Directorio de artículos
Descripción ambiental
Anaconda+python3.6+Jupyter Notebook
Anaconda crea un entorno virtual e instala el paquete correspondiente
Crea un entorno virtual
1. Creación de
la línea de comando Abra la línea de comando e
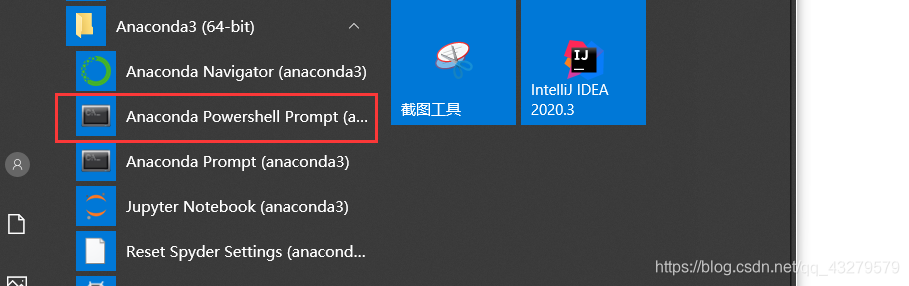
ingrese el siguiente comando
conda create -n sklearn python = 3.6
tf1 es el nombre que elegí para crear el entorno virtual.Puedes elegir la versión de python según tus necesidades.
2. Creación de
interfaz Interfaz abierta y
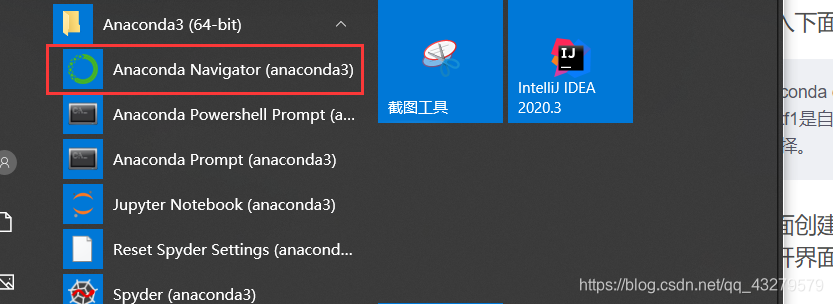
entorno de creación
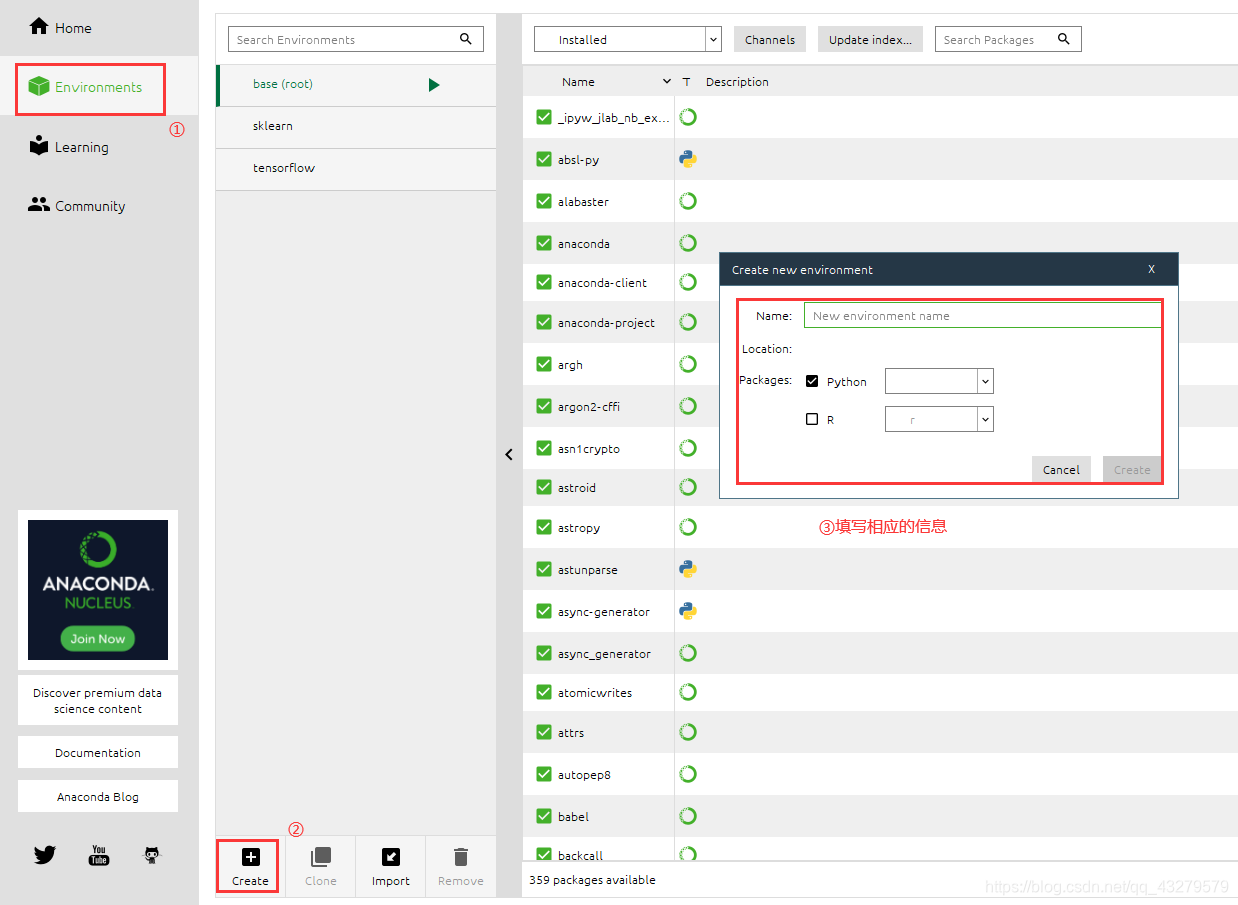
Paquete de instalación
pip install nombre del paquete
La instalación directa de esta manera puede causar fallas en la instalación o una instalación lenta debido a razones de red.
Solución:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple nombre del
paquete El paquete instalado aquí incluye numpy , Pandas, sklearn, matplotlib
SVM (máquina de vectores de soporte)
Introducción a SVM
Svm (support Vector Mac), también conocido como support vector machine, es un modelo de dos clases. Las máquinas de vectores de soporte se pueden dividir en dos categorías: lineales y no lineales. La idea principal es encontrar una línea recta (plano o hiperplano) en el espacio que sea más capaz de dividir todas las muestras de datos y hacer que la distancia entre todos los datos del conjunto de datos y este hiperplano sea la más corta.
El conjunto de datos del iris utiliza la clasificación lineal SVM
LinearSVC (apoyo de la clasificación vectorial lineal) lineal máquina de soporte vectorial, la función del núcleo es lineal.
Parámetros relacionados:
- C: El coeficiente de penalización C de la función objetivo, el valor predeterminado C = 1.0;
- loss: especifique la función de pérdida. squared_hinge (predeterminado), squared_hinge
- penalización: método de penalización, tipo str, l1, l2
- dual: elija un algoritmo para resolver problemas de optimización primitivos o duales. Dual = falso cuando nsamples> nfeatures
- tol: la precisión del estándar svm end, el valor predeterminado es 1e-3
- multi_class: si la categoría de salida y contiene varias categorías, se utiliza para determinar la estrategia de varias categorías, ovr significa uno a varios y "crammer_singer" optimiza un objetivo común para todas las categorías. Si elige "crammer_singer", se ignorarán las pérdidas, las penalizaciones y las optimizaciones.
- max_iter: el número máximo de iteraciones para ejecutar. int, predeterminado 1000
Forma de LinearSVC (C) para lograr la clasificación
Importar los paquetes requeridos
#导入相应的包
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
recuperar datos
# 获取所需数据集
iris=datasets.load_iris()
#每行的数据,一共四列,每一列映射为feature_names中对应的值
X=iris.data
#每行数据对应的分类结果值(也就是每行数据的label值),取值为[0,1,2]
Y=iris.target
#通过Y=iris.target.size,可以得到一共150行数据,三个类别个50条数据,并且数据是按照0,1,2的顺序放的
Procesar los datos
#只取y<2的类别,也就是0 1并且只取前两个特征
X=X[:,:2]
#获取0 1类别的数据
Y1=Y[Y<2]
y1=len(Y1)
#获取0类别的数据
Y2=Y[Y<1]
y2=len(Y2)
X=X[:y1,:2]
Trazado de puntos de datos brutos no estandarizados
#绘制出类别0和类别1
plt.scatter(X[0:y2,0],X[0:y2,1],color='red')
plt.scatter(X[y2+1:y1,0],X[y2+1:y1,1],color='blue')
plt.show()

