[Minería de datos] Minería de datos #Business Intelligence (BI) Análisis de datos y concepto de minería
Actualmente la minería de datos está en auge en todo tipo de empresas e instituciones. Por lo tanto, hemos producido un resumen de la terminología común en este campo.
- CRM/aCRM analítico: Se utiliza para apoyar la toma de decisiones, mejorar la interacción de la empresa con los clientes o aumentar el valor de la interacción. Recopile, analice y aplique el conocimiento sobre los clientes y cómo contactarlos de manera efectiva.
- Big Data: Big Data es una palabra de moda usada en exceso y una tendencia real en la sociedad actual. Este término se refiere al volumen cada vez mayor de datos que se capturan, procesan, agregan, almacenan y analizan todos los días. Así es como Wikipedia describe "Big Data": "La suma de conjuntos de datos tan grandes y complejos que las herramientas de gestión de bases de datos existentes son intratables (...)".
- Business Intelligence: aplicaciones, instalaciones, herramientas y procesos que analizan datos y presentan información para ayudar a los ejecutivos de negocios, la gerencia y otros a tomar decisiones comerciales más informadas.
- Análisis de rotación/Análisis de desgaste: describa qué clientes probablemente dejarán de usar el producto/negocio de la empresa e identifique qué clientes son más costosos de abandonar. Los resultados del análisis de abandono se utilizan para preparar nuevas ofertas para los clientes que probablemente abandonen.
- Análisis conjunto/Análisis de compensación: Comparación de varias variantes diferentes del mismo producto/servicio sobre la base del uso real por parte de los consumidores. Puede predecir la aceptación de productos/servicios después de su lanzamiento y se utiliza para la gestión de líneas de productos, fijación de precios y otras actividades.
- Credit Scoring: Evaluación de la solvencia de una entidad (empresa o individuo). El banco (el prestatario) usa esto para determinar si el prestatario pagará el préstamo.
- Cross/Up Selling: Un concepto de marketing. Vender productos complementarios (venta de kits) o productos adicionales (venta de valor agregado) a consumidores específicos en función de sus características y comportamiento pasado.
- Segmentación y creación de perfiles de clientes: según los datos de clientes existentes, los clientes con características y comportamientos similares se clasifican en grupos. Describir y comparar grupos.
- Data Mart: datos almacenados por una organización específica sobre un tema o departamento específico, como datos de ventas, financieros y de marketing.
- Almacén de datos: un depósito central de datos que recopila y almacena datos de múltiples sistemas comerciales de una empresa.
- Calidad de los datos: Procesos y técnicas relacionados con la garantía de la fiabilidad y utilidad de los datos. Los datos de alta calidad deben reflejar fielmente el proceso de transacción que hay detrás y poder cumplir con el uso esperado en las operaciones, la toma de decisiones y la planificación.
- Extraer-Transformar-Cargar ETL (Extraer-Transformar-Cargar): Un proceso en el almacenamiento de datos. Adquiera datos de una fuente, transforme los datos según sea necesario para su uso posterior y luego coloque los datos en la base de datos de destino correcta.
- Detección de fraude: identifique transferencias, pedidos y otras actividades ilegales sospechosas de fraude contra organizaciones o empresas específicas. Las alertas desencadenadas están prediseñadas en el sistema de TI, y aparecerán advertencias al intentar o realizar dichas actividades.
- Hadoop: Otra palabra de moda de Big Data hoy en día. Apache Hadoop es una arquitectura de software de código abierto para el almacenamiento y procesamiento distribuidos de grandes conjuntos de datos en un clúster de computadoras compuesto por hardware comercial existente. Permite el almacenamiento de datos a gran escala y un procesamiento de datos más rápido.
- Internet de las cosas (IoT): una red ampliamente distribuida que consta de dispositivos electrónicos de muchos tipos (personales, domésticos, industriales) y muchos propósitos (médico, ocio, medios, compras, fabricación, regulación ambiental). Estos dispositivos intercambian datos y coordinan actividades entre sí a través de Internet.
- Customer Lifetime Value (Valor de por vida, LTV): La ganancia descontada esperada que un cliente generará para una empresa durante su vida.
- Aprendizaje automático: una disciplina que estudia el aprendizaje automático a partir de datos para que las computadoras puedan ajustar sus operaciones en función de la retroalimentación que reciben. Está estrechamente relacionado con la inteligencia artificial, la minería de datos y los métodos estadísticos.
- Análisis de la cesta de la compra: identifique combinaciones de bienes o servicios que a menudo coexisten en transacciones, como productos que a menudo se compran juntos. Los resultados de dicho análisis se utilizan para recomendar productos adicionales, proporcionar una base para la toma de decisiones sobre la exhibición de productos, etc.
- Procesamiento analítico en línea (OLAP): una herramienta que permite a los usuarios crear y examinar fácilmente informes que resumen datos relevantes y los analizan desde múltiples perspectivas.
- Análisis predictivo: extracción de información de conjuntos de datos existentes para identificar patrones y predecir futuros rendimientos y tendencias. En los negocios, los modelos y análisis predictivos se utilizan para analizar datos actuales y hechos históricos para comprender mejor a los clientes, productos, socios e identificar oportunidades y riesgos para la empresa.
- Toma de decisiones en tiempo real (RTD): ayude a las empresas a tomar decisiones óptimas de ventas/mercadeo en tiempo real (casi sin demora). Por ejemplo, un sistema de toma de decisiones en tiempo real (sistema de puntuación) puede puntuar y clasificar a los clientes en el momento en que interactúan con la empresa a través de varias reglas o modelos comerciales.
- Retención / Retención de Clientes: Se refiere al porcentaje de relaciones con clientes que se pueden mantener por mucho tiempo después del establecimiento.
- Análisis de redes sociales (SNA): representa y mide las relaciones y los flujos entre personas, grupos y grupos, instituciones e instituciones, computadoras y computadoras, URL y URL y otros tipos de entidades de información/conocimiento conectadas. Estas personas o grupos son nodos en la red y las líneas entre ellos representan relaciones o flujos. SNA proporciona un método para analizar las relaciones humanas que es tanto matemático como visual.
- Análisis de supervivencia: estimación de cuánto tiempo un cliente seguirá utilizando un negocio, o la probabilidad de perder en períodos posteriores. Dicha información permite a las empresas juzgar la retención de clientes durante el período de pronóstico deseado e introducir políticas de lealtad adecuadas.
- Minería de texto: el análisis de datos que contienen lenguaje natural. Se realizan cálculos estadísticos sobre las palabras y frases de los datos de origen para expresar la estructura del texto en términos matemáticos y, a continuación, se analiza la estructura del texto mediante técnicas tradicionales de extracción de datos.
- Datos no estructurados: los datos carecen de un modelo de datos predefinido o no están organizados de acuerdo con una especificación predefinida. Este término generalmente se refiere a información que no se puede colocar en una base de datos en columnas tradicional, como mensajes de correo electrónico, comentarios.
- Minería web / Minería de datos web: el uso de técnicas de minería de datos para descubrir y extraer información automáticamente de sitios, documentos o servicios de Internet.
Diferencia entre base de datos y almacén de datos
La diferencia entre una base de datos y un almacén de datos es en realidad la diferencia entre OLTP y OLAP.
El procesamiento operativo, llamado OLTP (On-Line Transaction Processing), también puede llamarse un sistema de procesamiento orientado a transacciones.Es una operación diaria en la base de datos para negocios específicos, y generalmente consulta y modifica una pequeña cantidad de registros. Los usuarios están más preocupados por el tiempo de respuesta de las operaciones, la seguridad de los datos, la integridad y la cantidad de usuarios admitidos simultáneamente. Como principal medio de gestión de datos, el sistema de base de datos tradicional se utiliza principalmente para el procesamiento operativo.
