Tarea extracurricular 2: Configuración del entorno Hadoop y HDFS
- Detalles del trabajo
contenido
- Alibaba Cloud-Yunqi Lab- "Construcción de un entorno Hadoop" -Hadoop-2.10.1 pseudodistribuido:
1. Tome una captura de pantalla de la dirección IP pública del ECS en este experimento y agregue una marca de cuadro de color, como se muestra en la siguiente figura: 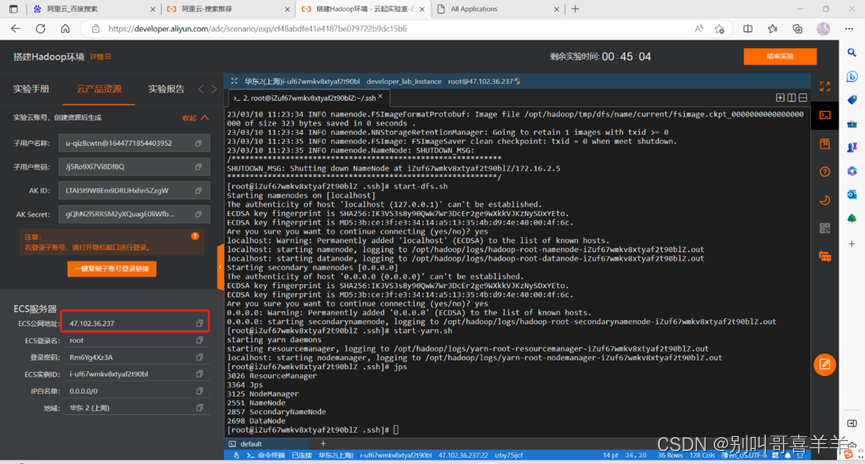 2. Paso 6. Después de iniciar Hadoop con éxito, tome una captura de pantalla y agregue una marca de cuadro de color. como se muestra en la siguiente figura.
2. Paso 6. Después de iniciar Hadoop con éxito, tome una captura de pantalla y agregue una marca de cuadro de color. como se muestra en la siguiente figura.
3. Cree una carpeta en el directorio raíz hdfs (nombre de la carpeta: su nombre y los últimos cuatro dígitos de su número de estudiante) 4. Cree un archivo debajo de la carpeta (nombre del archivo: su nombre y los últimos cuatro dígitos de su número de estudiante) number.txt) 5. Cargue el archivo de instalación de Hadoop en el directorio raíz de ECS a la carpeta creada por usted mismo en hdfs 6. Después de que la operación sea exitosa, tome una captura de pantalla y agregue una marca de cuadro de color, como se muestra en la siguiente figura :

- Huawei Cloud-Koolabs Cloud Experiment-Experiment "Archivo de escritura HDFS" Cambie el nombre del archivo de datos experimentales descargado 000000_0 a su nombre y empalme completamente los últimos cuatro dígitos de la identificación del estudiante. Después de ejecutar el programa Python al final del experimento, tome una captura de
 pantalla para ver el comando de contenido del archivo y mostrar los resultados.
