Big Data (4) Tecnología convencional de Big Data
1. Las palabras escritas delante

A esas buenas chicas (buenos chicos) que son torturados y golpeados:
Hay algunas cosas que no podemos elegir y no podemos evitar que nos lastimen.
Pero recuerda en todo momento:
Puede que no valgas nada delante de algunas personas y que te lastimen gravemente.
Pero definitivamente será un tesoro invaluable en los corazones de otras personas, y él (ella) te considerará más importante que él mismo.
Simplemente sé tú mismo, no es necesario que cambies nada deliberadamente, las personas que te aman naturalmente te amarán.
¡Recuerda tu valor! ¡Vives en tu propio mundo, en los corazones de quienes te aman!
Sobrio en la adversidad
2023.8.27

2. Tecnología de grandes datos
Las tecnologías convencionales de big data se pueden dividir en dos categorías.
Un tipo está orientado a escenarios comerciales de procesamiento por lotes no en tiempo real , centrándose en el procesamiento, almacenamiento, procesamiento, análisis y aplicaciones de datos masivos a nivel TB y PB que las tecnologías tradicionales de procesamiento de datos no pueden manejar en un entorno de espacio-tiempo limitado. Tales como: análisis del comportamiento del usuario, análisis antifraude de pedidos, análisis de pérdida de usuarios, almacén de datos, etc. Las características de dichos escenarios comerciales son la respuesta no en tiempo real. Por lo general, algunas unidades extraen todo tipo de datos en la plataforma de análisis de big data al final de las operaciones nocturnas, obtienen los resultados del cálculo en unas pocas horas y los utilizan para las operaciones del día siguiente. Las principales tecnologías de soporte son HDFS, MapReduce, Hive, etc.
Otro tipo de escenarios comerciales para procesamiento en tiempo real , como aplicaciones Weibo, redes sociales en tiempo real, procesamiento de pedidos en tiempo real, etc. Este tipo de escenarios comerciales se caracteriza por una fuerte respuesta en tiempo real. solicitud, se debe dar una respuesta en unos pocos segundos y garantizar la integridad de los datos. Las tecnologías de soporte más convencionales son HBase, Kafka, Storm, etc.
(1) HDFS

HDFS se refiere al sistema de archivos distribuido Hadoop (Sistema de archivos distribuido Hadoop), que es el componente central del proyecto Apache Hadoop. Es un sistema de archivos distribuido con alta disponibilidad, alta confiabilidad, alta escalabilidad y alta tolerancia a fallas. Puede almacenar y procesar conjuntos de datos a gran escala en un grupo de computadoras económicas y realizar el procesamiento paralelo de datos a gran escala mediante la distribución de datos y tareas informáticas entre múltiples nodos.
HDFS es el subproyecto central de Hadoop y la base para el almacenamiento y acceso a datos de toda la plataforma Hadoop. Basado en el sistema de archivos del sistema de archivos nativo de Linux. Además de esto, alberga el funcionamiento de otros subproyectos como MapReduce y HBase. Es un sistema de archivos distribuido que es fácil de usar y administrar.
HDFS es un sistema altamente tolerante a fallas adecuado para implementar en máquinas económicas. HDFS puede proporcionar acceso a datos de alto rendimiento y es muy adecuado para aplicaciones en conjuntos de datos a gran escala. HDFS relaja algunas restricciones POSIX para lograr el propósito de transmitir datos del sistema de archivos.
La tecnología HDFS tiene las siguientes características:
1. Almacenamiento a gran escala: HDFS puede manejar conjuntos de datos a gran escala a nivel de PB y admite el almacenamiento distribuido y la gestión de archivos de datos.
2. Alta confiabilidad: HDFS es un método de almacenamiento de datos basado en redundancia, que distribuye datos a diferentes nodos, y el tiempo de inactividad de cualquier servidor no afectará la integridad y disponibilidad de los datos.
3. Alta escalabilidad: HDFS puede ejecutarse en cientos de máquinas, admite expansión dinámica y es conveniente para los usuarios expandirse con el crecimiento del volumen de datos.
4. Alta tolerancia a fallas (tolerante a fallas): HDFS logra tolerancia a fallas de datos a través de múltiples copias de bloques de datos. Si un nodo deja de funcionar, otros nodos pueden continuar brindando servicios de datos.
5. Eficiencia: HDFS admite la lectura y escritura de datos por lotes, proporciona un mecanismo de transmisión de datos eficiente y puede realizar una transmisión y procesamiento de datos rápidos en el clúster.6. Alto rendimiento
7.HDFS relaja (relaja) los requisitos de POSIX (requisitos) para que se pueda acceder a los datos en el sistema de archivos en forma de flujo (acceso de transmisión).
En resumen, la tecnología HDFS es una de las tecnologías necesarias para realizar el almacenamiento, la gestión y el procesamiento de big data y puede proporcionar soluciones de almacenamiento de datos eficientes y confiables para empresas de diferentes industrias.
(2)MapaReducir

