SVM y red neuronal
SVM no es una red neuronal, estos dos son dos vías totalmente diferente ahora. Sin embargo Específicamente, la sección de cálculo lineal SVM es como una sola capa redes neuronales, y es SVM completamente no lineal y de la red neural no es el mismo (sí sí, en la vida real mayor parte del problema es no lineal), los detalles puede refiriéndose sabemos casi contestar.
Los dos amantes han sido de primera indiscutible a abajo, la profundidad de la reciente estudio basado en redes neuronales debido a temas de actualidad populares AlphaGo, etc., para promover la red neuronal de calor llegó a un máximo sin precedentes. Después de todo, el estudio de múltiples capas de la estructura de la profundidad de la capa oculta que, como una caja de negro, una fuerte capacidad de aprender la caja de Pandora. Algunas personas pueden pensar que esta es nuestra red neuronal verdadera, no sabemos lo que hizo a ese número de neuronas dólares Baiqian, no entienden por qué una estructura de este tipo puede nacer mucho mejor los datos - como la complejidad de la ciencia-como, en la parte superior que no podemos saber por qué la parte inferior del "grupo de estúpidos" puede emerger. En comparación con un tanto, no parece SVM aprendizaje profundidad de manera muy fanática, incluso bromeó SVM Hinton no son más que el aprendizaje superficial (las burlas de la profundidad del aprendizaje).
De lo contrario, personalmente creo que con respecto interesado en la capa de red neuronal escondido, tiene una profunda teoría matemática de la SVM es más digno vamos a estudiar. Gran razón de ser de las matemáticas SVM puede decirse que los grandes logros matemáticos de la actualidad de la humanidad, por lo tanto, SVM red explicativa ni neuronal que se puede decir, que está lleno de ella teoría matemática racional, tal razón es un anhelo de los estudiantes de ciencia e ingeniería a. A medida que ganas de conocer la fuente de alimentación con el fin de determinar si el alimento tóxico, tóxico si lo que las drogas, lo que esta droga reaccionará en el cuerpo humano con el fin de hacerle mal - mi razón me volvió pienso, un antecedentes alimentos desconocido no puedo permitir fácilmente aceptar.
¿Cuál es SVM
En pocas palabras, SVM es un clasificador, cuando se pidió la devolución de la SVR (Apoyo vector de regresión), son los mismos en SVM y la RVS naturaleza. La figura es clasificación SVM:
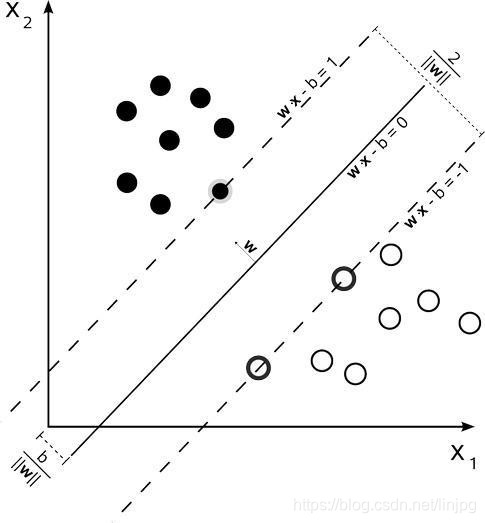
(Un punto en el límite es de vector de soporte, que es la clave, que es la "máquina de vectores de soporte" fue nombrado después)
SVM objetivo: encontrar un hiperplano que la muestra en dos, y la separación máxima. Y hemos obtenido w representa el factor hiperplano tenemos que encontrar.
El lenguaje matemático para describir:
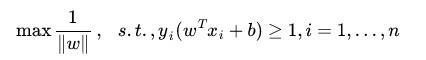
Los desarrolladores leame: cómo entiendo la máquina de soporte vectorial (SVM) y Artificial Neural Network
Esta es la SVM básica.
Investigación Operativa básica de SVM problema de programación cuadrática que pertenece a, y es un problema de programación cuadrática convexa (programación cuadrática convexa).
Andrew maestro que le explique SVM Ng
En el aprendizaje supervisado, el rendimiento de muchos algoritmos de aprendizaje son muy similares. Por tanto, es importante que usted decide no utilizar el algoritmo de aprendizaje Un algoritmo de aprendizaje o B, pero lo más importante es la gran cantidad de datos creados por la aplicación de estos algoritmos.
En la aplicación de estos algoritmos, el rendimiento por lo general depende de su nivel. Por ejemplo, como un algoritmo de aprendizaje cantidad característica diseñada de opciones y cómo elegir el parámetro de regularización ese tipo de cosas. También hay una más potente algoritmo ampliamente utilizado en la industria y el mundo académico. Se llama SVM (Apoyo Vector Machine), referido como SVM.
En la regresión logística, si hay una muestra y = 1, queremos h (x) se aproxima a uno. Esto significa que cuando h (x) tiende a 1 cuando, multiplicado por la transpuesta [theta] x 0 es mucho mayor de lo que debería ser, a continuación, la salida será la regresión logística para cierre 1.