pantalla para ver el comando de contenido del archivo y mostrar los resultados.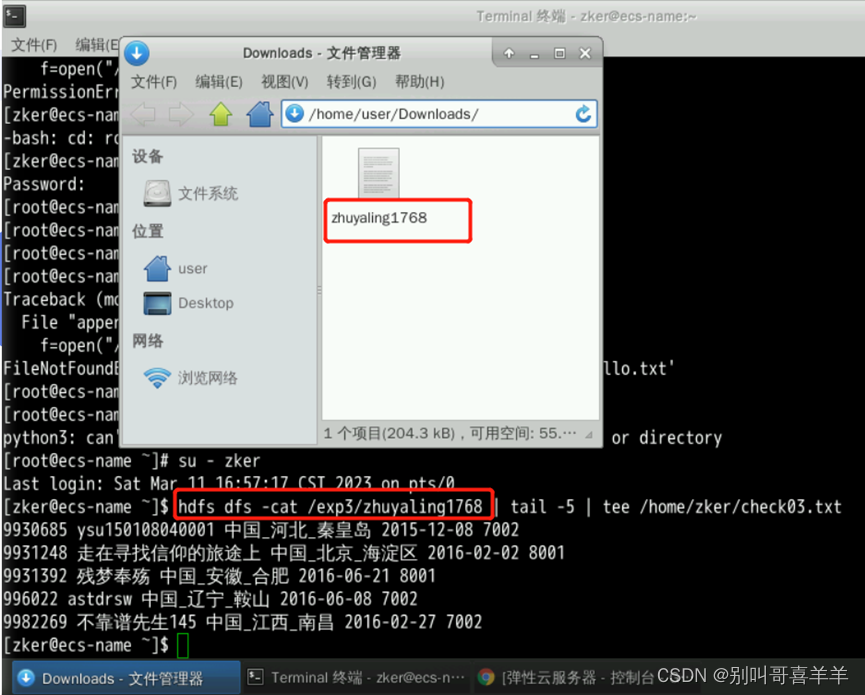
- Experimento "Archivos de lectura HDFS": el archivo txt check02 en el último paso del experimento se cambia a los últimos cuatro dígitos de su nombre y número de estudiante. Después de ejecutar el programa Python, tome una captura de pantalla del resultado de la ejecución.

- Responder brevemente al contenido de “Evaluación en el aula”
- ¿Cuáles son los modos para la instalación de Hadoop? ¿En qué modo está este experimento? ¿Es posible instalar otros modos?
Respuesta: Hay 4 modos para la instalación de Hadoop: modo de nodo único, modo pseudodistribuido, modo totalmente distribuido y modo de alta disponibilidad.
- ¿Por qué instalar JDK? ¿Dónde está la fuente de descarga? ¿Qué versión es? ¿Hay otras versiones disponibles? ¿Dónde está instalado?
Respuesta: Antes de instalar Hadoop, primero debe instalar JDK. Debido a que Hadoop se desarrolla en base a Java, JDK proporciona un entorno de compilación y el funcionamiento de Hadoop depende del entorno JDK.
- ¿ Dónde está la fuente de descarga de Hadoop ? ¿Qué versión es? ¿Hay otras versiones disponibles? ¿Dónde está instalado?
Respuesta: La fuente de descarga de Hadoop es el sitio web oficial de Apache. La última versión es Hadoop 2.7. También hay otras versiones disponibles, pero se recomienda utilizar la última versión. Hadoop se instala en una máquina, que puede ser una máquina física o una máquina virtual, que tiene la red y el entorno de usuario correctamente instalados y configurados.
- ¿Cuáles son las diferencias entre instalar JDK y Hadoop en Linux e instalar en Windows?
Respuesta: Instalar JDK y Hadoop en Linux es similar a instalarlo en Windows, excepto que Windows usa una interfaz GUI, mientras que Linux usa una interfaz de línea de comandos.
- ¿Para qué se utilizan las configuraciones de variables de entorno de JDK y Hadoop? ¿Qué archivos son? ¿Por qué necesitas la fuente después de la configuración?
Respuesta: Las variables de entorno de JDK y Hadoop deben configurarse en el archivo .bashrc. JDK debe configurarse con JAVA_HOME y Hadoop debe configurarse con HADOOP_HOME, HADOOP_PREFIX, etc. La configuración de estas variables de entorno permite a los usuarios llamar a Hadoop comandos desde cualquier directorio y ejecutarlos. La fuente se utiliza para hacer que las variables de entorno recién configuradas surtan efecto. Iniciará un nuevo shell. En el nuevo shell, las variables de entorno utilizarán la nueva configuración.
- ¿Qué archivos se deben configurar para la pseudodistribución de Hadoop ? ¿Cuales son las funciones?
