- Rastreador enfocado: rastrea el contenido de la página especificada en la página
- Proceso de codificación
- URL especificada
- Hacer una solicitud
- Obtener datos de respuesta
- análisis de los datos
- Almacenamiento persistente
- Clasificación del análisis de datos:
- Regular
-bs4
- xpath (***)
- Descripción general de los principios del análisis de datos
- El contenido del texto local analizado se almacenará entre etiquetas o en los atributos correspondientes a las etiquetas.
- 1. Coloque la etiqueta especificada.
- 2. Extraer (analizar) los datos almacenados en la etiqueta o el atributo correspondiente a la etiqueta.
formato caso




Expresiones regulares en acción
- Requisito: Enciclopedia de rastreo de imágenes de historias embarazosas
- re.S coincidencia de una sola línea
-re.MCoincidencia de varias líneas
- Formato binario: contenido
- formato: poderosa herramienta para formatear cadenas. Puede insertar variables, expresiones y otros valores en una cadena formateada en posiciones específicas
Lugar de enlace de imagen
Análisis de datos periódicos
Obtenga la dirección de la imagen y escriba la expresión regular.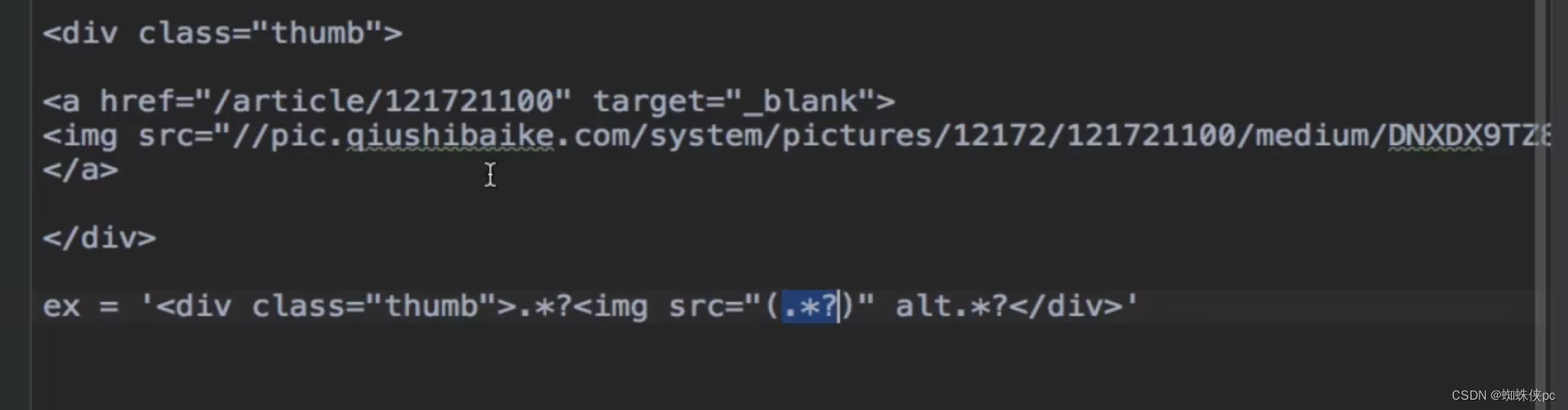
Dirección de imagen sin protocolo
import re
import requests
import os
#创建文件夹
if not os.path.exists('./qiutuLibs'):
os.mkdir('./qiutuLibs')
url = 'https://www.qiushibaike.com/pic/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
#使用通用爬虫对一整张页面进行爬取
page_text = requests.get(url=url,headers=headers).text
#使用聚焦爬虫将页面中的糗图进行解析
#正则表达式
ex = '<div class="thumb">.*?<img src="(.*?)" alt.*?</div>'
img_src_list = re.findall(page_text,ex,re.S) #正则用到数据解析时一定用的re.S
print(img_src_list) #拿到图片地址的列表
for src in img_src_list:
#拼接出一个完整的图片url
src = 'http:'+src
#请求到了图片的二进制
img_data = requests.get(url=src,headers=headers).content#content以二进制的形式存储
#生成图片名称
img_name = src.split('/')[-1]
#图片最终存储的路径
iimgPath = './qiutuLibs/'+img_name
with open(iimgPath,'wb') as fp:
fp.write(img_data)
print(img_name,"下载成功!!!")bs4 para análisis de datos
- Principios del análisis de datos.
- 1. Posicionamiento de etiquetas
- 2. Extraer etiquetas y valores de datos almacenados en atributos de etiquetas
- Principio del análisis de datos bs4.
- 1. Cree una instancia de un objeto BeautifulSoup y cargue los datos del código fuente de la página en el objeto.
-2. Realizar posicionamiento de etiquetas y extracción de datos llamando a propiedades o métodos relevantes en el objeto BeautifulSoup
- Instalación ambiental.
- pipa instalar bs4
- instalación de pip lxml
- Cómo crear una instancia de un objeto BeautifulSoup
- desde bs4 importar BeautifulSoup
- Creación de instancias de objetos
- 1. Cargue los datos del documento html local en el objeto.
fp = open('./test.html','r',codificación = 'utf-8')
sopa = HermosaSopa(fp,'lxml')
- 2. Cargue el código fuente de la página obtenido de Internet en el objeto.
texto_pagina =respuesta.texto
sopa = HermosaSopa(page_text,'lxml')
- Métodos y propiedades proporcionados para el análisis de datos.
- sopa.tagName: Devuelve la etiqueta correspondiente al tagName que aparece por primera vez en el documento
- sopa.buscar() :
-find('tagName'): Equivalente a sopa.tarName
- Posicionamiento de atributos:
- sopa.find('div',class_/id/attr='canción')
- Soup.find_all('tagName'): devuelve todas las etiquetas (lista) que cumplen con los requisitos.
- seleccionar :
- select('Algún tipo de selector (id, clase, etiqueta...selector)'), devuelve una lista
- Selector de nivel:
- sopa.select('.tang > ul > li > a')
- Soup.select('.tang > ul > li a'): Múltiples niveles representados por espacios
- Obtener datos de texto entre etiquetas:
- sopa.a.text/string/get_text() dos atributos, un método
- text/get_text(): puedes obtener todo el contenido de texto en una determinada etiqueta
- cadena: solo se puede obtener el contenido del texto directamente debajo de la etiqueta
- Obtener el valor del atributo en la etiqueta.
- sopa.a['href']

BeautifluSoup en acción: rastreo de libros de Romance de los Tres Reinos
import requests
from bs4 import BeautifulSoup
url = 'https://www.shicimingju.com/book/sanguoyanyi.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36'
}
#发起请求
page_text = requests.get(url=url,headers=headers).text.encode('ISO-8859-1')
print(page_text)
soup = BeautifulSoup(page_text,'lxml') #实例化对象
li_list = soup.select('.book-mulu > ul >li') #拿到所有的li标签
print(li_list)
fp = open ('./sanguo.txt','w',encoding='utf-8')
for li in li_list:
title =li.a.string #拿到a标签的文本内容
detail_url ='https://www.shicimingju.com/'+li.a['href'] #拿到该章内容的网页
detail_page_text = requests.get(url=detail_url, headers=headers).text.encode('ISO-8859-1')
detail_soup = BeautifulSoup(detail_page_text,'lxml')
div_tag = detail_soup.find('div',class_='chapter_content')
#解析到了章节的内容
content = div_tag.get_text()
# 持久化存储
fp.write(title +':'+content+'\n')
print(title,'爬取成功!!!')