 (dicotomizador iterativo3) fue propuesto por Quinlan en 1986. Es el representante del algoritmo del árbol de decisión, y la mayoría de los algoritmos del árbol de decisión se mejoran en función de él. Utiliza una estrategia de divide y vencerás. Al seleccionar los atributos en todos los niveles del árbol de decisión, la ganancia de información se usa como criterio de selección de atributos, de modo que cuando se prueba en cada nodo no hoja, se puede obtener el método específico para obtener la información de categoría más grande sobre el registro probado. Sí: detecte todos los atributos, seleccione el atributo con la mayor ganancia de información para generar un nodo del árbol de decisión, establezca ramas de diferentes valores de este atributo y luego llame recursivamente a este método en un subconjunto de cada rama para establecer ramas del nodo del árbol de decisión hasta todos los subconjuntos Solo contiene datos de la misma categoría. Finalmente, se obtiene un árbol de decisión, que puede clasificar nuevas muestras.
3. algoritmo C4.5
Quinlan. JR propuso el algoritmo C4.5 en 1993. Se desarrolló a partir del algoritmo ID3 y heredó las ventajas del algoritmo ID3. El algoritmo C4.5 introdujo nuevos métodos y funciones:
- Utilice el concepto de ganancia de información para superar las deficiencias de sesgo a atributos de valores múltiples al seleccionar atributos con ganancia de información;
- Poda durante la construcción del árbol para evitar sobreajustar el árbol;
- Capacidad para discretizar atributos continuos;
- Puede manejar conjuntos de muestras de entrenamiento con valores de atributos faltantes;
- Capacidad para procesar datos incompletos;
- K-fold validación cruzada;
El algoritmo C4.5 reduce la complejidad del cálculo y mejora la eficiencia del cálculo. Su mejora importante para el algoritmo ID3 es utilizar la tasa de ganancia de información para seleccionar atributos. Las teorías y los experimentos muestran que el uso de la tasa de ganancia de información es mejor que el uso de la ganancia de información, principalmente porque supera el atributo del método ID3 de elegir más valores. El algoritmo C4.5 también se ha ocupado de los datos del atributo de valor continuo, compensando el defecto de que el algoritmo ID3 solo puede manejar datos de atributo de valor discreto.
Sin embargo, el algoritmo C4.5 paga un gran precio por procesar el umbral de búsqueda lineal en atributos de prueba continua. En 2002, Salvatore Ruggieri propuso un algoritmo mejorado para el algoritmo C4.5: EC4.5. El algoritmo EC4.5 utiliza la búsqueda binaria en lugar de la búsqueda lineal para superar esta deficiencia. Los experimentos muestran que al generar el mismo árbol de decisión, en comparación con el algoritmo C4.5, el algoritmo EC4.5 puede mejorar la eficiencia en 5 veces, pero la desventaja del algoritmo EC4.5 ocupa más memoria. 5. Algoritmo SLIQ El algoritmo anterior requiere que los conjuntos de muestras de entrenamiento residan en la memoria, por lo que no es adecuado para procesar datos a gran escala. Con este fin, los investigadores de IBM propusieron un algoritmo de clasificación de árbol de decisión más rápido, escalable SLIQ (Supervised Learning In Quest) adecuado para procesar datos a mayor escala en 1996. Utiliza la tabla de atributos, la tabla de clase y el histograma de clase para construir un árbol. La tabla de atributos contiene dos campos: valor de atributo y número de muestra. La tabla de clase también contiene
4. Algoritmo de entrenamiento CART
Scikit-Learn utiliza el algoritmo del árbol de clasificación y regresión (CART) para entrenar árboles de decisión (también conocidos como árboles de "crecimiento"). La idea es muy simple: primero, use una sola característica k y un umbral tk (por ejemplo, longitud de pétalo ≤ 2.45 cm) para dividir el conjunto de entrenamiento en dos subconjuntos. ¿Cómo elegir k y umbral tk? La respuesta es que k y tk, que producen el subconjunto más puro (ponderado por su tamaño), están determinados por la búsqueda de algoritmos (t, tk).

