Directorio de artículos
Prefacio
La llamada clasificación es la operación de organizar una cadena de registros en orden creciente o decreciente según el tamaño de una o algunas palabras clave que contiene. Clasificar es muy común en nuestras vidas, como mirar el volumen de ventas, comparar precios, etc. a la hora de comprar algo. La clasificación también se divide en clasificación interna y clasificación externa . La clasificación interna es una clasificación en la que todos los elementos de datos se colocan en la memoria, y la clasificación externa es una clasificación en la que no se pueden almacenar demasiados elementos de datos en la memoria al mismo tiempo, y los datos no se pueden mover entre la memoria interna y externa de acuerdo con la requisitos del proceso de clasificación. Entendamos formalmente la clasificación.
1. Implementación de algoritmos de clasificación comunes
1. Ordenación por inserción
Inserte los registros a ordenar en una secuencia ordenada uno por uno según el tamaño de sus valores clave, hasta que se inserten todos los registros y se obtenga una nueva secuencia.
1. Clasificación por inserción directa
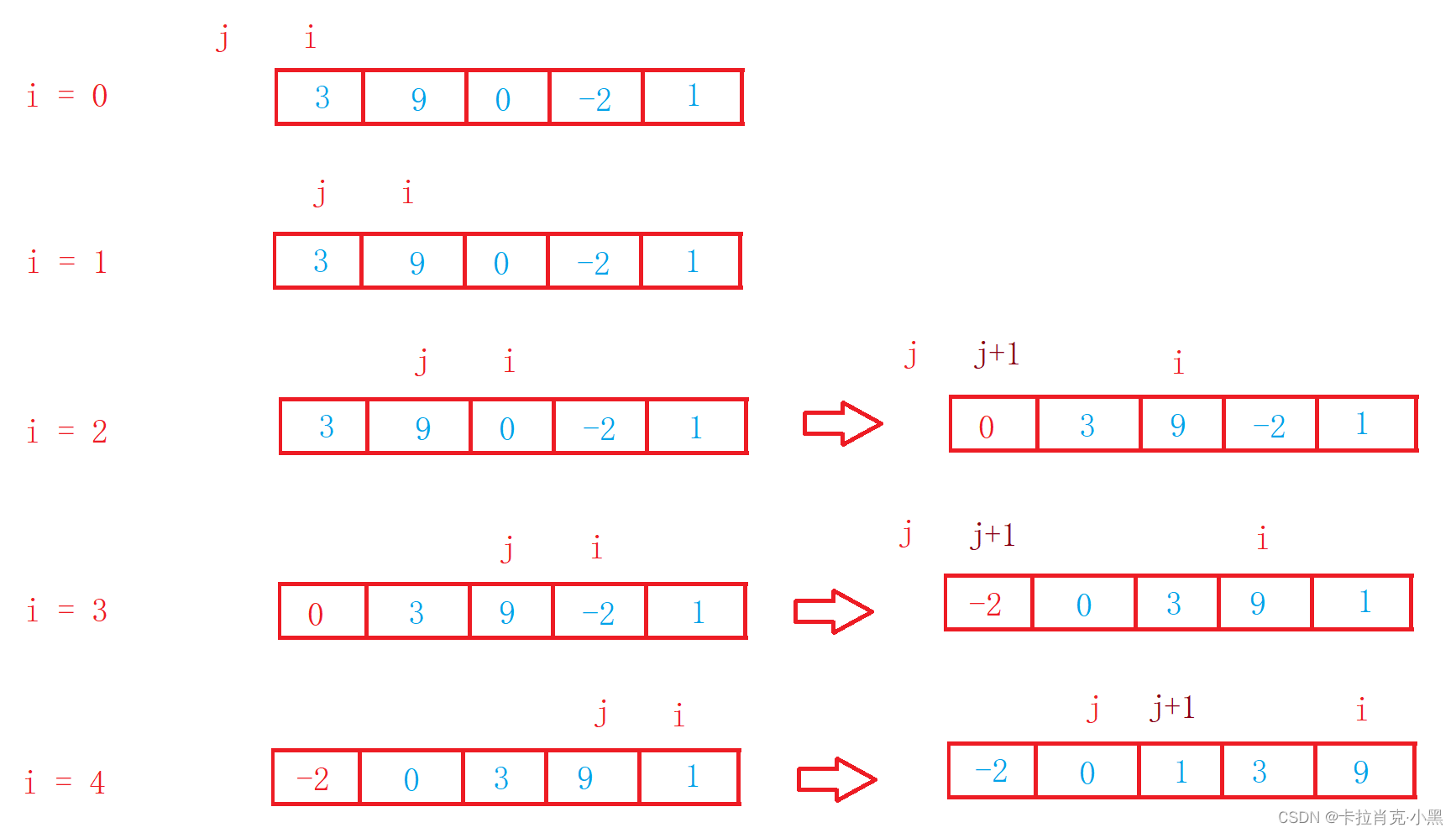
void InsertSort(int* nums, int numsSize)
{
int i = 0;
//i变量控制的是整个比较元素的数量
for (i = 0; i < numsSize; i++)
{
int num = nums[i];
//从后面一次和前面的元素进行比较,前面的元素大于后面的数据,则前面的元素向后移动
int j = i - 1;
while (j > -1)
{
if (nums[j] > num)
{
//要交换的元素小于前一个元素
nums[j + 1] = nums[j];
j--;
}
else
{
break;
}
}
//把该元素填到正确的位置
nums[j + 1] = num;
}
}
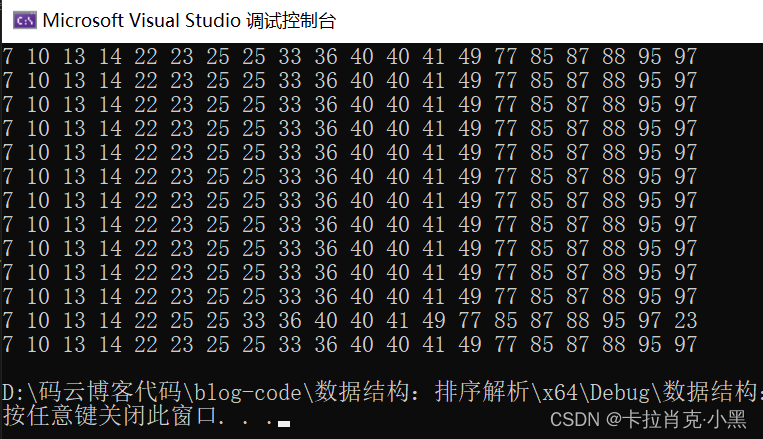
Caso de prueba:
void sortArray(int* nums, int numsSize)
{
InsertSort(nums, numsSize);//插入排序
}
void print(int* nums, int numsSize)
{
int i = 0;
for (i = 0; i < numsSize; i++)
{
printf("%d ", nums[i]);
}
}
int main()
{
int nums[] = {
3,9,0,-2,1 };
int numsSize = sizeof(nums) / sizeof(nums[0]);//计算数组大小
sortArray(nums, numsSize);//调用排序算法
print(nums, numsSize);//打印排序结果
return 0;
}

Ventajas de la ordenación por inserción directa: cuanto más cerca esté el conjunto de elementos del orden, mayor será la eficiencia temporal del algoritmo de ordenación por inserción directa.
Complejidad temporal: O (N ^ 2)
Complejidad espacial O (1)
La clasificación por inserción directa es un algoritmo de clasificación estable.
