Tabla de contenido
1. Descripción general de MapReduce
1. La idea central de MapReduce
2. Modelo de programación MapReduce
2. Principio de funcionamiento de MapReduce
1. Fragmentación y formato de fuentes de datos
3. Ejecute el proceso de reproducción aleatoria
1. Estadísticas de frecuencia de palabras
(1) componente de formato de entrada
(5) Modo de funcionamiento de MapReduce
(2) Implementación de la etapa del Mapa
(3) Implementación de etapa combinada
(4) Implementación de la fase Reducir
(5) Implementación de la clase principal del programa controlador
(6) Visualización de resultados
(1) Implementación de la etapa del Mapa
(2) Implementación de la fase Reducir
(3) Implementación de la clase principal del programa controlador
(4) Visualización de resultados
(2) Implementación de la etapa del Mapa
(3) Implementación de la fase Reducir
(4) Implementación de la clase principal del programa controlador
(5) Visualización de resultados
El código del caso se ha colocado en el disco de red de Baidu y puede extraerlo usted mismo si es necesario.
http://enlace: https://pan.baidu.com/s/1Vcqn7-A5YWOMqhBLpr3I0A?pwd=759w código de extracción: 759w
1. Descripción general de MapReduce
1. La idea central de MapReduce
La idea central de MapReduce es "divide y vencerás" , es decir, descomponer una tarea en múltiples subtareas. No existe una interdependencia necesaria entre estas subtareas, y todas se pueden ejecutar de forma independiente. Finalmente, los resultados de estas subtareas son agregados y combinados.
2. Modelo de programación MapReduce
Como modelo de programación, MapReduce se especializa en el procesamiento de operaciones paralelas de datos a gran escala. Este modelo se basa en la idea de la programación funcional. El proceso de implementación del programa se realiza a través de la función map() y la función reduce(). Cuando se utiliza MapReduce para procesar tareas informáticas, cada tarea se divide en dos fases, la fase Map y la fase Reduce.
(1) Etapa del mapa: preprocesamiento de datos sin procesar.
(2) Etapa de reducción: resuma los resultados del procesamiento de la etapa de mapa y, finalmente, obtenga el resultado final.
Descripción del proceso: el primer paso es convertir los datos originales en forma de par clave-valor <k1, v1>; el segundo paso es importar el par clave-valor convertido <k1, v1> a la función map(), y la función map() De acuerdo con las reglas de mapeo, el par clave-valor <k1, v1> se mapea a una serie de pares clave-valor <k2, v2> en forma de resultados intermedios; el tercer paso es formar los pares clave-valor <k2, v2> en la forma intermedia a <k2, la forma {v2......}> se pasa a la función reduce() para su procesamiento, y el valor de la clave con el mismo El resultado se fusiona para generar un nuevo par clave-valor <k3,v3>. En este momento, el par clave-valor <k3,v3> es el resultado final.
2. Principio de funcionamiento de MapReduce
1. Fragmentación y formato de fuentes de datos
La entrada de la fuente de datos a la etapa del mapa debe fragmentarse y formatearse.
(1) Operación de fragmentación: divida el archivo de origen en pequeños bloques de datos del mismo tamaño y, a continuación, Hadoop creará una tarea Map para cada fragmento y la tarea ejecutará la función map() personalizada para procesar los datos en la fragmentación. registro.
(2) Operación de formateo: formatee los fragmentos divididos en datos en forma de pares clave-valor <clave, valor>, donde la clave representa el desplazamiento y el valor representa una línea de contenido.
2. Ejecutar MapTask
(1) Etapa de lectura: Map Task analiza cada par clave-valor <k,v> desde la InputSplit de entrada a través del RecordReader escrito por el usuario.
(2) Etapa del mapa: el <k, v> analizado se entrega a la función de mapa escrita por el usuario para su procesamiento, y se genera un nuevo par clave-valor <k, v>.
(3) Etapa de recopilación: en la función de mapa escrita por el usuario, después de procesar los datos, generalmente se llama a outputCollector.collect() para generar el resultado, y el fragmento de par clave-valor <k,v> se genera dentro del función, y escrito como un búfer de memoria de anillo.
