Parte 1: Principio de SVM y explicación de ejemplo de código python multicategoría (datos de flor de iris)
Principio de SVM
Support Vector Machine (Support Vector Machine, SVM), que se utiliza principalmente para la clasificación binaria, la clasificación múltiple y el análisis de regresión en muestras pequeñas, es un algoritmo de aprendizaje supervisado. La idea básica es encontrar un hiperplano para segmentar la muestra y separar los ejemplos positivos y negativos en la muestra con el hiperplano, y el principio es maximizar el intervalo entre los ejemplos positivos y negativos.
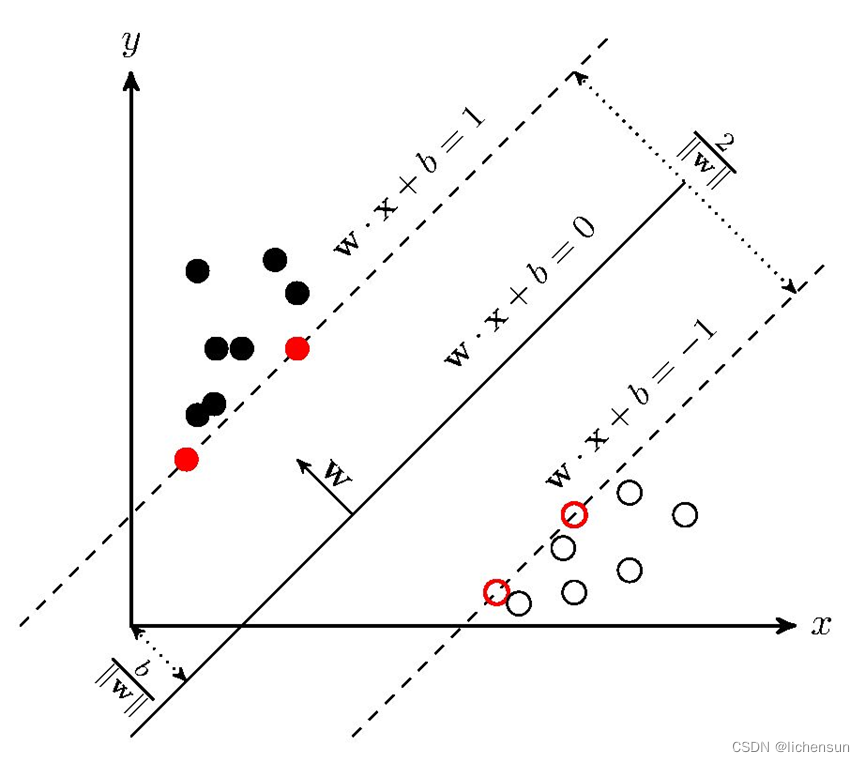
La idea básica del aprendizaje de SVM es resolver el hiperplano de separación que puede dividir correctamente el conjunto de datos de entrenamiento y tiene el intervalo geométrico más grande. Como se muestra en la siguiente figura, wx+b=0 es el hiperplano de separación Para conjuntos de datos separables linealmente, hay infinitos hiperplanos (es decir, perceptrones), pero el hiperplano de separación con el intervalo geométrico más grande es el único.
SVM implementa código de clasificación
1. Introducción al conjunto de datos - Conjunto de datos Iris
Método de descarga: descargue a través del repositorio de aprendizaje automático de UCI o use el código directamente
desde sklearn.datasets importar load_iris
Visualización e introducción de datos (iris.data)
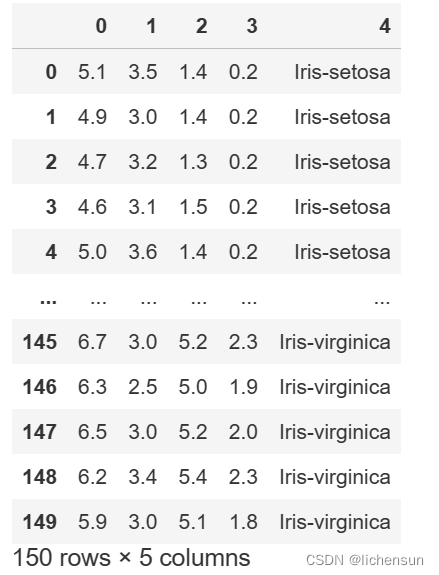
Hay 5 atributos en Iris.data, incluidos 4 atributos de predicción (longitud del sépalo, ancho del sépalo, longitud del pétalo, ancho del pétalo) y 1 atributo de categoría (Iris-setosa, Iris-versicolor, Iris-virginica tres categorías). Primero, debe convertir la información de la categoría en la quinta columna en números y luego elegir ingresar datos y etiquetas.