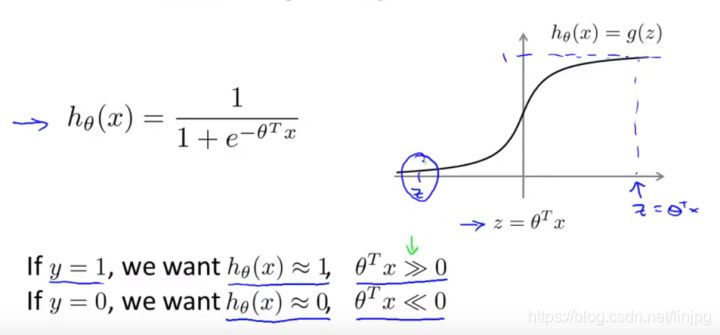
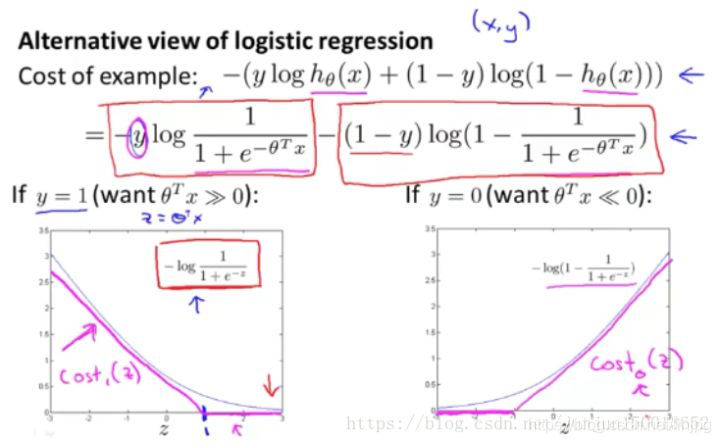
Ahora, comenzamos a construir máquinas de vectores de soporte. Vuelva a colocar la curva original con la curva de color púrpura, la nueva función de coste vamos a utilizar, para el Costo1 función izquierda (z), el derecho a la cost0 (z). Aquí, el subíndice se refiere a la función de coste correspondiente a Y = 1 e y = 0.
Una vez que tenga estas definiciones, ahora podemos empezar a construir máquinas de vectores de soporte, el cual se utiliza una función de costo J (θ) en la regresión logística.
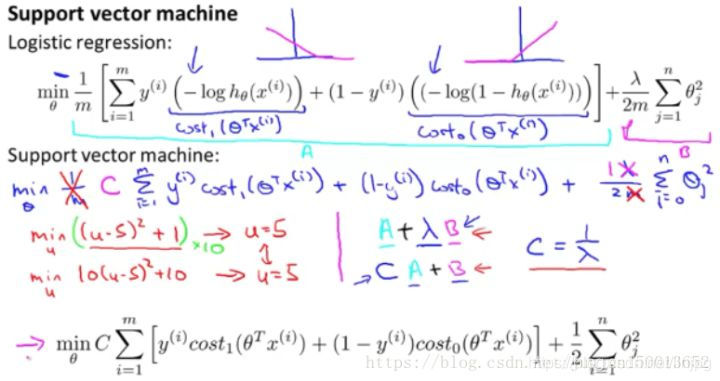
Para la regresión logística, en la función objetivo, no estamos optimizado donde A + λ × B, lo que hacemos es conjunto diferente parámetro de regularización [lambda] para lograr los propósitos de optimización. De esta manera, vamos a ser capaces de ponderar la tecla correspondiente: es hacer que la muestra de entrenamiento que es mejor ajuste para minimizar A, o lo suficientemente pequeño como para asegurar el parámetro de regularización, es decir, para los artículos B.
Λ se controla mediante el uso de la primera peso A, B o segunda peso pesado, por lo que un resultado de la optimización de la función de coste J a un mínimo.
Pero para la máquina de vectores de soporte, se utiliza un parámetro diferente, por convención, se refirió a C (similar a la acción de 1 / λ, pero no es necesariamente igual a 1 / λ) al mismo tiempo para optimizar el objetivo C × A + B. Por lo tanto, en la regresión logística, se nos da un valor muy grande de λ, significado dado mayor peso B (peso A es el peso se reduce, es equivalente al peso B del peso se incrementa). Y aquí, se corresponde con C se establece en un valor muy pequeño, entonces, un peso mayor de A a relación de B será apropiado.
Por lo tanto, esta es sólo una forma diferente para controlar este comercio-off, o un método diferente, es decir, para determinar el parámetro, que están más preocupados por la optimización de la primera plazo o segundo término se refiere más a la optimización.
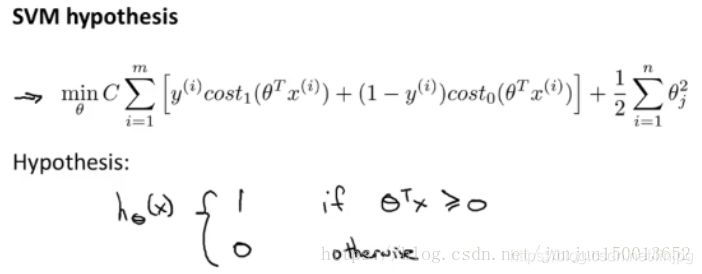
La función objetivo para obtener los parámetros de SVM C. aprendizaje Por último, la probabilidad es diferente de la salida de regresión logística, reduciendo al mínimo la función de coste para obtener los parámetros [theta], SVM es que lo hace directamente valor de predicción y igual a 1 o igual a 0 (lógica necesaria para manualmente θ determinación de regresión ^ T cuando x> 0,5, 1 predijeron ...). Por lo tanto, la función de predicción se supone 1, cuando T ^ [theta] X es mayor que o igual a 0, el parámetro de aprendizaje [theta] es la forma SVM supuesto de una función. Bueno, esta es la definición de las matemáticas de la máquina de vectores de soporte.