2. Clasificación de colinas
Divida la secuencia que se va a ordenar en varias subsecuencias, realice la clasificación por inserción en cada subsecuencia, ordene básicamente toda la secuencia y luego realice la clasificación por inserción en toda la secuencia. Es una mejora del tipo de inserción.
void ShellSort(int* nums, int numsSize)
{
int group = numsSize;
while (group > 1)
{
//进行分组
//加1为了保证最后一次分组为1,组后一次必须要进行正常的插入排序
group = group / 3 + 1;
int i = 0;
//每次对分的组进行排序
//和插入排序思路相同
for (i = 0; i < numsSize; i++)
{
int num = nums[i];
int j = i - group;
while (j >= 0)
{
if (nums[j] > num)
{
nums[j + group] = nums[j];
j -= group;
}
else
{
break;
}
}
nums[j + group] = num;
}
}
}
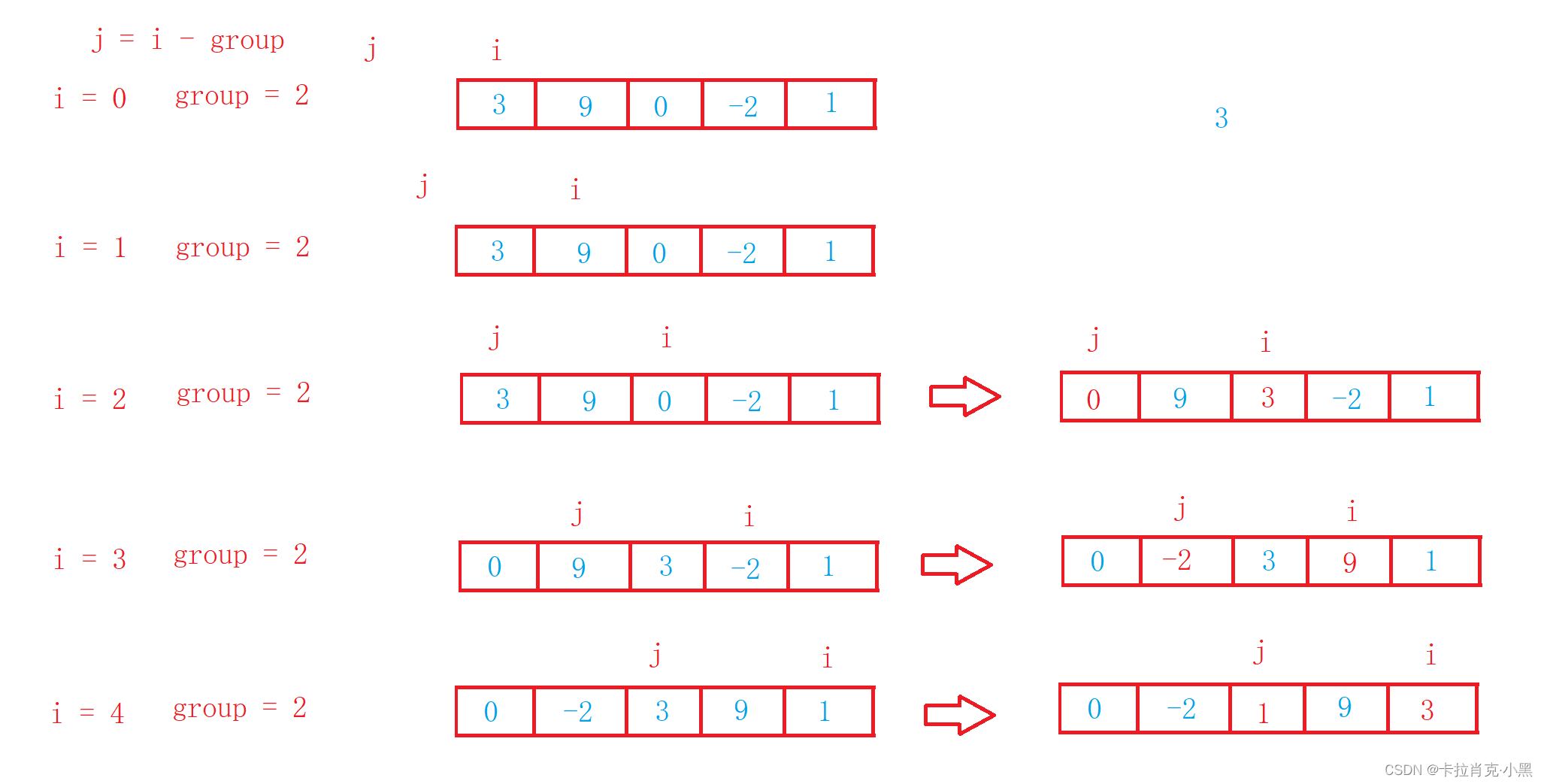
Cuando el grupo es 1, se trata de ordenación por inserción, se debe garantizar que el último grupo sea 1 para que la ordenación sea correcta. El método de clasificación en
colina es una optimización de la clasificación por inserción directa.
Será pronto. De esta manera, se pueden lograr resultados de optimización generales. Después de implementarlo, podemos comparar las pruebas de rendimiento.
Cuando el grupo> 1, está preordenado. El propósito es acercar la matriz al orden, de modo que los números grandes puedan llegar más rápido a la parte posterior y los números pequeños puedan llegar más rápido al frente. Cuando grupo = 1, la matriz ya está casi ordenada. En este momento, el uso de la inserción puede hacer que la complejidad temporal del ordenamiento por inserción se acerque a O (N). Para lograr el efecto de optimización. La complejidad temporal de la clasificación Hill es aproximadamente O (N ^ 1,3).
Caso de prueba:
void sortArray(int* nums, int numsSize)
{
//InsertSort(nums, numsSize);//插入排序
ShellSort(nums, numsSize);//希尔排序
}
int main()
{
int nums[] = {
3,9,0,-2,1 };
int numsSize = sizeof(nums) / sizeof(nums[0]);//计算数组大小
sortArray(nums, numsSize);//调用排序算法
print(nums, numsSize);//打印排序结果
return 0;
}

2. Intercambiar clasificación
1. Clasificación de burbujas
void BubbleSort(int* nums, int numsSize)
{
int i = 0;
//控制循环次数
for (i = 0; i < numsSize; i++)
{
int j = 0;
//用记录该数组是否有序可以提前退出循环
int flag = 0;
//用来控制比较次数
for (j = 0; j < numsSize - i - 1; j++)
{
if (nums[j + 1] < nums[j])
{
swap(&nums[j], &nums[j + 1]);
flag = 1;
}
}
//当该此循环不在进行交换则证明数组已经有序,可以提前退出循环
if (flag == 0)
{
break;
}
}
}
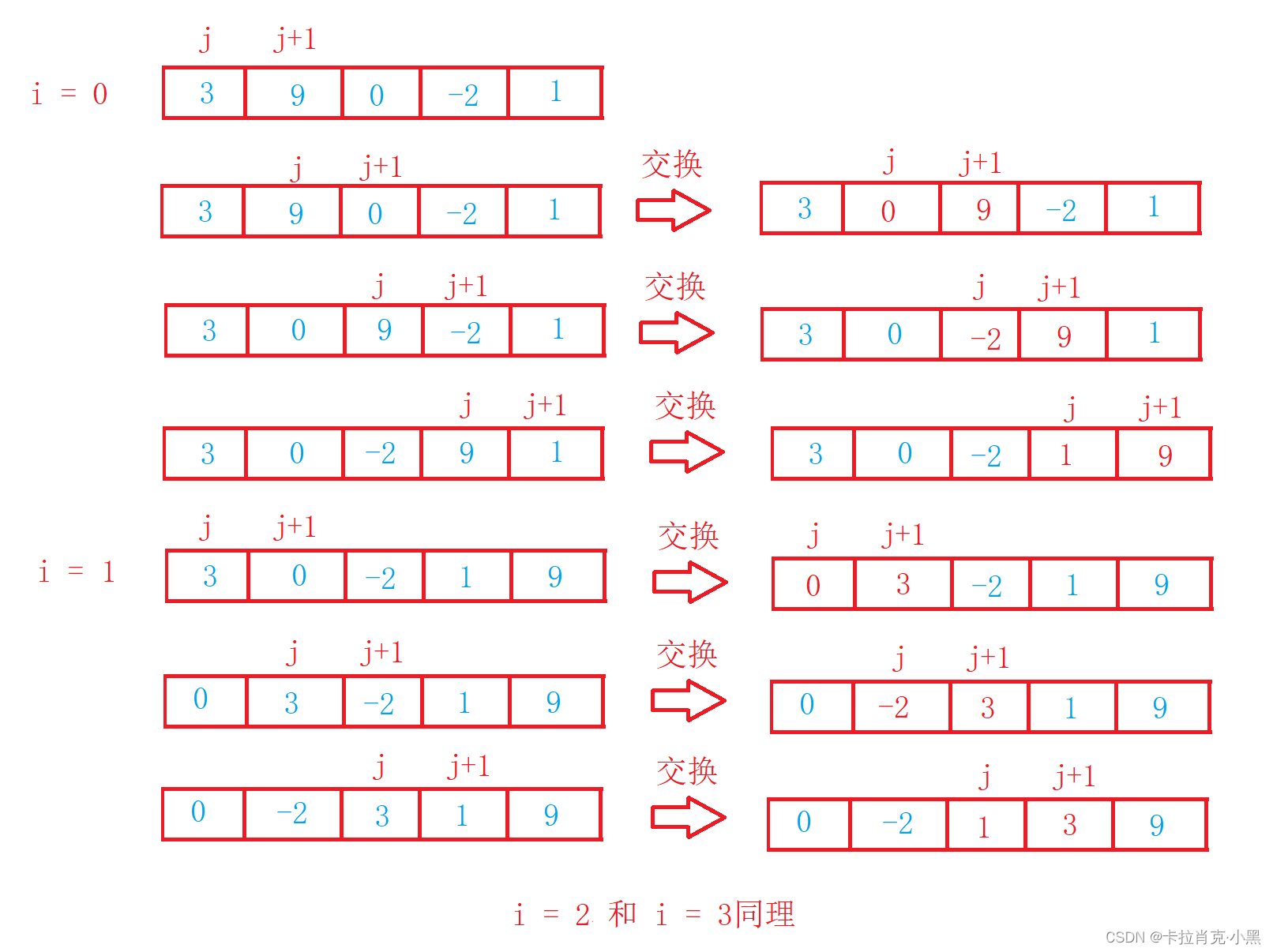
La clasificación de burbujas es muy fácil de entender, su complejidad temporal es O (N ^ 2), complejidad espacial: O (1) y muy estable.