El procesamiento analítico, llamado OLAP (On-Line Analytical Processing), generalmente analiza datos históricos de ciertos sujetos para respaldar las decisiones de gestión.
En primer lugar, debemos entender que el surgimiento del almacén de datos no reemplaza a la base de datos.
- La base de datos es un diseño orientado a transacciones, el almacén de datos es un diseño orientado a temas.
- Las bases de datos generalmente almacenan datos comerciales y los almacenes de datos generalmente almacenan datos históricos.
- El diseño de la base de datos es para evitar la redundancia tanto como sea posible. Generalmente, está diseñado para una determinada aplicación comercial, como una tabla de usuario simple, que puede registrar datos simples como el nombre de usuario y la contraseña, que es adecuado para aplicaciones comerciales, pero no es adecuado para el análisis. El diseño del almacén de datos introduce intencionalmente redundancia y está diseñado de acuerdo con los requisitos del análisis, las dimensiones del análisis y los indicadores del análisis.
- Las bases de datos están diseñadas para capturar datos, los almacenes de datos están diseñados para analizar datos.
Tome la banca, por ejemplo. La base de datos es la plataforma de datos del sistema de transacciones. Cada transacción realizada por el cliente en el banco se escribirá en la base de datos y se registrará. Aquí, puede entenderse simplemente como el uso de la base de datos para llevar las cuentas. El almacén de datos es la plataforma de datos del sistema de análisis. Obtiene datos del sistema de transacciones, los resume y procesa, y proporciona a los responsables de la toma de decisiones una base para la toma de decisiones. Por ejemplo, cuántas transacciones ocurren en una determinada sucursal de un banco en un mes y cuál es el saldo actual de depósito de la sucursal. Si hay más depósitos y más transacciones de consumo, entonces es necesario instalar un cajero automático en el área.
Obviamente, el volumen de transacciones de los bancos es enorme, generalmente calculado en millones o incluso decenas de millones de veces. El sistema de transacciones es en tiempo real, lo que requiere puntualidad, los clientes tardan decenas de segundos en depositar una suma de dinero, lo cual es insoportable, lo que requiere que la base de datos solo almacene datos durante un período corto de tiempo. El sistema de análisis es posterior al evento y debe proporcionar todos los datos válidos dentro del período de tiempo de interés. Estos datos son masivos y el cálculo resumido es más lento, pero mientras se puedan proporcionar datos de análisis efectivos, se logrará el objetivo.
El almacén de datos se produce con el fin de extraer más recursos de datos y tomar decisiones cuando ya existe una gran cantidad de bases de datos. De ninguna manera es una de las llamadas "bases de datos grandes".
Conceptos relacionados
Data Warehouse: el nombre completo en inglés de DW es Data Warehouse, que es una recopilación de datos relativamente estable, integrada y orientada a temas que refleja los cambios históricos y se utiliza para respaldar las decisiones de gestión.
Cubo: el objeto principal en el procesamiento analítico en línea (OLAP), un cubo es una tecnología que permite un acceso rápido a los datos en un almacén de datos Un cubo es una colección de datos, generalmente de un subconjunto del almacén de datos Construir, organizar y resumir en una estructura multidimensional definida por un conjunto de dimensiones y medidas.
Dimensiones: propiedades estructurales de un cubo. Son jerarquías organizadas (niveles) de categorías utilizadas en tablas de hechos para describir datos. Estas categorías y niveles describen conjuntos similares de miembros en función de los cuales los usuarios analizarán.
Medidas: en un cubo, una medida es un conjunto de valores que se basan en una columna en la tabla de hechos del cubo y generalmente es numérica. Además, una medida es el valor central del cubo que se analiza.
Tabla de hechos: se refiere a una tabla en la que se guarda una gran cantidad de datos de medición comercial. Las medidas en una tabla de hechos generalmente se conocen como hechos.
Para otros conceptos relacionados, consulte la introducción en el blog. Para obtener más detalles, consulte el sistema de análisis multidimensional
ETL basado en mondrian: extracción, conversión y carga.
La esencia del trabajo de ETL es extraer datos de varias fuentes de datos, convertir los datos y, finalmente, cargar y completar los datos en el almacén de datos Tablas modeladas dimensionalmente. El trabajo de ETL no está completo hasta que se completan estas tablas de dimensiones/hechos. A continuación, explicaremos los tres enlaces de extracción, conversión y carga respectivamente:
1. Extracto
Los almacenes de datos están orientados al análisis, mientras que las bases de datos operativas están orientadas a la aplicación. Obviamente, no es necesario analizar todos los datos utilizados para respaldar los sistemas comerciales. Por lo tanto, esta etapa es principalmente para determinar los datos que deben extraerse de la base de datos de la aplicación de acuerdo con el tema y el dominio del tema del almacén de datos.
Durante el proceso de desarrollo específico, los desarrolladores a menudo deben encontrar que algunos pasos de ETL no coinciden con las descripciones de la tabla después del modelado del almacén de datos. En este momento, es necesario volver a verificar, diseñar los requisitos y volver a hacer ETL. Como se menciona en este artículo de la serie de bases de datos, cualquier cambio que involucre requisitos debe comenzar desde cero y actualizar los documentos de requisitos.
2. Transformar
El paso de conversión se refiere principalmente al proceso de convertir la estructura de datos extraídos para cumplir con el modelo de almacenamiento de datos de destino. Además, el proceso de transformación también es responsable del trabajo de calidad de los datos, esta parte también se conoce como limpieza de datos (data cleaning).
3. Carga
El proceso de carga carga los datos extraídos y convertidos con calidad de datos garantizada en el almacén de datos de destino. La carga se puede dividir en dos tipos: primera carga (primera carga) y carga de actualización (carga de actualización). Entre ellos, la primera carga implica una gran cantidad de datos, mientras que la carga de actualización es una carga de microlotes.
Una cosa más, ahora con el surgimiento de varias herramientas distribuidas y de computación en la nube, ETL se ha convertido en realidad en ELT. Es decir, el sistema empresarial en sí mismo no realiza el trabajo de conversión, sino que importa los datos a la plataforma distribuida después de una simple limpieza, de modo que la plataforma pueda realizar el trabajo de limpieza y conversión de manera unificada. Si lo hace, puede hacer un uso completo de la naturaleza distribuida de la plataforma, al tiempo que hace que el sistema comercial se centre más en el negocio en sí.
Herramientas OLAP/BI
Una vez construido el almacén de datos, los usuarios pueden escribir sentencias SQL para acceder a él y analizar los datos que contiene. Sin embargo, sería demasiado problemático escribir sentencias SQL para cada consulta, y las rutinas de código SQL para analizar datos de modelado dimensional son relativamente fijas. Por lo tanto, existe una herramienta OLAP, que se dedica al análisis de datos de modelado dimensional. La herramienta de BI puede mostrar los resultados de OLAP en forma gráfica, y generalmente aparece junto con OLAP. (Nota: las herramientas OLAP a las que se hace referencia en este artículo se refieren a ambas).