Respuesta: La pseudodistribución de Hadoop requiere los siguientes tres archivos: core-site.xml, hdfs-site.xml y mapred-site.xml. core-site.xml se usa principalmente para configurar las propiedades globales de Hadoop, como las configuraciones específicas de Hadoop; hdfs-site.xml se usa principalmente para configurar las opciones de HDFS, como el espacio de nombres HDFS y el tamaño del bloque de almacenamiento; mapred-site.xml se utiliza principalmente para configurar Opciones para configurar MapReduce, como el número de puerto de JobTracker o la ruta relacionada del programa MapReduce.
- ¿Qué significa iniciar sesión sin contraseña? ¿Por qué configurar el inicio de sesión sin contraseña?
Respuesta: El inicio de sesión sin contraseña significa que puede iniciar sesión en un sistema Linux remoto sin ingresar un nombre de usuario y contraseña, lo que mejora la seguridad y la conveniencia del inicio de sesión remoto SSH. Para configurar el inicio de sesión sin contraseña, debe instalar ssh-keygen en el cliente y el servidor respectivamente, generar la clave pública y la clave privada en las dos máquinas y luego copiar la clave pública para lograr un inicio de sesión sin contraseña.
- ¿Qué nodos se pueden ver después de iniciar Hadoop? ¿Qué hacen?
Respuesta: Después de iniciar Hadoop, puede ver el nodo NameNode, el nodo DataNode y el nodo SecondaryNameNode. NameNode es el nodo de administración de HDFS, utilizado para registrar información de metadatos del sistema de archivos; los nodos DataNode son nodos que almacenan datos y almacenan datos cargados por los usuarios; el nodo SecondaryNameNode es responsable del trabajo de respaldo de NameNode, que es un nodo auxiliar. se utiliza para guardar una copia de imagen en memoria del sitio NameNode para una mejor tolerancia a fallas.
- ¿Para qué se utilizan las dos páginas web de Hadoop ?
Respuesta: Hadoop tiene dos páginas web, a saber, NameNode Web UI y JobTracker Web UI. La interfaz de usuario web NameNode se usa para ver el sistema de archivos, ver los nodos en el clúster y administrar los datos almacenados en el sistema de archivos; mientras que la interfaz de usuario web JobTracker se usa para ver el estado y la información de la tarea para facilitar el monitoreo de la ejecución. de la tarea.
- ¿Cuál es la diferencia entre el sistema de archivos de escritorio experimental y el sistema de archivos ECS? ¿A qué sistema de archivos descarga archivos el navegador? ¿Cómo transferir archivos entre los dos?
Respuesta: La diferencia entre el sistema de archivos de escritorio experimental y el sistema de archivos ECS es que el sistema de archivos de escritorio experimental se refiere al sistema de archivos local en el entorno de escritorio experimental, que se almacena en el disco duro local; mientras que el sistema de archivos ECS se refiere a el sistema de archivos en la instancia EMR, administrado por el sistema de archivos distribuido Hadoop HDFS, que se almacena en el disco duro de la instancia. El archivo de descarga del navegador se descarga en el sistema de archivos de escritorio experimental. Los archivos se pueden transferir entre los dos mediante el protocolo de transferencia de archivos FTP o el protocolo de transferencia segura de archivos SCP.
- ¿Cuál es la diferencia entre el sistema de archivos HDFS y el sistema de archivos local?
Respuesta: La diferencia entre el sistema de archivos HDFS y el sistema de archivos local es que HDFS es un sistema de archivos distribuido que puede admitir gran capacidad, alto rendimiento y confiabilidad, mientras que el sistema de archivos local se parece más a un sistema de archivos independiente con capacidad de almacenamiento y rendimiento. es inferior a HDFS.
- ¿Cuál es la diferencia entre los comandos de Hadoop y los comandos de Linux?
Respuesta: En comparación con los comandos de Linux, los comandos de Hadoop son más extensos y pueden realizar más operaciones, mientras que los comandos de Linux solo pueden realizar operaciones básicas, como ver directorios, crear archivos y ejecutar algunos comandos simples.
- ¿ Cómo crear archivos y carpetas en HDFS ? ¿Como revisar?