2. Clasificación rápida
Tome cualquier elemento en la secuencia de elementos a ordenar como valor estándar, divida el conjunto a ordenar en dos segmentos de acuerdo con el código de clasificación, todos los elementos de la izquierda son menores que este valor, todos los elementos de la derecha son mayores que este valor, y luego repita el proceso en los lados izquierdo y derecho, hasta que todos los elementos estén dispuestos en las posiciones correspondientes.
1.versión ronca
void PartSort1(int* nums, int left, int right)
{
//当区间不存在或者区间只有一个数时结束递归
if (left >= right)
{
return ;
}
int key = left;
int begin = left;
int end = right;
while (begin < end)
{
//右边先走,目的是结束是相遇位置一定比key值小
//开始找比选定值小的元素
while ((begin < end) && (nums[key] <= nums[end]))
{
end--;
}
//开始找比选定值大的元素
while ((begin < end) && (nums[begin] <= nums[key]))
{
begin++;
}
//把两个数进行交换
swap(&nums[begin], &nums[end]);
}
//把关键值和相遇点的值进行交换,由于右边先走,相遇值一定小于关键值
swap(&nums[key], &nums[begin]);
key = begin;
//开始递归左边区间
PartSort1(nums, left, key - 1);
//开始递归右边区间
PartSort1(nums, key + 1, right);
}
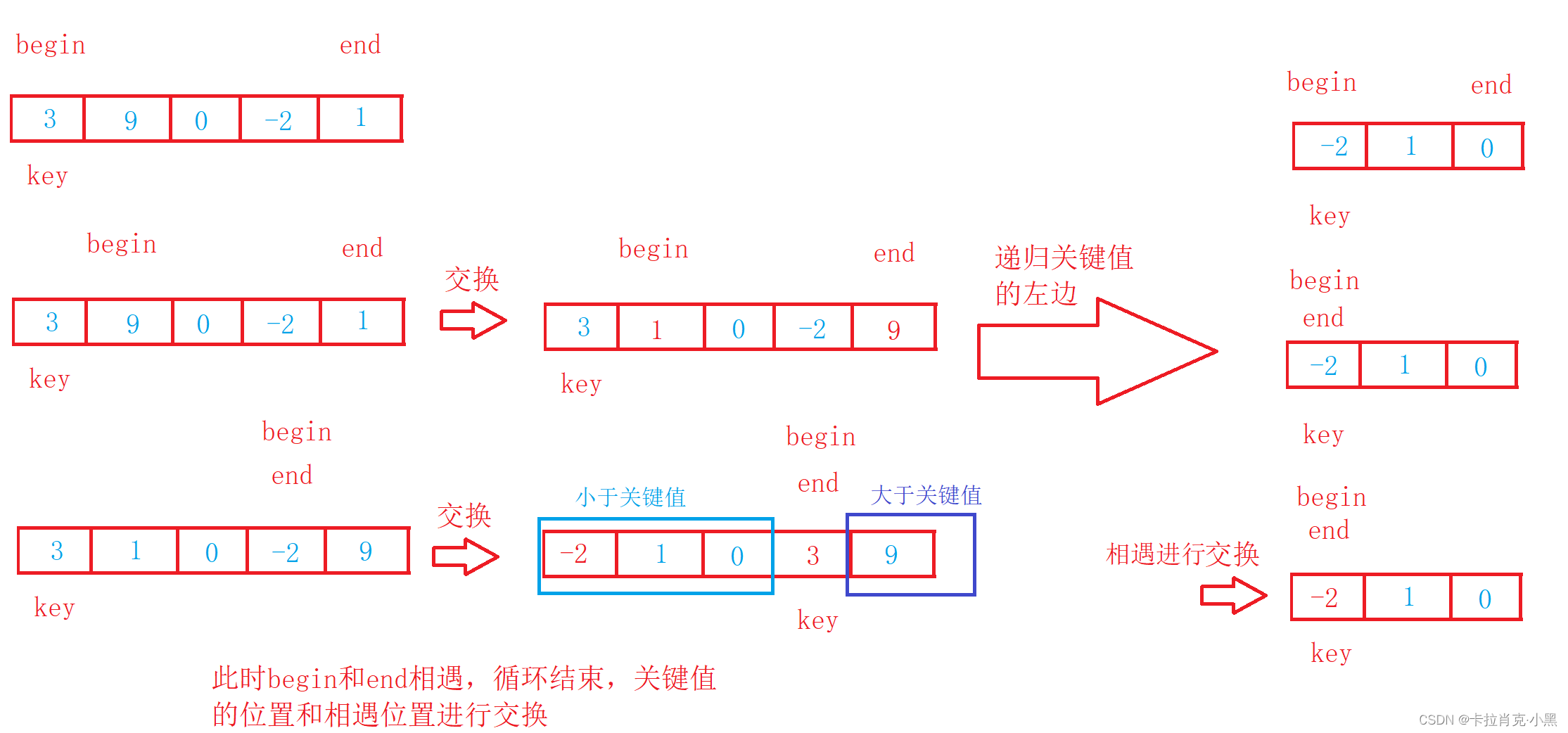
Recurra los intervalos izquierdo y derecho por separado hasta que la recursión se convierta en un intervalo indivisible. Es un algoritmo de divide y vencerás. Cada recursión devolverá un número a la posición correcta.