En segundo lugar, las grandes separación clasificador
personas ven a veces como una máquina de soporte vectorial clasificador campo grande. En esta sección se describe el significado, lo que nos ayuda a comprender intuitivamente suponemos modelo SVM es lo que, este es mi modelo SVM función de coste.
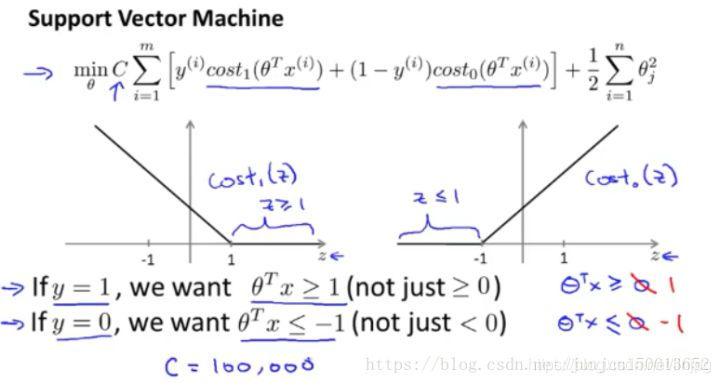
funciones Costo1 y cost2 se supone
Si usted tiene una muestra positiva de y es 1, entonces estamos en realidad sólo requiere multiplicar la transpuesta de mayor θ x que o igual a 0, la muestra puede ser separadamente. Esto es porque si θ multiplicado por la transpuesta de x es mayor que 0, se modela el valor de la función de coste es cero. Del mismo modo, si usted tiene una muestra negativa, sólo es necesaria transposición θ multiplicado por x es menor o igual a 0. El ejemplo negativo se separará correctamente.
Sin embargo, los requisitos más altos SVM, la muestra no sólo para separar correctamente de entrada, es decir, no sólo requiere la multiplicación de la transpuesta de θ x es mayor que 0, necesitamos un valor mucho mayor que 0, tal como mayor que o igual a 1. También creo que esto es mucho menor que 0, por ejemplo, yo quiero que sea menor o igual -1, que es equivalente a incrustar un factor de seguridad adicional en la máquina de vectores de soporte, o el factor de distancia de seguridad. Por supuesto, la regresión logística hace una cosa similar. Pero Echemos un vistazo a las SVM este factor conducirá a ningún resultado.
En concreto, voy a considerar un caso especial: Tenemos esta constante C se establece en un valor muy grande, por ejemplo, se supone que el valor de C 100000, u otro número muy grande, y después de observar lo que se da la oportunidad de vectores de soporte resultados.

Si C es muy grande, lo que minimiza la función de coste, nos gustaría mucho la esperanza de encontrar una solución óptima es el primer cero. Por lo tanto, una entrada de muestra de entrenamiento, etiquetado y = 1, que quieren hacer el primer término es 0, lo que necesita hacer es encontrar un [theta], de manera que [theta] se multiplica por la transpuesta de x es mayor o igual a 1.
Del mismo modo, para un entrenamiento de etiqueta de la muestra y = 0. Con el fin de cost0 (z) es 0, necesitamos multiplicar la transpuesta de θ menor que el valor de x es igual a -1. Porque vamos a seleccionar el primer parámetro es 0, nuestro problema de optimización se convierte en la esquina inferior derecha, como se muestra de esta manera, para resolver el problema de optimización, cuando minimiza esta función con respecto a las variables θ, obtendrá una frontera de decisión muy interesante.
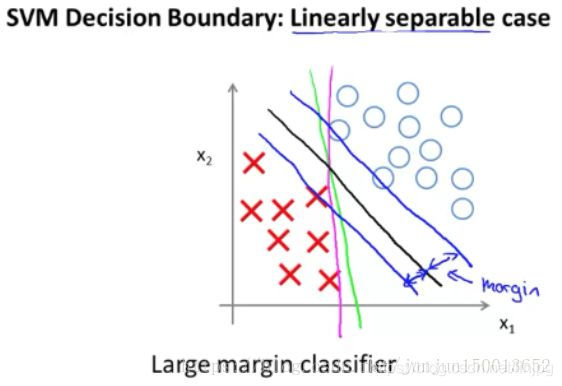
En concreto, si nos fijamos en Tal linealmente separables conjuntos de datos, límite de caracteres de color rojo y verde claramente no es una buena opción, máquinas de vectores soporte elegirán la frontera de decisión negro. Mira, esta es una más robustos y mejores círculos de toma de decisiones, que tiene una mayor distancia. Esta distancia se denomina distancia (margen) y esta es la razón para máquinas de vectores soporte robusto, ya que está tratando de utilizar un espacio máximo para muestras independientes, por lo que SVM es a veces llamado el gran espaciado clasificador. Y esto es en realidad el resultado de resolver problemas de optimización en las diapositivas anteriores.
