SVM Introducción
SVM (máquinas de vectores soporte, SVM) es un modelo binario que modelo básico se define en el máximo espacio de características espaciadas clasificadores lineales, perceptron distinguirlo del intervalo máximo; que comprende además el truco SVM kernel , por lo que es esencialmente un clasificador lineal. estrategia de aprendizaje de SVM es maximizar el intervalo, puede ser formalizada como la resolución de problemas de programación cuadrática convexa, también es equivalente a una regularización problema de minimización de la función de pérdida de bisagra. El algoritmo de aprendizaje SVM es un algoritmo de optimización para resolver programación cuadrática convexa.
principio algoritmo SVM
La idea básica de la SVM es resolver capaz de dividir correctamente el conjunto de datos de entrenamiento y máxima geométrica intervalo que separa hiperplano. Como se muestra a continuación, es el hiperplano de separación para los conjuntos de datos linealmente separables, de modo que hay un número infinito de hiperplanos (es decir perceptron), pero el máximo geométrico intervalo que separa hiperplano es único.
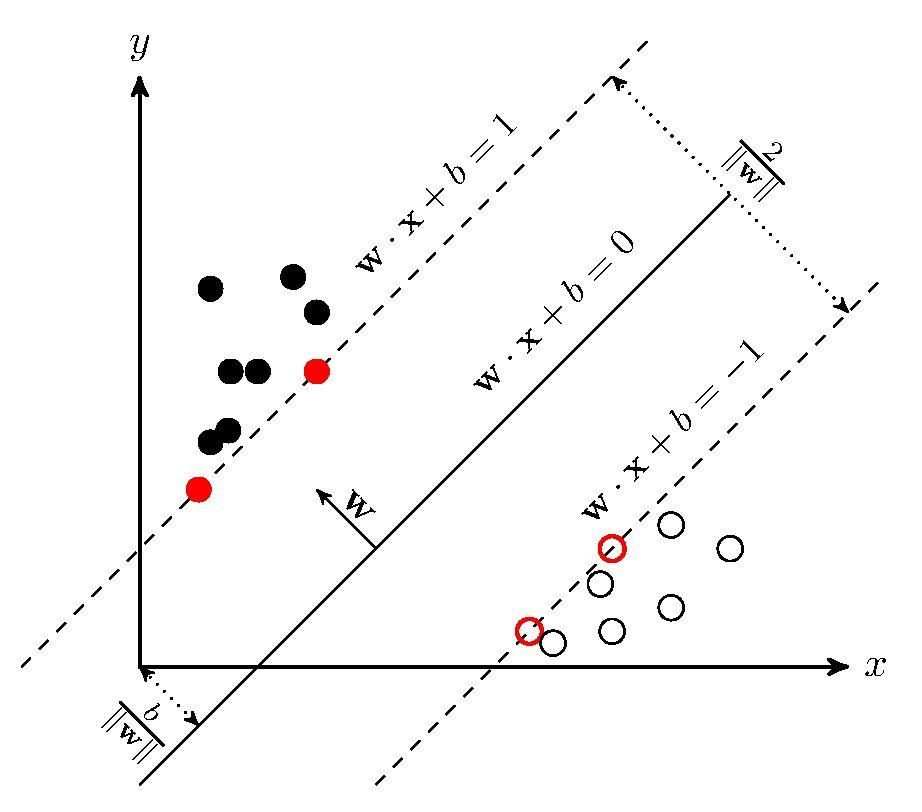
Antes de derivación, con algunas definiciones. Suponiendo que un conjunto de datos de entrenamiento conjunto dado en un espacio de características
En el que, ,
,
para la primera
característica vector
una etiqueta de clase, cuando es casos positivos es igual a 1; -1 cuando ejemplo negativo. Supóngase además que el conjunto de datos de entrenamiento es linealmente separables.
Geometría de los intervalos: para un conjunto dado de datos y el hiperplano
, un hiperplano define los puntos de muestra en
el intervalo geométrica es
mínimo Hyperplane espaciado geométrico de todos los puntos de muestra de
De hecho, esta es la distancia desde el hiperplano a nuestro llamado vector de apoyo.
Sobre la base de la definición anterior, resolver el mayor problema dividiendo modelo SVM hiperplano se puede expresar como el siguiente problema de optimización con restricciones
Las limitaciones de ambos lados, mientras que divide , para dar
Debido a que todos los escalares, por lo que en la expresión fin de la brevedad, por lo
obtener
Y debido a la maximización es equivalente a la maximización
, es equivalente a minimizar
(
hacia atrás después de forma concisa derivación, no afecta el resultado), por lo que el modelo SVM para resolver el mayor problema ha hiperplano de división se puede expresar como las siguientes limitaciones más optimización
Se trata de un problema de programación cuadrática convexa contiene restricciones de desigualdad, que podemos hacerlo (problema doble) el problema dual de su uso multiplicadores de Lagrange.
En primer lugar, vamos a tener las limitaciones de la función objetivo original convertidos a la nueva estructura sin restricciones función objetivo de Lagrange
¿Qué es el multiplicador de Lagrange, y
. Ahora hacemos
Cuando el punto de muestra no satisface las condiciones de restricción, es decir, fuera del área solución factible:
En este caso, se establece en el infinito,
que es infinita.