MapReduce es una arquitectura de software que procesa cantidades masivas de datos de manera informática paralela en un clúster compuesto por miles de hardware ordinario. Este marco informático tiene alta estabilidad y tolerancia a fallas. MapReduce reduce en gran medida la lógica responsable, que se abstrae en las clases Mapper y Reducer. La lógica compleja se transforma en un patrón que se ajusta al procesamiento de funciones de MapReduce mediante la comprensión.
Un trabajo MapReduce divide el conjunto de datos de entrada en bloques informáticos independientes, y estos bloques son procesados por tareas de mapas en un modo completamente paralelo e independiente. El marco MapReduce ordena la salida de los mapas y, después de ordenarlos, los datos se utilizan como datos de entrada de la tarea de reducción. Tanto los datos de entrada como los de salida de un trabajo se almacenan en el sistema de archivos HDFS. El marco informático gestiona la programación de trabajos, monitorea los trabajos y vuelve a ejecutar las tareas fallidas.
MapReduce es un marco informático distribuido para el procesamiento de datos a gran escala.
La arquitectura del software MapReduce se puede dividir en los siguientes tres niveles :
♦ Capa de aplicación: los desarrolladores de aplicaciones MapReduce utilizan la API MapReduce para escribir aplicaciones, descomponiendo el problema en tareas individuales que se pueden procesar en paralelo. Estas tareas se dividen en dos etapas: etapa de mapa y etapa de reducción. En la etapa de mapa, los datos se dividen en partes pequeñas y se procesan como pares clave-valor, y luego los datos procesados se agrupan y fusionan de acuerdo con la clave. y finalmente se generan los datos deseados resultado deseado.
♦ Capa informática: el clúster informático de MapReduce consta de dos tipos de nodos: un nodo maestro y un grupo de nodos trabajadores. El nodo maestro es responsable de coordinar todo el proceso informático, incluida la división de tareas, el seguimiento de los nodos trabajadores y la transmisión de datos. Los nodos trabajadores ejecutan las tareas que se les asignan y devuelven los resultados al nodo maestro. Cada nodo en la capa informática es una computadora física o una máquina virtual, y todos pueden comunicarse en todo el sistema.
♦ Capa de almacenamiento: la capa de almacenamiento de MapReduce utiliza el sistema de archivos distribuido Hadoop (HDFS) para almacenar grandes cantidades de datos. HDFS es un sistema de archivos escalable y tolerante a fallas que puede replicar datos en diferentes nodos para garantizar la confiabilidad de los datos. HDFS proporciona métodos eficientes de gestión y almacenamiento de datos para MapReduce.
Los anteriores son los tres niveles de la arquitectura del software MapReduce. MapReduce permite el procesamiento eficiente de datos a gran escala al dividirlos en partes pequeñas y distribuir tareas entre nodos informáticos.
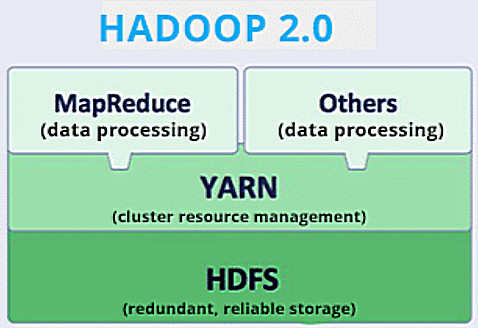
(3) HILO