2. Versión de excavación
void PartSort2(int* nums, int left, int right)
{
if (left >= right)
{
return;
}
int hole = left;//坑的位置
int key = nums[left];//记录初始坑位置的值
int begin = left;
int end = right;
while (begin < end)
{
while ((begin < end) && (key <= nums[end]))
{
end--;
}
nums[hole] = nums[end];//把小于初始坑位置的填到坑中
hole = end;//更新坑的位置
while ((begin < end) && (nums[begin] <= key))
{
begin++;
}
nums[hole] = nums[begin];//把大于初始坑位置的填到坑中
hole = begin;//更新坑的位置
}
//坑的位置放置初始坑位置的值
nums[begin] = key;
//开始递归左边区间
PartSort2(nums, left, hole - 1);
//开始递归右边区间
PartSort2(nums, hole + 1, right);
}
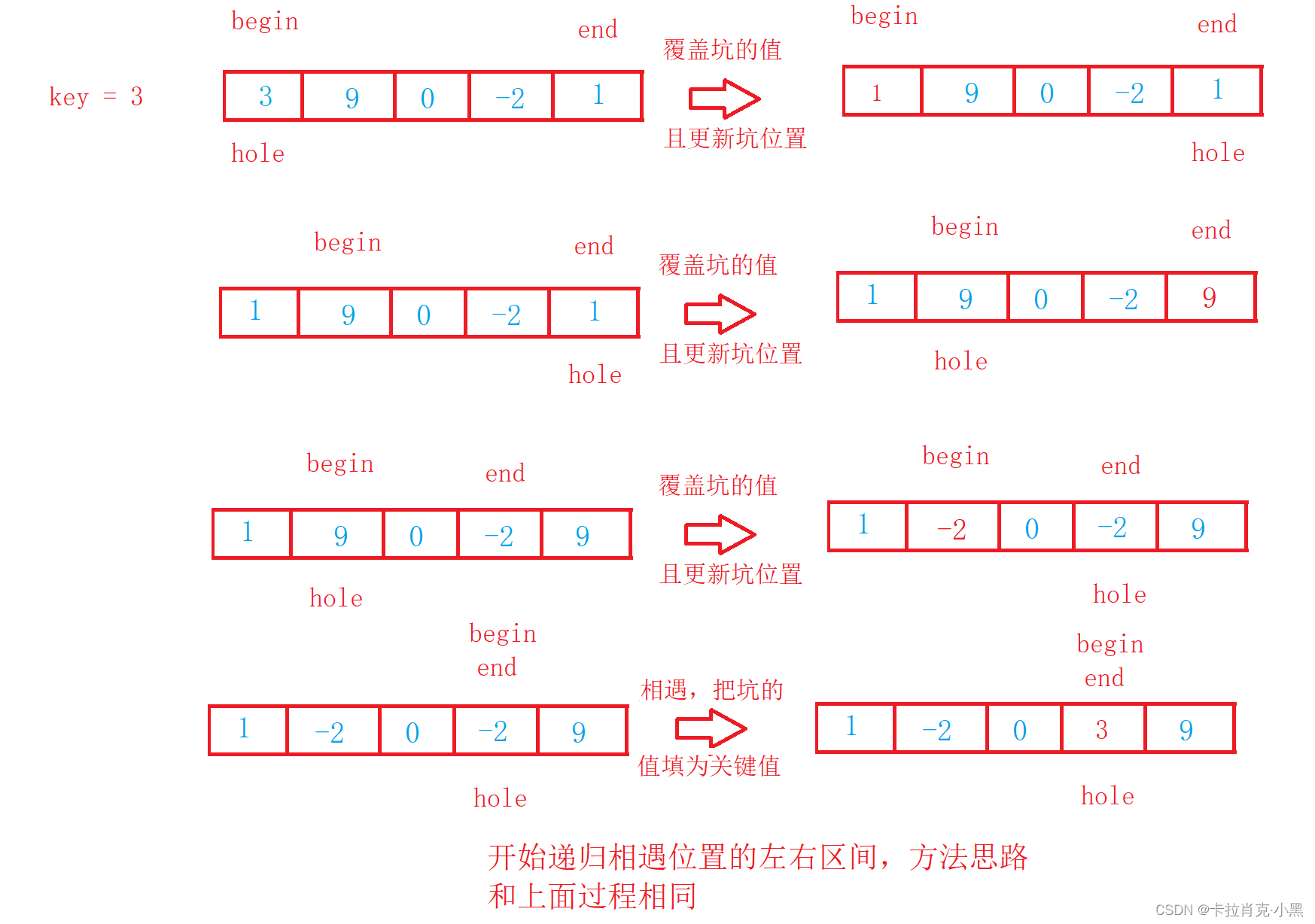
Tenga en cuenta que los primeros datos deben guardarse primero para formar el primer hoyo antes de poder sobrescribirlos.
3. Versión de puntero delantero y trasero
void PartSort3(int* nums, int left, int right)
{
if (left >= right)
{
return;
}
//记录关键值
int key = nums[left];
//快指针为关键值的下一个位置
int fast = left + 1;
//慢指针为关键值的位置
int slow = left;
while (fast <= right)
{
//当快指针的值小于关键值时
if (nums[fast] < key)
{
//当慢指针的下一个不为快指针时则不进行交换
if (++slow != fast)
{
swap(&nums[fast], &nums[slow]);
}
}
//对快指针进行移动
fast++;
//简写形式
//if (nums[fast] < key && ++slow != fast)
//{
// swap(&nums[slow], &nums[fast]);
//}
//++fast;
}
//关键值的位置和慢指针进行交换
swap(&nums[left], &nums[slow]);
//开始递归左边区间
PartSort3(nums, left, slow - 1);
//开始递归右边区间
PartSort3(nums, slow + 1, right);
}
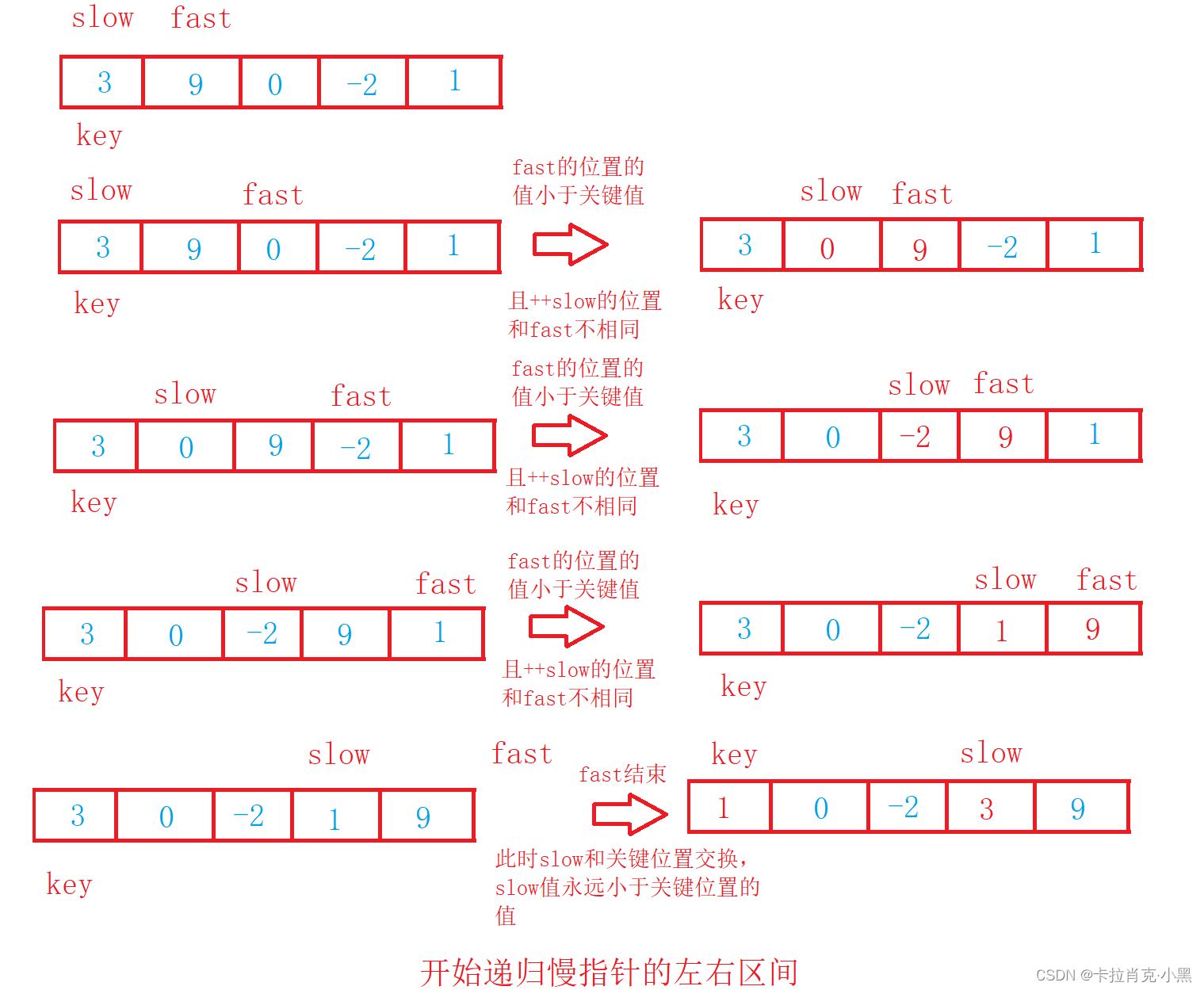
4.Versión mejorada
Cuando el intervalo a ordenar está en orden, nuestra clasificación es el peor de los casos y debemos optimizarla en este momento.
Vamos a sumar tres números para tomar la operación del medio.
//三数取中
void middle(int* nums, int left, int right)
{
//找到中间的数,交换到数组开头,因为我们关键值选则的为数组的左边值
int middle = (left + right) / 2;
if (nums[left] < nums[middle])
{
if (nums[middle] < nums[right])
{
swap(&nums[left], &nums[middle]);
}
else
{
swap(&nums[left], &nums[right]);
}
}
else
{
if (nums[right] < nums[left])
{
swap(&nums[left], &nums[right]);
}
}
}
void QuickSort(int* nums, int left, int right)
{
if (left >= right)
{
return;
}
middle(nums, left, right);//把中间值换到排序的开始位置
int key = left;
int begin = left;
int end = right;
while (begin < end)
{
//右边先走,目的是结束是相遇位置一定比key值小
while ((begin < end) && (nums[key] <= nums[end]))
{
end--;
}
while ((begin < end) && (nums[begin] <= nums[key]))
{
begin++;
}
swap(&nums[begin], &nums[end]);
}
swap(&nums[key], &nums[begin]);
key = begin;
QuickSort(nums, left, key - 1);
QuickSort(nums, key + 1, right);
}
La mejora de la versión 1 que implementamos, la mejora de las versiones 2 y 3 es la misma, solo agrega una función de llamada.