La relación entre las herramientas OLAP y los almacenes de datos en los almacenes de datos normalizados es aproximadamente la siguiente:
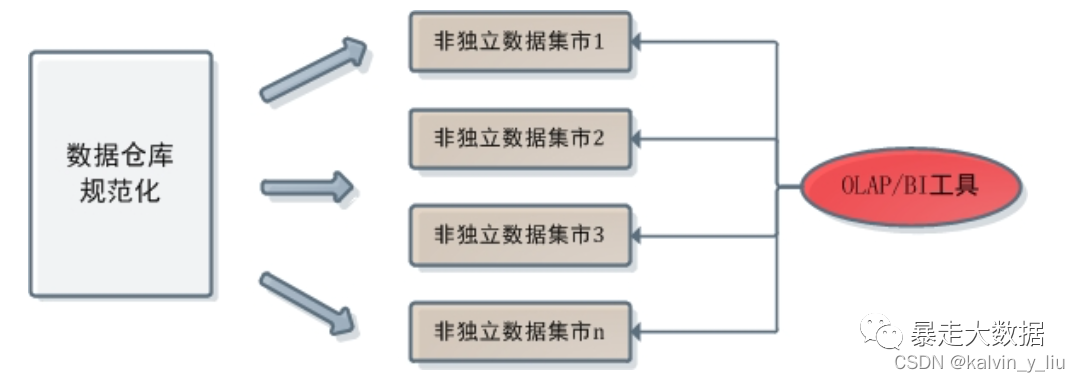
En este caso, OLAP no permite el acceso a la base de datos central. Por un lado, la base de datos central adopta el modelado estandarizado, mientras que OLAP solo admite el análisis de datos de modelado dimensional; por otro lado, la base de datos central del almacén de datos estandarizado en sí no permite que los desarrolladores de nivel superior accedan a ella. En el almacén de datos de modelado dimensional, la relación entre las herramientas OLAP/BI y el almacén de datos es la siguiente:
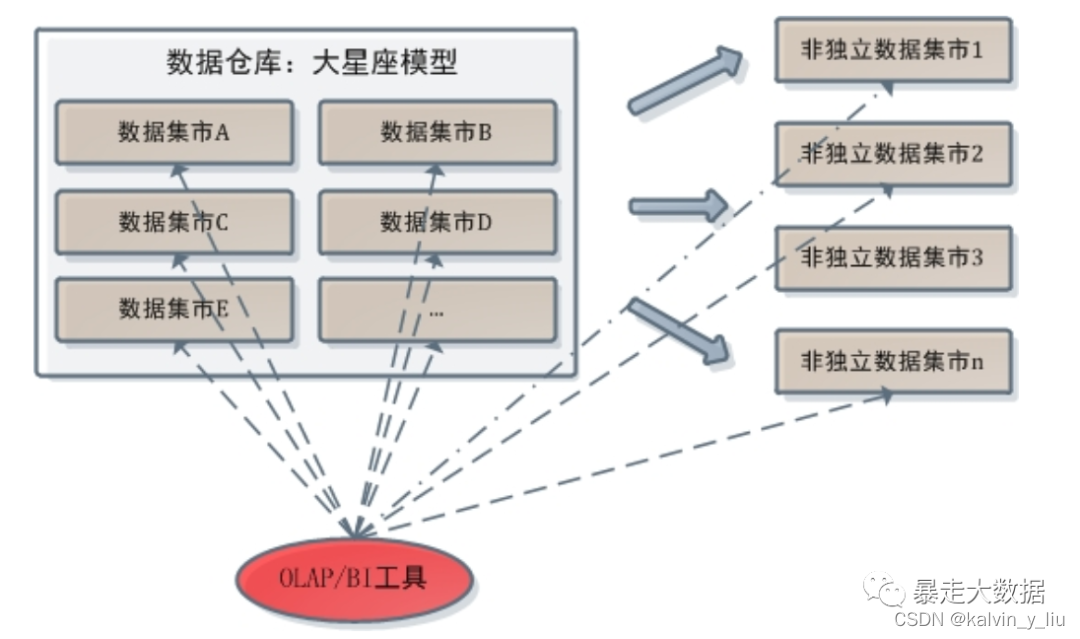
2.3 Caso de consulta
#Sample 1 维度表查询:
SELECT TOP (10) [DateKey] '日期Key'
,[FullDateAlternateKey] '日期代理key'
,[DayNumberOfWeek] '周所在日'
,[EnglishDayNameOfWeek] '所在周'
,[DayNumberOfMonth] '月所在日'
,[DayNumberOfYear] '年所在日'
,[WeekNumberOfYear] '年所在周'
,[EnglishMonthName] '英文月名'
,[MonthNumberOfYear] '年所在月'
,[CalendarQuarter] '所在季度'
,[CalendarYear] '日历年'
,[FiscalQuarter] '财季度'
,[FiscalYear] '财年'
FROM [AdventureWorksDW2019].[dbo].[DimDate]
ORDER BY DateKey DESC
#Sample 2 事实表查询
# 查看2013财年网上销售的产品名、汇率名、订单日期、用户信息、销售额、总产品成本、打折量等。
SELECT TOP 10、 B.EnglishProductName,C.CurrencyName CurrencyName,
D.FrenchPromotionName FrenchPromotionName,E.FirstName,E.LastName,
A.Salesamount,A.TaxAmt,A.TotalProductCost,A.DiscountAmount
FROM FactInternetSales A
JOIN DimProduct B
ON A.ProductKey = B.ProductKey
JOIN DimCurrency C
ON A.CurrencyKey = C.CurrencyKey
JOIN DimPromotion D
ON A.PromotionKey = D.PromotionKey
JOIN DimCustomer E
ON A.CustomerKey = E.CustomerKey
JOIN DimDate F
ON A.OrderDateKey =F.DateKey
WHERE F.FiscalYear=2013
——————————————————
0 Términos y restricciones
-
Extracción-Transformación-Carga es el proceso de extracción, transformación y carga de datos OLTP (en adelante, ETL)
-
Las descripciones de los documentos están todas de acuerdo con ETL→DW→CUBE→presentation
1 ETL relacionado
1.1 Tabla de dimensiones
1.1.1 Dimensión temporal
-
Explicación: Esta dimensión registra la hora de cada día, la mayor granularidad es el día, y se puede dividir en semanas, meses, años y otras granularidades.
-
Tabla correspondiente: tbl_dimdate
-
Proceso correspondiente: pro_supportdw_dimdate
-
Si es público: sí
-
Nota: La jerarquía (capa) se puede construir en esta dimensión, como se muestra en la siguiente figura:
1.1.2 Dimensiones del equipo
-
Descripción: Esta dimensión registra la información del equipo, se puede dividir en marcas, modelos y otras granularidades.
-
Tabla de correspondencia: tbl_dimdevice
-
Proceso correspondiente: pro_supportdw_dimdevice
-
Si es público: no
-
Nota: La jerarquía (capa) se puede construir en esta dimensión, como se muestra en la siguiente figura:
1.1.3 Dimensión regional
-
Descripción: Esta dimensión registra la información geográfica, se puede dividir en países, provincias, distritos y otras granularidades.
-
Tabla de correspondencia: tbl_dimgeography
-
Proceso correspondiente: Ninguno, agregue manualmente los datos de la región si es necesario
-
Si es público: no
-
Explicación: No hay Jerarquía (capa) en esta dimensión, vea la figura a continuación:
1.1.4 Dimensión de resolución
-
Descripción: Esta dimensión registra la información de resolución.
-
Tabla de correspondencia: tbl_dimsolution
-
Proceso correspondiente: pro_supportdw_dimsolution
-
Si es público: no
-
Descripción: No hay Jerarquía (capa) en esta dimensión, solo Nivel (nivel)
1.1.5 Dimensiones del sistema operativo
-
Descripción: Esta dimensión registra la información del sistema operativo.
-
Tabla de correspondencia: tbl_dimos
-
Proceso correspondiente: pro_supportdw_dimos
-
Si es público: no
-
Descripción: No hay Jerarquía (capa) en esta dimensión, solo Nivel (nivel)
1.1.6 Dimensión del tipo de red
-
Descripción: Esta dimensión registra la información del tipo de red.
-
Tabla de correspondencia: tbl_dimnetworktype
-
Proceso correspondiente: Ninguno, mantener manualmente los datos
-
Si es público: no
-
Descripción: No hay Jerarquía (capa) en esta dimensión, solo Nivel (nivel)
1.1.7 Dimensiones del Portador
-
Descripción: Esta dimensión registra la información del tipo de operador.