(4) Etapa de derrame: si el búfer circular está lleno, MapReduce escribirá los datos en el disco local para generar un archivo temporal. Cabe señalar aquí que antes de que los datos se escriban en el disco local, los datos deben ordenarse una vez y los datos deben combinarse y comprimirse si es necesario.
(5) Etapa de combinación: después de que se procesen todos los datos, Map Task fusionará todos los archivos temporales una vez para garantizar que solo se genere un archivo de datos al final.
3. Ejecute el proceso de reproducción aleatoria
Shuffle distribuirá la salida de datos del resultado del procesamiento de Map Task a RecudeTask y, durante el proceso de distribución, los datos se dividirán y ordenarán por clave.
4. Ejecutar RecudeTack
(1) Etapa de copia: Recude copiará de forma remota una copia de los datos de cada MapTask y, para determinados datos, si su tamaño supera un determinado valor, se escribirán en el disco; de lo contrario, se almacenarán en la memoria.
(2) Etapa de combinación: mientras copia datos de forma remota, RecudeTack iniciará dos subprocesos en segundo plano para combinar archivos en la memoria y el disco respectivamente para evitar el uso excesivo de la memoria o demasiados archivos en el disco.
(3) Etapa de clasificación: el usuario escribe el método reduce() para ingresar datos que son un conjunto de datos agregados por clave. Para teclear los mismos datos juntos, Hadoop adopta una estrategia basada en la clasificación. Dado que cada MapTask ha implementado una clasificación parcial de sus propios resultados de procesamiento, ReduceTask solo necesita clasificar todos los datos una vez.
(4) Fase de reducción: llame al método reduce () en los pares clave-valor ordenados, y llame al método reduce () una vez para los pares clave-valor con claves iguales. Cada llamada generará cero o más pares clave-valor, y finalmente coloque estas claves. Los pares de valores se escriben en HDFS.
(5) Etapa de escritura: la función reduce() escribe los resultados del cálculo en HDFS.
5. Escribir en el archivo
El marco MapReduce transferirá automáticamente la <clave, valor> generada por RecudeTack al método de escritura de OutputFormat para implementar la operación de escritura de archivos.
3. Caso
1. Estadísticas de frecuencia de palabras
Aquí usamos el caso de las estadísticas de frecuencia de palabras para comprender brevemente los componentes relacionados de MapReduce.
(1) componente de formato de entrada
Este componente se utiliza principalmente para describir el formato de los datos de entrada y proporciona las siguientes dos funciones.
a) Segmentación de datos: De acuerdo con la estrategia, los datos de entrada se dividen en varios fragmentos para determinar el número de MapTasks y los fragmentos correspondientes.
b. Proporcione la fuente de datos de entrada para Mapper: Dada una porción determinada, analícela en pares clave-valor <k, v>.
Hadoop viene con una interfaz InputFormat, que define el código de la siguiente manera.
public abstract class InputFormat <K, V> {
public abstract List<InputFormat>getSplits(JobContext context) throws IOException, InterruptedException;
public abstract RecordReader <K, V> createRecordReader (InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException;
}La interfaz InputFormat define dos métodos: getSplits() y createRecordReader(). El método getSplits() es responsable de dividir el archivo en múltiples fragmentos. El método createRecordReader() es responsable de crear un objeto RecordReader para obtener datos de los fragmentos.
(2) Componente de mapeador
El programa MapReduce generará múltiples tareas de mapa de acuerdo con el archivo de entrada. La clase Mapper implementa una clase abstracta de la tarea Map. Esta clase proporciona un método map(). De forma predeterminada, este método no tiene ningún procesamiento. En este momento, podemos personalizar el método map(), heredar la clase Mapper y reescribir el método map().
