Capítulo 1 HDFS—Resolución de problemas
1.1 Modo de seguridad del clúster
1) Modo de seguridad: el sistema de archivos solo acepta solicitudes de lectura de datos, pero no solicitudes de eliminación, modificación y otros cambios.
2) Ingrese a la escena del modo seguro
NameNode está en modo seguro durante la carga de imágenes y los registros de edición
Cuando NameNode recibe el registro de DataNode nuevamente , está en modo seguro

3) Salir de las condiciones del modo seguro
dfs.namenode.safemode.min.datanodes: el número mínimo de nodos de datos disponibles, predeterminado 0;
dfs.namenode.safemode.threshold-pct: el porcentaje de bloques con el número mínimo de réplicas respecto al número total de bloques en el sistema; el valor predeterminado es 0,999f.
dfs.namenode.safemode.extension: tiempo estable, el valor predeterminado es 30000 milisegundos, que son 30 segundos
4) Gramática básica
El clúster está en modo seguro y no puede realizar operaciones críticas (operaciones de escritura). Una vez que se completa el inicio del clúster, sale automáticamente del modo seguro.
bin/hdfs dfsadmin -safemode get #(功能描述:查看安全模式状态)
bin/hdfs dfsadmin -safemode enter #(功能描述:进入安全模式状态)
bin/hdfs dfsadmin -safemode leave #(功能描述:离开安全模式状态)
bin/hdfs dfsadmin -safemode wait #(功能描述:等待安全模式状态)1.2 Solución de problemas de NameNode
1) Requisitos:
El proceso de NameNode se bloquea y los datos almacenados se pierden, cómo restaurar NameNode
2) Simulación de fallas
(1) matar -9 proceso NameNode
[atguigu@hadoop102 current]$ kill -9 NameNode的进程号(2) Eliminar los datos almacenados por NameNode (/opt/module/hadoop-3.1.3/data/tmp/dfs/name)
[atguigu@hadoop102 hadoop-3.1.3]$ rm -rf /opt/module/hadoop-3.1.3/data/dfs/name/*3) Resolución de problemas
(1) Copie los datos de SecondaryNameNode en el directorio de datos de almacenamiento original de NameNode.
[atguigu@hadoop102 dfs]$ scp -r atguigu@hadoop104:/opt/module/hadoop-3.1.3/data/dfs/namesecondary/* ./name/(2) Reinicie el NameNode
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs --daemon start namenode(3) Subir un archivo al clúster
1.3 Resumen
1.3.1 Pérdida de metadatos

Eliminar todos los metadatos en NN (edits, edits_inprogress, fsimage)
Después de detener y reiniciar NN, se descubrió que no se podía iniciar.
Recuperación de emergencia (esto no ocurrirá en el entorno de producción porque se usará HA) copie las ediciones y fsimage en 2NN a NN
Solo se puede recuperar una parte de los datos. También permanecerá en modo seguro.
Si no le importa esa parte del grupo de datos y desea volver a la normalidad:
hdfs dfsadmin -safemode forceExit1.3.2 Pérdida de bloque

Cuando eliminemos dos bloques en los tres nodos y reiniciemos el NameNode, entrará en modo seguro
Para un funcionamiento normal, salga del modo seguro
Reiniciar NameNode seguirá entrando en modo seguro (a menos que los metadatos del bloque faltante (por comando o borrado en la página) ya no permanezcan en modo seguro)
Capítulo 2 HDFS: múltiples directorios
2.1 Configuración multidirectorio de DataNode
1) DataNode se puede configurar en varios directorios y los datos almacenados en cada directorio son diferentes (los datos no son una copia)

2) La configuración específica es la siguiente
Agregue el siguiente contenido al archivo hdfs-site.xml.
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data,
file://${hadoop.tmp.dir}/dfs/data2
</value>
</property>3) Ver los resultados
[atguigu@hadoop102 dfs]$ ll
总用量 12
drwx------. 3 atguigu atguigu 4096 4月 4 14:22 data
drwx------. 3 atguigu atguigu 4096 4月 4 14:22 data2
drwxrwxr-x. 3 atguigu atguigu 4096 12月 11 08:03 name1
drwxrwxr-x. 3 atguigu atguigu 4096 12月 11 08:03 name24) Cargue un archivo en el clúster y observe el contenido de las dos carpetas nuevamente y descubra que son inconsistentes (una tiene un número y la otra no)
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -put wcinput/word.txt /2.2 Equilibrio de datos entre discos para el equilibrio de datos de clúster
En el entorno de producción, debido a la falta de espacio en el disco duro, a menudo es necesario agregar un disco duro. Cuando el disco duro recién cargado no tiene datos, puede ejecutar el comando de balance de datos del disco. (Nuevas características de Hadoop3.x).