Apache Hadoop YARN (Yet Another Resource Negotiator, otro coordinador de recursos) es un nuevo marco de gestión de recursos y programación de aplicaciones evolucionado a partir de Hadoop 0.23. Basado en YARN se pueden ejecutar varios tipos de aplicaciones, como MapReduce, Spark, Storm, etc. YARN ya no administra aplicaciones específicamente: la administración de recursos y la administración de aplicaciones son dos módulos poco acoplados.
En cierto sentido, YARN es un sistema operativo en la nube (Cloud OS). Basado en este sistema operativo, los programadores pueden desarrollar una variedad de aplicaciones, como programas MapReduce de procesamiento por lotes, programas Spark y programas Storm de trabajos de transmisión. Estas aplicaciones pueden utilizar simultáneamente los recursos de datos y los recursos informáticos del clúster Hadoop.
YARN (Yet Another Resource Negotiator) es un administrador de recursos en el ecosistema Hadoop. Su función principal es administrar y programar los recursos del clúster de manera unificada, asignar recursos del clúster para múltiples aplicaciones y mejorar la utilización de recursos de los clústeres de Hadoop. Como componente importante de Hadoop 2.0, YARN amplía enormemente los escenarios de aplicación de Hadoop y admite múltiples modelos informáticos, incluidos MapReduce, Spark y Storm.
Las principales funciones de YARN incluyen:
1. Gestión de recursos: YARN puede gestionar los recursos de diferentes nodos en el clúster y asignar recursos a diferentes aplicaciones para garantizar el funcionamiento normal de las aplicaciones.
2. Gestión de programación: YARN puede programar los recursos del clúster de acuerdo con las políticas y reglas especificadas de acuerdo con los requisitos de diferentes aplicaciones, y garantizar el intercambio justo de recursos entre las aplicaciones.
3. Gestión de aplicaciones: YARN puede gestionar automáticamente el ciclo de vida de las aplicaciones, incluidas operaciones como el inicio, la supervisión, el reinicio y el cierre de las aplicaciones.
4. Gestión de seguridad: YARN puede proporcionar potentes funciones de gestión de seguridad, incluida la autenticación de usuarios, la autorización y el cifrado de datos, para garantizar la seguridad y estabilidad del clúster.
En resumen, como componente importante del ecosistema Hadoop, YARN proporciona funciones confiables de gestión y programación de recursos para el funcionamiento de múltiples aplicaciones, y se usa ampliamente en diversas industrias, como Internet, finanzas y atención médica.
(4)HBase

