Libros de referencia: Tutorial básico de aprendizaje automático de Python
1. Datos iniciales
El conjunto de datos Iris es un conjunto de datos clásico en aprendizaje automático y estadística. Está incluido en el módulo de conjuntos de datos de scikit-learn.
Podemos llamar a la función load_iris para cargar los datos:
from sklearn.datasets import load_iris
iris_dataset = load_iris()El objeto iris devuelto por load_iris es un objeto Bunch, muy similar a un diccionario, que contiene claves y valores:
# 查看数据集的keys
print('Keys of iris_dataset: \n{}'.format(iris_dataset.keys()))producción:
Keys of iris_dataset:
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])Como puede ver, el conjunto de datos tiene muchas claves.
El valor correspondiente a la clave DESCR es una breve descripción del conjunto de datos. Veamos la parte anterior:
print(iris_dataset['DESCR'][:193] + "\n...")producción:
.. _iris_dataset:
Iris plants dataset
--------------------
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, pre
...A través de la información de descripción anterior, podemos saber que el conjunto de datos contiene 150 datos y que cada 50 datos pertenecen a una categoría, es decir, hay tres categorías y cada dato tiene cuatro características.
El valor correspondiente a la clave target_names es una matriz de cadenas que contiene las especies de flores que queremos predecir:
print("Target names: {}".format(iris_dataset['target_names']))producción:
Target names: ['setosa' 'versicolor' 'virginica']A partir de esto, podemos saber que el conjunto de datos de iris contiene 3 tipos de iris, a saber, Iris-setosa, Iris-versicolor e Iris-virginica.
El valor correspondiente a la clave feature_names es una lista de cadenas que describen cada característica:
print("Feature names: \n{}".format(iris_dataset['feature_names']))producción:
Feature names:
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']A partir de esto, podemos saber que cada dato contiene 4 características: longitud del sépalo (longitud del sépalo), ancho del sépalo (ancho del sépalo), longitud del pétalo (longitud del pétalo), ancho del pétalo (ancho del pétalo)
Los datos están contenidos en los campos de destino y de datos. data contiene los datos de medición de la longitud del sépalo, el ancho del sépalo, la longitud del pétalo y el ancho del pétalo, en el formato de matriz NumPy:
print("Type of data: {}".format(type(iris_dataset['data'])))producción:
Type of data: <class 'numpy.ndarray'>Cada fila de la matriz de datos corresponde a una flor y las columnas representan cuatro medidas para cada flor:
print("Shape of data: {}".format(iris_dataset['data'].shape))producción:
Shape of data: (150, 4)A partir de esto, podemos saber que hay 150 filas en la matriz de datos, correspondientes a los datos de medición de 150 flores, 150 muestras y 4 columnas, cada columna representa una característica.
Veamos los primeros 5 datos:
print("First five rows of data:\n{}".format(iris_dataset['data'][:5]))producción:
First five rows of data:
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]]La primera línea representa la primera flor con una longitud de sépalo de 5,1 cm, una anchura de sépalo de 3,5 cm, una longitud de pétalo de 1,4 cm y una anchura de pétalo de 0,2 cm.
La matriz objetivo contiene la variedad de cada flor que se ha medido, es una matriz NumPy unidimensional y cada flor corresponde a uno de los datos:
print("Shape of target: {}".format(iris_dataset['target'].shape))producción:
Shape of target: (150,)Podemos saber por la clave target_names que el conjunto de datos de iris tiene 3 variedades, y estas tres variedades se convierten en números en la matriz de destino, que son 0, 1 y 2 respectivamente:
print("Target:\n{}".format(iris_dataset['target']))producción:
Target:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]Desde aquí también podemos ver que los datos del iris no están alterados, es decir, los primeros 50 datos son una categoría (setosa), los 50 datos del medio son una categoría (versicolor) y los últimos 50 datos son una categoría (virginica).
2. Divide los datos
Normalmente, no podemos utilizar los datos a partir de los cuales se construyó el modelo para evaluarlo. Debido a que nuestro modelo siempre recuerda todo el conjunto de entrenamiento, siempre predecirá la etiqueta correcta para cualquier punto de datos en el conjunto de entrenamiento. Esta "memoria" no nos dice nada sobre qué tan bien se generaliza el modelo (en otras palabras, si predice correctamente sobre nuevos datos). Por lo tanto, necesitamos utilizar nuevos datos para evaluar el rendimiento del modelo. La forma habitual es dividir nuestro conjunto de datos en conjunto de entrenamiento y conjunto de prueba.
La función train_test_split en scikit-learn puede mezclar el conjunto de datos y dividirlo:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
iris_dataset['data'], iris_dataset['target'], test_size=0.25, random_state=0)El primer parámetro de la función train_test_split son los datos que se dividirán, el segundo parámetro es la etiqueta de los datos que se dividirán, el parámetro test_size indica el tamaño del conjunto de prueba, el valor predeterminado es 0,25, random_state es una semilla aleatoria, si Se especifica este valor, luego cada división produce el mismo resultado. La función train_test_split barajará los datos de forma predeterminada antes de dividirlos. La función devuelve 4 matrices, que son datos de entrenamiento, datos de prueba, etiquetas de entrenamiento y etiquetas de prueba.
