Capítulo 1 Descripción general de HDFS
1.1 Fondo y definición de salida HDFS
Fondo de generación HDFS
A medida que aumenta la cantidad de datos, no se pueden almacenar todos en un solo sistema operativo, por lo que se asignan a más discos administrados por el sistema operativo, pero es un inconveniente de administrar y mantener, y se necesita con urgencia un sistema para administrar varias máquinas Este es el sistema de administración de archivos distribuidos. HDFS es solo un tipo de sistema de administración de archivos distribuidos .
HDFS definición
HDFS (Sistema de archivos distribuidos de Hadoop), que es un sistema de archivos, se usa para almacenar archivos y ubicarlos a través de árboles de directorios; en segundo lugar, está distribuido y muchos servidores se combinan para realizar sus funciones. Los servidores en el clúster tienen su propio Role.
Escenarios de uso de HDFS: adecuado para una sola escritura, múltiples escenarios de lectura. No es necesario cambiar un archivo después de crearlo, escribirlo y cerrarlo.
1.2 Ventajas y desventajas de HDFS
1.2.1 Ventajas de HDFS
alta tolerancia a fallas
Los datos se guardan automáticamente en varias copias. Mejora la tolerancia a fallas al agregar copias.
Después de perder una copia, se puede restaurar automáticamente.
Adecuado para el manejo de grandes datos
Escala de datos: capaz de manejar datos con escalas de datos que alcanzan niveles de GB, TB o incluso PB
Tamaño del archivo: puede manejar la cantidad de archivos por encima de la escala de un millón , que es bastante grande.
Se puede construir en máquinas baratas y la confiabilidad se puede mejorar a través del mecanismo de copias múltiples.
1.2.2 Desventajas de HDFS
No es adecuado para el acceso a datos de baja latencia , como almacenar datos en milisegundos, es imposible.
No puede almacenar de manera eficiente una gran cantidad de archivos pequeños.
Si almacena una gran cantidad de archivos pequeños, ocupará una gran cantidad de memoria de NameNode para almacenar el directorio de archivos y bloquear la información. Esto no es aconsejable, porque la memoria del NameNode siempre es limitada.
El tiempo de búsqueda para el almacenamiento de archivos pequeños superará el tiempo de lectura, lo que infringe el objetivo de diseño de HDFS.