HBase es una importante base de datos no relacional en la plataforma Hadoop y puede admitir capacidades de procesamiento y almacenamiento de datos a nivel de PB mediante una implementación escalable lineal.
Como base de datos no relacional, HBase es adecuada para el almacenamiento de datos no estructurados y su modo de almacenamiento se basa en columnas.
HBase es una base de datos NoSQL distribuida de código abierto. En el ecosistema Hadoop, es uno de los componentes de la base de datos Hadoop, MapReduce y HDFS. Basado en el artículo BigTable de Google, HBase es una base de datos altamente confiable, escalable y de alto rendimiento diseñada para ejecutarse en conjuntos de datos a gran escala. HBase tiene las siguientes características:
Utiliza grupos de columnas como unidad de almacenamiento básica y admite columnas dinámicas.
Admite partición automática, equilibrio de carga automático y conmutación por error automática.
Admite datos semiestructurados y datos no estructurados, no hay modo de tabla fija.
Admite operaciones de lectura y escritura altamente simultáneas, datos de múltiples versiones, compresión de datos y almacenamiento en caché de datos.
HBase es altamente escalable y puede admitir cientos de miles de millones de filas de datos, cada fila puede tener decenas de miles de columnas.
HBase se usa comúnmente para almacenar datos semiestructurados, como registros, datos de redes sociales, datos de sensores, datos de red, imágenes y audio, etc. Puede ajustar dinámicamente la capacidad de almacenamiento y procesamiento según las necesidades y puede realizar consultas y análisis de conjuntos de datos a gran escala, lo cual es una opción ideal para procesar big data.
(5) colmena

Apache Hive es un almacén de datos construido sobre la arquitectura Hadoop. Puede proporcionar refinamiento, consulta y análisis de datos. Apache Hive fue desarrollado originalmente por Facebook y actualmente otras empresas utilizan y desarrollan Apache Hive, como Netflix.
Hive es un marco de código abierto de la Fundación Apache. Es una herramienta de almacenamiento de datos basada en Hadoop. Puede asignar archivos de datos estructurados a una tabla de almacenamiento de datos y proporcionar funciones de consulta SQL (lenguaje de consulta estructurado) simples. Las declaraciones se convierten en tareas de MapReduce. correr.
El uso de Hive puede satisfacer las necesidades de algunos administradores de bases de datos que no comprenden MapReduce pero entienden SQL, para que puedan utilizar la plataforma de análisis de big data sin problemas.
Hive es una herramienta de almacenamiento de datos basada en Hadoop. Es una infraestructura de almacenamiento de datos que puede asignar archivos de datos estructurados a una tabla de base de datos y proporciona un conjunto de lenguaje de consulta similar a SQL HiveQL para consultar datos. Hive está diseñado para facilitar el procesamiento de grandes conjuntos de datos a los desarrolladores de SQL. Puede convertir la sintaxis similar a SQL en tareas de MapReduce para su ejecución a través de HQL, utilizando así clústeres de Hadoop para procesar datos masivos.
Hive admite múltiples fuentes de datos, incluidos HDFS, HBase y sistemas de archivos locales. Puede almacenar datos masivos a través de formatos de almacenamiento de datos integrados, como texto, serialización, ORC, etc., y proporciona funciones como compresión de datos, partición de datos y depósitos de datos para optimizar el rendimiento.
Hive tiene una buena escalabilidad y ecosistema, puede extender funciones a través de UDF (función definida por el usuario) y UDAF (función agregada definida por el usuario), y admite la integración de muchas herramientas de terceros, como JDBC, ODBC, Tableau, etc. .
En resumen, Hive es una potente herramienta de almacenamiento de datos que tiene un gran valor práctico para escenarios que necesitan procesar grandes cantidades de datos.
(6)Kafka