2. Código python multicategoría (dos categorías se pueden considerar como multicategoría con solo dos categorías)
from sklearn import svm #引入svm包
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
from sklearn.model_selection import train_test_split
#定义字典,将字符与数字对应起来
def Iris_label(s):
it={b'Iris-setosa':0, b'Iris-versicolor':1, b'Iris-virginica':2}
return it[s]
#读取数据,利用np.loadtxt()读取text中的数据
path='iris.data' #将下载的原始数据放到项目文件夹,即可不用写路径
data= np.loadtxt(path, dtype=float, delimiter=',', converters={4:Iris_label}) #分隔符为‘,'
#确定输入和输出
x,y=np.split(data,(4,),axis=1) #将data按前4列返回给x作为输入,最后1列给y作为标签值
x=x[:,0:2] #取x的前2列作为svm的输入,为了便于可视化展示
#划分数据集和标签:利用sklearn中的train_test_split对原始数据集进行划分,本实验中训练集和测试集的比例为7:3。
train_data,test_data,train_label,test_label=train_test_split(x,y,random_state=1,train_size=0.7,test_size=0.3)
#创建svm分类器并进行训练:首先,利用sklearn中的SVC()创建分类器对象,其中常用的参数有C(惩罚力度)、kernel(核函数)、gamma(核函数的参数设置)、decision_function_shape(因变量的形式),再利用fit()用训练数据拟合分类器模型。
'''C越大代表惩罚程度越大,越不能容忍有点集交错的问题,但有可能会过拟合(defaul C=1);
kernel常规的有‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’ ,默认的是rbf;
gamma是核函数为‘rbf’, ‘poly’ 和 ‘sigmoid’时的参数设置,其值越小,分类界面越连续,其值越大,分类界面越“散”,分类效果越好,但有可能会过拟合,默认的是特征个数的倒数;
decision_function_shape='ovr'时,为one v rest(一对多),即一个类别与其他类别进行划分,等于'ovo'时,为one v one(一对一),即将类别两两之间进行划分,用二分类的方法模拟多分类的结果。
'''
model=svm.SVC(C=2,kernel='rbf',gamma=10,decision_function_shape='ovo')
model.fit(train_data,train_label.ravel()) #ravel函数在降维时默认是行序优先
#利用classifier.score()分别计算训练集和测试集的准确率。
train_score = model.score(train_data,train_label)
print("训练集:",train_score)
test_score = model.score(test_data,test_label)
print("测试集:",test_score)
#决策函数的查看(可省略)
#print('train_decision_function:\n',model.decision_function(train_data))#(90,3)