Recuerde factor de regularización premisa de este ejemplo, la constante C se pone muy grande, de hecho, son ahora más sofisticados SVM clasificador esta gran separación que refleja.
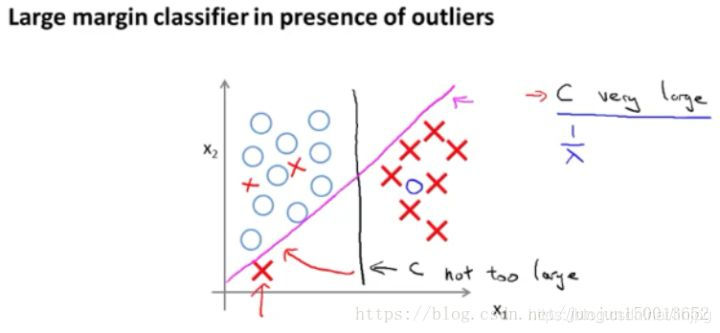
Como se muestra un conjunto de tales muestras, la esquina inferior izquierda hay valores extremos, cuando la regularización parámetro C se pone muy grande, máquinas de vectores soporte con el tiempo conseguir un trozo de hilo de color rosa, sobre la base de un solo valor atípico del sector será mi decisión esta línea negro se cambia a esta línea de color rosa, que no es prudente.
Pero si es pequeño punto de ajuste C, y luego se termina con esta línea negro. Es decir, cuando el valor de C apropiada, máquinas de vectores soporte puede pasar por alto algunos de los efectos de los valores extremos, mejores círculos de toma de decisiones. En consecuencia, la descripción es muy grande clasificador de tono meramente dada parámetro de regularización C en el caso de muy grandes de forma intuitiva.
En tercer lugar, los principios matemáticos detrás de la gran margen clasificador
En primer lugar, revisar el conocimiento sobre el producto interno del vector producto interno entre el resultado multiplicado por v u transponer del vector u y v:
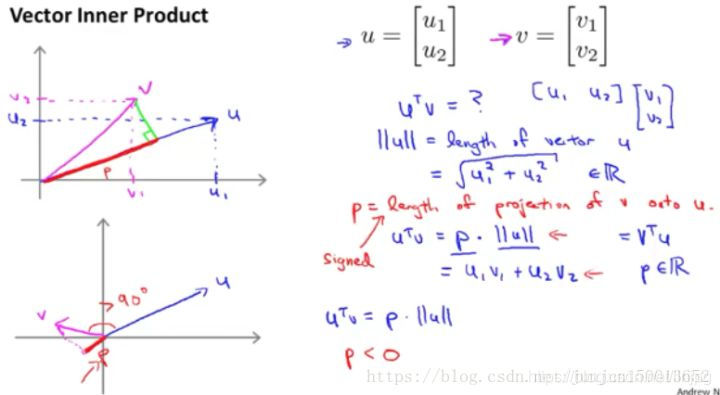
u. v = u || || || v || cos [theta] = P || || u (donde p = || v || * cos, es decir, en la proyección de u V, que es positiva o negativa, [theta] se determina por el flip)
Este es el conocimiento sobre el vector de producto interno, vamos a utilizar estos en el siguiente vector de producto interno de la naturaleza, tratando de comprender la función de apoyo de máquinas de vectores objetivo. Este es el modelo SVM hemos dado con anterioridad función objetivo (cuando C es muy grande). Para facilitar la explicación, θ0 ignorado hasta interceptar igual a 0, en el que el número n se establece en 2.
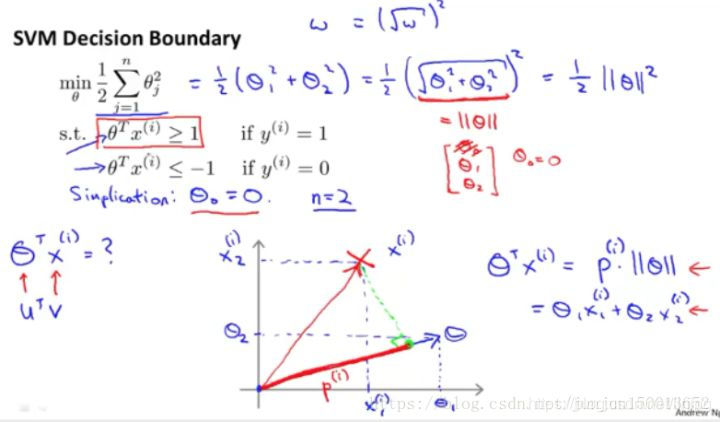
La imagen muestra una proyección del vector xi en un vector anterior θ
Por lo tanto, la imagen de arriba condiciones será [theta] T XI se convierte en p bajo la condición de la figura || [theta] ||
Ahora, nos fijamos en la función objetivo, SVM función objetivo, ya que estamos solamente dos características x1, x2, es decir, n = 2, esta fórmula puede escribirse como medio θ1 más θ2 cuadrado cuadrado, ya que el primer término es 0, por lo que necesitamos la segunda (es decir, la mitad más θ2 θ1 cuadrado cuadrado) mínimo. Nosotros sólo dos parámetros theta] 2 theta] 1 y la función objetivo se pueden simplificar, como se muestra en la elección correcta del vector [theta] y el límite es vertical (como límites de decisión theta] 1 X1 + theta] 2 X2 = 0, la pendiente de -θ1 / θ2, el vector θ = (θ1, theta] 2) es la pendiente θ2 / θ1).