A continuación, tomemos las estadísticas de frecuencia de palabras como ejemplo y personalicemos el método map() El código es el siguiente.
package cn.itcast.mr.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
//接收传入进来的一行文本,并转换成String类型
String line = value.toString();
//将这行内容按分隔符空格切割成单词,保存在String数组中
String[] words = line.split(" ");
//遍历数组,产生<K2,V2>键值对,形式为<单词,1>
for (String word : words
) {
//使用context,把map阶段处理的数据发送给reduce阶段作为输入数据
context.write(new Text(word), new IntWritable(1));
}
}
}(3) Componente reductor
Los pares clave-valor generados por el proceso Map serán combinados por el componente Reducer. Aquí tomamos las estadísticas de frecuencia de palabras como ejemplo y personalizamos el método reduce().
package cn.itcast.mr.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
//定义一个计数器
int count = 0;
//遍历一组迭代器,把每一个数量1累加起来构成了单词出现的总次数
for (IntWritable iw : values
) {
count +=iw.get();
}
//向上下文context写入<k3,v3>
context.write(key, new IntWritable(count));
}
}(4) Componente combinador
La función de este componente es realizar un cálculo de combinación en los datos duplicados de salida de la etapa Map y luego usar el nuevo par clave-valor como entrada de la etapa Reduce. Si desea personalizar la clase Combiner, necesita heredar la clase Reducer y reescribir el método reduce() El código específico es el siguiente.
package cn.itcast.mr.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountCombiner extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//局部汇总
//定义一个计数器
int count = 0;
//遍历一组迭代器,把每一个数量1累加起来构成了单词出现的总次数
for (IntWritable v : values
) {
count += v.get();
}
//向上下文context写入<k3,v3>
context.write(key, new IntWritable(count));
}
}(5) Modo de funcionamiento de MapReduce
Hay dos modos operativos de MapReduce, el modo operativo local y el modo operativo de clúster.
a. Modo de ejecución local: simule el entorno de ejecución de MapReduce en el entorno de desarrollo actual y los resultados de salida de los datos procesados son todos locales.
B. Modo de operación de clúster: empaque el programa MapReduce en un paquete jar, cárguelo en el clúster de Yarn para su funcionamiento y procese los datos y los resultados en HDFS.
Aquí hablamos principalmente sobre el modo de operación local.Para realizar la operación local, también necesitamos una clase de controlador, el código es el siguiente.
package cn.itcast.mr.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//通过 Job 来封装本次 MR 的相关信息
Configuration conf = new Configuration();
//配置MR运行模式,使用 local 表示本地模式,可以省略
conf.set("mapreduce.framework.name","local");
//获取 Job 运行实例
Job wcjob = Job.getInstance(conf);
//指定 MR Job jar运行主类
wcjob.setJarByClass(WordCountDriver.class);
//指定本次 MR 所有的 Mapper Combiner Reducer类
wcjob.setMapperClass(WordCountMapper.class);
wcjob.setCombinerClass(WordCountCombiner.class); //不指定Combiner的话也不影响结果
wcjob.setReducerClass(WordCountReducer.class);
//设置业务逻辑 Mapper 类的输出 key 和 value 的数据类型
wcjob.setMapOutputKeyClass(Text.class);
wcjob.setMapOutputValueClass(IntWritable.class);
//设置业务逻辑 Reducer 类的输出 key 和 value 的数据类型
wcjob.setOutputKeyClass(Text.class);
wcjob.setOutputValueClass(IntWritable.class);
//使用本地模式指定要处理的数据所在的位置
FileInputFormat.setInputPaths(wcjob,"/home/huanganchi/Hadoop/实训项目/HadoopDemo/textHadoop/WordCount/input");
//使用本地模式指定处理完成后的结果所保持的位置
FileOutputFormat.setOutputPath(wcjob,new Path("/home/huanganchi/Hadoop/实训项目/HadoopDemo/textHadoop/WordCount/output"));
//提交程序并且监控打印程序执行情况
boolean res = wcjob.waitForCompletion(true);
System.exit(res ? 0:1);
}
}Cuando terminemos de ejecutar, se generará un archivo de resultados localmente.

2. índice invertido
(1. Introducción
El índice invertido es una estructura de formato de datos de uso común en los sistemas de recuperación de documentos y se usa ampliamente en los motores de búsqueda de texto completo. Puede entenderse simplemente como encontrar documentos basados en contenido, en lugar de encontrar contenido basado en documentos.