Procesamiento de normalización de datos
#标准化
standardScaler=StandardScaler()
standardScaler.fit(X)
#计算训练数据的均值和方差
X_standard=standardScaler.transform(X)
#用scaler中的均值和方差来转换X,使X标准化
svc=LinearSVC(C=1e9)
svc.fit(X_standard,Y1)
Dibuje el límite de decisión y
la descripción de las funciones relacionadas:
- meshgrid () devuelve una colección de todos los puntos en un espacio cuadrado definido por dos vectores. x0 es el valor de x, x1 es el valor de y
- ravel () tira del vector en una línea
- c_ [] organizar los vectores juntos
- contourf () contorno
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1, 1),# 600个,影响列数
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1, 1),# 600个,影响行数
)
# x0 和 x1 被拉成一列,然后拼接成360000行2列的矩阵,表示所有点
X_new = np.c_[x0.ravel(), x1.ravel()] # 变成 600 * 600行, 2列的矩阵
y_predict = model.predict(X_new) # 二维点集才可以用来预测
zz = y_predict.reshape(x0.shape) # (600, 600)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
#print(X_new)
plot_decision_boundary(svc, axis=[-3, 3, -3, 3])
plt.scatter(X_standard[0:y2,0], X_standard[0:y2,1],color='red')
plt.scatter(X_standard[y2:y1,0], X_standard[y2:y1,1],color='blue')
plt.show()