Respuesta: Para crear archivos y carpetas en HDFS, puede usar el comando hadoop fs -mkdir para crear carpetas y usar el comando hadoop fs -put para cargar archivos en HDFS; para ver archivos y carpetas, puede usar hadoop fs - Comando ls para ver los archivos en HDFS.Archivos y carpetas.
- ¿Cómo descargar archivos de HDFS a local? ¿Cuál es el orden? ¿Describe brevemente el principio? ¿Cuáles son los flujos y métodos clave de entrada y salida de Java?
Respuesta: El comando para descargar archivos de HDFS al local es hadoop fs -get. El principio es llamar a la API java de hadoop para obtener los archivos en el sistema de archivos remoto. Los flujos y métodos clave de entrada y salida son leer el archivo de HDFS en el InputStream y escribir el archivo en el OutputStream local para realizar la descarga del archivo.
- ¿Cómo cargar archivos locales a HDFS? ¿Cuál es el orden? ¿Describe brevemente el principio? ¿Cuáles son las funciones y flujos de entrada y salida clave de Java?
Respuesta: El comando para cargar archivos locales en HDFS es hadoop fs -put. El principio es llamar a la API java de hadoop para cargar archivos al sistema de archivos remoto. Los flujos y métodos clave de entrada y salida son leer archivos del InputStream local y escribir los archivos en el OutputStream de HDFS para lograr la carga de archivos.
- En el experimento "Archivos de escritura HDFS", ¿qué función utiliza Python para escribir en HDFS? ¿Dónde fue escrito?
Respuesta: En el experimento "Escritura de archivos HDFS", la función utilizada por Python para escribir en HDFS es hdfs3.HDFile, que escribirá archivos en HDFS.
- En el experimento "Lectura de archivos HDFS", ¿cuál es la función que utiliza Python para crear un flujo de entrada HDFS? ¿Dónde se lee el contenido del archivo desde la salida HDFS?
Respuesta: En el experimento "Lectura de archivos HDFS", la función de Python para crear el flujo de entrada HDFS es hdfs3.HDFile, y el contenido del archivo leído desde HDFS se enviará al objeto HDFile.
- ejercicio
- Describa la relación entre Hadoop y MapReduce, GFS y otras tecnologías de Google.
Respuesta: Hadoop es una implementación de código abierto de las tecnologías MapReduce y GFS (sistema de archivos distribuidos) de Google. Hadoop implementa la arquitectura informática y de almacenamiento distribuido de Google.
- Describir las características de Hadoop.
Respuesta: Hadoop tiene las características de alta escalabilidad, alta tolerancia a fallas y administración eficiente de la capacidad.
- Analicemos la aplicación de Hadoop en varios campos.
Respuesta: Actualmente, Hadoop se utiliza ampliamente en muchos campos, como los negocios, las finanzas, la atención médica y la educación, y puede reducir en gran medida el tiempo y los costos de procesamiento de datos, ahorrar costos laborales, mejorar el nivel de procesamiento de datos de las empresas y liberar su valor.
- Describir el ecosistema Hadoop y las funciones específicas de cada parte.
Respuesta: El ecosistema Hadoop incluye HDFS (sistema de archivos distribuido), MapReduce (marco informático distribuido), YARN (administrador de recursos de clúster), Hive (almacén de datos), HBase (base de datos distribuida NoSQL), ZooKeeper (servicio de coordinación), etc. Las funciones son: proporcionar un sistema de almacenamiento altamente confiable, implementar un marco informático, administrar los recursos del clúster, proporcionar un almacén de datos, proporcionar una base de datos distribuida NoSQL y coordinar la comunicación entre los nodos del clúster.
- Al configurar Hadoop, ¿en qué archivo de configuración se establece la ruta Java JAVAHOME?
Respuesta: La ruta JAVAHOME de Java se establece en el archivo de configuración hadoop-env.sh.
- Todas las rutas HDFS se configuran a través de fs.default.name ¿En qué archivo de configuración se configura?
Respuesta: Todas las rutas HDFS se configuran en core-site.xml hasta fs.default.name.