Una vez que el conjunto de entrenamiento se divide con éxito en dos, usará la misma lógica para continuar dividiendo el subconjunto, y luego el subconjunto del subconjunto, e iterar a su vez. Hasta que se alcanza la profundidad máxima (explicada a continuación por el control de hiperparámetro max_depth). Reducir max_depth puede regularizar el modelo, lo que reduce el riesgo de sobreajuste. ), O ya no puede encontrar una división que pueda reducir la impureza, se detendrá.
Complejidad computacional
Hacer predicciones requiere atravesar el árbol de decisión de raíz a hoja. En términos generales, el árbol de decisión está más o menos equilibrado, por lo que atravesar el árbol de decisión requiere unos nodos O (log2 (m)). (Nota: log2 es el logaritmo de la base 2. Es igual a log2 (m) = log (m) / log (2).) Y cada nodo solo necesita verificar un valor propio, por lo que la complejidad de predicción general es solo O ( log2 (m)), independientemente del número de características. Por lo tanto, incluso cuando se trata de grandes conjuntos de datos, las predicciones son rápidas. Sin embargo, en cada nodo durante el entrenamiento, el algoritmo necesita comparar todas las características en todas las muestras (si max_features está configurado, será menor). Esto conduce a una complejidad de entrenamiento de O (n × m log (m)). Para conjuntos de entrenamiento pequeños (en miles de instancias), Scikit_learn puede acelerar el entrenamiento al preprocesar los datos (configuración preestablecida = Verdadero), pero para conjuntos de entrenamiento más grandes, puede ralentizar el entrenamiento.
Hiperparámetro regularizado
Los árboles de decisión rara vez hacen suposiciones sobre los datos de entrenamiento (por ejemplo, el modelo lineal es todo lo contrario, obviamente supone que los datos son lineales). Si no se restringe, la estructura del árbol cambiará con el conjunto de entrenamiento, se ajustará estrechamente y probablemente se sobreajuste. Este tipo de modelo generalmente se llama modelo no paramétrico. Esto no significa que no contenga ningún parámetro (de hecho, generalmente tiene muchos parámetros), pero significa que el número de parámetros no se determina antes del entrenamiento, lo que hace que la estructura del modelo sea libre y esté cerca de los datos. . Los modelos de parámetros correspondientes, como los modelos lineales, tienen algunos parámetros preestablecidos, por lo que sus grados de libertad son limitados, lo que reduce el riesgo de sobreajuste (pero aumenta el riesgo de falta de ajuste). Se puede optimizar de la siguiente manera.
1. Limite las ramas y las hojas.
Para evitar el sobreajuste, es necesario reducir el grado de libertad del árbol de decisión durante el proceso de capacitación, proceso que se denomina regularización. La elección de los hiperparámetros de regularización depende del modelo que utilice, pero en general, al menos puede limitar la profundidad máxima del árbol de decisión. Control de parámetro max_depth híper (el valor predeterminado es Ninguno, lo que significa ilimitado) Reducir max_depth puede regularizar el modelo, lo que reduce el
riesgo de sobreajuste .
Parámetro
- min_samples_split (el número mínimo de muestras que debe tener un nodo antes de dividir)
- min_samples_leaf (el número mínimo de muestras que debe tener un nodo hoja)
- min_weight_fraction_leaf (igual que min_samples_leaf, pero expresado como un porcentaje del número total de instancias ponderadas)
- max_leaf_nodes (número máximo de nodos hoja)
- max_features (divide el número máximo de características evaluadas por cada nodo). Aumentar hiperparámetro
- Min_ * o disminuyendo max_ * regularizará el modelo.