No se admiten la escritura simultánea ni la modificación aleatoria de archivos .
Un archivo solo puede ser escrito por uno, y no se permite que varios subprocesos escriban al mismo tiempo.
Solo admite la adición de datos (adjuntar) , no admite la modificación aleatoria de archivos
1.3 Estructura HDFS
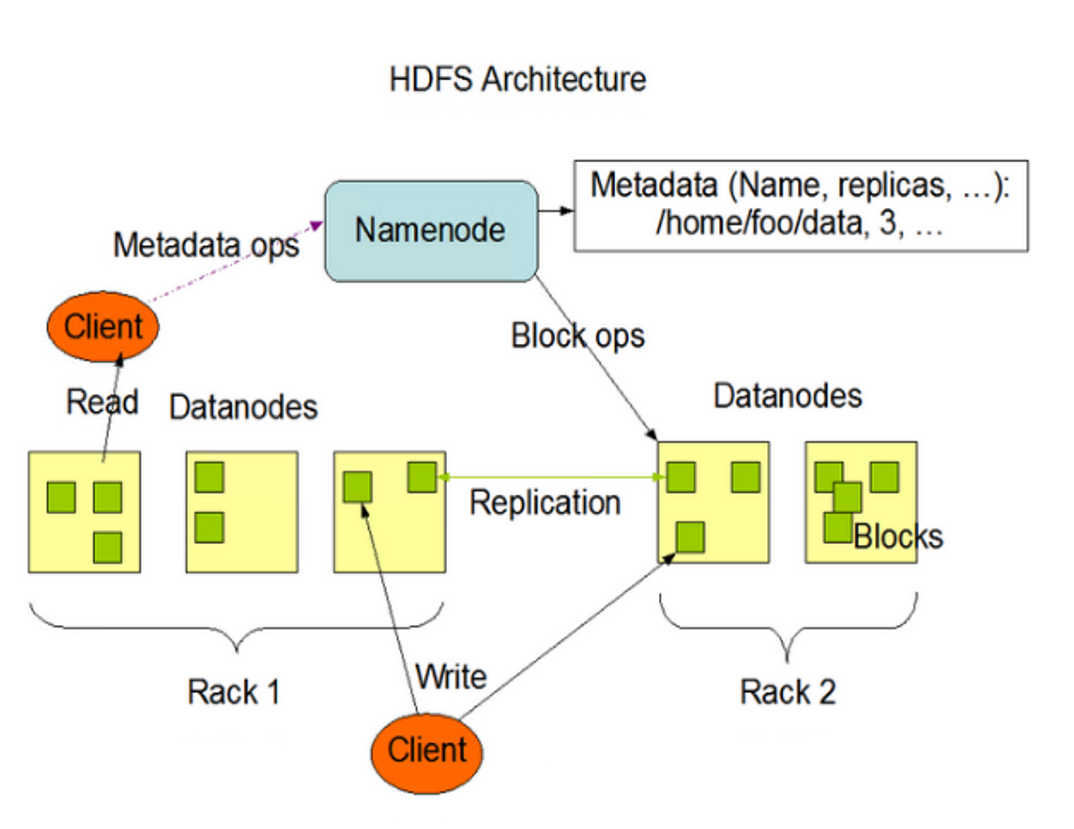
NameNode (nn) es el Maestro, que es un supervisor y administrador.
Administrar espacios de nombres HDFS;
estrategia de copia;
Administrar la información de mapeo del bloque de datos (Bloque);
Manejar las solicitudes de lectura y escritura del cliente.
DataNode : Es esclavo. NameNode emite órdenes y DaaNode realiza operaciones reales.
almacenar el bloque de datos actual
Realizar operaciones de lectura/escritura en bloques de datos.
Cliente : Es el cliente.
Segmentación de archivos. Cuando se carga un archivo en HDFS, el cliente divide el archivo en bloques uno por uno y luego carga el archivo.
Interactuar con NameNode para obtener la información de ubicación del archivo;
Interactuar con DaaNode, leer o escribir datos;
El cliente proporciona algunos comandos para administrar HDFS, como el formateo de NameNode;
El cliente puede acceder a HDFS a través de algunos comandos, como agregar, eliminar, modificar y consultar HDFS.
NameNode secundario : no es un modo de espera activo de NameNode. Cuando el NameNode cuelga, no puede reemplazar inmediatamente al NameNode y proporcionar servicios.
NameNode auxiliar comparte su trabajo, como fusionar Fsiage y Edits regularmente y enviarlos a NameNode.
En caso de emergencia, puede ayudar a recuperar el NameNode.
1.4 Tamaño de bloque de archivo HDFS (enfoque de entrevista)

pensar:
¿Por qué el tamaño del bloque no puede establecerse demasiado pequeño ni demasiado grande?
La configuración del bloque de HDFS es demasiado pequeña , lo que aumentará el tiempo de búsqueda y el programa ha estado buscando la posición de inicio del bloque;
Si el bloque es demasiado grande , el tiempo para transferir datos desde el disco será significativamente más largo que el tiempo requerido para ubicar el comienzo del bloque . Como resultado, el programa será muy lento al procesar este dato.
Resumen: la configuración del tamaño del bloque HDFS depende principalmente de la velocidad de transferencia del disco.