- Intente enumerar las similitudes y diferencias entre el modo autónomo y el modo pseudodistribuido.
Respuesta: Las similitudes y diferencias entre el modo independiente y el modo pseudodistribuido: ambos son modelos informáticos de Hadoop, en los que se puede utilizar el marco informático MapReduce proporcionado por Hadoop; ambos pueden utilizar el sistema de almacenamiento distribuido HDFS proporcionado por Hadoop. para almacenar grandes cantidades de datos; diferencias: el modo independiente solo requiere una máquina, mientras que el modo pseudodistribuido requiere al menos dos máquinas, y debe haber suficientes conexiones de red entre las dos máquinas para garantizar que los datos y las tareas se puedan transmitir normalmente ; en modo independiente, mantendrá un clúster HDFS y un clúster MapReduce, y en modo pseudodistribución, mantendrá un clúster HDFS y múltiples clústeres MapReduce; el modo independiente solo admite trabajos de MapReduce en una sola máquina, mientras El modo pseudodistribuido admite la distribución de datos en varias máquinas Trabajo MapReduce; el modo de una sola máquina solo puede usar los recursos de una sola máquina para procesar datos, mientras que el modo pseudodistribuido puede usar los recursos de varias máquinas para procesar datos , logrando así un mejor rendimiento.
- ¿Cuáles son los procesos que tiene Hadoop después de que se inicia la operación pseudodistribuida?
Respuesta: Los procesos que tiene Hadoop después de iniciar la operación pseudodistribuida son: proceso NameNode, proceso SecondaryNameNode, proceso DataNode, proceso ResourceManager, proceso NodeManager y proceso JobHistoryServer.
- Si tiene las condiciones para el experimento de clúster, intente crear un entorno de clúster Hadoop completamente distribuido de acuerdo con la documentación oficial de Hadoop.
- ejercicio
- Describir los requisitos para el diseño de sistemas de archivos distribuidos.
Respuesta: Debe poder utilizar diferentes tipos de sistemas de archivos, admitir múltiples tipos de operaciones de lectura y escritura de archivos, el sistema debe ser fácil de expandir y mantener, tener un mecanismo de recuperación para errores de nodos de almacenamiento, admitir administración de permisos y admitir múltiples protocolos de red., la seguridad debe garantizarse hasta cierto punto y se debe admitir la transmisión de archivos de red y del disco duro.
- ¿Cómo logra un sistema de archivos distribuido una expansión de nivel superior?
Respuesta: La tecnología de almacenamiento distribuido se utiliza para almacenar datos de manera descentralizada. El sistema de archivos distribuido utiliza múltiples servidores de datos para lograr una expansión horizontal y distribuir datos a múltiples servidores de datos al mismo tiempo, lo que aumenta la flexibilidad del servidor y mejora la eficiencia del almacenamiento. Además, el sistema de archivos distribuido también puede lograr una expansión horizontal a través de la tecnología de almacenamiento en caché distribuido y la tecnología de equilibrio de carga de red.
- Describa la diferencia entre bloques en HDFS y bloques en sistemas de archivos normales.
Respuesta: Bloques en HDFS: el bloque de almacenamiento de HDFS es de 64 M, que es la unidad de almacenamiento interna de HDFS. Todos los archivos deben subdividirse en bloques de almacenamiento de 64 M para lograr la replicación y el almacenamiento de datos. Bloques en sistemas de archivos ordinarios: los bloques son las unidades de lectura y escritura más pequeñas de los sistemas de archivos. Generalmente, el tamaño de los bloques de almacenamiento en los sistemas de archivos ordinarios es menor que el de HDFS, generalmente entre 4 KB y 8 KB.
- Describir las funciones específicas de los nodos de nombres y de datos en HDFS.