-
Tabla de correspondencia: tbl_dimoperator
-
Proceso correspondiente: Ninguno, mantener manualmente los datos
-
Si es público: no
-
Descripción: No hay Jerarquía (capa) en esta dimensión, solo Nivel (nivel)
1.1.8 Dimensiones del sistema
-
Descripción: Esta dimensión registra la información del sistema (similar a la información de mercado de proyecto [mercado], escritorio [LAU]).
-
Tabla de correspondencia: tbl_dimsystem
-
Proceso correspondiente: Ninguno, mantener manualmente los datos
-
Si es público: sí
-
Descripción: No hay Jerarquía (capa) en esta dimensión, solo Nivel (nivel)
1.1.9 Dimensiones del paquete
-
Descripción: Esta dimensión registra la información del paquete.
-
Tabla de correspondencia: tbl_cms_apk_package_ref
-
Proceso correspondiente: ninguno, mantener manualmente los datos, procedente de tbl_cms_apk_package (requiere sincronización de datos)
-
Si es público: sí
-
Descripción: No hay Jerarquía (capa) en esta dimensión, solo Nivel (nivel)
1.1.10 Dimensiones del fabricante
-
Descripción: Esta dimensión registra la información del fabricante.
-
Tabla correspondiente: tbl_user
-
Proceso correspondiente: no
-
Si es público: sí
-
Descripción: No hay Jerarquía (capa) en esta dimensión, solo Nivel (nivel)
1.1.11 Dimensiones de la versión del sistema
-
Descripción: Esta dimensión registra la información de la versión del sistema.
-
Tabla de correspondencia: tbl_dimappversion
-
Proceso correspondiente: pro_supportdw_dimappversion
-
Si es público: sí
-
Descripción: No hay Jerarquía (capa) en esta dimensión, solo Nivel (nivel)
1.1.12 Dimensiones de los recursos publicitarios
-
Descripción: esta dimensión registra información sobre recursos o anuncios.
-
Tabla correspondiente: tbl_dimresource
-
Proceso correspondiente: Ninguno, mantener manualmente los datos, procedente de tbl_resource (requiere sincronización de datos)
-
Es público: no, exclusivo del modelo de inventario
-
Descripción: No hay Jerarquía (capa) en esta dimensión, solo Nivel (nivel)
1.1.13 Dimensiones diferenciadoras de los recursos publicitarios
-
Descripción: Esta dimensión registra la información de distinción de recurso o publicidad.
-
Tabla de correspondencia: tbl_dimadres_type
-
Proceso correspondiente: Ninguno, mantener manualmente los datos
-
Es público: no, exclusivo del modelo de inventario
-
Descripción: No hay Jerarquía (capa) en esta dimensión, solo Nivel (nivel)
1.1.14 Dimensiones de los recursos publicitarios antiguos y nuevos
-
Descripción: Esta dimensión registra la información de distinción de recurso o publicidad.
-
Tabla de correspondencia: tbl_dimnewold
-
Proceso correspondiente: Ninguno, mantener manualmente los datos
-
Es público: no, exclusivo del modelo de inventario
-
Descripción: No hay Jerarquía (capa) en esta dimensión, solo Nivel (nivel)
1.1.15 Dimensión del tipo de sistema
-
Descripción: Esta dimensión registra la información del subtipo del sistema (similar al tipo airpush, tipo uubao)
-
Tabla de correspondencia: tbl_dimsystemtype
-
Proceso correspondiente: Ninguno, mantener manualmente los datos
-
Es público: no, exclusivo del modelo de inventario
-
Descripción: No hay Jerarquía (capa) en esta dimensión, solo Nivel (nivel)
1.1.16 Dimensión fuente del sistema
-
Descripción: Esta dimensión registra la información del tipo de fuente del sistema (la fuente es similar a los recursos publicitarios, editados manualmente)
-
Tabla de correspondencia: tbl_dimresourcetype
-
Proceso correspondiente: Ninguno, mantener manualmente los datos
-
Es público: no, exclusivo del modelo de inventario
-
Descripción: No hay Jerarquía (capa) en esta dimensión, solo Nivel (nivel)
1.2 Tabla de hechos y medida (medida)
1.2.1 Tabla de hechos del mercado y medida (medida)
1.2.1.1 Tabla de hechos del mercado
-
TBL_FACTMARKET Esta tabla es una tabla de hechos de mercado, que contiene indicadores como nuevas incorporaciones, usuarios independientes, tiempos de inicio, retención, etc. La dimensión es precisa para IMEI
-
TBL_FACTMARKET_FIN Esta tabla tiene una precisión de APK_ID
1.2.1.2 medida de mercado
-
Agregado: Estadísticas sobre el número de nuevos usuarios en el Mercado
-
Independiente: Estadísticas sobre el número de usuarios independientes del Mercado
-
Inicio: estadísticas de volumen de inicio del mercado
-
Los usuarios del mercado se retienen cada dos días, esto es posterior a la actualización
-
Almacenar usuarios en el mercado cada 7 días, esto es postActualización
-
Los usuarios del mercado se retienen cada 15 días, esto es posterior a la actualización
-
Los usuarios del mercado se retienen cada 21 días, esto es posterior a la actualización
-
Los usuarios del mercado se retienen cada 30 días, esto es posterior a la actualización
-
Tasa de retención semanal
-
tasa de retención mensual
1.2.2 Tabla de hechos y medidas de inventario
1.2.2.1 Tabla de hechos de inventario
-
TBL_FACTADRES Esta tabla es la tabla de hechos de recursos publicitarios, y los indicadores que contiene incluyen recepción, lectura, descarga, finalización de descarga, instalación, etc. La dimensión es exacta al IMEI
-
TBL_FACTADRES_FIN Esta tabla es la tabla de hechos de recursos publicitarios, que contiene indicadores como lectura, clic, descarga, descarga completa, instalación, etc. La dimensión es precisa para APK_ID
1.2.2.2 Medida de inventario de anuncios (métrica)
-
Recepción: estadísticas de volumen de recepción de recursos publicitarios
-
Volumen de visionado: estadísticas sobre el volumen de lectura de los recursos publicitarios
-
Descargas: Descargar estadísticas de inventario
-
Descargas completadas: las estadísticas de las descargas completadas de recursos publicitarios
-
Instalaciones: estadísticas de instalación para el inventario
1.3 ETL
1.3.1 Modelo de mercado
-
Pro_supportdw_factmarketmarket2.0 o superior extracción de tabla de hechos
-
Pro_support_oldfactmarketmarket1.2 versión extracción de tablas de hechos (incluido airpush)
-
Resumen de extracción de tabla de datos de Pro_supportdw_loadfactmarketmarket (agregado a la dimensión apk_id)
-
extracción de retención pro_supportdw_preservemarket2.0 (esto es PostUpdate)
1.3.2 Modelo de inventario
- pro_supportdw_factadres extracción de tabla de hechos de inventario
1.3.3 Modelo de proveedor
- pro_supportdw_loadaggrmarket Esta es la colección de modelos de mercado y modelos de recursos publicitarios, la dimensión es apk_id
1.4 Programación ETL
1.4.1 Trabajo de tabla de dimensiones
-
Proceso correspondiente al trabajo: pro_supportDW_Dim_jobs
-
El proceso de inclusión de tablas de dimensiones es el siguiente:
pro_supportdw_dimdevice(sysdate);–dimensión del dispositivo (modelo de marca de diseño)
pro_supportdw_dimos(sysdate); --Dimensión del sistema operativo
pro_supportdw_dimsolution(SYSDATE); – dimensión de resolución
pro_new_user_install(SYSDATE); --Información de usuario nuevo, utilizada por AdRes para comparar usuarios nuevos y antiguos
pro_supportdw_dimresource; ---- actualización de datos de dimensiones de anuncios recientemente agregada
1.4.2 Trabajo de tabla de hechos
1.4.2.1 mercado laboral
-
Proceso correspondiente a Market Job: PRO_Support_Market_JOBs
-
El proceso de inclusión de la tabla de hechos es el siguiente:
pro_supportdw_factmarket
pro_support_oldfactmarket
pro_supportdw_loadfactmarket
1.4.2.2 Trabajo de inventario de anuncios
- Este trabajo está incluido en el trabajo del proveedor.