2. Poda y corte de hojas.
También puede entrenar el modelo sin restricciones antes de
podar (eliminar) nodos innecesarios . Si los nodos secundarios de un nodo son todos nodos hoja, el nodo puede considerarse innecesario a menos que la mejora de la pureza que representa tenga una importancia estadística importante. Las pruebas estadísticas estándar, como la prueba χ2, se utilizan para estimar la probabilidad de que "la mejora sea puramente accidental" (conocida como hipótesis falsa). Si esta probabilidad (llamada valor p) es mayor que un umbral dado (generalmente 5%, controlado por hiperparámetros), entonces este nodo puede considerarse innecesario y sus nodos secundarios pueden eliminarse. Hasta que se eliminen todos los nodos innecesarios, el proceso de poda finaliza.
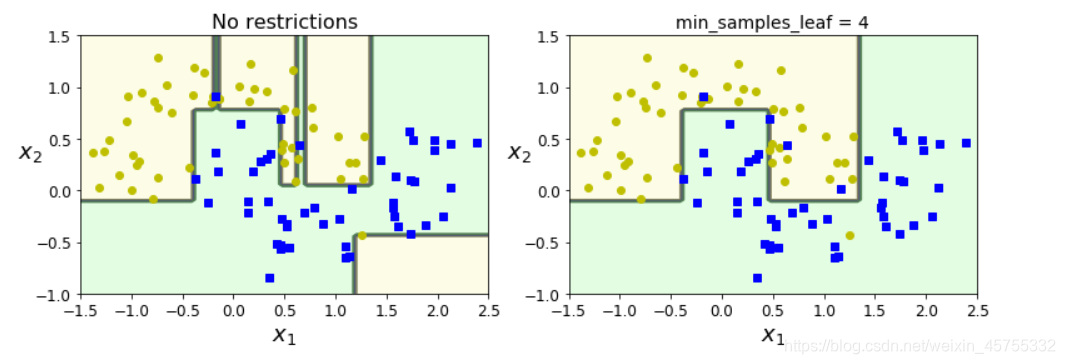
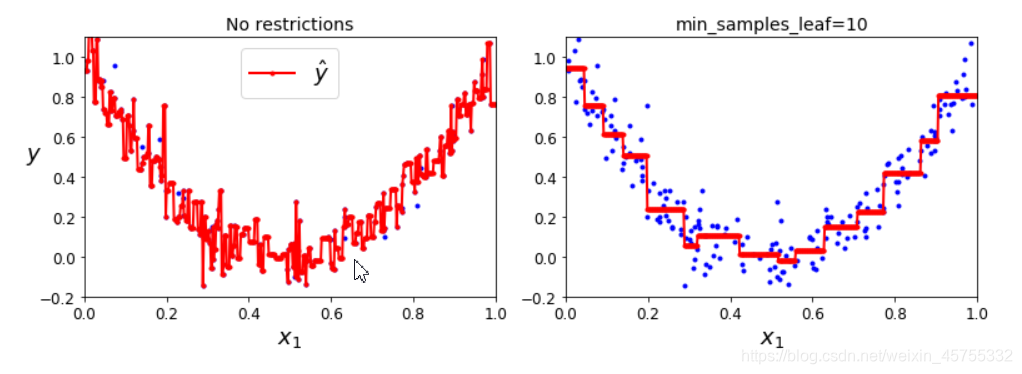
Obviamente, la imagen izquierda es ilimitada, pero sobreajustada; la imagen derecha está limitada por min_samples_leaf, y su efecto de generalización es mejor.
Volver
Los árboles de decisión también se pueden usar para el análisis de regresión.A diferencia de la clasificación, la regresión predice un valor en lugar de una categoría.