Respuesta: El nodo de nombre en HDFS es el núcleo de todo el clúster. Almacena los metadatos de todos los archivos, es responsable de administrar las actualizaciones y consultas de metadatos y también es responsable del control de acceso a los archivos. También es responsable de la asignación y administración. de bloques de datos, lo que permite a los nodos cargar y descargar datos, es responsable de copiar y verificar bloques de datos, también es responsable de monitorear y administrar todo el sistema de archivos HDFS y puede monitorear el estado de ejecución de todo HDFS. El nodo de datos HDFS es responsable de procesar las solicitudes de lectura y escritura del cliente, dividir los archivos enviados por el cliente en bloques de almacenamiento, guardar los datos en cada bloque de almacenamiento localmente y copiar estos bloques de almacenamiento en varios bloques de almacenamiento especificados por el nodo de nombre. Nodos de datos para almacenamiento redundante. El nodo de datos también es responsable de verificar los bloques de almacenamiento almacenados localmente. Si se encuentra un bloque de almacenamiento dañado, se marcará como no válido y se volverá a copiar desde el local.
- En un sistema de archivos distribuido, el diseño del nodo central es crucial. Explique cómo HDFS reduce la carga sobre el nodo central.
Respuesta: HDFS adopta un modelo cliente / servidor: su cliente puede consultar la información del nodo de nombre y obtener información del nodo de datos del nodo de nombre, lo que reduce la carga sobre el nodo central. Además, existen algunas formas de reducir la carga sobre el nodo de nombre: si hay un nodo de falla inaccesible, el administrador del nodo puede verificar el estado del nodo de datos de forma asincrónica desde una ubicación remota, lo que puede reducir la carga sobre el nodo de nombre. .
- HDFS solo configura un nodo de nombre único, lo que simplifica el diseño del sistema pero también trae algunas limitaciones obvias. Explique los aspectos específicos de las limitaciones.
Respuesta: En primer lugar, debido a que solo hay un nodo de nombre, su disponibilidad es limitada. Si el nodo de nombre falla, todo el sistema no funcionará. En segundo lugar, el nodo de nombre almacena los metadatos de todos los archivos en el clúster, por lo que su carga de procesamiento es pesado, y posteriormente A medida que el sistema de archivos continúa creciendo, las capacidades de procesamiento del nodo de nombre pueden ser limitadas.
- Describa la estrategia de almacenamiento de datos redundantes de HDFS.
Respuesta: La estrategia de almacenamiento de datos redundantes de HDFS es copiar un bloque de datos a múltiples nodos de datos, con tres copias por defecto. De esta manera, incluso si un nodo falla, podemos recuperar datos de otros nodos, y esta estrategia de preservación puede reducir efectivamente el punto único de falla del sistema.
- La replicación de datos debe ocurrir durante la escritura y recuperación de datos. La replicación de datos HDFS utiliza una estrategia de replicación de canalización. Por favor, detalle los detalles de esta estrategia.
Respuesta: La replicación de datos HDFS utiliza una estrategia de replicación de canalización, que se refiere a copiar un fragmento de datos (archivo) a un conjunto de nodos DataNode conocidos. El factor de replicación predeterminado es 3, es decir, cada copia de datos se escribirá en 3 nodos DataNode. HDFS dividirá secuencialmente estos datos en varios bloques, escribirá estos bloques por separado en el nodo DataNode e inmediatamente comenzará a escribir el siguiente bloque hasta que se hayan escrito todos los bloques. Esto puede mejorar en gran medida la eficiencia de transmisión de la replicación de datos y utilizar eficazmente el ancho de banda de la red para transmitir grandes cantidades de datos.
- Describa cómo HDFS detecta errores y cómo recuperarlos.
Respuesta: HDFS utilizará el mecanismo Heartbeat y el mecanismo Blockreport para detectar fallas en los nodos de datos. Cuando el NameNode recibe la información Heartbeat del DataNode, significa que el bloque en el nodo DataNode no ha fallado; y cuando el NameNode no recibe la Información de latido del DataNode Información de latido, el NameNode pensará que el DataNode ha fallado y luego emitirá un comando de recuperación para restaurar los datos dañados.
- Explique el proceso de lectura de archivos HDFS sin fallas.