5. Versión no recursiva
Cuando la llamada recursiva de los datos que tomamos es demasiado profunda, la pila se destruirá, por lo que la clasificación rápida de la versión no recursiva también es la máxima prioridad. Hagámoslo realidad. En el modo no recursivo, utilizamos la pila que aprendimos antes para ayudarnos a completarla.
void QuickSortNonR(int* nums, int left, int right)
{
Stack st;//创建栈
StackInit(&st);//初始话栈
StackPush(&st, right);//把要排序的右边界入栈,这时会先左边界先出栈
StackPush(&st, left);//把要排序的左边界入栈
while (!StackEmpty(&st))//如果栈不为空,则一直进行循环
{
int left = StackTop(&st);//获得要排序的左边界
StackPop(&st);//把左边界出栈
int right = StackTop(&st);//获得要排序的右边界
StackPop(&st);//把右边界出栈
if (left >= right)//如果边界不合法则跳过本次循环
{
continue;
}
//快速排序版本1
int key = left;
int begin = left;
int end = right;
while (begin < end)
{
//右边先走,目的是结束是相遇位置一定比key值小
while ((begin < end) && (nums[key] <= nums[end]))
{
end--;
}
while ((begin < end) && (nums[begin] <= nums[key]))
{
begin++;
}
swap(&nums[begin], &nums[end]);
}
swap(&nums[key], &nums[begin]);
key = begin;
StackPush(&st, key-1);//把左边界的结束位置入栈
StackPush(&st, left);//把左边界的起始位置入栈
StackPush(&st, right);//把右边界的结束位置入栈
StackPush(&st, key+1);//把右边界的起始位置入栈
}
StackDestroy(&st);//销毁栈
}
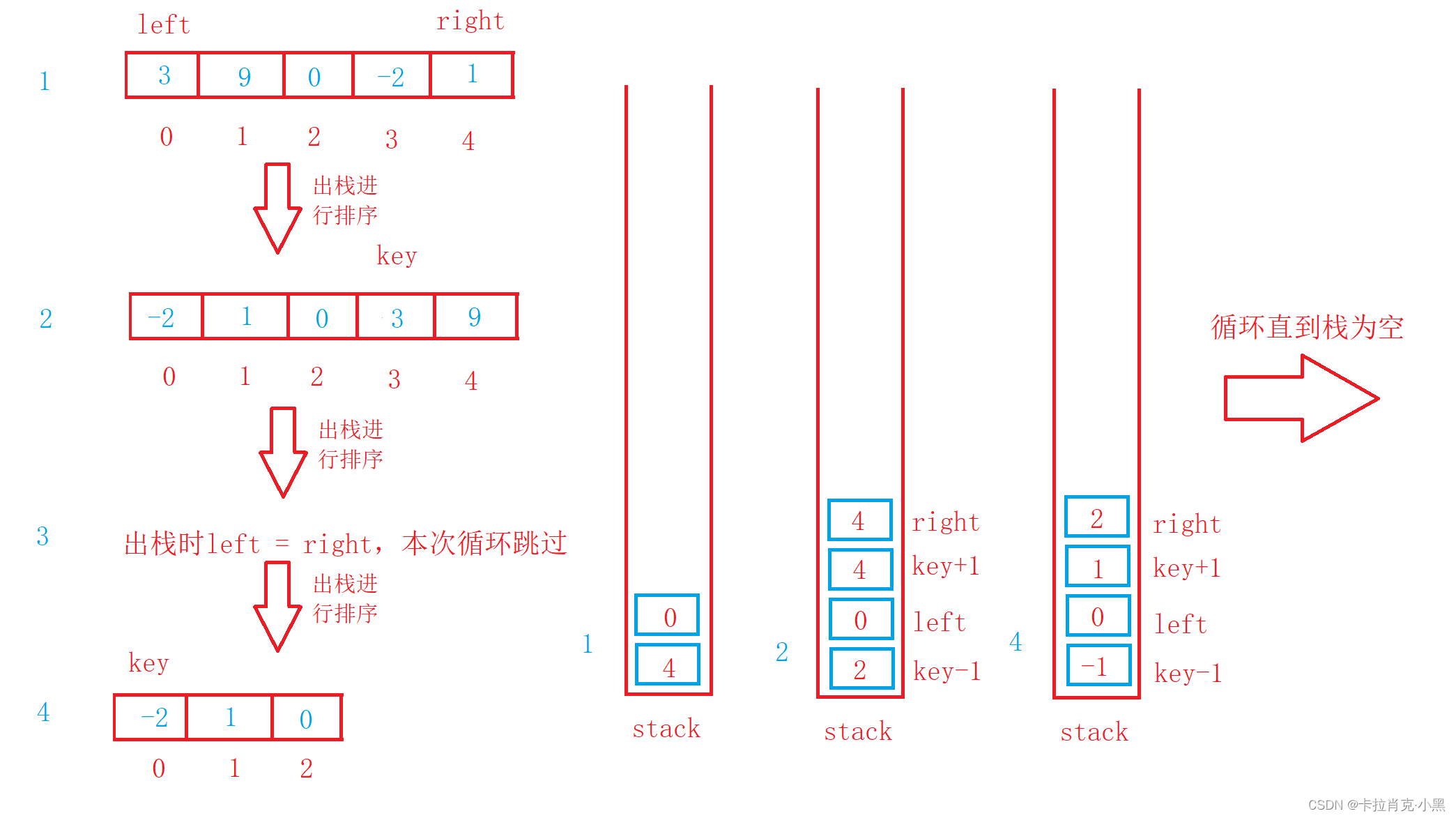
La clasificación rápida es muy eficiente en circunstancias normales y se puede combinar con otras clasificaciones para optimizar áreas pequeñas. Su complejidad temporal es O(N*logN) y su complejidad espacial es O(logN), pero es inestable
3.Seleccione ordenar
Cada vez, seleccione el valor más pequeño (o más grande) de los elementos de datos que se van a ordenar y guárdelo al principio de los datos hasta que se agoten todos los elementos de datos que se van a ordenar.
1. Clasificación por selección directa
void SelectSort(int* nums, int numsSize)
{
int i = 0;
for (i = 0; i < numsSize; i++)
{
int min = i;//记录最小数的下标
int j = 0;
for (j = i; j < numsSize; j++)//开始寻找最小数
{
if (nums[j] < nums[min])
{
min = j;//记录下标
}
}
if (min != i)
{
swap(&nums[min], &nums[i]);//如果最小数和开始位置不相同则进行交换
}
}
}
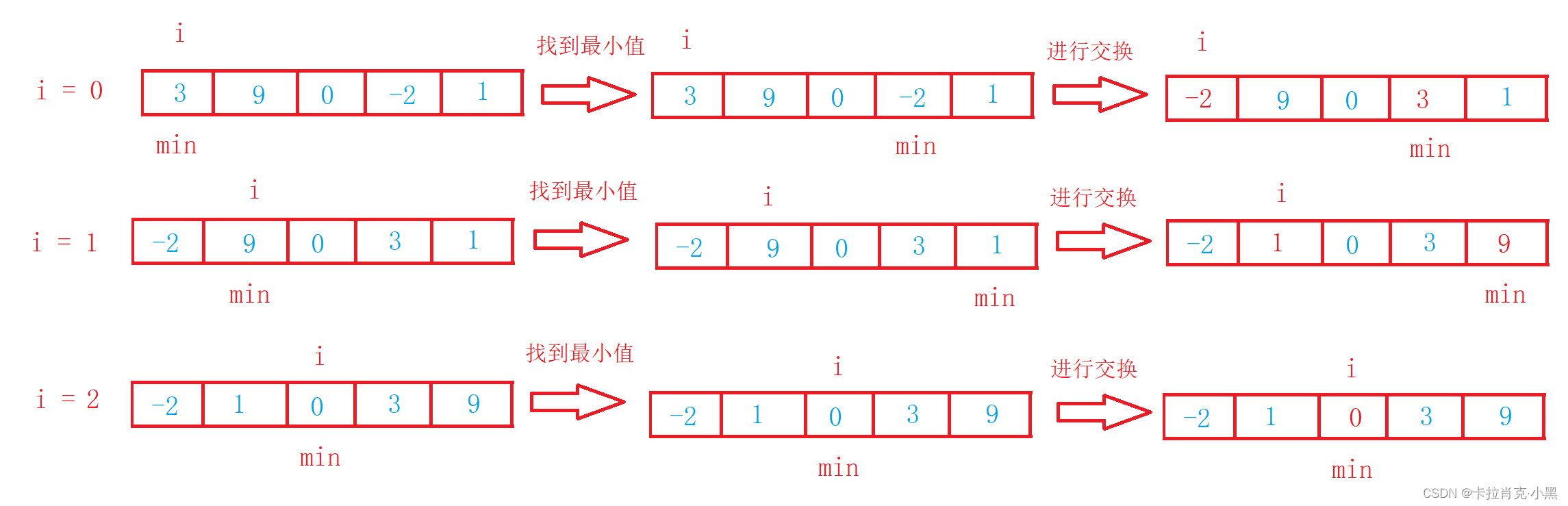
La clasificación por selección directa es muy fácil de entender, pero la eficiencia es demasiado baja. raramente utilizado en la práctica
2. Ordenación del montón
La idea de montón es la misma que la de árbol. La clasificación de montón se refiere a un algoritmo de clasificación diseñado utilizando una estructura de datos de árbol apilado (montón). Necesitamos construir un montón grande en orden ascendente y un montón pequeño en orden descendente.