(2) Implementación de la etapa del Mapa
package cn.itcast.mr.invertedIndex;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileSplit;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class InvertedIndexMapper extends Mapper<LongWritable, Text, Text, Text> {
//存储单词和文档名称
private static Text keyInfo = new Text();
// 存储词频,初始化为1
private static final Text valueInfo = new Text("1");
/*
* 在该方法中将K1、V1转换为K2、V2
* key: K1行偏移量
* value: V1行文本数据
* context: 上下文对象
* 输出: <MapReduce:file3 "1">
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
// 得到单词数组
String[] fields = line.split(" ");
//得到这行数据所在的文件切片
FileSplit fileSplit = (FileSplit) context.getInputSplit();
//根据文件切片得到文件名
String filename = fileSplit.getPath().getName();
for (String field : fields
) {
// key值由单词和文件名组成,如“MapReduce:file1”
keyInfo.set(field + ":" + filename);
context.write(keyInfo, valueInfo);
}
}
}(3) Implementación de etapa combinada
package cn.itcast.mr.invertedIndex;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class InvertedIndexCombiner extends Reducer<Text, Text, Text, Text> {
private static Text info = new Text();
// 输入: <MapReduce:file3 {1,1,...}>
// 输出:<MapReduce file3:2>
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
int sum = 0; //统计词频
//遍历一组迭代器,把每一个数量1累加起来构成了单词出现的总次数
for (Text value : values) {
sum += Integer.parseInt(value.toString());
}
int splitIndex = key.toString().indexOf(":");
// 重新设置 value 值由文件名和词频组成
info.set(key.toString().substring(splitIndex + 1) + ":" + sum);
// 重新设置 key 值为单词
key.set(key.toString().substring(0, splitIndex));
//向上下文context写入<k3,v3>
context.write(key, info);
}
}
(4) Implementación de la fase Reducir
package cn.itcast.mr.invertedIndex;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class InvertedIndexReducer extends Reducer<Text, Text, Text, Text> {
private static Text result = new Text();
// 输入:<MapReduce, file3:2>
// 输出:<MapReduce, file1:1;file2:1;file3:2;>
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
// 生成文档列表
StringBuffer fileList = new StringBuffer();
for (Text value : values) {