1.4.2.3 Trabajo del fabricante
-
Proceso correspondiente al trabajo del fabricante: pro_support_adres_agg_jobs
-
El proceso de inclusión de la tabla de hechos es el siguiente:
pro_supportdw_factadres
pro_supportdw_loadaggrmercado
2 Cubo relacionado
2.1 Cubo介绍
2.1.1 cubo说明
Un OLAPcube es una matriz de datos entendidos en términos de sus 0 o más dimensiones.
Cubo es una abreviatura de modelo de datos multidimensional.
2.1.1 Términos relacionados con Cube
1) Cube: Cube es el objeto principal en el procesamiento analítico en línea (OLAP), y es una tecnología que puede acceder rápidamente a los datos en el almacén de datos. Cube es una colección de datos, generalmente construida a partir de un subconjunto del almacén de datos, organizado y resumido en una estructura multidimensional definida por un conjunto de dimensiones y medidas.
2) Dimensiones: son las características estructurales de los cubos. Son jerarquías organizadas (niveles) de clasificaciones utilizadas para describir datos en tablas de hechos. Estas clasificaciones y niveles describen algunas colecciones similares de miembros que los usuarios basarán en este conjunto de miembros para el análisis.
3. Medidas: En un cubo, una medida es un conjunto de valores que se basan en una columna en la tabla de hechos del cubo y generalmente es numérica. Además, una medida es el valor central del cubo que se analiza. Es decir, el valor de la medida son los datos numéricos en los que se centra el usuario final cuando navega por el cubo. El valor de la medida que elija depende del tipo de información que solicite el usuario final. Algunos valores de medida comunes son las ventas, los costos, los gastos y el recuento de producción. , etc .
4) Metadatos: el modelo estructural de datos y aplicaciones en diferentes componentes OLAP. Los metadatos describen objetos como tablas en bases de datos OLTP, almacenes de datos y cubos en data marts, y también registran qué aplicaciones se refieren a diferentes bloques de registro.
5) Nivel: Un nivel es un elemento de una jerarquía de dimensiones. Los niveles describen la jerarquía de datos, desde el nivel de datos más alto (el más resumido) hasta el nivel más bajo (el más detallado).
6) Minería de datos: la minería de datos le permite definir modelos que incluyen agrupación y reglas predictivas para aplicar a datos en bases de datos relacionales o conjuntos de datos OLAP multidimensionales. Estos modelos predictivos luego se pueden usar para automatizar análisis de datos complejos para descubrir tendencias que ayuden a identificar nuevos oportunidades y seleccionar las ganadoras.
7) Multidimensional: OLAP (MOLAP): El modo de almacenamiento MOLAP permite que la agregación de particiones y una copia de sus datos de origen se almacenen en la computadora del servidor de análisis en una estructura multidimensional.De acuerdo con el porcentaje y el diseño de la agregación de particiones, el El modo de almacenamiento MOLAP es para la respuesta de consulta más rápida El tiempo ofrece potencial En general, MOLAP es más adecuado para particiones en cubos que se usan con frecuencia y necesitan una respuesta de consulta rápida.
8) Relacional: OLAP (ROLAP): El modo de almacenamiento ROLAP permite que la agregación de particiones se almacene en la tabla de la base de datos relacional (especificada en la fuente de datos de la partición). Sin embargo, el modo de almacenamiento ROLAP se puede usar para datos particionados sin creando agregados en la base de datos relacional.
9) Híbrido: OLAP (HOLAP): El modo de almacenamiento HOLAP combina las características de MOLAP y ROLAP.
10) Granularidad: El nivel o profundidad de agregación de datos.
11) Agregación | Agregación: la agregación es un resumen de datos precalculados, que puede mejorar el tiempo de respuesta de las consultas porque la respuesta se prepara antes de que se formule la pregunta.
12) Bloque de corte: los datos de partición definidos por varios miembros de varias dimensiones se denominan bloque de corte.
13) Segmentación: los datos de partición definidos por un miembro de una dimensión se denominan división.
14) Exploración de datos: el usuario final selecciona una sola unidad de un cubo normal, un cubo virtual o un cubo vinculado, y recupera un conjunto de resultados de los datos de origen de la unidad para obtener información más detallada.Este proceso de operación son los datos Perforar.
Observaciones: Mondrian está basado en ROLAP
—————————————————
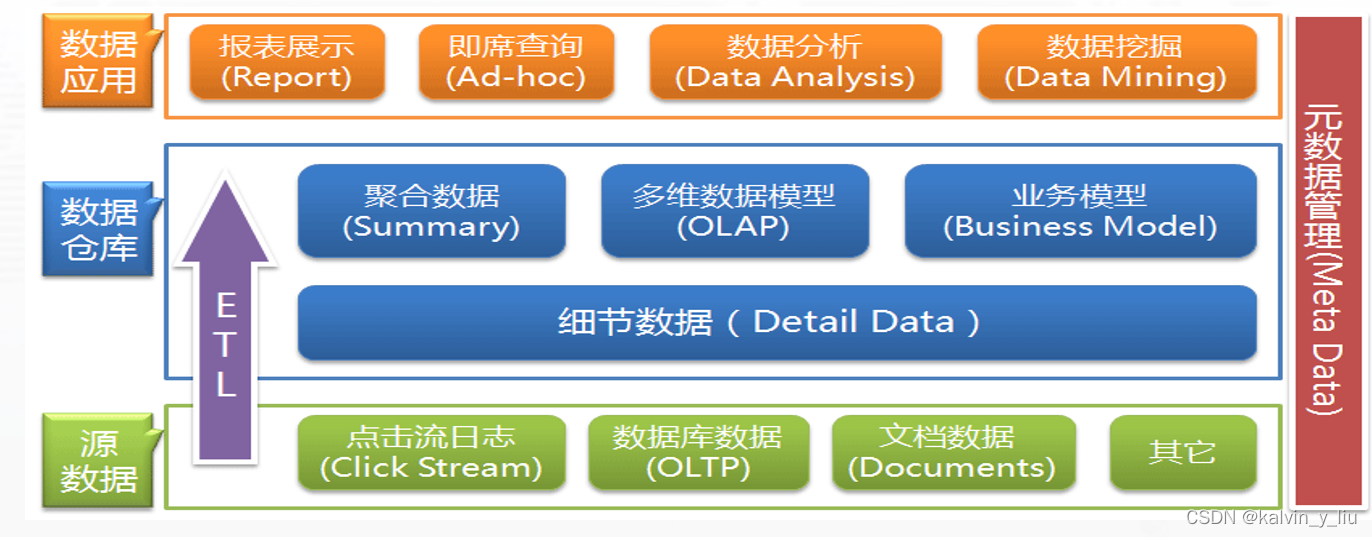
Jerarquía de la estructura del almacén de datos
Almacenamiento de datos y minería de datos: operaciones de datos multidimensionales
Cubo de datos
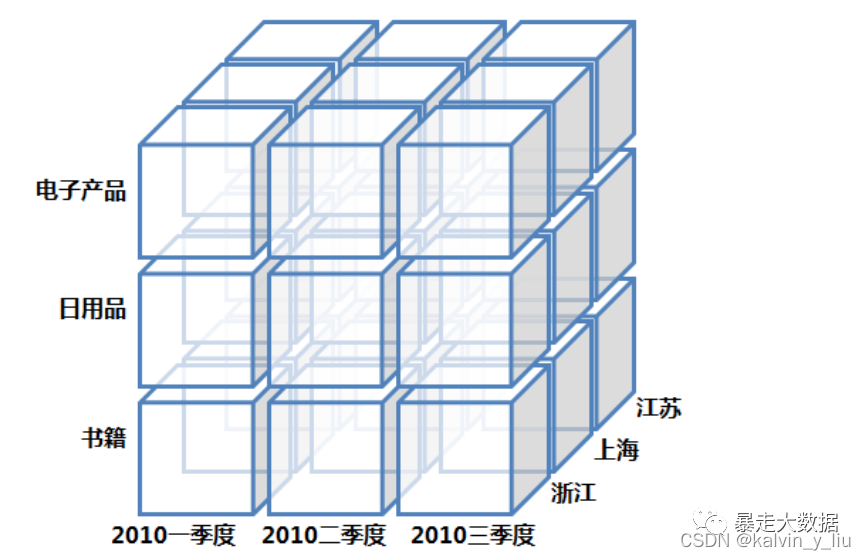
Antes de introducir el uso específico de las herramientas OLAP, primero debemos entender este concepto: Cubo de datos.