Podemos observar la forma de los conjuntos de entrenamiento y prueba:
print("X_train shape: {}".format(X_train.shape))
print("y_train shape: {}".format(y_train.shape))
print("X_test shape: {}".format(X_test.shape))
print("y_test shape: {}".format(y_test.shape))producción:
X_train shape: (112, 4)
y_train shape: (112,)
X_test shape: (38, 4)
y_test shape: (38,)3. Visualizar datos
El formato DataFrame de pandas se puede utilizar para ver datos en un formato similar a Excel. Podemos convertir los datos del iris en formato numpy a pandas DataFrame:
import pandas as pd
# columns 表示使用鸢尾花的特征名作为每一列的列名
df = pd.DataFrame(iris_dataset.data, columns=iris_dataset.feature_names)
# 添加一列,列名为 label ,数据为标签数据
df['label'] = iris_dataset.target
df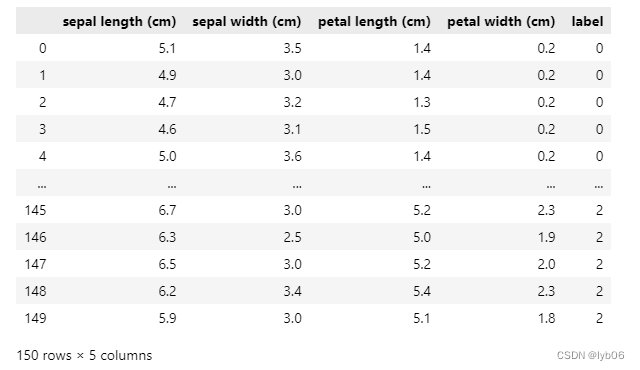
A continuación, visualice los datos mediante gráficos, pero hay un problema. Un dato del iris contiene cuatro características y nos resulta difícil trazar un conjunto de datos con más de tres características en la computadora. Una forma de resolver este problema es dibujar una matriz de diagrama de dispersión (gráfico de pares), de modo que todas las características puedan verse en pares.
pandas tiene una función para dibujar una matriz de diagrama de dispersión llamada scatter_matrix. La diagonal de la matriz es un histograma de cada característica, y las otras posiciones son diagramas de dispersión dibujados por características por pares:
# 将数据data转换为DataFrame格式
# 利用iris_dataset.feature_names中的字符串对数据列进行标记
iris_dataframe = pd.DataFrame(iris_dataset.data, columns=iris_dataset.feature_names)
# 利用DataFrame创建散点图矩阵,按标签target着色
grr = pd.plotting.scatter_matrix(iris_dataframe, c=iris_dataset.target, figsize=(10, 10), marker='o',hist_kwds={'bins': 50}, s=50, alpha=.8)El parámetro c significa colorear los puntos de datos de acuerdo con la etiqueta, es decir, los puntos de datos que pertenecen a diferentes categorías tienen diferentes colores, figsize significa que el tamaño del gráfico es 10 × 10, marcador significa usar un punto grande para representar cada punto de datos, y hist_kwds es un diccionario relacionado con hist Parámetros, s representa el área de cada punto y alfa representa la transparencia del punto.

4. Suplementario (otros conjuntos de datos)
Del contenido anterior, podemos saber que el conjunto de datos del iris es un conjunto de datos de tres categorías, y sklearn también proporciona algunos conjuntos de datos de uso común:
Conjunto de datos sobre cáncer de mama de Wisconsin
El conjunto de datos de cáncer de mama de Wisconsin (cáncer para abreviar), que registra datos de medición clínica de tumores de cáncer de mama.
Cada tumor está etiquetado como "benigno" (que indica un tumor inofensivo) o "maligno" (que indica un tumor canceroso), y la tarea es aprender a predecir si un tumor es maligno o no basándose en mediciones de tejido humano.
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
print("cancer.keys(): \n{}".format(cancer.keys()))producción:
cancer.keys():
dict_keys(['feature_names', 'data', 'DESCR', 'target', 'target_names'])Los conjuntos de datos incluidos en scikit-learn generalmente se guardan como objetos Bunch, que contienen datos reales así como cierta información del conjunto de datos. Todo lo que necesitas saber sobre el objeto Bunch es que es muy similar a un diccionario, con la ventaja adicional de que puedes usar la notación de puntos para acceder a los valores del objeto (por ejemplo, grupo.clave en lugar de grupo['clave'] ).
Información del conjunto de datos:
- Este es un conjunto de datos de clasificación binaria.
- Este conjunto de datos contiene un total de 569 puntos de datos, cada uno con 30 características.
- De los 569 puntos de datos, 212 fueron marcados como malignos y 357 como benignos.
Conjunto de datos sobre precios de la vivienda en Boston
La tarea asociada con este conjunto de datos es predecir el precio medio de la vivienda en el área de Boston en la década de 1970 utilizando información como la tasa de criminalidad, la proximidad al río Charles y la accesibilidad vial.
from sklearn.datasets import load_boston
boston = load_boston()Información del conjunto de datos:
- Este es un conjunto de datos de regresión.
- Este conjunto de datos contiene 506 puntos de datos y 13 características.