void AdjustDwon(int* nums, int n, int root)
{
int left = root * 2 + 1;
while (left < n)
{
if (((left + 1) < n) && (nums[left] < nums[left + 1]))//当右子树存在并且右子树的值大于左子树
{
left = left + 1;//更新节点的下标
}
if (nums[root] < nums[left])
{
swap(&nums[root], &nums[left]);//如果根节点小于孩子节点,就进行交换
root = left;//更新根节点
left = root * 2 + 1;//更新孩子节点
}
else//已符合大堆结构,跳出循环
{
break;
}
}
}
//建大堆
void HeapSort(int* nums, int numsSize)
{
int i = 0;
//从第一个非叶子节点开始进行建堆,当左右都为大堆时才会排根节点
for (i = (numsSize - 1 - 1) / 2; i >= 0; --i)
{
AdjustDwon(nums, numsSize, i);
}
while (numsSize--)
{
swap(&nums[0], &nums[numsSize]);//如果根节点小于孩子节点,就进行交换
//调整堆结构
AdjustDwon(nums, numsSize, 0);
}
}
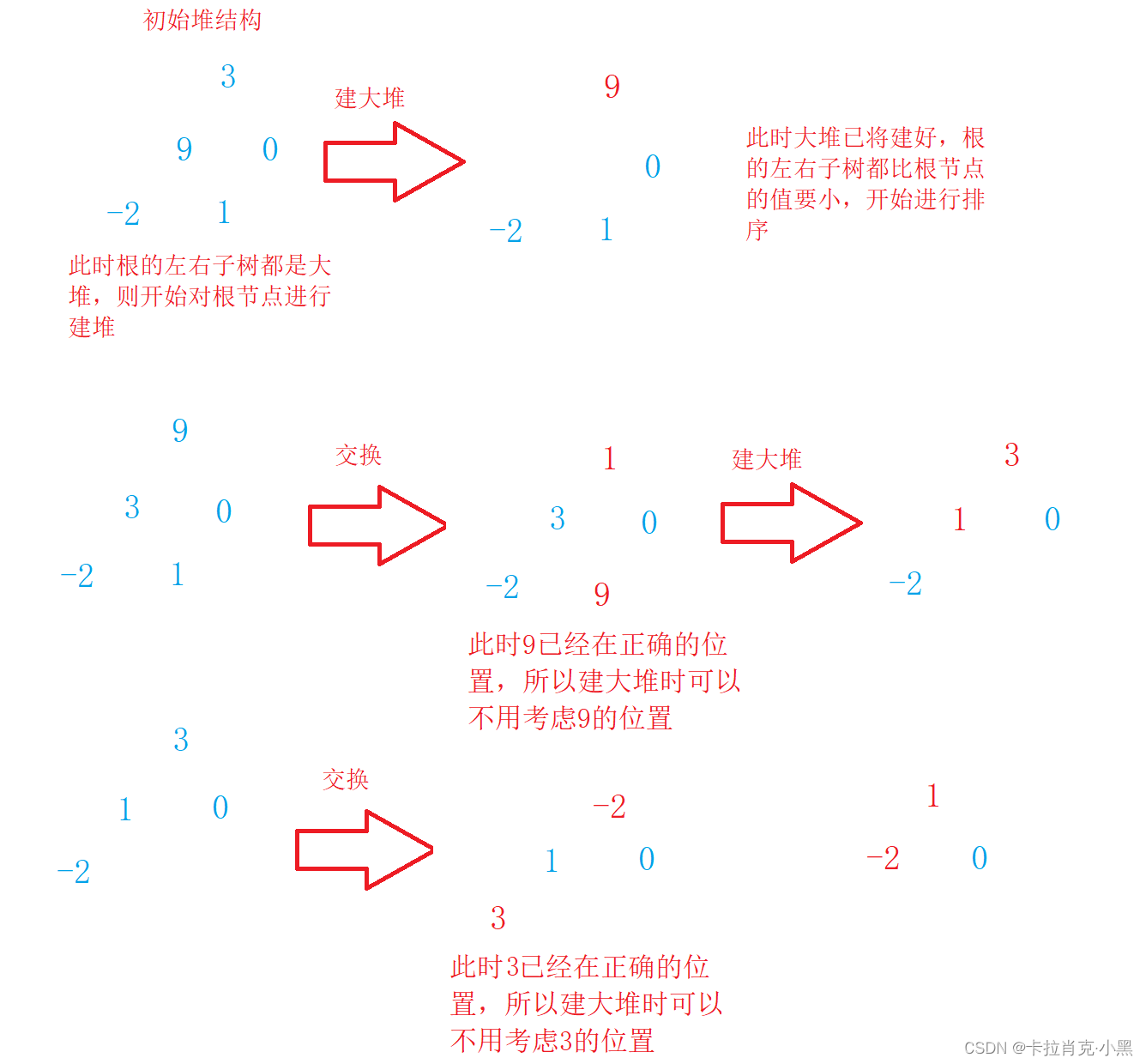
La clasificación de montón utiliza montones para seleccionar números, lo cual es mucho más eficiente que la clasificación directa. Tiene complejidad temporal O (N * logN) y complejidad espacial O (1), pero no es estable.
4. Combinar clasificación
Merge sort es un algoritmo de clasificación eficaz basado en la operación de fusión, que utiliza el método de dividir y conquistar. Ordene cada subsecuencia primero y luego ordene los segmentos de la subsecuencia. Si dos listas ordenadas se combinan en una lista ordenada. La fusión requiere un espacio temporal para almacenar la subsecuencia y copiarla a la secuencia fuente.