fileList.append(value.toString() + ";");
}
result.set(fileList.toString());
context.write(key, result);
}
}
(5) Implementación de la clase principal del programa controlador
package cn.itcast.mr.invertedIndex;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class InvertedIndexDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//通过 Job 来封装本次 MR 的相关信息
Configuration conf = new Configuration();
//获取 Job 运行实例
Job job = Job.getInstance(conf);
//指定 MR Job jar运行主类
job.setJarByClass(InvertedIndexDriver.class);
//指定本次 MR 所有的 Mapper Combiner Reducer类
job.setMapperClass(InvertedIndexMapper.class);
job.setCombinerClass(InvertedIndexCombiner.class);
job.setReducerClass(InvertedIndexReducer.class);
//设置业务逻辑 Mapper 类的输出 key 和 value 的数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//设置业务逻辑 Reducer 类的输出 key 和 value 的数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//使用本地模式指定要处理的数据所在的位置
FileInputFormat.setInputPaths(job,"/home/huanganchi/Hadoop/实训项目/HadoopDemo/textHadoop/InvertedIndex/input");
//使用本地模式指定处理完成后的结果所保持的位置
FileOutputFormat.setOutputPath(job,new Path("/home/huanganchi/Hadoop/实训项目/HadoopDemo/textHadoop/InvertedIndex/output"));
//提交程序并且监控打印程序执行情况
boolean res = job.waitForCompletion(true);
System.exit(res ? 0:1);
}
}
(6) Visualización de resultados
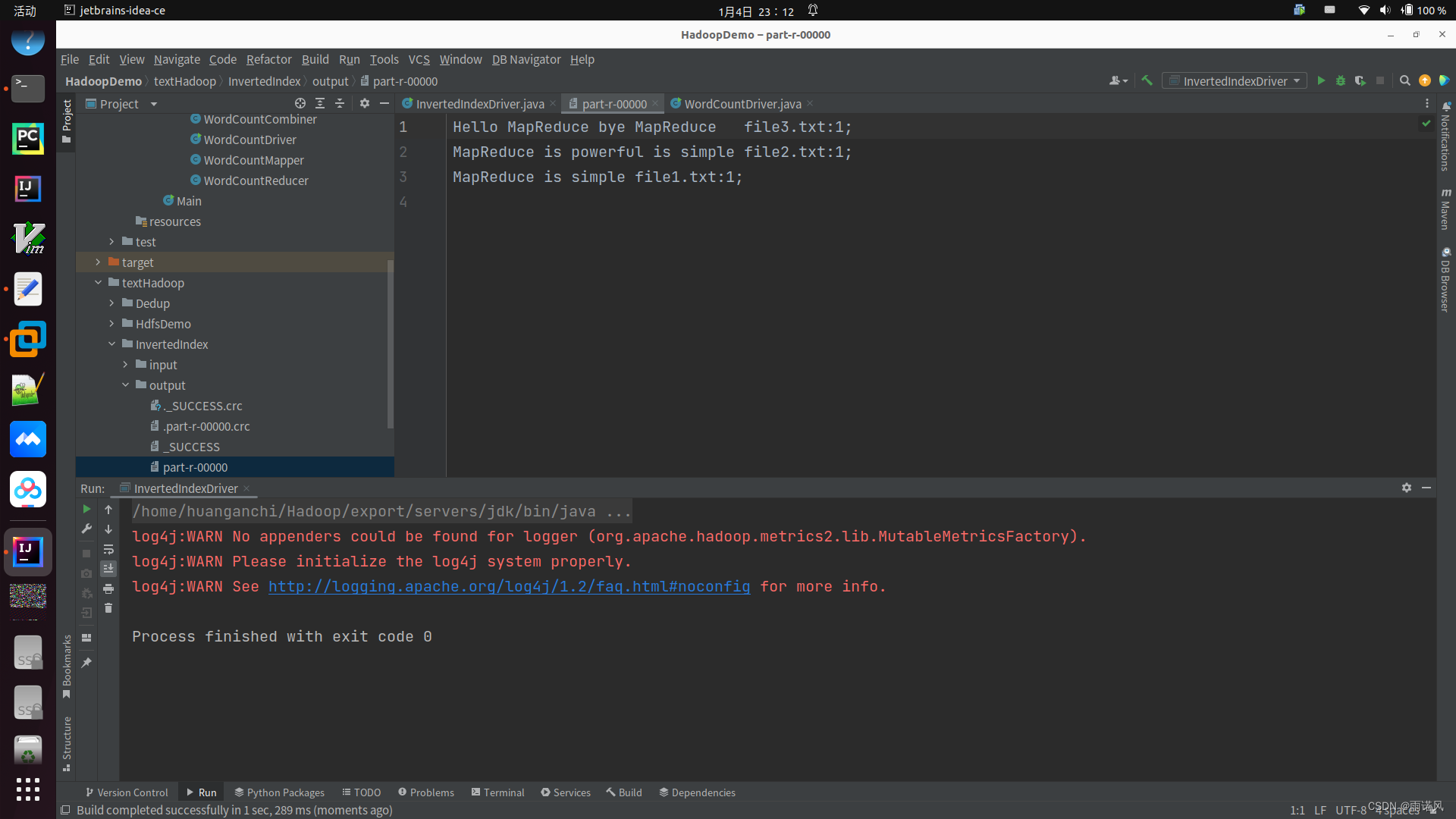
3. Deduplicación de datos
(1) Implementación de la etapa del Mapa
package cn.itcast.mr.dedup;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class DedupMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
private static Text field = new Text();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context)
throws IOException, InterruptedException {
field = value;
context.write(field,NullWritable.get());
}
}
(2) Implementación de la fase Reducir
package cn.itcast.mr.dedup;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class DeupReducer extends Reducer<Text, NullWritable, Text, NullWritable> {
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Reducer<Text, NullWritable, Text, NullWritable>.Context context)
throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
(3) Implementación de la clase principal del programa controlador
package cn.itcast.mr.dedup;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
public class DedupDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(DedupDriver.class);
job.setMapperClass(DedupMapper.class);
job.setReducerClass(DeupReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path("/home/huanganchi/Hadoop/实训项目/HadoopDemo/textHadoop/Dedup/input"));
FileOutputFormat.setOutputPath(job, new Path("/home/huanganchi/Hadoop/实训项目/HadoopDemo/textHadoop/Dedup/output"));
//job.waitForCompletion(true);
boolean res = job.waitForCompletion(true);
if (res) {
FileReader fr = new FileReader("/home/huanganchi/Hadoop/实训项目/HadoopDemo/textHadoop/Dedup/output/part-r-00000");
BufferedReader reader= new BufferedReader(fr);
String str;
while ( (str = reader.readLine()) != null )
System.out.println(str);
System.out.println("运行成功");
}
System.exit(res ? 0 : 1);
}
}
(4) Visualización de resultados

4、SuperiorN
(1) Introducción del caso
El método de análisis TopN se refiere al método de instalar un determinado indicador del objeto de investigación en orden inverso o directo, tomando los N casos requeridos y centrándose en el análisis de los N datos.
(2) Implementación de la etapa del Mapa
package cn.itcast.mr.topN;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.TreeMap;
public class TopNMapper extends Mapper<LongWritable, Text,
NullWritable, IntWritable> {
private TreeMap<Integer, String>repToRecordMap =
new TreeMap<Integer, String>();
@Override
public void map (LongWritable key, Text value, Context context) {
String line = value.toString();
String[] nums = line.split(" ");
for (String num : nums
) {
repToRecordMap.put(Integer.parseInt(num), " ");
if (repToRecordMap.size() > 5) {
repToRecordMap.remove(repToRecordMap.firstKey());
}
}
}
@Override
protected void cleanup(Context context) {
for (Integer i: repToRecordMap.keySet()
) {
try {
context.write(NullWritable.get(), new IntWritable(i));
} catch (Exception e) {