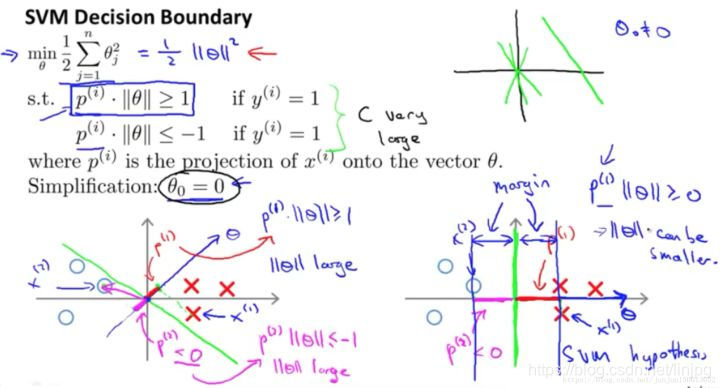
Vistazo a la parte izquierda del mapa frontera de decisión, que analiza SVM ¿Por qué no va a votar por ella, y elegir el límite derecho del intervalo máximo de toma de decisiones.
Máquinas de Vectores Soporte porque todas las cosas que hacer es reducir al mínimo la norma al cuadrado del vector de parámetros θ.
En el p * || θ ||> = 1 si y = 1 y p * || θ || <= - 1 si y = 0 cuando:
Consideremos en primer lugar el caso en que y = 1: norma mínimo tal que [theta], es decir, [theta] || || mínimo, y p * || θ ||> = 1, entonces p lo más grande posible para el trabajo, en el θ x p proyección, la proyección es que cuanto más grande mejor, como he dicho antes θ y la frontera de decisión es vertical, entonces x se proyecta sobre el θ x es la distancia vertical desde la frontera de decisión, y, finalmente, el problema se reduce a la frontera de decisión a x la distancia vertical más grande es el mejor, y que es la oportunidad de elegir el intervalo máximo de frontera de decisión SVM. Análisis supra y = 0 en el caso.
y = 1 cuando la norma mínima → θ → || θ || mínimo → p * || θ ||> = 1 → p → p lo más grande posible es x → θ y una proyección en la frontera de decisión es [theta] P x → = proyección vertical en la x θ = la decisión distancia vertical límite → = P lo más grande posible tan grande como → frontera de decisión que la máxima distancia de separación x perpendicularmente a la frontera de decisión
En cuarto lugar, el núcleo que
hacer algunos cambios en el algoritmo de apoyo de máquinas de vectores para construir clasificadores no lineales complejas, utilizamos "núcleos (kernels)" para lograr este propósito.

Veamos lo que la función del núcleo es y cómo usarlo. Si usted tiene un conjunto de entrenamiento, algo como esto, entonces usted desee para adaptarse a una frontera de decisión no lineal, para distinguir entre muestras positivas y negativas. Un enfoque consiste en construir un polinomio característica variable, si θ1 θ0 * x1 acoplada junto con otras variables características de la suma polinomio es mayor que 0, entonces predicción es 1. Por el contrario, la predicción es de 0.
Otra forma de este método θ0 + θ1 × f1 + θ2 × f2 + θ3 × f3 + ..., a continuación, f1 es igual a x1, F2 es igual a x2, F3 igual a este x1x2, f4 igual al cuadrado de x1, f5 igual al cuadrado de x2, y así sucesivamente. Antes de ver por la adición de estos términos de orden superior, podemos obtener más características variables.
La cuestión es cómo construir estos términos de orden superior para mejor ajuste de nuestros datos:

No se puede construir una novela f1 característica, f2, f3 idea, seleccione manualmente un número de puntos se definen como la l primer marcador (1), el segundo marcador l (2), el tercer marcador de l (3), en el que la variable fn n-ésimo se define como una medida de similitud. Fórmula similitud muestra métrica x n-ésimo marca, la métrica de similitud se ha descrito anteriormente en la figura. La función de similitud es la función del núcleo, aquí está el núcleo gaussiano, y en donde x se supone que un marcador l (n) está muy cerca de, la fn más cerca. 1, fn la inversa que cerca de cero.
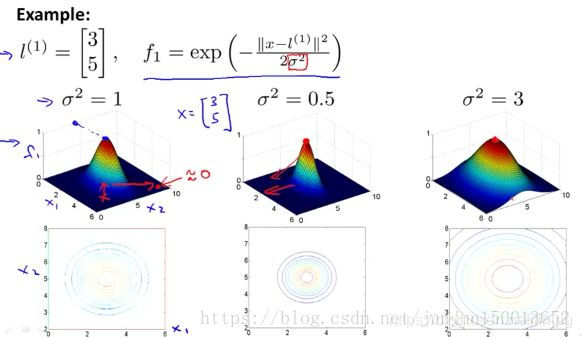
σ es la plaza de los parámetros de la función del núcleo de Gauss, cuando cambia su valor, obtendrá resultados ligeramente diferentes. El cuadrado más pequeño de σ, más estrecha será la anchura de la protuberancia, un gráfico de contorno también número de contrato, el valor de la variable reducida característica de velocidad se hace más rápido.