(1) Generar un plan equilibrado ( solo tenemos un disco y no generaremos un plan )
hdfs diskbalancer -plan hadoop102(2) Ejecutar un plan equilibrado
hdfs diskbalancer -execute hadoop102.plan.json(3) Ver el estado de ejecución de la tarea de saldo actual
hdfs diskbalancer -query hadoop102(4) Cancelar la tarea de saldo
hdfs diskbalancer -cancel hadoop102.plan.jsonCapítulo 3 HDFS: expansión y reducción de clústeres
3.1 Dar servicio al nuevo servidor
1) demanda
Con el crecimiento del negocio de la empresa, la cantidad de datos es cada vez mayor, y la capacidad de los nodos de datos originales ya no puede satisfacer las necesidades de almacenamiento de datos. Es necesario agregar dinámicamente nuevos nodos de datos sobre la base de la racimo original.
2) Preparación del entorno
(1) Clonar otro host hadoop105 en el host hadoop100
(2) Modificar la dirección IP y el nombre de host
[root@hadoop105 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33
[root@hadoop105 ~]# vim /etc/hostname(3) Copie el directorio /opt/module y /etc/profile.d/my_env.sh de hadoop102 a hadoop105
[atguigu@hadoop102 opt]$ scp -r module/*atguigu@hadoop105:/opt/module/
[atguigu@hadoop102 opt]$ sudo scp /etc/profile.d/my_env.shroot@hadoop105:/etc/profile.d/my_env.sh
[atguigu@hadoop105 hadoop-3.1.3]$ source /etc/profile
(4) Eliminar los datos históricos, datos y datos de registro de Hadoop en hadoop105
[atguigu@hadoop105 hadoop-3.1.3]$ rm -rf data/ logs/(5) Configure hadoop102 y hadoop103 para el inicio de sesión no secreto de hadoop105 ssh
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop105
[atguigu@hadoop103 .ssh]$ ssh-copy-id hadoop1053) Pasos específicos para dar servicio a nuevos nodos
Inicie el DataNode directamente para asociarlo con el clúster
[atguigu@hadoop105 hadoop-3.1.3]$ hdfs --daemon start datanode
[atguigu@hadoop105 hadoop-3.1.3]$ yarn --daemon start nodemanager3.2 Equilibrio de datos entre servidores
1) Experiencia empresarial:
En el desarrollo empresarial, si las tareas se envían a menudo en Hadoop102 y Hadoop104, y el número de copias es 2, debido al principio de localidad de datos, habrá demasiados datos en Hadoop102 y Hadoop104, y la cantidad de datos almacenados en Hadoop103 será menor. ser pequeño
Otra situación es que el volumen de datos del nuevo servidor es relativamente pequeño y es necesario ejecutar el comando de equilibrio del clúster.
2) Habilitar el comando de balance de datos
[atguigu@hadoop105 hadoop-3.1.3]$ sbin/start-balancer.sh -threshold 10Para el parámetro 10, significa que la utilización del espacio en disco de cada nodo en el clúster no difiere en más del 10 %, lo que se puede ajustar según la situación real.
3) Detener el comando de balance de datos
[atguigu@hadoop105 hadoop-3.1.3]$ sbin/stop-balancer.shNota: Debido a que HDFS necesita iniciar un RebalanceServer separado para realizar la operación de Rebalanceo, intente no ejecutar start-balancer.sh en NameNode, pero busque una máquina relativamente inactiva.
3.3 Agregar lista blanca
Lista blanca: indica que las direcciones IP del host en la lista blanca se pueden usar para almacenar datos.
En la empresa: configure una lista blanca para evitar ataques de acceso malicioso por parte de piratas informáticos.
Los pasos para configurar la lista blanca son los siguientes:
1) Cree archivos de lista blanca y lista negra respectivamente en el directorio /opt/module/hadoop-3.1.3/etc/hadoop del nodo NameNode
(1) Crear una lista blanca
[atguigu@hadoop102 hadoop]$ vim whitelist
# 在whitelist中添加如下主机名称,假如集群正常工作的节点为102 103 :
hadoop102
hadoop103(2) Crear una lista negra
[atguigu@hadoop102 hadoop]$ touch blacklistSolo mantenlo vacío.
