Directorio de artículos
本文是通过自己的理解进行的实验并进行文章撰写,如有问题请批评指正
preparación de datos
Primero, se usa el conjunto de datos de iris que viene con sklearn y los datos se importan usando datasets.load_iris(). El conjunto de datos contiene 150 muestras de datos, que se dividen en 3 categorías, con 50 datos en cada categoría, y cada dato contiene 4 atributos Luego use StandardScaler para normalizar la media y la varianza, y vea el código fuente a través de pycharm para mostrar las características de Standardize eliminando la media y escalando a la varianza de la unidad. El método de cálculo que utiliza esta función es z = (x - u) / s, ues la media de las muestras de entrenamiento o cero si with_mean=False, y ses la desviación estándar de las muestras de entrenamiento o uno si with_std=False. Mediante esta operación, las características de las las muestras de datos se pueden estandarizar, de modo que los datos estén más concentrados y sean más regulares, la estandarización y la normalización pueden hacer que las características de diferentes dimensiones sean más comparables numéricamente, mejorando así la precisión del clasificador, y luego el ajuste genera reglas y aplica las reglas formuladas a la importación anterior en el conjunto de datos del iris.
Creación del clasificador MLP
Luego genere un clasificador MLP, es decir, un clasificador de perceptrón multicapa. Aquí, la función MLPClassifier se usa para generar un clasificador MLP específico. La red neuronal multicapa en el código es una red neuronal con tres capas ocultas. , la la primera capa tiene 30 neuronas, la segunda capa tiene 20 neuronas y la tercera capa tiene 10 neuronas, el número máximo de iteraciones es 800, el optimizador de función de pérdida utilizado es adam y la función de activación es tanh.
mlp = MLPClassifier(max_iter=800, # 最大迭代次数
solver='adam',
activation='tanh',
# 3个隐含层,每层10个神经元
hidden_layer_sizes=(30, 20, 10),
verbose=False)
Dibujar la curva de cambio de tasa de precisión
Luego use la función de curva de aprendizaje learning_curve, el código fuente se describe como Determina el entrenamiento con validación cruzada y los puntajes de prueba para diferentes tamaños de conjuntos de entrenamiento.Es el resultado de determinar el conjunto de entrenamiento con validación cruzada y el conjunto de prueba para diferentes conjuntos de entrenamiento. El estimador de esta función se refiere al método de entrenamiento y predicción. Aquí, se pasa el modelo MLP generado previamente; X representa el conjunto de datos e Y representa la etiqueta del conjunto de datos. Aquí, el conjunto de datos del iris importado previamente es se pasan respectivamente. Datos y etiquetas relevantes; train_sizes es el número relativo o absoluto de muestras de entrenamiento utilizadas para generar la curva de aprendizaje. El valor predeterminado es np.linspace(0.1, 1.0, 5), y el valor pasado también es este, indicando que el tamaño del conjunto de entrenamiento se dividirá en 5 intervalos iguales, y tomará 5 valores linealmente entre 0.1 y 1.0; cv es un método de separación para determinar la validación cruzada. La validación cruzada consiste en dividir el conjunto de datos original en K partes iguales ("doblar") y luego usar la parte 1 como conjunto de prueba y el resto como conjunto de entrenamiento, entrenar el modelo y calcular la precisión del modelo en el conjunto de prueba, cada vez con una parte diferente de él se usa como conjunto de prueba, y el proceso anterior se repite K veces, y finalmente la tasa de precisión promedio se usa como la tasa de precisión del modelo final. 150 muestras se dividen equitativamente en 5 partes (cv = 5), cada una con 30 muestras, según el método de validación cruzada k-fold, hay un máximo de 30 muestras como conjunto de verificación, por lo que el número máximo de muestras que se pueden usado para el conjunto de entrenamiento es 150-30= 120, es decir, el valor máximo de train_sizes es 120.