Capítulo 2 Operación Shell de HDFS
2.1 Sintaxis básica
hadoop fs [comando específico] O hdfs dfs [comando específico]
dos son identicos
2.2 Comandos comunes
2.2.1 Subir
-moveFromLocal: cortar y pegar de local a HDFS
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -moveFromLocal ./shuguo.txt /sanguo-copyFromLocal: copia archivos del sistema de archivos local a la ruta HDFS
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -copyFromLocal weiguo.txt /sanguo-put: Equivalente a copyFromLocal, el entorno de producción está más acostumbrado a usar put
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -put ./wuguo.txt /sanguo-appendToFile: agrega un archivo al final de un archivo existente
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -appendToFile liubei.txt /sanguo/shuguo.txt2.2.2 descargar
-copyToLocal: copia de HDFS a local
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -copyToLocal /sanguo/shuguo.txt ./-get: equivalente a copyToLocal, el entorno de producción está más acostumbrado a usar get
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -get /sanguo/shuguo.txt ./shuguo2.txt2.2.3 Operación directa de HDFS
-ls: mostrar información del directorio
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -ls /sanguo-cat: muestra el contenido del archivo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -cat /sanguo/shuguo.txt-chgrp, -chmod, -chown: el mismo uso en el sistema de archivos de Linux, modifica los permisos del archivo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -chmod 666 /sanguo/shuguo.txt
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -chown atguigu:atguigu /sanguo/shuguo.txt-mkdir: crear ruta
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /jinguo-cp: copia de una ruta de HDFS a otra ruta de HDFS
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -cp /sanguo/shuguo.txt /jinguo-mv: mover archivos en el directorio HDFS
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/wuguo.txt /jinguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/weiguo.txt /jinguo-tail: muestra el final de 1kb de datos de un archivo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -tail /jinguo/shuguo.txt-rm: eliminar un archivo o carpeta
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -rm /sanguo/shuguo.txt-rm -r: Borrar directorios recursivamente y sus contenidos