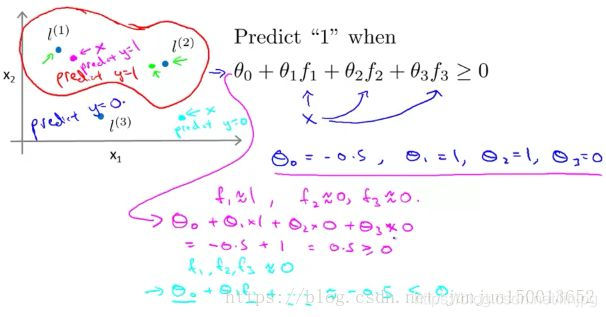
Supongamos que hemos encontrado un algoritmo de aprendizaje, y supongamos que tengo los valores de estos parámetros. Así que si θ0 es igual a -0,5, θ1 es igual a 1, θ2 es igual a 1, θ3 es igual a 0. Como se muestra, supongamos que tenemos una muestra de entrenamiento x está cerca de L (1) está cerca de 1, entonces f1. Y debido a que la muestra de entrenamiento x de l (2) l (3) está muy lejos, por lo que es casi 0 F2, F3 también está cerca de 0, lo mismo que antes, y otro punto diferente x se calcula si encuentra f1 f2 f3 Estamos cerca de cero. Por lo tanto, a través del cálculo, que predijo valores de y es 0, entonces un gran número de puntos correspondiente tal proceso, que termina con una decisión límite la función de predicción.
Este límite de decisión dentro de los rojos valores y pronosticados es igual a 1, en el que el exterior predijo valores de y igual a cero.
Este es el concepto de esta parte del núcleo, y la forma en que los utilizan en máquinas de vectores soporte. Definimos una nueva marcadores variables características y función de similitud, para entrenar a un complejo de clasificadores lineales.
En quinto lugar, el núcleo II
sobre un tema legado, ¿cómo obtener estos marcadores?
Dirigimos la muestra de entrenamiento como un marcador, se rodeará el proceso es el siguiente:


Dos detalles son: n = m, el número de muestras es igual al número de características para optimizar la segunda θj función de 1 a m, y cuadrada, se puede reescribir como multiplicada por la transpuesta de θ θ, recuerde ignorar θ0.
La mayor parte de SVM en la realización, asumiendo la función de transposición lo reemplazan multiplicado por fuera θ θ se multiplica por una matriz transpuesta θ, dependiendo de su uso del núcleo, que es en realidad otro ligeramente diferente tipo de método de medición de distancia. Nos ligero cambio en una medida para reemplazar, sin suavizarlas directa del cuadrado del módulo de θ. Pero minimizada otra métrica similar, que se está convirtiendo en el parámetro de modo de vector θ estándar. Este cambio y las funciones nucleares relacionada, los detalles matemáticos de manera que SVM pueden ejecutar más eficiente.
SVM razón para hacer tal modificación se hace para acomodar conjunto de entrenamiento grande, por ejemplo: cuando el conjunto de entrenamiento de 10.000 muestras, lo que ayudará con los paquetes de software de cálculo de máquinas de vectores soporte. .
Por cierto, puede que se pregunte por qué no aplicamos el núcleo de esta idea a otros algoritmos, como la regresión logística sobre. Los hechos han demostrado que, si se desea, se puede de hecho ser usado para definir el vector de características del kernel idea. El marcador de tales técnicas para el algoritmo de regresión logística. Sin embargo, para máquinas de vectores soporte habilidades de cálculo, no mejor generalizada a otros algoritmos, como la regresión logística sobre. Por lo que la función del núcleo utilizado para la regresión logística, será muy lenta. Por el contrario, la técnica de cálculo, como la tecnología del hormigón, las modificaciones a estos detalles, y soporte de software de vectores detalles de implementación, como la función SVM núcleo y se complementan entre sí. La regresión logística y el kernel, se ejecutan muy lentamente, por no hablar de que no pueden utilizar esas técnicas de optimización avanzadas, debido a que estas técnicas están diseñadas para las personas para el desarrollo de máquinas de vectores soporte utilización del núcleo.
Cuando se utiliza el SVM desviación - varianza compromiso, utilizando máquinas de vectores de soporte, que es una cuestión de elección para el parámetro de la función objetivo C correspondientes a las pequeñas lambda problemas de regresión logística grande C. Esto significa que sin el uso de regularización, es posible hacer si recibe un sesgo bajo, pero más alta varianza más inclinado a ajuste del modelo, si se utiliza una pequeña C, que corresponde a su uso en una logística que los problemas de regresión λ corresponde a un grande de alta desviación, pero baja varianza modelo underfitting prefieren, además de un parámetro seleccionado es una función gaussiana núcleo σ ^ 2, cuando una función kernel gaussiana sigma 2 ^ cuando demasiado grande, a continuación, el kernel gaussiana tiende a ser relativamente suave, esto le dará a su modelo, resultan en un mayor sesgo y menor varianza. Por el contrario, si σ ^ 2 es muy pequeña, es decir, Gaussian kernel similitud función varían muy grave, el modelo resultante sería un sesgo de baja y alta varianza.