Respuesta: Primero, el cliente inicia una solicitud de lectura de datos al NameNode. Después de que el NameNode la reciba, devolverá el nodo DataNode donde se encuentran los datos; después de que el NameNode establezca la conexión, el cliente extraerá el bloque de datos del DataNode. hasta que se complete la extracción; el cliente extrae Los datos obtenidos también verificarán la integridad de los datos. Si se encuentra que los datos están incompletos, el cliente volverá a solicitar nuevos bloques de datos del NameNode hasta que los bloques de datos válidos se extraigan con éxito y finalmente se extraerán los múltiples bloques de datos y se combinarán en un solo documento.
- Explique el proceso mediante el cual HDFS escribe archivos sin fallas.
Respuesta: Primero, el cliente inicia una solicitud de escritura de archivo al NameNode. Después de que el NameNode la reciba, responderá a múltiples nodos de DataNode disponibles; después de que el NameNode establezca la conexión, el cliente dividirá el archivo en bloques y copiará cada parte de datos, y en cada nodo Escriba en el nodo DataNode hasta que se escriban todos los bloques y se complete la escritura; luego el cliente enviará una señal al NameNode para confirmar que la escritura se completó, y el NameNode registrará la ubicación del archivo y bloques de contenido del archivo en los metadatos después de recibirlo.
- ejercicio
- Hablemos de los dos aspectos principales de la optimización y el desarrollo de Hadoop después de su lanzamiento.
Respuesta: La optimización y el desarrollo de Hadoop se reflejan principalmente en los dos aspectos siguientes: 1. Optimización de la arquitectura: en el proceso de desarrollo de la arquitectura Hadoop, desde la arquitectura de punto único de la versión original de HDFS hasta la arquitectura HDFS HA, las ventajas La arquitectura multipunto puede aliviar efectivamente el nombre de punto único de falla del nodo, desarrollándose desde la arquitectura de un solo punto de MapReduce1.0 hasta la arquitectura multipunto de MapReduce2.0 y YARN. reducir la ocupación de recursos y mejorar la escalabilidad y expansibilidad del sistema. 2. Optimización del sistema: Hadoop también optimiza constantemente las estrategias de programación interna, como HDFS, MapReduce, Spark, etc., para lograr una ejecución de tareas más rápida y eficiente, utilizar menos recursos y poder expandirse a una escala mayor.
- Analicemos los problemas causados por incluir solo un nodo de nombre en HDFS1.0.
Respuesta: 1. Punto único de falla: solo hay un nodo de nombre. Una vez que ocurre una falla, es posible que todo el sistema no pueda funcionar normalmente e incluso pueden ocurrir problemas como la pérdida de datos. 2. Baja utilización de recursos: debido a la arquitectura de punto único, los recursos del sistema no se pueden utilizar de manera efectiva, lo que hace que todo el sistema sea ineficiente.
- Describa los componentes de la arquitectura HA de HDFS y sus funciones específicas.
Respuesta: 1. Servicio NameNode: responsable del control de acceso a los datos, como el control de lectura y escritura de archivos por parte del usuario y la ubicación de almacenamiento de bloques de datos. 2. Servicio DataNode: responsable del procesamiento y almacenamiento de datos reales, así como de informes de latidos, etc. 3. Servicio JournalNode: Responsable de almacenar el estado activo de NameNode en uno o más servidores y sincronizar las operaciones entre NameNodes.
- Analice cómo los nodos de datos mantienen la comunicación con los nodos de nombres en la arquitectura HA de HDFS.
Respuesta: En la arquitectura HA de HDFS, se utilizará un determinado protocolo para comunicarse entre el nodo de datos y el nodo de nombre. Por ejemplo, el nodo de datos utilizará Heartbeat para confirmar si el proceso actual está activo; el nodo de nombre utilizará la transmisión de red. Tecnología para cargar bloques de datos y metadatos. La información de datos se proporciona a los nodos de datos.
- Explique por qué se necesita la federación HDFS y qué problemas puede resolver.