Hace muchos años, cuando teníamos que extraer información manualmente de una pila de datos, analizábamos una pila de informes de datos. Por lo general, estos informes de datos se presentan en dos dimensiones, una tabla bidimensional de filas y columnas. Sin embargo, en el mundo real, podemos analizar datos desde múltiples perspectivas.Un cubo de datos puede entenderse como una tabla bidimensional con dimensiones expandidas.
La siguiente figura muestra un cubo de datos tridimensional:
Aunque este ejemplo es tridimensional, más a menudo el cubo de datos es N-dimensional. Se implementa de dos maneras, que se discutirán más adelante en este artículo. El esquema estrella mencionado en el artículo anterior es uno de ellos, este esquema es en realidad un puente que conecta tablas relacionales y cubos de datos. Pero para la mayoría de los usuarios de OLAP puro, el objeto del análisis de datos es el cubo de datos en este concepto lógico, y no hay necesidad de profundizar en su implementación específica. Para los usuarios de estas herramientas OLAP, el uso básico es configurar primero las tablas de dimensiones y las tablas de hechos, y luego decirle a OLAP las dimensiones y los campos de hechos y los tipos de operaciones que se mostrarán en cada consulta.
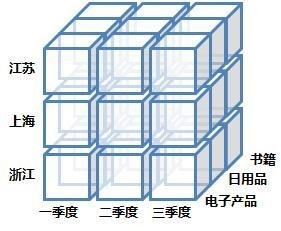
Las cinco operaciones más comunes en los cubos de datos se presentan a continuación: rebanar, cortar en cubitos, rotar, enrollar y desglosar.
Las operaciones en el cubo de datos son: cortar, cortar en cubitos, rotar, enrollar y profundizar.
El cubo de datos se ve así:
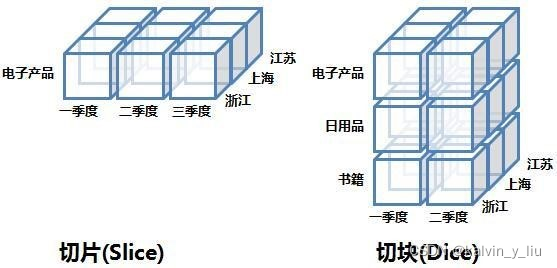
Rebanar y dividir (Slice and Dice)
La operación de seleccionar un miembro de dimensión en una determinada dimensión del cubo de datos se denomina rebanar, y la selección de dos o más dimensiones se denomina rebanar.
La siguiente figura muestra lógicamente las operaciones de rebanado y troceado:
las sentencias de simulación SQL de estas dos operaciones son las siguientes, principalmente trabajando en la sentencia WHERE.
# 切片
SELECT Locates.地区, Products.分类, SUM(数量)
FROM Sales, Dates, Products, Locates
WHERE Dates.季度 = 2
AND Sales.Date_key = Dates.Date_key
AND Sales.Locate_key = Locates.Locate_key
AND Sales.Product_key = Products.Product_key
GROUP BY Locates.地区, Products.分类
# 切块
SELECT Locates.地区, Products.分类, SUM(数量)
FROM Sales, Dates, Products, Locates
WHERE (Dates.季度 = 2 OR Dates.季度 = 3) AND (Locates.地区 = '江苏' OR Locates.地区 = '上海')
AND Sales.Date_key = Dates.Date_key
AND Sales.Locate_key = Locates.Locate_key
AND Sales.Product_key = Products.Product_key
GROUP BY Dates.季度, Locates.地区, Products.分类
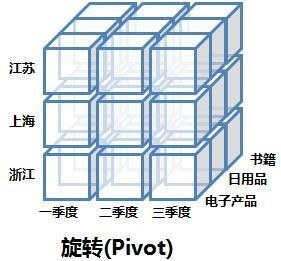
Pivote Pivote
se refiere a cambiar la dirección de visualización de un informe o página. Para el usuario, es una operación de vista, pero desde la perspectiva de la declaración de simulación SQL, es solo para cambiar el orden de los campos detrás de SELECT. La siguiente figura muestra lógicamente la operación de rotación:
Roll-up y Drill-down (Rol-up and Drill-down)
El roll-up puede entenderse como "ignorar" ciertas dimensiones, el drill-down se refiere a la subdivisión de ciertas dimensiones. La siguiente figura muestra lógicamente las operaciones de roll-up y drill-down:
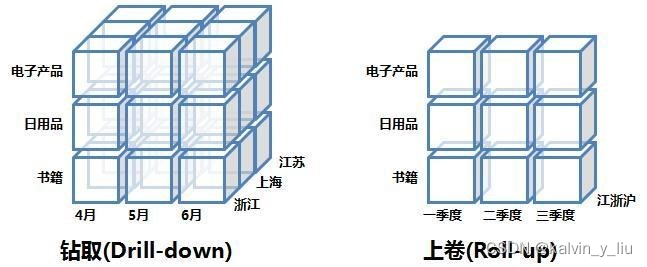
Las sentencias de simulación SQL de estas dos operaciones son las siguientes, trabajando principalmente en la sentencia GROUP BY.
# 上卷
SELECT Locates.地区, Products.分类, SUM(数量)
FROM Sales, Products, Locates
WHERE Sales.Locate_key = Locates.Locate_key
AND Sales.Product_key = Products.Product_key
GROUP BY Locates.地区, Products.分类
# 下钻
SELECT Locates.地区, Dates.季度, Products.分类, SUM(数量)
FROM Sales, Dates, Products, Locates
WHERE Sales.Date_key = Dates.Date_key
AND Sales.Locate_key = Locates.Locate_key
AND Sales.Product_key = Products.Product_key
GROUP BY Dates.季度.月份, Locates.地区, Products.分类
4. Otras operaciones OLAP
Además de las operaciones básicas mencionadas anteriormente, diferentes herramientas OLAP también brindan sus propias funciones de consulta OLAP, como profundizar, profundizar, etc. Este artículo no las explicará una por una. Por lo general, una consulta OLAP compleja es el resultado de la superposición de varias operaciones OLAP de este tipo.