e.printStackTrace();
}
}
}
}(3) Implementación de la fase Reducir
package cn.itcast.mr.topN;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
import java.util.Comparator;
import java.util.TreeMap;
public class TopNReducer extends Reducer<NullWritable, IntWritable, NullWritable, IntWritable> {
private TreeMap<Integer, String>repToRecordMap = new
TreeMap<Integer, String>(new Comparator<Integer>() {
public int compare(Integer a, Integer b) {
return b-a;
}
});
public void reduce(NullWritable key,
Iterable<IntWritable>values, Context context)
throws IOException, InterruptedException {
for (IntWritable value : values
) {
repToRecordMap.put(value.get(), " ");
if (repToRecordMap.size() > 5) {
repToRecordMap.remove(repToRecordMap.lastKey());
}
}
for (Integer i : repToRecordMap.keySet()
) {
context.write(NullWritable.get(), new IntWritable(i));
}
}
}
(4) Implementación de la clase principal del programa controlador
package cn.itcast.mr.topN;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.BufferedReader;
import java.io.FileReader;
public class TopNDriver {
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(TopNDriver.class);
job.setMapperClass(TopNMapper.class);
job.setReducerClass(TopNReducer.class);
job.setNumReduceTasks(1);
job.setMapOutputKeyClass(NullWritable.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path("/home/huanganchi/Hadoop/实训项目/HadoopDemo/textHadoop/TopN/input"));
FileOutputFormat.setOutputPath(job, new Path("/home/huanganchi/Hadoop/实训项目/HadoopDemo/textHadoop/TopN/output"));
boolean res = job.waitForCompletion(true);
if (res) {
FileReader fr = new FileReader("/home/huanganchi/Hadoop/实训项目/HadoopDemo/textHadoop/TopN/output/part-r-00000");
BufferedReader reader= new BufferedReader(fr);
String str;
while ( (str = reader.readLine()) != null )
System.out.println(str);
System.out.println("运行成功");
}
System.exit(res ? 0 : 1);
}
}(5) Visualización de resultados
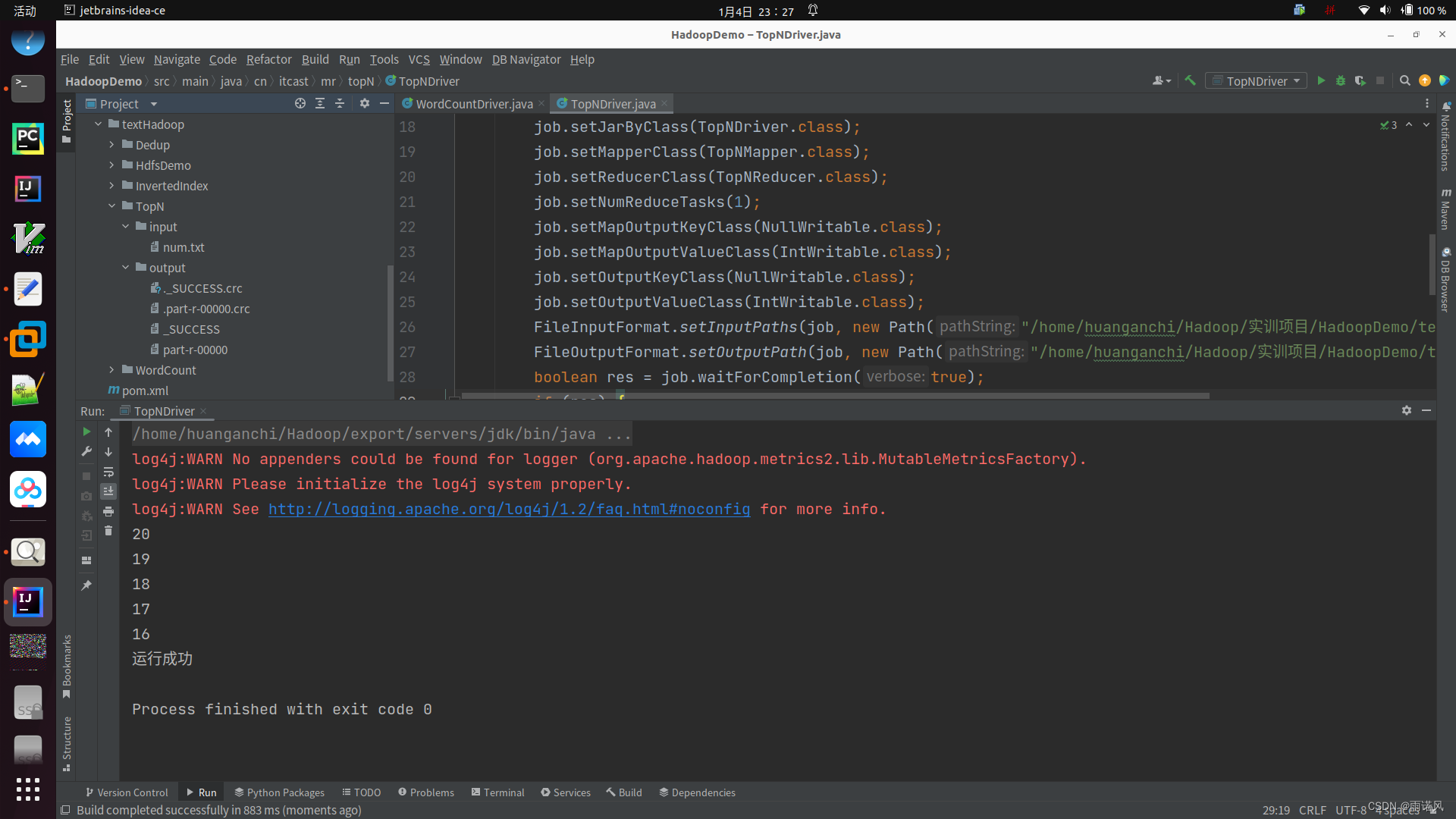
libros de referencia
"Principio y aplicación de la tecnología de big data de Hadoop"