Apache Kafka es un sistema de mensajería distribuido de "publicación-suscripción", desarrollado originalmente por LinkedIn y luego se convirtió en un proyecto de Apache. Kafka es un servicio de registro de confirmación rápido, escalable e inherentemente distribuido, particionado y replicado por diseño.
Kafka es un sistema distribuido que es fácil de escalar. Puede proporcionar un alto rendimiento para la publicación y la suscripción, y admite múltiples suscriptores. Cuando falla, puede equilibrar automáticamente a los consumidores. Los negocios en tiempo real también pueden orientarse a negocios en tiempo real. .
Apache Kafka es una plataforma de procesamiento de flujo distribuido desarrollada por Apache Software Foundation, que tiene las características de alta confiabilidad, alta escalabilidad y alto rendimiento. Basado en el modelo de publicación/suscripción, Kafka se utiliza principalmente para registrar datos de transmisión, como registros, eventos e indicadores.
La arquitectura de Kafka incluye los siguientes componentes:
Broker: cada nodo del clúster de Kafka se llama Broker y es responsable de almacenar y procesar datos.
Tema: Los registros de datos se almacenan en uno o más temas. Cada tema se divide en varias particiones y cada partición se puede distribuir en diferentes corredores.
Productor: el productor es responsable de enviar datos al tema en el clúster de Kafka y puede especificar a qué partición se envían los datos.
Consumidor: el consumidor se suscribe a los datos del tema en el clúster de Kafka y procesa los datos. Los consumidores pueden formar grupos de consumidores y los consumidores de cada grupo consumen datos de forma conjunta en una o más particiones.
Kafka se usa ampliamente en varios escenarios, como recopilación de registros, procesamiento de flujo de datos en tiempo real, arquitectura basada en eventos, etc. Está estrechamente integrado con tecnologías de código abierto como Hadoop y Spark, y se ha convertido en una parte indispensable del ecosistema de big data.
(7)Tormenta
Storm es un sistema informático en tiempo real gratuito, de código abierto, distribuido y altamente tolerante a fallas. Puede manejar tareas informáticas de flujo continuo y actualmente se usa ampliamente en análisis en tiempo real, aprendizaje automático en línea, ETL y otros campos.
Storm es un sistema informático distribuido en tiempo real de código abierto, que se utiliza principalmente para procesar una gran cantidad de datos en streaming. Puede adquirir datos en tiempo real, procesarlos y enviar los datos procesados a otros sistemas. Storm es altamente escalable, tolerante a fallas y confiable, y puede ejecutarse en clústeres distribuidos.
El concepto central de Storm es la topología, que es una forma de procesamiento de flujo de datos, que consta de Spout y Bolt. Spout es un componente utilizado para la entrada de la fuente de datos, que es responsable de ingresar datos en la topología. Bolt es un componente utilizado para el procesamiento y la transmisión de datos. Recibirá los datos enviados por Spout, los procesará y luego pasará los datos procesados a el siguiente perno o fregadero. Cada elemento de la topología puede ejecutarse en paralelo para hacer que el procesamiento de datos sea más eficiente.
Storm también tiene un mecanismo de tolerancia a fallas incorporado, que puede reiniciarse automáticamente o cambiar a otros nodos para ejecutarse cuando falla un nodo del clúster, logrando una computación distribuida altamente confiable. Al mismo tiempo, Storm también admite múltiples fuentes de datos (como Kafka, RabbitMQ, etc.) y almacenamiento de datos (como HDFS, Cassandra, Redis, etc.), puede procesar diferentes tipos de datos y almacenar los resultados en diferentes. almacenamientos de datos.
En resumen, Storm es un potente marco informático en tiempo real que se utiliza ampliamente en el procesamiento de datos en tiempo real en diversas industrias.
Comparación de Storm y Hadoop
| estructura | Hadoop | Tormenta |
|---|---|---|
| nodo maestro | Seguimiento de trabajos | Nube |
| nodo esclavo | rastreador de tareas | Supervisor |
| solicitud | Trabajo | Topología |
| Nombre del proceso de trabajo | Niño | Obrero |
| Modelo computacional | Mapa reducido | Caño / Perno |
Artículos de big data:
- Big data (1) Definición y características
- Big data (2) Estadísticas relacionadas con la industria de big data
- Big data (3) Trabajos relacionados con big data
- Cree una pantalla grande de visualización de big data basada en Echarts
- Big Data (4) Tecnología convencional de Big Data
Lectura recomendada:








































|
|
|
|
| Configuración de instalación de Tomcat11, Tomcat10 (entorno Windows) (gráficos detallados) |
Conjunto de resolución de problemas de flashback de inicio de Tomcat (ocho categorías en detalle) |
|