Respuesta: La federación HDFS es una arquitectura distribuida para servicios HDFS, que consta de múltiples NameNodes y DataNodes independientes. Puede reducir eficazmente el riesgo de puntos únicos de falla, al tiempo que proporciona a los usuarios más espacio disponible, mejorando la escalabilidad del sistema y la escalabilidad para satisfacer las necesidades de los usuarios.
- Describa el concepto de "grupo de bloques" en la federación HDFS y analice por qué la falla de un nodo de nombre en la federación HDFS no afectará los nodos de datos relacionados con él para continuar brindando servicios a otros nodos de nombre.
Respuesta: El "grupo de bloques" en la federación HDFS se refiere al número máximo de bloques de datos que cada nodo de datos puede almacenar. Su función es administrar mejor el espacio de almacenamiento de los bloques de datos. Se puede configurar para diferentes tamaños según el tamaño de el grupo de bloques. El DataNode asigna diferente espacio de almacenamiento de bloques de datos. Cuando un NameNode falla, su DataNode relacionado puede continuar brindando servicios a otros NameNodes, haciendo que todo el sistema tenga una mayor disponibilidad.
- Explique los problemas existentes en la arquitectura MapReduce1.0.
Respuesta: 1. Baja utilización de recursos: MapReduce1.0 no tiene recursos redundantes para utilizar, por lo que la utilización de recursos no es alta y lleva más tiempo 2. Escala limitada: la arquitectura de un solo punto es limitada y la arquitectura MapReduce1.0 es limitada No se puede expandir y continúa siendo limitado 3. Mecanismo de recolección de basura poco amigable: MapReduce 1.0 no tiene un buen mecanismo de recolección de basura, lo que genera desperdicio de recursos, fallas del sistema y otros problemas.
- Describa las funciones de cada componente en la arquitectura YARN.
Respuesta: 1. ResourceManager: responsable de administrar los recursos del clúster, programar aplicaciones y actualizar el estado en tiempo real. 2. NodeManager: responsable de administrar y monitorear los recursos del nodo, incluida la memoria, el disco y la red. 3. ApplicationMaster: responsable de gestionar la asignación y programación de recursos de los nodos, proporcionando una capa de abstracción para la gestión de recursos.
- Describa los pasos específicos desde el envío hasta la finalización al ejecutar un programa MapReduce en el marco YARN.
Respuesta: 1. El usuario envía el programa MapReduce a ResourceManager. 2. ResourceManager asigna el trabajo a ApplicationMaster. 3. ApplicationMaster extrae el paquete Jar del programa y lo divide en múltiples subtareas según el trabajo. 4. ApplicationMaster inicia una solicitud a NodeManager para solicitar recursos. 5. NodeManager extrae el programa Jar e inicia la tarea. 6. Después de completar cada tarea, ApplicationMaster notifica a ResourceManager que el trabajo se completó.
- Realice un análisis comparativo de las ventajas y desventajas de los marcos YARN y MapReduce1.0.
Respuesta: Ventajas: 1. YARN tiene una mayor escalabilidad horizontal y puede admitir la operación de más nodos y procesar más trabajos. 2. La gestión de recursos de YARN es más flexible y puede utilizar mejor los recursos del sistema. 3. YARN puede admitir más modelos de programación, como Tez, Spark, Kafka, etc. Desventajas: 1. El marco YARN es más complejo que el marco MapReduce1.0 en términos de asignación y programación de recursos. 2. La eficiencia operativa y el rendimiento del marco YARN son inferiores a los del marco MapReduce1.0.
- Describa las funciones de Pig Tez y Kafka respectivamente. Respuesta: 1. Pig Tez: Pig Tez es un mecanismo para acelerar el procesamiento de datos de Pig. Puede utilizar la arquitectura de Apache Tez para crear un gráfico de tareas, que puede combinar varios trabajos y usarse para combinar algunos trabajos livianos. 2. Kafka: Kafka es un sistema distribuido de mensajería de publicación y suscripción. Al mantener un clúster de gran capacidad, puede admitir millones de suscripciones de mensajes, admite un alto rendimiento y baja latencia y se puede utilizar a gran escala. Recopilación, agregación y Procesando;