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -rm -r /sanguo-du información estadística sobre el tamaño de la carpeta
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -du -s -h /jinguo-setrep: establece el número de copias de archivos en HDFS
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -setrep 10 /jinguo/shuguo.txt2.3 Funcionamiento de la API de HDFS
2.3.1 Carga de archivos HDFS
@Test
public void testCopyFromLocalFile() throws IOException, InterruptedException, URISyntaxException {
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration, "atguigu");
// 2 上传文件
fs.copyFromLocalFile(new Path("e:/banzhang.txt"), new Path("/banzhang.txt"));
// 3 关闭资源
fs.close();
2.3.2 Descarga de archivos HDFS
@Test
public void testCopyToLocalFile() throws IOException, InterruptedException, URISyntaxException{
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration, "atguigu");
// 2 执行下载操作
// boolean delSrc 指是否将原文件删除
// Path src 指要下载的文件路径
// Path dst 指将文件下载到的路径
// boolean useRawLocalFileSystem 是否开启文件校验
fs.copyToLocalFile(false, new Path("/banzhang.txt"), new Path("e:/banhua.txt"), true);
// 3 关闭资源
fs.close();
}
2.3.3 Prioridad de parámetros
Clasificación de prioridad de parámetros: (1) Valor establecido en el código del cliente > (2) Archivo de configuración definido por el usuario en ClassPath > (3) Luego configuración predeterminada del servidor
Capítulo 3 Proceso de lectura y escritura HDFS (enfoque de entrevista)
3.1 Proceso de escritura de datos HDFS
3.1.1 Escritura del archivo de análisis
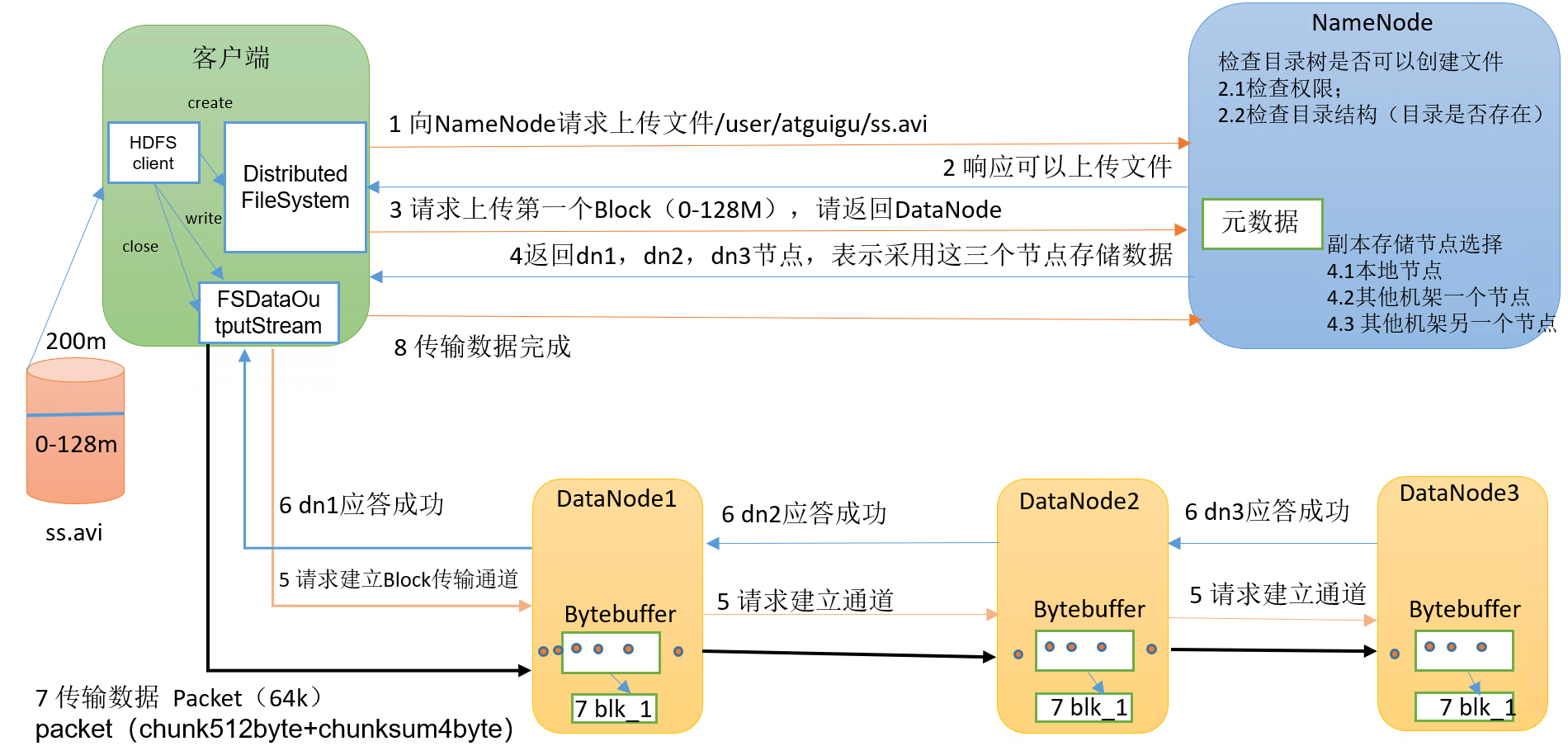
proceso específico:
(1) El cliente solicita a NameNode que cargue archivos a través del módulo Distributed FileSystem, y NameNode verifica si existe el archivo de destino y si existe el directorio principal.
(2) NameNode devuelve si se puede cargar.
(3) A qué servidores de DataNode solicita el cliente cargar el primer Bloque.
(4) NameNode devuelve tres nodos DataNode, a saber, dn1, dn2 y dn3.
(5) El cliente solicita a dn1 que cargue datos a través del módulo FSDataOutputStream. Después de recibir la solicitud, dn1 continuará llamando a dn2, y luego dn2 llamará a dn3 para completar el establecimiento del canal de comunicación.
(6) dn1, dn2 y dn3 responden al cliente paso a paso.