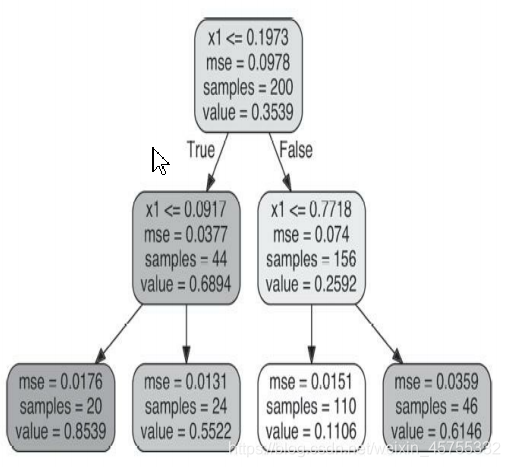
Por ejemplo, si quieres
nueva instancia de la previsión, entonces atravesada desde el nodo raíz, y, finalmente, con el valor pronóstico = 0,1106 de un nodo hoja. Este resultado de predicción es en realidad el valor objetivo promedio de 110 instancias asociadas con este nodo hoja. En estos 110 ejemplos, el error cuadrático medio (MSE) generado por la predicción es igual a 0.0151.
Al igual que las tareas de clasificación, los árboles de decisión también son propensos a sobreajustar cuando se trata de tareas de regresión.
El problema
1. Si el conjunto de entrenamiento tiene 1 millón de instancias, ¿cuál es la profundidad aproximada del árbol de decisión de entrenamiento (sin restricciones)?
Respuesta: La profundidad de un árbol binario equilibrado que contiene m nodos de hoja es igual a log2 (m) (Nota: log2 representa una función de registro con 2 como base, log2 (m) = log (m) / log (2).) Redondeo. En términos generales, el entrenamiento del árbol de decisión binario generalmente está equilibrado hasta el final. Si no se restringe, el promedio de cada nodo hoja es una instancia. Por lo tanto, si el conjunto de entrenamiento contiene un millón de instancias, entonces la profundidad del árbol de decisión es aproximadamente igual a log2 (106) ≈ 20 capas (de hecho, será más porque el árbol de decisión generalmente es imposible de equilibrar perfectamente).
2. Si el árbol de decisión se adapta al conjunto de entrenamiento, ¿es una buena idea reducir max_depth?
Respuesta: puede ser una buena idea reducir max_depth porque limitará el modelo y lo regularizará.
3. Si el árbol de decisión no se ajusta bien al conjunto de entrenamiento, ¿es una buena idea intentar escalar las características de entrada?
Respuesta: Una de las ventajas de los árboles de decisión es que no les importa si los datos de entrenamiento se escalan o concentran, por lo que si el árbol de decisiones no se ajusta bien al conjunto de entrenamiento, escalar las características de entrada es solo una pérdida de tiempo.
4. Si se tarda una hora en entrenar un árbol de decisión en un conjunto de entrenamiento que contiene 1 millón de instancias, ¿cuánto tiempo se tarda en entrenar un árbol de decisión en un conjunto de capacitación que contiene 10 millones de instancias?
Respuesta: La complejidad del entrenamiento del árbol de decisión es O (n × mlog (m)). Por lo tanto, si el tamaño del conjunto de entrenamiento se multiplica por 10, el tiempo de entrenamiento se multiplicará por K = (n × 10m × log (10m)) / (n × m × log (m)) = 10 × log (10m) / log (m ) Si m = 106, entonces K≈11.7, por lo que toma alrededor de 11.7 horas entrenar 10 millones de instancias.
Nota
Como soy un principiante, todavía no sé mucho sobre los parámetros del algoritmo, por lo que tomo prestado mucho de los extractos y los fusiono, así que no tengo una fuente famosa aquí. Espero entenderlo. No escribí mucho código, principalmente porque sentí que la escritura haría que el espacio fuera demasiado grande, y no escribí mucho razonamiento en las fórmulas (la clave es que era un estudiante de primer año, la mayoría de ellos no pueden entenderlo), así que escribí algunos conocimientos básicos de manera concisa.
Además, este artículo se refiere principalmente al libro "Aprendizaje automático práctico: basado en Scikit-Learn y TensorFlow". Si hay una demanda (todavía hay mucha información sobre Python y el aprendizaje automático), puede seguirme y enviarme un correo privado, y se entregarán uno por uno.
Después de todo, novatos, si tienen errores, aún quieren iluminarse y apoyarlos, no les gusta rociar, y esperan encontrar amigos que escriban con ideas afines y aprendan juntos.