Modelo arquitectónico OLAP
1. MOLAP (Procesamiento analítico en línea multidimensional)
La arquitectura MOLAP genera un nuevo cubo, o un cubo de datos real, por así decirlo. Su estructura se muestra en la siguiente figura:
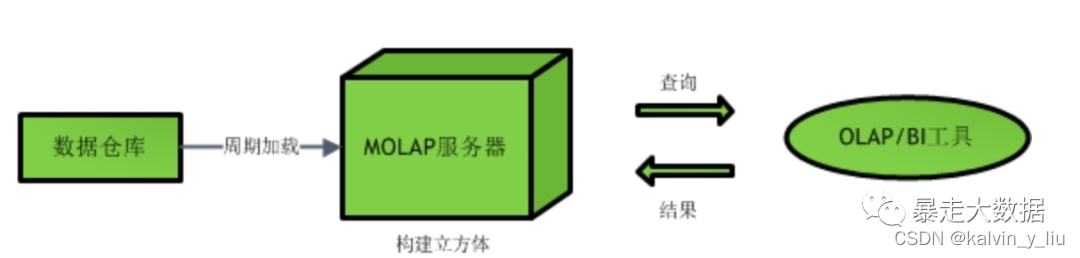
En el cubo, cada celda corresponde a una dirección directa y las consultas de uso frecuente se calculan previamente. Por lo tanto, cada consulta es muy rápida, pero debido a que la actualización del cubo es relativamente lenta, es necesario analizar en detalle si se debe usar esta arquitectura.
2. ROLAP (procesamiento analítico relacional en línea)
El esquema ROLAP no genera cubos reales, sino que simula un cubo de datos mediante un esquema en estrella con varias tablas relacionales. Su estructura se muestra en la siguiente figura:
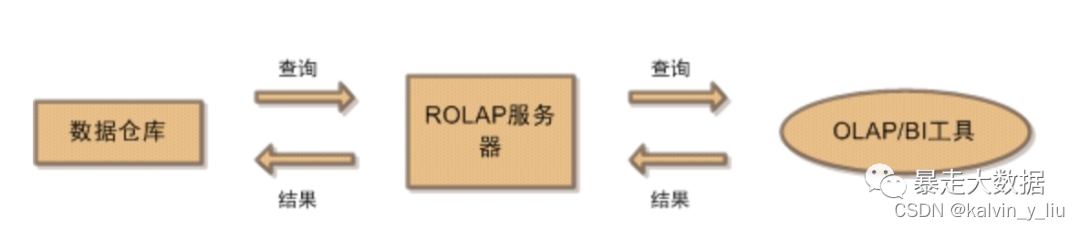
Obviamente, las consultas bajo esta arquitectura no son tan rápidas como MOLAP. Porque en ROLAP, todas las consultas se convierten en sentencias SQL para su ejecución. La ejecución de estas instrucciones SQL implicará operaciones JOIN entre varias tablas, lo que no es tan rápido como MOLAP.
3. HOLAP (procesamiento analítico en línea híbrido)
Esta arquitectura adopta una solución híbrida con referencia integral a MOLAP y ROLAP, colocando algunas consultas que necesitan una aceleración especial en el motor MOLAP y otras consultas llaman al motor ROLAP.
El autor encontró un fenómeno interesante. El desarrollo de muchas herramientas satisface esta regla: la herramienta A se crea y sus deficiencias se encuentran después de que se pone en uso; luego, la herramienta B se crea para compensar esta deficiencia, pero trae nuevas deficiencias; entonces se utilizará la herramienta C creada para llamar a A y B según diferentes situaciones. relativamente sin palabras...
Resumen
El desarrollo de todo el sistema de almacenamiento de datos involucrará a varios equipos: equipo de modelado de datos, equipo de análisis comercial, equipo de arquitectura del sistema, equipo de mantenimiento de la plataforma, equipo de desarrollo front-end, etc. Para aquellos que están decididos a trabajar en este campo, todavía hay mucho que aprender. Pero para aquellos que quieren ser un excelente "científico de datos" como el autor, estos conceptos básicos de datos son suficientes. En opinión del autor, las principales ventajas competitivas de los científicos de datos se encuentran en tres aspectos: base de datos, visualización de datos y modelo de algoritmo. Estos tres aspectos requieren un tiempo y un coste cada vez mayores, mientras que la importancia del conocimiento va disminuyendo. Por lo tanto, la serie de bases de datos y la serie de almacenes de datos son las dos series más rentables.
Requisitos de trabajo:
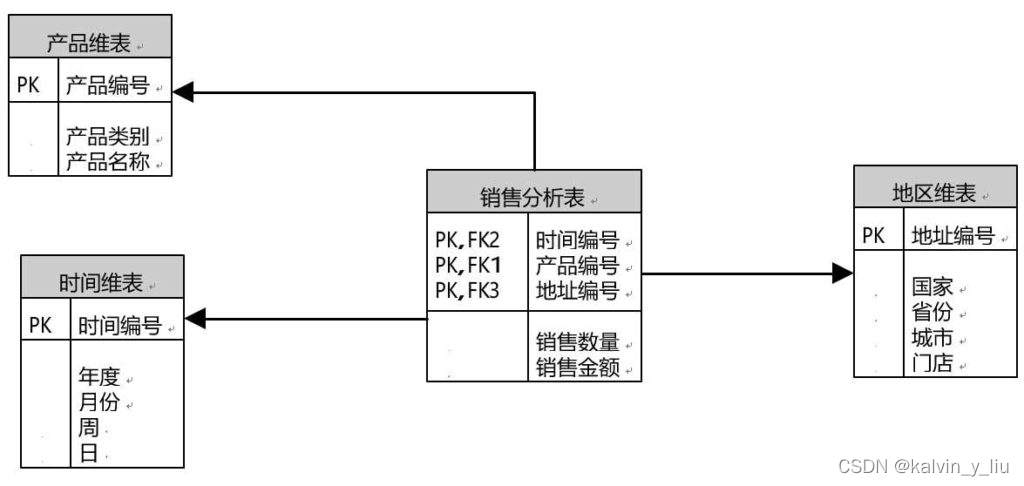
- Cree una base de datos en SQL SERVER 2012, que contiene cuatro tablas. El diseño de la tabla de referencia se muestra en la siguiente figura.
- Luego corte, corte en dados, gire, enrolle y profundice en función de las tablas de la base de datos anterior.
- Cuatro mesas de construcción propia y operaciones multidimensionales (rebanado, corte en cubitos, rotación, enrollado y desglose) realizadas en las mesas.
Cree una estructura de tabla e inserte datos simulados.
Estos datos se exportan desde la base de datos de la versión SQL Server 2012, solo como referencia y referencia.
