Fuente | Identificación del corazón de la máquina | casihumano2014
Transformer es una máquina de vectores de soporte (SVM), una nueva teoría que ha provocado debate en la comunidad académica.
El fin de semana pasado, un artículo de la Universidad de Pensilvania y la Universidad de California en Riverside intentó estudiar los principios de la estructura Transformer subyacente al modelo grande, su geometría optimizada en la capa de atención y el SVM rígido que separa los tokens de entrada óptimos de tokens no óptimos Se establece una equivalencia formal entre los problemas.
El autor declaró en hackernews que esta teoría resuelve el problema de que SVM separe los tokens "buenos" de los "malos" en cada secuencia de entrada. Como selector de tokens con excelente rendimiento, este SVM es esencialmente diferente del SVM tradicional que asigna etiquetas 0-1 a las entradas.
Esta teoría también explica cómo la atención induce escasez a través de softmax: los tokens "malos" que caen en el lado equivocado del límite de decisión SVM son suprimidos por la función softmax, mientras que los tokens "buenos" son aquellos que terminan con una probabilidad softmax distinta de cero. También vale la pena mencionar que este SVM se deriva de las propiedades exponenciales de softmax.
Después de que el artículo se subió a arXiv, la gente expresó sus opiniones una tras otra: algunas personas dijeron: La dirección de la investigación de la IA está realmente en espiral, ¿volverá a retroceder?
Después de completar el círculo, las máquinas de vectores de soporte aún no están desactualizadas.
Desde la publicación del artículo clásico "La atención es todo lo que necesitas", la arquitectura Transformer ha aportado un progreso revolucionario al campo del procesamiento del lenguaje natural (PLN). La capa de atención en Transformer acepta una serie de tokens de entrada X y calcula
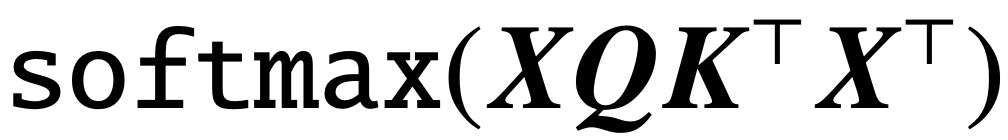
Evalúe la correlación entre tokens, donde (K, Q) son parámetros de consulta clave entrenables y, en última instancia, capturan de manera efectiva las dependencias remotas.
Ahora, un nuevo artículo titulado "Transformers as Support Vector Machines" establece una equivalencia formal entre la geometría de optimización de la autoatención y el problema SVM de margen duro, utilizando la restricción lineal del producto externo de pares de tokens para optimizar. Los tokens de entrada están separados de los no -fichas óptimas.

Enlace del artículo: https://arxiv.org/pdf/2308.16898.pdf
Esta equivalencia formal se basa en el artículo "Selección de tokens de margen máximo en el mecanismo de atención" de Davoud Ataee Tarzanagh et al., que puede describir el sesgo implícito de un transformador de 1 capa optimizado por descenso de gradiente:
(1) Optimice la capa de atención parametrizada por (K, Q), mediante regularización evanescente, para converger a una solución SVM que minimice los parámetros combinados.
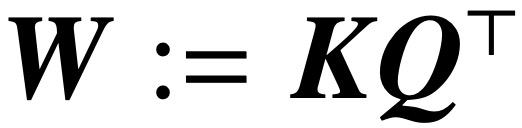
La norma nuclear de . Por el contrario, la parametrización directamente a través de W minimiza el objetivo SVM de la norma Frobenius. El artículo describe esta convergencia y enfatiza que puede ocurrir en la dirección de un óptimo local en lugar de un óptimo global.
(2) El artículo también demuestra la convergencia en la dirección local/global del descenso de gradiente en condiciones geométricas apropiadas para la parametrización de W. Es importante destacar que la sobreparametrización cataliza la convergencia global al garantizar la viabilidad del problema SVM y garantizar un entorno de optimización benigno sin puntos estacionarios.
(3) Aunque la teoría de este estudio se aplica principalmente a cabezales de predicción lineal, el equipo de investigación propone un equivalente SVM más general que puede predecir la polarización implícita de un transformador de 1 capa con un cabezal no lineal/MLP.
En general, los resultados de este estudio son aplicables a conjuntos de datos generales y pueden extenderse a capas de atención cruzada, y la validez práctica de las conclusiones del estudio se ha verificado mediante experimentos numéricos exhaustivos. Este estudio establece una nueva perspectiva de investigación, viendo los transformadores multicapa como jerarquías SVM que separan y seleccionan los mejores tokens.
Específicamente, dada una secuencia de entrada de longitud T y dimensión de incrustación d
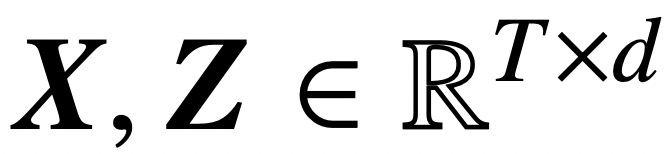
, este estudio analiza los modelos centrales de atención cruzada y autoatención:

Entre ellos, K, Q y V son matrices de clave, consulta y valor entrenables, respectivamente.
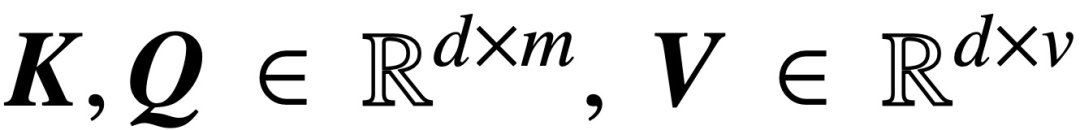
;S (・) representa la no linealidad de softmax, que se aplica fila por fila

. Este estudio supone que el primer token de Z (indicado por z) se utiliza para la predicción. Específicamente, dado un conjunto de datos de entrenamiento
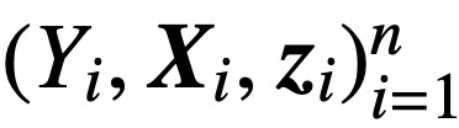
,
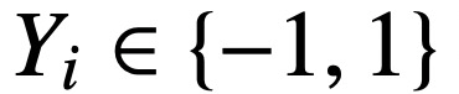
,
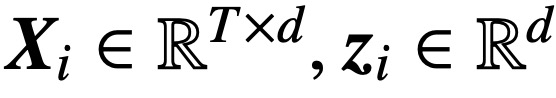
, este estudio utiliza una función de pérdida decreciente

Minimizar:
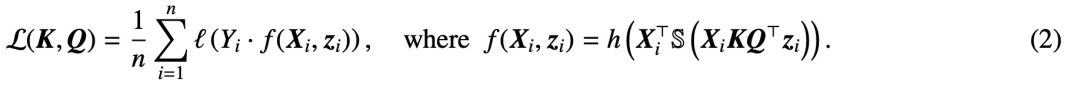
Aquí, h (・):
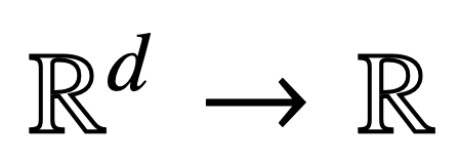
es el encabezado de predicción que contiene el peso del valor V. En esta formulación, el modelo f (・) representa con precisión un transformador de una sola capa donde la capa de atención es seguida por un MLP. El autor establece
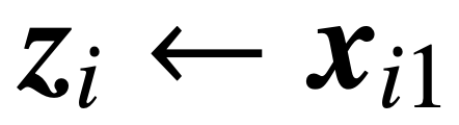
Para restaurar la autoatención en (2), donde x_i representa el primer token de la secuencia X_i. Debido a la naturaleza no lineal de la operación softmax, plantea grandes desafíos para la optimización. Incluso si el cabezal de predicción es fijo y lineal, el problema no es convexo ni lineal. En este estudio, los autores se centran en optimizar los pesos de atención (K, Q o W) y superar estos desafíos para establecer la equivalencia básica de SVM.
La estructura del artículo es la siguiente: el Capítulo 2 presenta el conocimiento preliminar de la autoatención y la optimización; el Capítulo 3 analiza la geometría de optimización de la autoatención, mostrando que el parámetro de atención RP converge a la solución marginal máxima; el Capítulo 4 y el Capítulo 5 presenta Se realiza un análisis de descenso de gradiente global y local, que muestra que la variable de consulta clave W converge a la solución de (Att-SVM); el Capítulo 6 proporciona resultados sobre la equivalencia de cabezas de predicción no lineales y SVM generalizadas; el Capítulo 7 combina la teoría Extensiones a la predicción secuencial y causal; el Capítulo 8 analiza la literatura relacionada. Finalmente, el Capítulo 9 concluye y propone preguntas abiertas y futuras direcciones de investigación.
Los principales contenidos del documento son los siguientes:
Sesgo implícito en las capas de atención (Capítulo 2-3)
La optimización de los parámetros de atención (K, Q) cuando la regularización desaparece convergerá en la dirección a