Resultado de salida:

Visualización de resultados de clasificación (dado que solo se seleccionan 2 dimensiones de datos de entrada, la visualización se puede realizar directamente en un plano bidimensional)
#训练集和测试集的预测结果
trainPredict = (model.predict(train_data).reshape(-1, 1))
testPredict = model.predict(test_data).reshape(-1, 1)
#将预测结果进行展示,首先画出预测点,再画出分类界面
#预测点的画法,可参考https://zhuanlan.zhihu.com/p/81006952
#画图例和点集
x1_min,x1_max=x[:,0].min(),x[:,0].max() #x轴范围
x2_min,x2_max=x[:,1].min(),x[:,1].max() #y轴范围
matplotlib.rcParams['font.sans-serif']=['SimHei'] #指定默认字体
cm_dark=matplotlib.colors.ListedColormap(['g','r','b']) #设置点集颜色格式
cm_light=matplotlib.colors.ListedColormap(['#A0FFA0','#FFA0A0','#A0A0FF']) #设置边界颜色
plt.xlabel('length',fontsize=13) #x轴标注
plt.ylabel('width',fontsize=13) #y轴标注
plt.xlim(x1_min,x1_max) #x轴范围
plt.ylim(x2_min,x2_max) #y轴范围
plt.title('SVM result') #标题
plt.scatter(x[:,0],x[:,1],c=y[:,0],s=30,cmap=cm_dark) #画出测试点
plt.scatter(test_data[:,0],test_data[:,1],c=test_label[:,0],s=30,edgecolors='k',zorder=2,cmap=cm_dark) #画出预测点,并将预测点圈出
#画分类界面
x1,x2=np.mgrid[x1_min:x1_max:200j,x2_min:x2_max:200j]#生成网络采样点
grid_test=np.stack((x1.flat,x2.flat),axis=1)#测试点
grid_hat=model.predict(grid_test)# 预测分类值
grid_hat=grid_hat.reshape(x1.shape)# 使之与输入的形状相同
plt.pcolormesh(x1,x2,grid_hat,cmap=cm_light)# 预测值的显示
plt.show()Visualice los resultados del trazado:
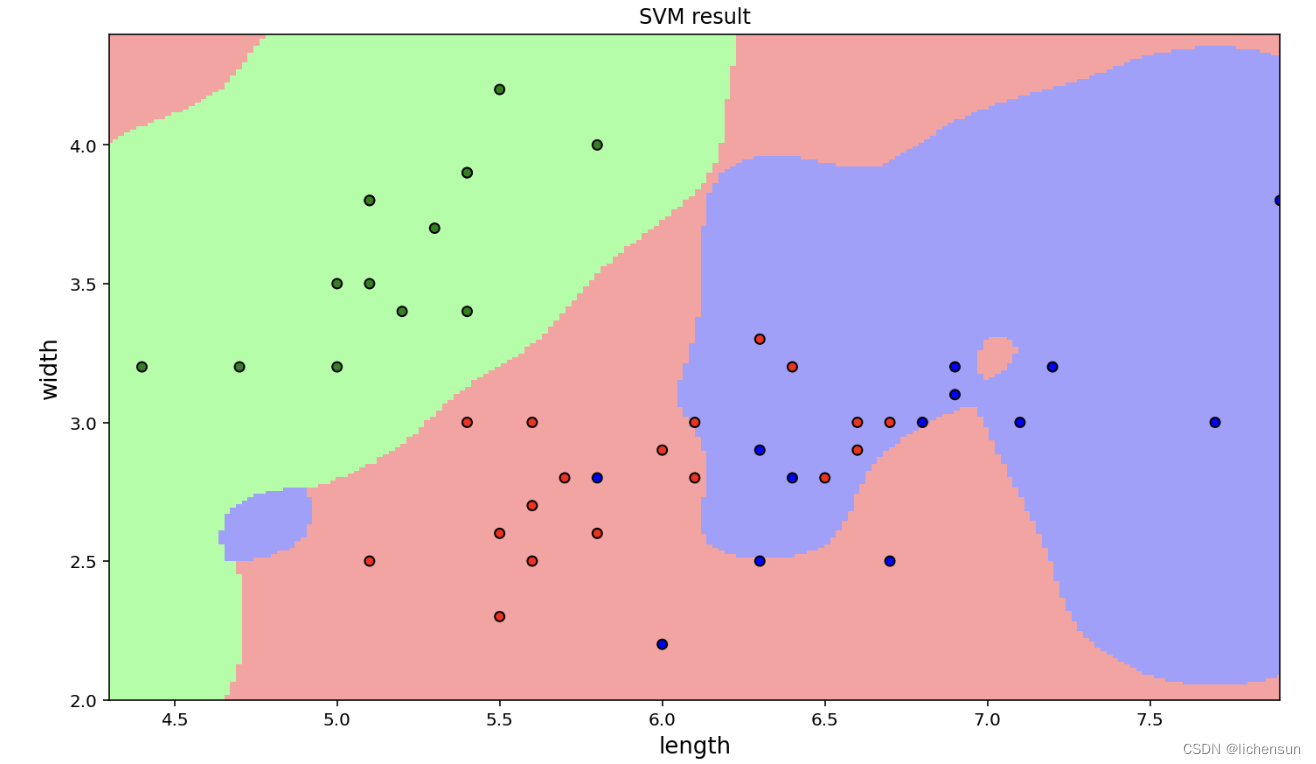
De acuerdo con los resultados, se encuentra que el efecto de la clasificación no es bueno. A continuación, se entrenan todas las funciones del iris de entrada y los resultados de la clasificación se reducen en dimensión y se muestran visualmente.