**1 销售分析表结构**
/****** Object: Table [dbo].[analysisTable] Script Date: 2019/3/11 15:33:52 ******/
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[analysisTable](
[timeID] [tinyint] NOT NULL,
[productID] [tinyint] NOT NULL,
[areaID] [tinyint] NOT NULL,
[number] [int] NOT NULL,
[money] [int] NOT NULL ) ON [PRIMARY] GO
地区维表表结构
CREATE TABLE [dbo].[areaTable](
[areaID] [tinyint] IDENTITY(1,1) NOT NULL,
[areaCou] [varchar](200) NOT NULL,
[areaPro] [varchar](50) NOT NULL,
[areaCity] [varchar](50) NOT NULL,
[areaDoor] [varchar](200) NOT NULL,
CONSTRAINT [PK_areaTable] PRIMARY KEY CLUSTERED
(
[areaID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
产品维表表结构
CREATE TABLE [dbo].[productTable](
[productID] [tinyint] IDENTITY(1,1) NOT NULL,
[productType] [nvarchar](50) NOT NULL,
[productName] [nvarchar](50) NOT NULL,
CONSTRAINT [PK_productTable] PRIMARY KEY CLUSTERED
(
[productID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
时间维表表结构
CREATE TABLE [dbo].[timeTable](
[timeID] [tinyint] IDENTITY(1,1) NOT NULL,
[timeYear] [varchar](50) NOT NULL,
[timeMonth] [varchar](50) NOT NULL,
CONSTRAINT [PK_timeTable] PRIMARY KEY CLUSTERED
(
[timeID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
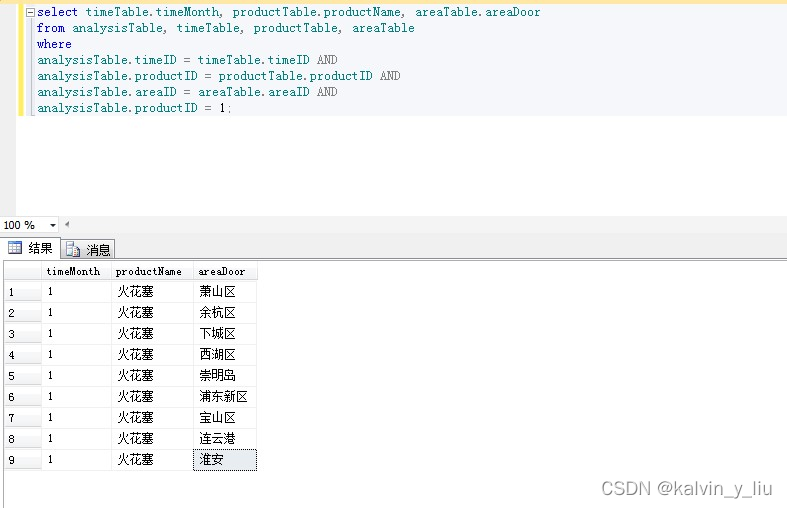
Operación de datos multidimensionales
Operación de división
Operación Sentencia SQL
select timeTable.timeMonth, productTable.productName, areaTable.areaDoor
from analysisTable, timeTable, productTable, areaTable
where
analysisTable.timeID = timeTable.timeID AND
analysisTable.productID = productTable.productID AND
analysisTable.areaID = areaTable.areaID AND
analysisTable.productID = 1;
Gráfico de consulta de resultado de operación
Ir a matriz básica de lenguaje, división, mapa
En el lenguaje Go, para facilitar el almacenamiento y la gestión de los datos de los usuarios, el diseño de su estructura de datos se divide en tres estructuras: Array, Slice y Map.
Recientemente, leí el contenido de los conceptos básicos del lenguaje Go y observé los principios de la realización de estas tres estructuras:
Array Array
Array es la estructura de datos básica de corte y mapeo;
la matriz es un tipo de datos de longitud fija y se asigna continuamente en la memoria, y la velocidad de los datos
de la matriz de índice sólido es muy rápida; al declarar una matriz, debe especificar el tipo y cantidad de almacenamiento de matriz (La longitud de la matriz);
el tipo de la variable de matriz incluye la longitud de la matriz y el tipo del elemento, y solo las matrices con las mismas dos partes pueden asignar valores entre sí .
Creación e inicialización
Una vez que se declara una matriz, su tipo de datos y longitud no se pueden cambiar.
// declarar matriz matriz usando matriz literal
:= [5]int{1, 2, 3, 4, 5}
// Deduce automáticamente la declaración de longitud array
array := […]int{1, 2, 3, 4, 5, 6}
// Usa ... en lugar de length, deducida según el número de elementos inicializados
// Declarar una matriz y especificar una
matriz de valor de elemento específico := [5]int{1:10, 2:20} El tipo de elemento de matriz de tipo
puntero
puede ser cualquier tipo integrado, también puede ser un cierto tipo de estructura , o puede ser un tipo de puntero .
// Declarar una matriz de punteros a cadenas con una longitud de elemento de 3
var matriz1 [3]*cadena
// Especifique los elementos para la matriz de punteros
*matriz1[0] = "demo0"
*matriz1[1] = "demo1"
*matriz1[2] = "demo2" La matriz
multidimensional
en sí misma son datos unidimensionales, y la matriz multidimensional es compuesto por múltiples arreglos combinados.
// declara un arreglo bidimensional
var array = [3][2]int
// declara un arreglo bidimensional con los elementos 3 y 2
// Inicializar un arreglo bidimensional
var arreglo = [3][2]int{ {1, 2}, {3, 4}, {5, 6}}
Pasar arreglos entre funciones: al pasar variables entre funciones, pasar es siempre una copia del valor de la variable, por lo que pasar una variable de matriz copiará toda la matriz. Al definir una función, el parámetro debe diseñarse como un tipo de puntero para un tipo de datos más grande, de modo que cuando se llama a la función, solo se deben asignar 8 bytes de memoria para cada puntero en la pila, pero esto significa que el puntero apuntado será cambiado Los valores (memoria compartida), de hecho, los tipos de segmento deben usarse en la mayoría de los casos, no las matrices.
Slice
Slice slice es un tipo de referencia, que se refiere a una parte o la totalidad de la matriz subyacente a la que apunta su campo de puntero; la división
se basa en el concepto de matriz dinámica;
el crecimiento dinámico de la división se realiza mediante la adición;
la reducción se logra mediante It is implementado al cortar nuevamente. El nuevo segmento obtenido al dividir nuevamente compartirá la matriz subyacente con la división original, y sus punteros apuntarán a la misma matriz subyacente.
Creación e inicialización
El tipo de corte tiene 3 campos:
Puntero: apunta a la dirección del primer elemento contenido en el segmento en el arreglo subyacente;
Longitud: el número de elementos en el arreglo subyacente contenido en el segmento (el número de elementos accesibles al segmento);
Capacidad: el tamaño máximo que se permite que el segmento crezca hasta el número de elementos, que es la longitud de la matriz subyacente.
literales make y slice
// usa make para crear un
slice := make([]int, 3)
// crea un sector con longitud y capacidad
:= make([]int, 1, 6)
// longitud 1, capacidad 6 elementos
nil y sector vacío
// cadena nula sector
var segmento []cadena
// Sector vacío
sector := []int{}
// Sector entero vacío
porque el sector solo se refiere a la matriz subyacente, y los datos del conjunto subyacente no pertenecen al sector en sí, por lo que un sector solo necesita 24 bytes de memoria (en 64 bits en la máquina): el campo de puntero es de 8 bytes, el campo de longitud es de 8 bytes y el campo de capacidad es de 8 bytes. Por lo tanto, es eficiente pasar segmentos directamente entre funciones y solo necesita asignar 24 bytes de memoria de pila.
La función len puede devolver la longitud del segmento y la función cap puede devolver la capacidad del segmento.
Mapa de mapeo
El mapa de mapeo se utiliza para almacenar una serie de pares clave-valor desordenados;
el mapeo es una colección desordenada y su implementación usa una tabla hash;
la tabla hash mapeada contiene un conjunto de cubos, y cada cubo almacena una parte de la clave- pares de valores ;
Se utilizan dos matrices dentro del mapa:
la primera matriz: almacena el valor alto de ocho bits de la clave hash utilizada para seleccionar el depósito, que se utiliza para distinguir en qué depósito debe almacenarse cada par clave-valor; el segunda matriz
: hay una matriz de bytes en cada cubo, que primero almacena todas las claves en el cubo y luego almacena todos los valores en el cubo;
creación e inicialización
// crea un mapa para almacenar información de
los estudiantes estudiantes: = map[cadena]cadena { "nombre": "mengxiaoyu", "edad": "22", "sexo": "chico", "pasatiempo": "pingpang", }
// Muestra toda la información del mapeo
para clave, valor := rango estudiantes{ fmt.printf("clave:%s, \t valor:%s\n", clave, valor); } El orden al atravesar la clave- pares de valores del mapeo Es aleatorio.Si desea obtener los pares clave-valor del mapa de manera ordenada, necesita atravesar las claves mapeadas y almacenarlas en un segmento, luego ordenar el segmento y finalmente atravesar el slice, y obtener la correspondencia en el mapa según el orden de los elementos en el valor slice.