La solución marginal máxima de , cuyo objetivo de norma nuclear es el parámetro de combinación
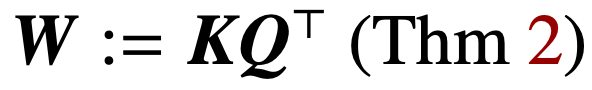
. En el caso de parametrizar directamente la atención cruzada con el parámetro combinado W, la ruta de regularización (RP) converge direccionalmente a la solución (Att-SVM) dirigida a la norma Frobenius.
Este es el primer resultado que distingue formalmente entre la dinámica de optimización paramétrica W y (K, Q), revelando sesgos de bajo orden en esta última. La teoría de este estudio describe claramente la optimización de los tokens seleccionados y, naturalmente, se extiende a configuraciones de clasificación causal o de secuencia a secuencia.
Convergencia del descenso de gradiente (Capítulo 4-5)
Con una inicialización adecuada y una cabeza lineal h (·), la iteración de descenso de gradiente (GD) de la variable de consulta clave combinada W converge en la dirección de la solución óptima local de (Att-SVM) (Sección 5). Para lograr la optimización local, el token seleccionado debe tener una puntuación más alta que los tokens adyacentes.
La dirección óptima local no es necesariamente única y puede determinarse en función de las características geométricas del problema [TLZO23]. Como contribución importante, los autores identifican las condiciones geométricas que garantizan la convergencia hacia el óptimo global (Capítulo 4). Estas condiciones incluyen:
-
Existe una clara diferencia en las puntuaciones entre las mejores fichas;
-
La dirección del gradiente inicial es consistente con el mejor token.
Además, el artículo también demuestra la viabilidad de la parametrización excesiva (es decir, la dimensión d es grande y las mismas condiciones) al garantizar (1) (Att-SVM) y (2) un panorama de optimización benigno (es decir, hay no hay puntos estacionarios y una dirección óptima local falsa) para catalizar la convergencia global (ver Sección 5.2).
Las figuras 1 y 2 ilustran esto.


Generalidad de la equivalencia SVM (Capítulo 6)
Al optimizar con h lineal (・), la capa de atención está inherentemente sesgada hacia la selección de un token de cada secuencia (también conocido como atención dura). Esto se refleja en (Att-SVM), donde el token de salida es una combinación convexa de los tokens de entrada. En contraste, los autores muestran que la cabeza no lineal debe estar compuesta por múltiples tokens, resaltando así su importancia en la dinámica del transformador (Sección 6.1). Utilizando los conocimientos adquiridos a partir de la teoría, los autores proponen un enfoque equivalente a SVM más general.
En particular, demuestran que nuestro método puede predecir con precisión el sesgo implícito de la atención entrenada mediante el descenso de gradiente en casos generales no cubiertos por la teoría (por ejemplo, h (・) es un MLP). Específicamente, nuestra fórmula general desacopla el peso de atención en dos partes: una parte direccional controlada por SVM, que selecciona marcadores aplicando una máscara 0-1; y una parte finita, que ajusta la probabilidad softmax y determina la composición precisa del token seleccionado.
Una característica importante de estos hallazgos es que se aplican a conjuntos de datos arbitrarios (siempre que SVM sea factible) y pueden verificarse numéricamente. Los autores verificaron ampliamente la equivalencia marginal máxima y el sesgo implícito del transformador a través de experimentos. El autor cree que estos hallazgos ayudan a comprender el transformador como un mecanismo jerárquico de selección de tokens de margen máximo y pueden sentar las bases para futuras investigaciones sobre su dinámica de optimización y generalización.
Contenido de referencia:
https://news.ycombinator.com/item?id=37367951
https://twitter.com/vboykis/status/1698055632543207862