Instancia de un svc2 (principalmente LinearSVC(C)una modificación de C)
svc2=LinearSVC(C=0.01)
svc2.fit(X_standard,Y1)
print(svc2.coef_)
print(svc2.intercept_)
plot_decision_boundary(svc2, axis=[-3, 3, -3, 3])
plt.scatter(X_standard[0:y2,0], X_standard[0:y2,1],color='red')
plt.scatter(X_standard[y2:y1,0], X_standard[y2:y1,1],color='blue')
plt.show()

La diferencia en el límite de decisión puede verse claramente a través de los dos gráficos dibujados: cuanto menor es la superficie CC, mayor es el espacio de tolerancia a fallas.
Agregue límites superiores e inferiores según el contenido clasificado
def plot_svc_decision_boundary(model, axis):
x0, x1 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1, 1),# 600个,影响列数
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1, 1),# 600个,影响行数
)
# x0 和 x1 被拉成一列,然后拼接成360000行2列的矩阵,表示所有点
X_new = np.c_[x0.ravel(), x1.ravel()] # 变成 600 * 600行, 2列的矩阵
y_predict = model.predict(X_new) # 二维点集才可以用来预测
zz = y_predict.reshape(x0.shape) # (600, 600)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
w = model.coef_[0]
b = model.intercept_[0]
index_x = np.linspace(axis[0], axis[1], 100)
# f(x,y) = w[0]x1 + w[1]x2 + b
# 1 = w[0]x1 + w[1]x2 + b 上边界
# -1 = w[0]x1 + w[1]x2 + b 下边界
y_up = (1-w[0]*index_x - b) / w[1]
y_down = (-1-w[0]*index_x - b) / w[1]
x_index_up = index_x[(y_up<=axis[3]) & (y_up>=axis[2])]
x_index_down = index_x[(y_down<=axis[3]) & (y_down>=axis[2])]
y_up = y_up[(y_up<=axis[3]) & (y_up>=axis[2])]
y_down = y_down[(y_down<=axis[3]) & (y_down>=axis[2])]
plt.plot(x_index_up, y_up, color="black")
plt.plot(x_index_down, y_down, color="black")
plot_svc_decision_boundary(svc, axis=[-3, 3, -3, 3])
plt.scatter(X_standard[0:y2,0], X_standard[0:y2,1],color='red')
plt.scatter(X_standard[y2:y1,0], X_standard[y2:y1,1],color='blue')
plt.show()

Modificar el valor de C
plot_svc_decision_boundary(svc2, axis=[-3, 3, -3, 3])
plt.scatter(X_standard[0:y2,0], X_standard[0:y2,1],color='red')
plt.scatter(X_standard[y2:y1,0], X_standard[y2:y1,1],color='blue')
plt.show()

Conclusión: cuanto
mayor es la constante C, menor es el espacio tolerante a fallas y más cercanos los límites superior e inferior; cuanto menor es la constante C, mayor es el espacio tolerante a fallas y más lejos los límites superior e inferior.