Luego dibuje las curvas de cambio de precisión de la validación cruzada de conjuntos de entrenamiento de diferentes tamaños, y el gráfico resultante se muestra a continuación
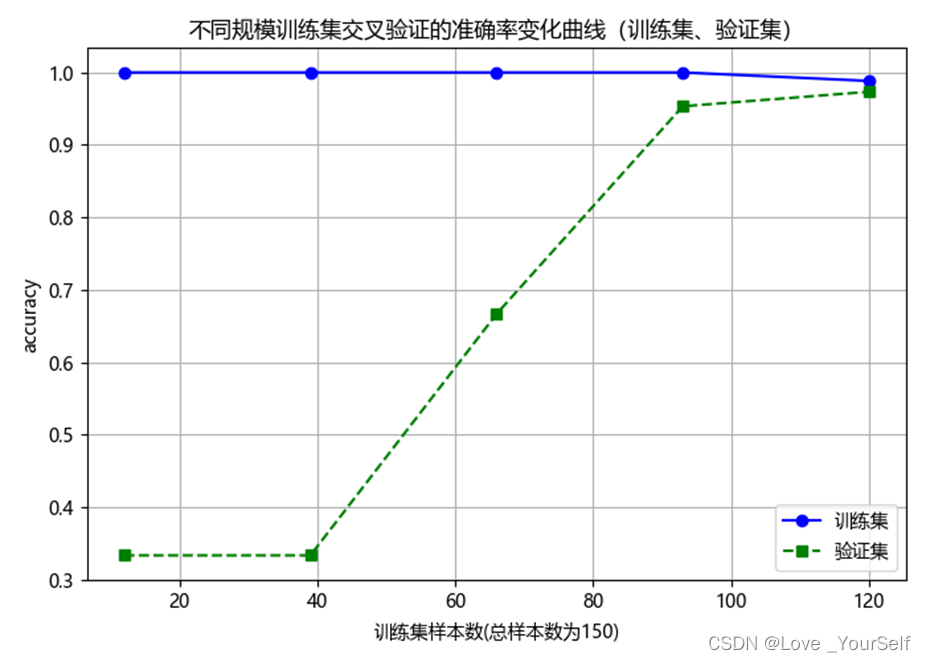
Análisis de resultados
A medida que aumenta el número de muestras de entrenamiento, la curva de precisión del conjunto de verificación muestra una tendencia ascendente: cuanto mayor es el número de muestras en el conjunto de datos de entrenamiento, los datos representados por la muestra están más conectados con todos los datos, es decir, los datos que pueden incluir más situaciones, lo que hace que el modelo sea más generalizable y reduce el impacto de los puntos de ruido en el entrenamiento del modelo, por lo que cuanto mayor sea la precisión, mayor será la curva de tasa de precisión.
A partir de los resultados de ejecución, la curva de tasa de precisión del conjunto de entrenamiento tiene pocos cambios, es decir, el cambio en la cantidad de muestras tiene poco efecto: porque el rol del conjunto de entrenamiento es entrenar parámetros, extrayendo características de los datos. del conjunto de entrenamiento, y afectando al conjunto de entrenamiento Optimización iterativa continua de los datos, para que el rendimiento del modelo obtenido se mejore continuamente, y se pueda predecir para los datos que no aparecen en el conjunto de entrenamiento, por lo que el conjunto de entrenamiento es la fuente de datos para el entrenamiento del modelo y se puede ajustar sobre esta base, por lo que la precisión del conjunto de entrenamiento es alta y no varía mucho con el número de muestras.
Método de validación cruzada: no se usan muchos conjuntos de datos. Cuando se usa el entrenamiento de validación cruzada, todos los datos se usan para el entrenamiento y no quedan datos para probar. La validación cruzada de K-fold se usa para ajustar el modelo para encontrar el mejor rendimiento de generalización del modelo Se utilizan excelentes valores de hiperparámetros para evaluar el rendimiento predictivo del modelo, especialmente el rendimiento del modelo entrenado en nuevos datos, lo que puede reducir el sobreajuste hasta cierto punto.