1. Implementación recursiva de clasificación por combinación
void MergeSort(int* nums, int left, int right,int *tmp)
{
if (left >= right)
{
return;
}
//把区间拆分为两段
int middle = (left + right) >> 1;
//拆分
MergeSort(nums, left, middle, tmp);
MergeSort(nums, middle+1, right, tmp);
//归并
int begin1 = left;
int begin2 = middle + 1;
int end1 = middle;
int end2 = right;
int i = 0;
//和链表的链接差不多
//直到有一个区间结束结束循环
while ((begin1 <= end1) && (begin2 <= end2))
{
//那个值小那个值进入开辟的数组
if (nums[begin1] <= nums[begin2])
{
tmp[i++] = nums[begin1++];
}
else
{
tmp[i++] = nums[begin2++];
}
}
//找到未完全结束的数组,并且把数组中的元素尾加到开辟的数组中
while (begin1 <= end1)
{
tmp[i++] = nums[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = nums[begin2++];
}
//把开辟的数组中的内容拷贝到源数组中
//拷贝时要注意拷贝时的位置
memcpy(nums + left, tmp, (right - left + 1) * sizeof(int));
}
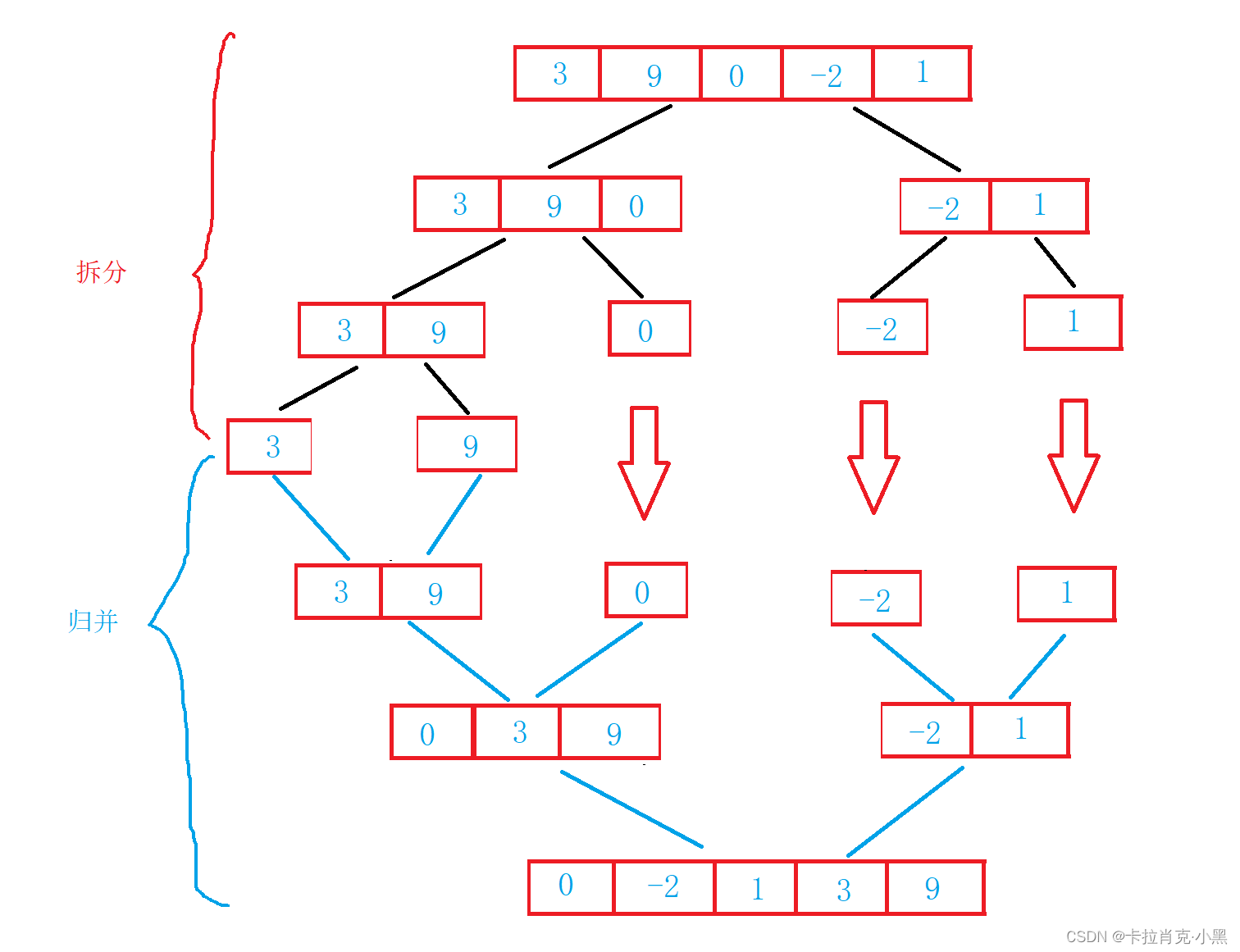
2. Implementación no recursiva de clasificación por combinación
void MergeSortNonR(int* nums, int numsSize, int* tmp)
{
//归并所用的数
int gap = 1;
int i = 0;
while(gap < numsSize)//当归并使用的数小于数组大小时进行循环
{
for (i = 0; i < numsSize;)//用i来控制归并的位置
{
int begin1 = i;
int begin2 = i + gap;
int end1 = i + gap - 1;
int end2 = i + 2 * gap - 1;
//当end1越界时进行修正,此时begin2和end2都会越界时进行修正
if (end1 > numsSize - 1)
{
end1 = numsSize - 1;
begin2 = numsSize + 1;
end2 = numsSize;
}
//当begin2越界时进行修正,此时end2也会越界
else if (begin2 > numsSize - 1)
{
begin2 = numsSize + 1;
end2 = numsSize;
}
//当end2越界时进行修正
else if(end2 > numsSize - 1)
{
end2 = numsSize - 1;
}
//开始进行归并
while ((begin1 <= end1) && (begin2 <= end2))
{
if (nums[begin1] <= nums[begin2])
{
tmp[i++] = nums[begin1++];
}
else
{
tmp[i++] = nums[begin2++];
}
}
//找到未结束的数组插入到临时数组中
while (begin1 <= end1)
{
tmp[i++] = nums[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = nums[begin2++];
}
}
//把临时数组的内容拷贝到源数组中
memcpy(nums, tmp, numsSize * sizeof(int));
//把归并的范围扩大
gap *= 2;
}
}
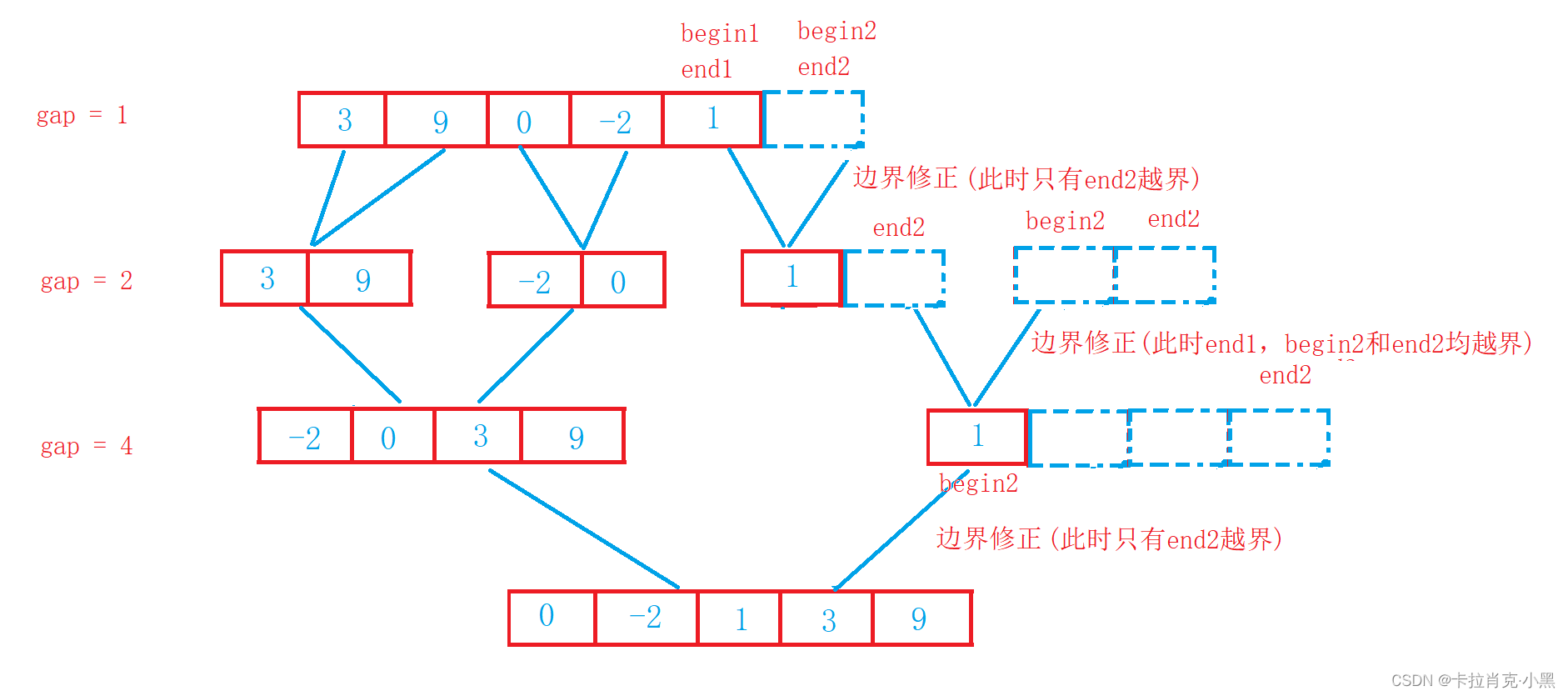
Al realizar una clasificación de combinación no recursiva, se debe prestar atención a la corrección de límites; de lo contrario, se producirá una situación fuera de límites.
La desventaja de la fusión es que requiere espacio O (N), pero la idea de la clasificación por fusión se trata más de resolver el problema de la subcontratación en el disco. Se puede utilizar como clasificación interna o clasificación externa, y la complejidad del tiempo es O (N * logN), que es una clasificación estable.