En sexto lugar, las SVM de práctica
para la máquina de soporte vectorial, tenemos que hacer primero es seleccionar el parámetro C. En segundo lugar, la función del núcleo.
Una opción que elegimos sin ningún núcleo, la función del núcleo sin esta práctica, también conocida como núcleo lineal. Este uso de una única θ SVM transposición multiplicado por x. Cuando θ0 + θ1x1 + ... + θnxn que 0, y = a término lineal predicción kernel 1 par. Se puede entender como esta versión de SVM que sólo te da un clasificador lineal estándar (cuando no se kernel?). Por lo tanto, en ciertos temas, es una elección razonable. Y usted sabe, hay muchas bibliotecas de software, tales como LIBLINEAR es un ejemplo de la biblioteca de software de muchos, que pueden ser utilizados para entrenar la SVM es ninguna de las funciones nucleares. Entonces ¿por qué hacer tal cosa que quieres hacer?
Si usted tiene un gran número de variables características, si n es grande, y el número de M muestras conjunto de entrenamiento pequeña. Bueno, usted sabe que tiene un montón de características es un vector + 1 dimensiones variables x n, por lo que si usted ya tiene una gran cantidad de valores propios y un pequeño conjunto de datos de entrenamiento, tal vez debería ajustarse a un límite de decisión lineal, no caben función no lineal muy complejo, porque no hay suficientes datos.
Si quieres un espacio de características de alta dimensión tratando de encajar función muy compleja, y el conjunto de entrenamiento y pequeños, es posible que el exceso de ajuste. Por lo tanto, debe ser su decisión no puede aplicarse a la función nuclear, o de manera equivalente, el uso de una función de núcleo razonablemente lineal.
Al seleccionar el kernel de Gauss es la función del núcleo, que tiene que hacer Otra opción es seleccionar un parámetro σ al cuadrado.
Así que la hora de seleccionar Gauss kernel que? Si el original característica variable x n dimensiones, si n es pequeño, y lo ideal, si m es grande.
Así que si tenemos un conjunto de entrenamiento de dos dimensiones, como en el ejemplo que he mencionado antes de la misma, entonces n es igual a 2. Pero tenemos bastante grande conjunto de entrenamiento, he dibujado mucho entrenamiento muestras, entonces puede que tenga que utilizar una función kernel para adaptarse a una más compleja frontera de decisión no lineal, entonces el núcleo gaussiano sería una opción buena.
Si utiliza octava o Matlab para lograr el apoyo de máquinas de vectores, a continuación, se le pedirá que proporcione una función para calcular las características específicas de la función del núcleo. Se generará de forma automática todas las variables características, se utilice automáticamente esta función se escribe será asignada a la correspondiente x F1, F2, hasta que FM generar todos los valores propios, ya partir de aquí comenzó a entrenar a las máquinas de vectores de soporte. Pero a veces hay que proporcionar su propia, pero esta función si está utilizando un kernel de Gauss, las implementaciones de SVM se incluyen algunos de los kernel de Gauss y otras funciones básicas, porque Gauss núcleo es, probablemente, el núcleo más común.
Si usted tiene características muy diferentes dimensiones variables, antes de usar el kernel de Gauss, que se normalizó es muy importante.
Ahora bien, si usted es una característica que los rangos variables de precios muy diferentes pronostican para tomar un ejemplo: Si los datos son algunos datos sobre la casa, si los valores de x1 en la gama de miles de pies cuadrados, pero es dormitorio x2 número, y si está dentro del rango de uno a cinco dormitorios.
Así X1-L1 será grande, lo que puede miles de valores cuadrados. Sin embargo x2-L2 se convertirá en pequeño, entonces en tal caso, a continuación, esta fórmula, estas parcelas serán casi siempre serán determinadas por el tamaño de la casa. Por lo tanto ignorar el número de dormitorios, con el fin de evitar esto, deje de máquinas de vectores de trabajar bien. De hecho las variables características tienen que ser normalizado, lo que asegurará que SVM puede que se trate por igual sobre todas las diferentes variables características, en lugar de centrarse en el tamaño de la casa como ejemplo, sin tener en cuenta otras variables características
No todos ustedes puede poner función de similitud adelante es función del núcleo válida, Gaussian kernel, lineal núcleo y otras veces utilizan funciones básicas adicionales, todos los cuales tienen que cumplir una condición técnica: se llama Somerset la razón Seúl Teorema (de Mercer Teorema) necesario para cumplir esta condición es: porque el algoritmo de máquinas de vectores soporte o implementar SVM, hay muchas técnicas de optimización numérica inteligentes, con el fin de resolver eficazmente el θ parámetro, la visión original, hay una decisión de este tipo una el único límite nuestra atención en las funciones básicas para cumplir el teorema de Mercer. Este teorema no se asegurará de que todos los paquetes de todo paquete de software SVM SVM pueden utilizar una gran cantidad de métodos de optimización, y obtener rápidamente parámetro θ.
Algunas otras funciones básicas: la función polinómica núcleo, núcleos de cuerda, del núcleo de chi-cuadrado, del núcleo, y así sucesivamente intersección histograma.