(7) El cliente comienza a cargar el primer Bloque a dn1 (primero lee los datos del disco y los coloca en un caché de memoria local), tomando el Paquete como unidad, dn1 pasará un Paquete a dn2 y dn2 lo pasará a dn3; dn1 Cada vez que se transmite un paquete, se colocará en una cola de respuesta para esperar la respuesta.
(8) Cuando se completa la transmisión de un Bloque, el cliente solicita al NameNode que vuelva a cargar el servidor del segundo Bloque. (Repita los pasos 3-7).
3.1.2 Conciencia de rack (selección de nodo de almacenamiento de réplica)
Instrucciones de reconocimiento de estantes
descripción oficial
For the common case, when the replication factor is three, HDFS’s placement policy is to put one replica on the local machine if the writer is on a datanode, otherwise on a random datanode, another replica on a node in a different (remote) rack, and the last on a different node in the same remote rack. This policy cuts the inter-rack write traffic which generally improves write performance. The chance of rack failure is far less than that of node failure; this policy does not impact data reliability and availability guarantees. However, it does reduce the aggregate network bandwidth used when reading data since a block is placed in only two unique racks rather than three. With this policy, the replicas of a file do not evenly distribute across the racks. One third of replicas are on one node, two thirds of replicas are on one rack, and the other third are evenly distributed across the remaining racks. This policy improves write performance without compromising data reliability or read performance.Hadoop3.1.3 selección de nodos de réplica
La primera copia está en el nodo donde se encuentra el Cliente. Si el cliente está fuera del clúster, seleccione uno al azar
La segunda réplica está en un nodo aleatorio en otro rack
La tercera réplica está en un nodo aleatorio en el mismo bastidor que la segunda réplica
3.2 Proceso de lectura de datos HDFS
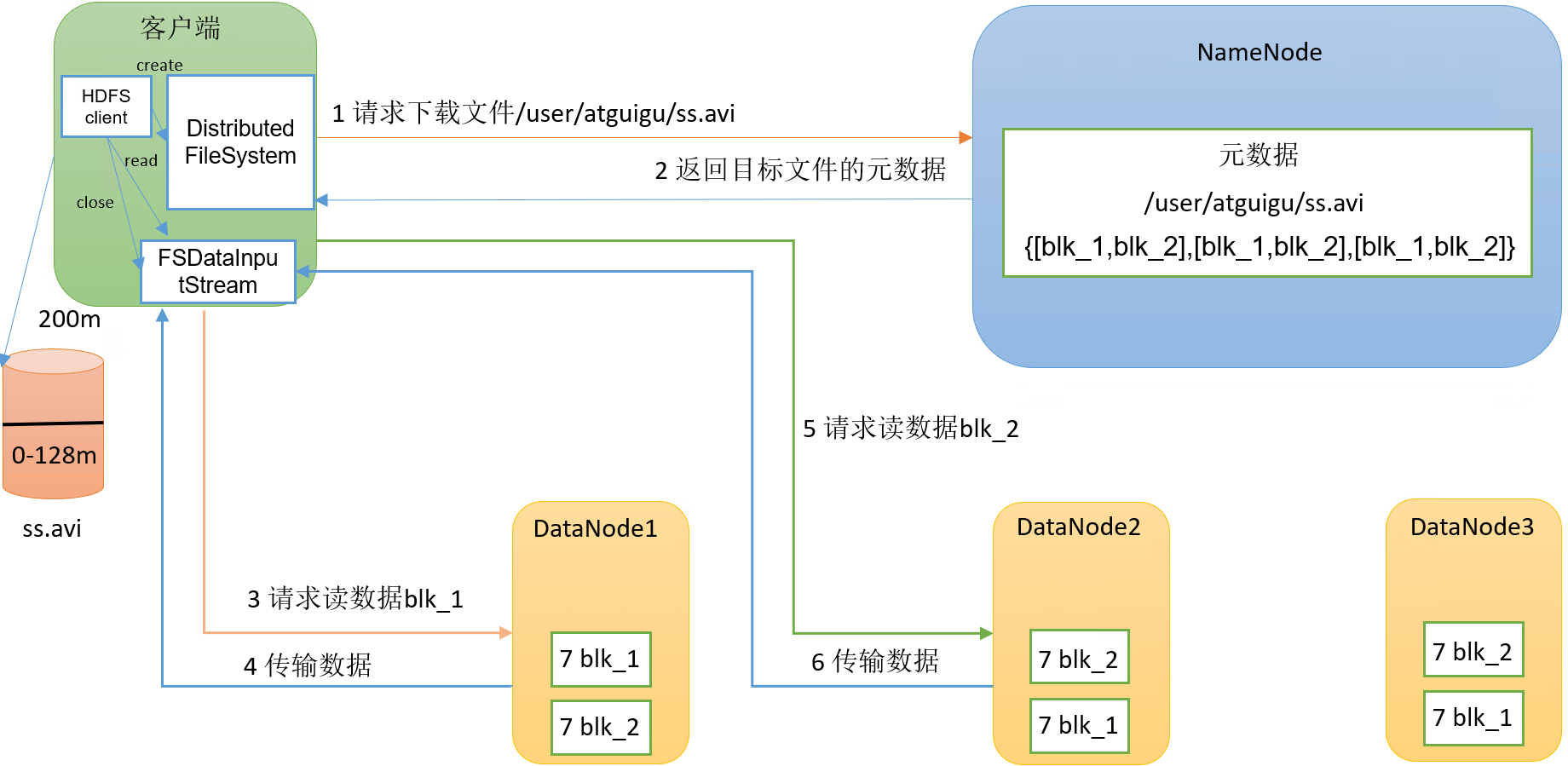