Cuando este punto es completo se cumplen las restricciones, es decir, en la región factible:
En este caso, la propia función original. Por lo tanto, los dos casos se pueden combinar para conseguir nuestra nueva función objetivo
Así que el problema es equivalente a la restricción original
Mira nuestra nueva función objetivo, para buscar el valor máximo, y luego buscar un mínimo. En este caso, lo primero que tiene que hacer frente a la necesidad de resolver los parámetros y
ecuaciones, que
es restricciones de desigualdad, este proceso de solución no es bueno hacerlo. Por lo tanto, tenemos que utilizar la dualidad de Lagrange, intercambiarán acerca de la posición mínima y máxima, por lo tanto se convierte en:
Tener una necesidad de cumplir con dos condiciones:
① problema de optimización es un problema de optimización convexa
② satisfacer las condiciones KKT
En primer lugar, el problema de optimización es un problema de optimización convexa es claramente, por lo tanto satisface una condición, y para cumplir las dos condiciones, es decir, los requisitos
Con el fin de obtener una forma específica para resolver el problema dual, por lo que el
y
el deflector es 0, disponible
Los anteriores dos ecuaciones en la función de Lagrange función objetivo, la eliminación y
para dar
que
Buscando a
grande, es decir, el problema dual
El objetivo de la fórmula un signo menos, se convertirá en la solución de un ACERCAMIENTO muy pequeña
Nuestro problema de optimización se convierte ahora en el formulario de arriba. Para este problema, tenemos un algoritmo de optimización más eficiente, que la secuencia mínima de optimización (SMO) algoritmo. Aquí desplegado temporalmente más detalles sobre el uso de SMO algoritmo para resolver problemas de optimización, junto con la derivación se detalla próximo artículo.
Podemos obtener a través de este algoritmo de optimización , y luego sobre la base de
que podemos resolver para
y
así lograr nuestro propósito original: "avión decisión" para encontrar el hiperplano que
Derivación supone que satisfacer lo anterior se establecen en las condiciones KKT, las condiciones KKT son como sigue
Además, de acuerdo a la derivación anterior, se establecen las dos fórmulas siguientes
Se puede ver en , por lo menos hay una
(reducción al absurdo para demostrar, si todos los ceros, la
contradicción), que
tiene
Para que pueda obtener
Para cualquier muestra de entrenamiento , siempre hay
o
. Si
, a continuación, la muestra no aparece en la fórmula final para resolver los parámetros del modelo. Si
, sin duda tiene
, que corresponde al punto máximo de la muestra se encuentra en los límites de intervalo, que es un vector de apoyo. Esto demuestra una propiedad importante de SVM: Después del entrenamiento, la mayoría de las muestras de entrenamiento no es necesario para retener el modelo final sólo admite relacionada con vectores.
Aquí los datos de entrenamiento se basan en la suposición de linealmente separables, pero los datos son linealmente separables ausencia casi completa de caso real, con el fin de resolver este problema, el concepto de "espaciador suave", es decir, permitir cierto punto no satisface la restricción
El uso de la pérdida de la bisagra, el problema de optimización original es volver a escribir como
En el que las "variables de holgura",
es decir, una función de pérdida de bisagra. Cada muestra tiene una variable de holgura correspondiente caracterizar el grado de la muestra no satisface la restricción.
Se llama el parámetro de penalización,
cuanto mayor sea el valor, mayor será el castigo para la clasificación. En consonancia con la idea de resolver separabilidad lineal, también aquí para obtener Lagrange con multiplicadores de Lagrange, y luego buscar su doble problema.
Sobre la base de la discusión anterior, podemos obtener un algoritmo de aprendizaje de máquina de soporte vectorial lineal es el siguiente:
Entrada: Conjunto de Entrenamiento de datos en la que ,;
Salida: separar función de decisión hiperplano y clasificación
(1) Seleccionar el parámetro pena , la construcción y la resolución de problemas de programación cuadrática convexas
La solución óptima
(2) Cálculo
Al seleccionar uno de los componentes
satisface la condición
se calcula
(3) separación de hiperplano requiere
Clasificación función de decisión:
principio no lineal SVM algoritmo
Por espacio de entrada problemas de clasificación no lineal, puede ser transformación no lineal en una dimensión lineal de un espacio de características de clasificación, aprendizaje lineal máquina de vectores de soporte en el espacio de características de alta dimensional. Debido a la doble problema de apoyo lineal de aprendizaje de máquinas de vectores, la función de la función y la decisión de clasificación objetivo sólo consiste en el producto interno entre los casos y ejemplos, no es necesario especificar explícitamente la transformación no lineal, pero con el reemplazo dentro de la función del núcleo entre las producto. Función Kernel, el producto interno entre dos instancias después de pasar a través de una conversión no lineal. Específicamente, una función, o un núcleo definida positiva, significa que hay un mapeo del espacio de entrada a la función de espacio
, un espacio de entrada arbitrario
, hay
problema doble en el aprendizaje lineal máquina de soporte vectorial, con una función de núcleo dentro de un producto alternativo, se resuelven es la máquina de vectores de soporte no lineal
Sobre la base de la discusión anterior, podemos obtener soporte vectorial algoritmo de aprendizaje automático no lineal es el siguiente:
Entrada: Conjunto de Entrenamiento de datos en la que ,;
Salida: separar función de decisión hiperplano y clasificación
(1) la selección de una función adecuada kernel y parámetro de penalización
, la configuración y de programación cuadrática Convex
La solución óptima
(2) Cálculo
Al seleccionar uno de los componentes
satisface la condición
se calcula
función de decisión (3) Clasificación:
Introducir una función básica común - Gaussian kernel
Correspondiente a la función de base radial es un clasificador SVM Gauss, en este caso, la función de decisión de clasificación
referencia
[1] "métodos de aprendizaje estadístico" Lee Hang
[2] "aprendizaje automático" Zhou Zhihua
[3] un pitón 3 "máquina de aprendizaje reales" notas de estudio (VIII): Shredded lineal de apoyo principales de máquinas de vectores artículos de SVM Jack-Cui
[5] Apoyo Vector Machine Introducción populares (SVM apreciará que la de tres estados)