La discusión de los últimos dos detalles:
Es una clasificación con varias categorías, que tiene cuatro categorías, o, más en general, la categoría K. Cómo hacer que la frontera de decisión SVM salida adecuada entre las diversas categorías? La mayor parte de paquete de SVM SVM tiene muchas funciones integradas de la clasificación con varias categorías, por lo que si usted está utilizando un tipo de paquete de software, puede utilizar directamente las funciones incorporadas. Usted puede utilizar el incorporado en funciones, debería ser capaz de trabajar bien directamente.
De lo contrario, muchos de otra manera (uno-contra-todos) método. Hemos hablado de esto en el momento de explicar la regresión logística, por lo que tiene que hacer es entrenar al K SVM. Si tiene categoría K, entonces un similares entre sí SVM clase distinguir, esto le dará el vector de parámetros K, que es θ (1), tal que y = 1 a theta (1), que la y = 1 y todos los demás categorías tales distingue de todas las demás categorías de distinguir, a continuación, obtener un θ segundo parámetro de vector (2), y luego obtener la θ segundo parámetro de vector (2), es como y = 2 de tipo n, es y = 2 para la clase positiva, clases de otras clases obtenidas es negativo. Y así sucesivamente, hasta que el vector de parámetros [theta] (K) se utiliza para distinguir la última categoría, el parámetro de categoría de vectores K y otras categorías.
Así que cuando vamos con esto?
Si el número n de variables con respecto a las características de su tamaño de capacitación es más grande, a menudo mediante regresión logística o ningún uso de la función kernel SVM o llamada núcleo lineal.
Si n es pequeño, y m es un tamaño medio, quiero decir que n puede tomar 1 - Cualquier número entre 1.000. Si el número de muestras de entrenamiento puede ser de quizás 10 a cualquier valor entre 10.000 muestras, tal vez hasta 50.000 muestras, por lo general es de Gauss SVM función del núcleo funcionará bien.
Una tercera preocupación es la situación: si n es pequeño, pero grande m. A continuación, el kernel de Gauss SVM, corriendo será muy lento. SVM paquete de hoy, si un kernel de Gauss, que será muy lenta. Si usted tiene 50.000, también es posible, pero si usted tiene un millón de muestras de entrenamiento, o cien mil, soy un gran valor. SVM paquete de hoy es muy buena, pero si usted es un gran, gran conjunto de entrenamiento, utilizando un kernel de Gauss, entonces van siendo algo lenta. En este caso, a menudo hacer es tratar de crear manualmente las variables más característicos, a continuación, mediante regresión logística o sin un SVM función del núcleo.
Ves esta diapositiva, se ve una regresión logística o sin función SVM núcleo en esta ambos lugares, y los pone juntos por una razón, y sin regresión logística función del núcleo SVM que está el algoritmo es muy similar, que van a hacer algo similar y también un rendimiento similar, pero dependiendo de la situación se da cuenta de lo que uno puede ser más eficaz que el otro, pero si uno se aplica el algoritmo, luego otro algoritmo, y muy que podría funcionar bien, pero el poder de la SVM, a medida que aprende a usar un diferentes funciones del kernel, la función no lineal compleja, y el juego.
Por último, las redes neuronales se deben usar cuando? Por todas estas preguntas, todos estos intervalos, una red neuronal bien diseñado también es probable que sea muy eficaz.
Un inconveniente es su razón o, a veces no pueden utilizar redes neuronales para muchos de estos problemas, las redes neuronales puede ser lento. Pero si usted tiene un muy buen paquete SVM logra, se ejecutará más rápido, mucho más rápido que la red neuronal, aunque no hemos probado antes, de hecho, el problema de optimización SVM es un problema de optimización convexa, tan bueno paquetes de optimización SVM siempre encontrarán el valor mínimo global o cerca de ella, no se preocupe por un problema óptimo local.
En la aplicación práctica, no una red neuronal óptimo local necesita resolver un problema importante. De acuerdo a su pregunta, la red neuronal puede ser más lenta que la SVM.
Algoritmo es de hecho muy importante, pero a menudo es más importante: la cantidad de datos que tiene, cómo usted está calificado, ya sea bueno en hacer el análisis de errores y depuración algoritmo de aprendizaje. Encontrar la manera de diseñar nuevas características a las variables de entrada y términos deben encontrar otras características tales como algoritmos de aprendizaje variables, estos aspectos por lo general SVM este respecto es más importante que está utilizando regresión logística, o. Sin embargo, se ha dicho que la SVM es aún ampliamente considerado como uno de los más potentes algoritmos de aprendizaje, sino también en una serie de SVM, es una forma muy eficaz de aprender función no lineal compleja. Así que, en realidad, la regresión logística, redes neuronales, SVM juntos, con estos tres algoritmos de aprendizaje, creo que ya tiene la capacidad de sistema de aprendizaje de máquinas de última generación acumulación en una amplia gama de aplicaciones en las que es su arma biblioteca de otra herramienta muy potente que se utiliza ampliamente en muchos lugares.
Referencia 11 Machine Learning (Andrew Ng): SVM
desarrollador readme: cómo entiendo la máquina de soporte vectorial (SVM) y Artificial Neural Network