proceso específico:
(1)客户端通过DistributedFileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。
(2)挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
(3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
(4)客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
第4章 NameNode和SecondaryNameNode
4.1 NN和2NN工作机制

1)第一阶段:NameNode启动
(1)第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode记录操作日志,更新滚动日志。
(4)NameNode在内存中对元数据进行增删改。
2)第二阶段:Secondary NameNode工作
(1)Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。
(2)Secondary NameNode请求执行CheckPoint。
(3)NameNode滚动正在写的Edits日志。
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint。
(7)拷贝fsimage.chkpoint到NameNode。
(8)NameNode将fsimage.chkpoint重新命名成fsimage。
4.2 Fsimage和Edits解析


4.3 oiv查看Fsimage文件
查看oiv和oev命令
[atguigu@hadoop102 current]$ hdfs
oiv apply the offline fsimage viewer to an fsimage
oev apply the offline edits viewer to an edits file
基本语法
# fsimage
hdfs oiv -p 文件类型 -i镜像文件 -o 转换后文件输出路径
# edits file
hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径4.4 CheckPoint时间设置
通常情况下,SecondaryNameNode每隔一小时执行一次。
[hdfs-default.xml]
<!-- 单位:秒 -->
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次。
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1分钟检查一次操作次数</description>
</property>
第5章 DataNode
5.1 DataNode工作机制
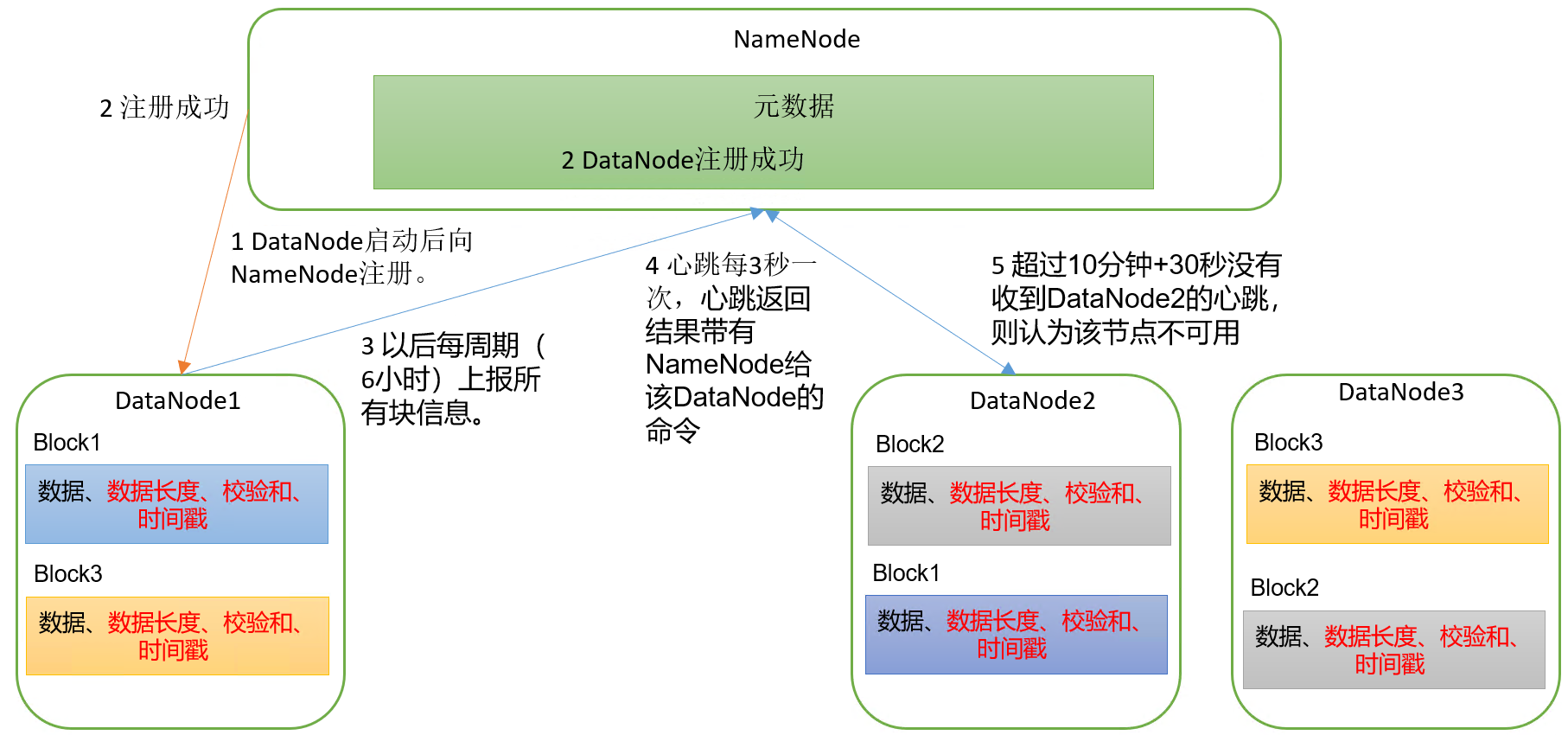
具体流程:
(1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
(2)DataNode启动后向NameNode注册,通过后,周期性(6小时)的向NameNode上报所有的块信息。
(3)心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟+30秒没有收到某个DataNode的心跳,则认为该节点不可用。
(4)集群运行中可以安全加入和退出一些机器。
5.2 DataNode 数据完整性
DataNode节点保证数据完整性的方法:
(1)当DataNode读取Block的时候,它会计算CheckSum。
(2)如果计算后的CheckSum,与Block创建时值不一样,说明Block已经损坏。
(3)Client读取其他DataNode上的Block。
(4)常见的校验算法crc(32),md5(128),sha1(160)。
(5)DataNode在其文件创建后周期验证CheckSum。
5.3 掉线时限参数设置
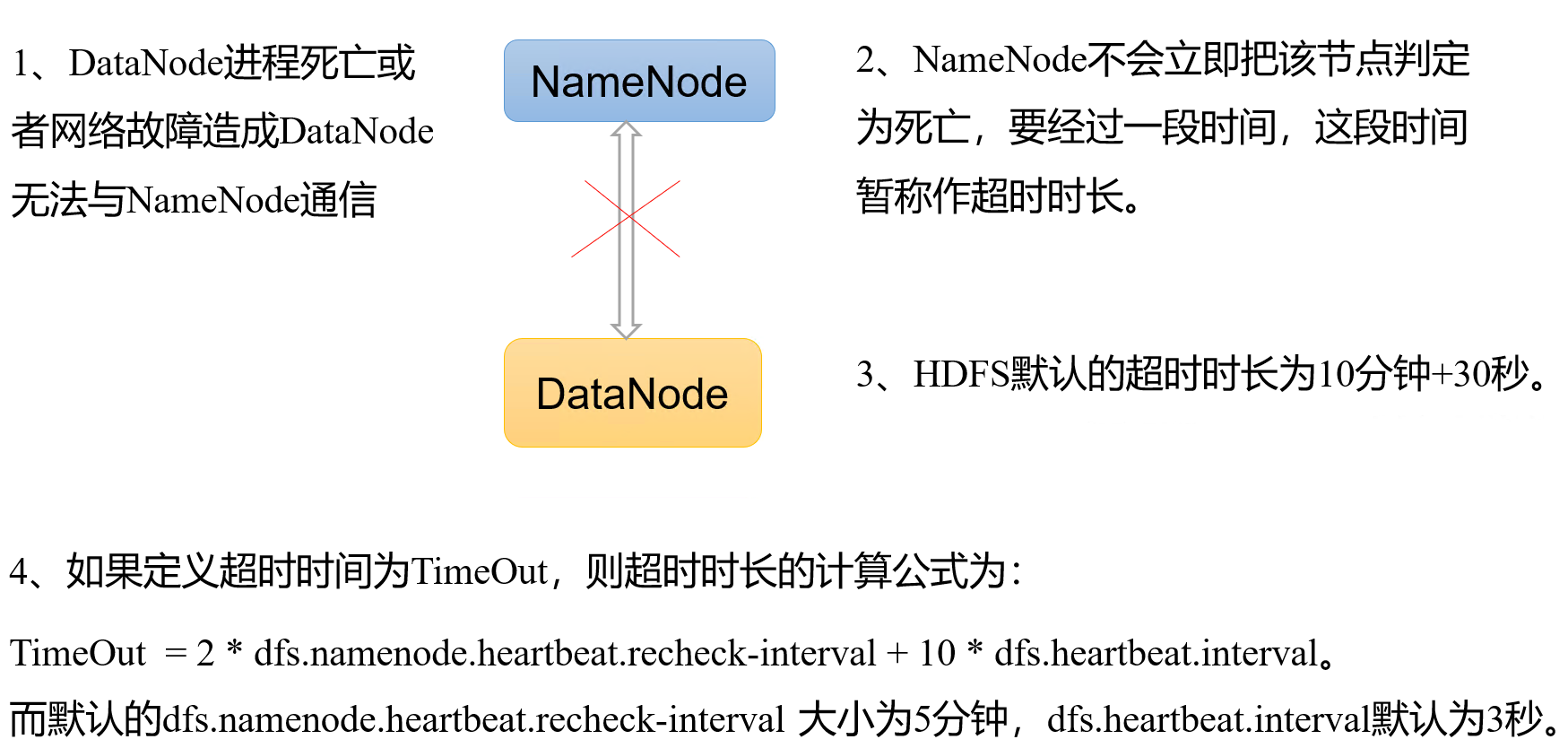
需要注意的是hdfs-site.xml 配置文件中的
heartbeat.recheck.interval的单位为毫秒,
dfs.heartbeat.interval的单位为秒。
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value>
</property>