5. Ordenación por conteo
void CountSort(int* nums, int numsSize)
{
int i = 0;
int min = nums[i];
int max = nums[i];
//找到原数组中的最大值和最小值
for (i = 0; i < numsSize; i++)
{
if (min > nums[i])
{
min = nums[i];
}
if (max < nums[i])
{
max = nums[i];
}
}
//计算出排序中最大和最小值的差,加上1为要开辟临时数组的大小
int num = max - min + 1;
//创建相应的大小的空间
int* tmp = (int*)malloc(sizeof(int) * num);
//对创建的空间进行初始话,把里面的元素全部置0
memset(tmp, 0, sizeof(int) * num);
//遍历原数组,把该元素值的下标映射到临时数组中
for (i = 0; i < numsSize; i++)
{
tmp[nums[i] - min]++;
}
int j = 0;
//遍历临时数组,把该元素不为0的恢复原值拷贝到原数组中
for (i = 0; i < num; i++)
{
while (tmp[i]--)
{
nums[j++] = i + min;
}
}
free(tmp);
}
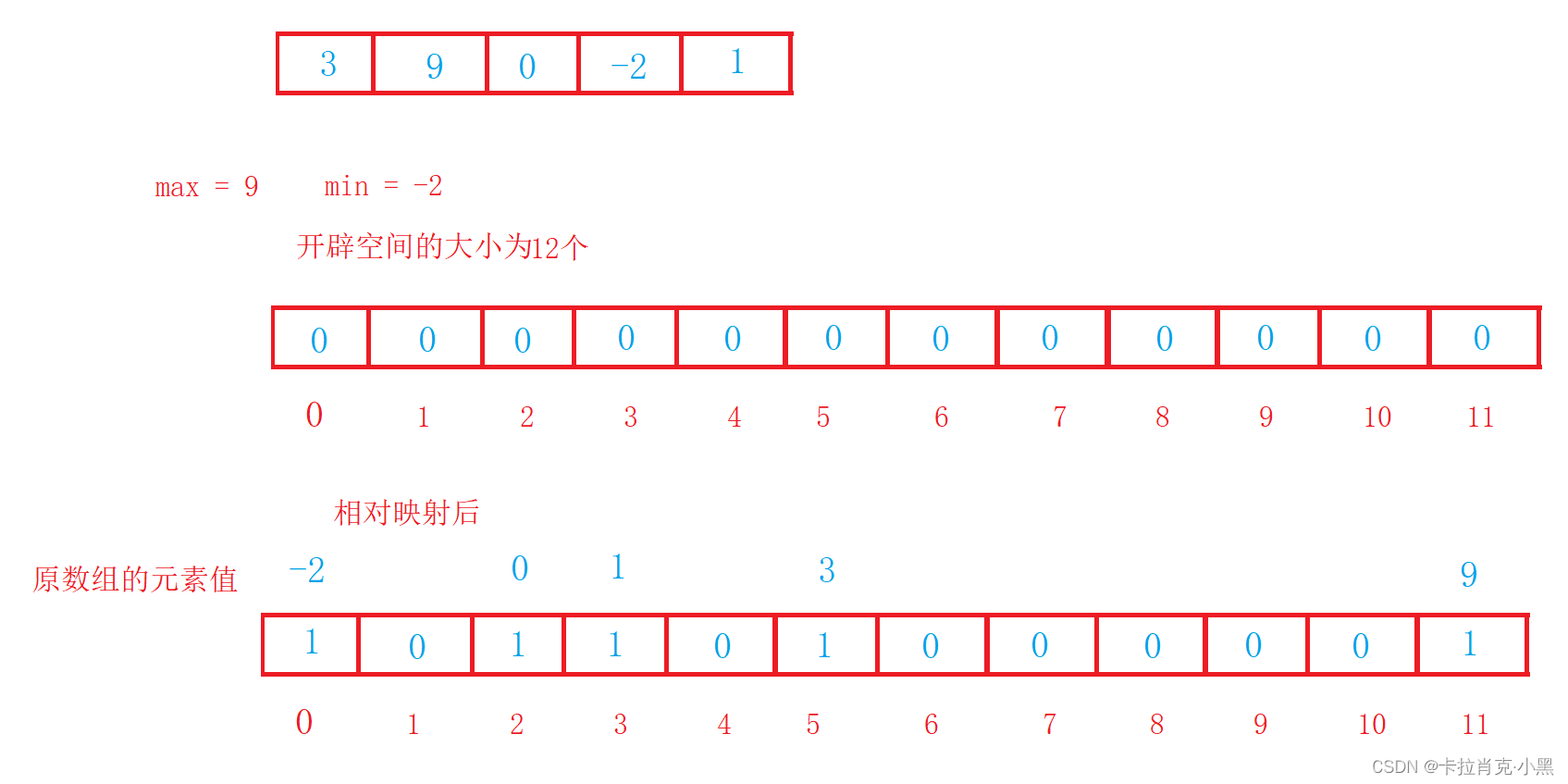
La clasificación por conteo es muy eficiente cuando el rango de datos está concentrado, pero su alcance de aplicación y escenarios son limitados.
2. La complejidad y estabilidad del algoritmo de clasificación.
| Método de clasificación | situación promedio | en el mejor de los casos | peor de los casos | consumo de espacio | estabilidad |
|---|---|---|---|---|---|
| clasificación por inserción directa | O(N^2) | EN) | O(N^2) | O(1) | Estabilizar |
| clasificación de colinas | O(N*logN)~O(N^2) | O(N^1.3) | O(N^2) | O(1) | inestable |
| Ordenamiento de burbuja | O(N^2) | EN) | O(N^2) | O(1) | Estabilizar |
| Ordenación rápida | O(N*logN) | O(N*logN) | O(N^2) | O(N*logN)~O(N) | inestable |
| clasificación de selección | O(N^2) | O(N^2) | O(N^2) | O(1) | inestable |
| clasificación de montón | O(N*logN) | O(N*logN) | O(N*logN) | O(1) | inestable |
| fusionar ordenar | O(N*logN) | O(N*logN) | O(N*logN) | EN) | Estabilizar |
prueba de clasificación
int tmp1[20];
int tmp2[20];
int tmp3[20];
int tmp4[20];
int tmp5[20];
int tmp6[20];
int tmp7[20];
int tmp8[20];
int tmp9[20];
int tmp10[20];
int tmp11[20];
int tmp12[20];
int tmp13[20];
void init()
{
int i = 0;
int nums = 0;
for (i = 0; i < 20; i++)
{
nums = rand() % 100;
tmp1[i] = nums;
tmp2[i] = nums;
tmp3[i] = nums;
tmp4[i] = nums;
tmp5[i] = nums;
tmp6[i] = nums;
tmp7[i] = nums;
tmp8[i] = nums;
tmp9[i] = nums;
tmp10[i] = nums;
tmp11[i] = nums;
tmp12[i] = nums;
tmp13[i] = nums;
}
}
void test()
{
int numsSize = 20;
InsertSort(tmp1, numsSize);//插入排序
ShellSort(tmp2, numsSize);//希尔排序
BubbleSort(tmp3, numsSize);//冒泡排序
PartSort1(tmp4, 0, numsSize - 1);//快排1
PartSort2(tmp5, 0, numsSize - 1);//快排2
PartSort3(tmp6, 0, numsSize - 1);//快排3
QuickSort(tmp7, 0, numsSize - 1);//快排改进
QuickSortNonR(tmp8, 0, numsSize - 1);//快排非递归
SelectSort(tmp9, numsSize);
HeapSort(tmp10, numsSize);
int* tmp = (int*)malloc(sizeof(int) * numsSize);
MergeSort(tmp11, 0, numsSize - 1, tmp);
MergeSortNonR(tmp12, numsSize - 1, tmp);
CountSort(tmp13, numsSize);
free(tmp);
}
void print(int* nums, int numsSize)
{
int i = 0;
for (i = 0; i < numsSize; i++)
{
printf("%d ", nums[i]);
}
printf("\n");
}
void Print()
{
print(tmp1, 20);
print(tmp2, 20);
print(tmp3, 20);
print(tmp4, 20);
print(tmp5, 20);
print(tmp6, 20);
print(tmp7, 20);
print(tmp8, 20);
print(tmp9, 20);
print(tmp10, 20);
print(tmp11, 20);
print(tmp12, 20);
print(tmp13, 20);
}
int main()
{
srand((unsigned)time());
//int nums[] = { 3,9,0,-2,1 };
//int numsSize = sizeof(nums) / sizeof(nums[0]);//计算数组大小
//sortArray(nums, numsSize);//调用排序算法
init();//对排序的数组赋值
test();//调用各个排序函数
//print(nums, numsSize);//打印排序结果
Print();//打印各个排序结果
return 0;
}