2) Agregue el parámetro de configuración dfs.hosts en el archivo de configuración hdfs-site.xml
<!-- 白名单-->
<property>
<name>dfs.hosts</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop/whitelist</value>
</property>
<!-- 黑名单-->
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop/blacklist</value>
</property>3) Lista blanca del archivo de configuración de distribución, hdfs-site.xml
[atguigu@hadoop104 hadoop]$ xsync hdfs-site.xml whitelist4) El clúster debe reiniciarse para agregar la lista blanca por primera vez, no la primera vez, simplemente actualice el nodo NameNode
[atguigu@hadoop102 hadoop-3.1.3]$ myhadoop.sh stop
[atguigu@hadoop102 hadoop-3.1.3]$ myhadoop.sh start5) Ver el DN en un navegador web, http://hadoop102:9870/dfshealth.html#tab-datanode
6) Modifique la lista blanca dos veces y agregue hadoop104
[atguigu@hadoop102 hadoop]$ vim whitelist
修改为如下内容
hadoop102
hadoop103
hadoop104
hadoop1057) Actualizar el NameNode
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs dfsadmin -refreshNodesActualizar nodos correctamente
8) Ver el DN en un navegador web, http://hadoop102:9870/dfshealth.html#tab-datanode
3.4 Lista negra de servidores dados de baja
Lista negra: indica que la dirección IP del host en la lista negra no puede almacenar datos.
En la empresa: configure la lista negra para desmantelar el servidor.
Los pasos de configuración de la lista negra son los siguientes:
1) Edite el archivo de la lista negra en el directorio /opt/module/hadoop-3.1.3/etc/hadoop
[atguigu@hadoop102 hadoop] vim blacklist
添加如下主机名称(要退役的节点)
hadoop105Nota: Si no hay ninguna configuración en la lista blanca, debe agregar el parámetro de configuración dfs.hosts en el archivo de configuración hdfs-site.xml
<!-- 黑名单-->
<property>
<name>dfs.hosts.exclude</name>
<value>/opt/module/hadoop-3.1.3/etc/hadoop/blacklist</value>
</property>2) Lista negra del archivo de configuración de distribución, hdfs-site.xml
[atguigu@hadoop104 hadoop]$ xsync hdfs-site.xml blacklist3) El clúster debe reiniciarse para agregar la lista negra por primera vez, no la primera vez, simplemente actualice el nodo NameNode
[atguigu@hadoop102 hadoop-3.1.3]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful4) Verifique el navegador web, el estado del nodo dado de baja es desmantelamiento en curso (desmantelamiento), lo que indica que el nodo de datos está copiando bloques a otros nodos
5) Espere a que se desactive el estado del nodo dado de baja (se han copiado todos los bloques), detenga el nodo y el administrador de recursos del nodo. Nota: Si la cantidad de réplicas es 3 y la cantidad de nodos en servicio es menor o igual a 3, la clausura no puede realizarse correctamente. Debe modificar la cantidad de réplicas antes de la clausura.
[atguigu@hadoop105 hadoop-3.1.3]$ hdfs --daemon stop datanode
stopping datanode
[atguigu@hadoop105 hadoop-3.1.3]$ yarn --daemon stop nodemanager
stopping nodemanager6) Si los datos están desequilibrados, puede usar comandos para reequilibrar el clúster
[atguigu@hadoop102 hadoop-3.1.3]$ sbin/start-balancer.sh -threshold10Capítulo 4 Optimización empresarial de Hadoop
4.1 Método de optimización MapReduce
El método de optimización de MapReduce considera principalmente seis aspectos : entrada de datos, fase de mapa, fase de reducción, transmisión de E/S, sesgo de datos y parámetros de ajuste de uso común.
Entrada de datos
Combinar archivos pequeños : combine archivos pequeños antes de ejecutar tareas de MR. Una gran cantidad de archivos pequeños generará una gran cantidad de MapTasks, lo que aumentará la cantidad de cargas de MapTask. La carga de tareas lleva mucho tiempo, lo que resulta en una operación lenta de MR.
Use CombineTextInputFormat como entrada para resolver una gran cantidad de escenarios de archivos pequeños en el extremo de entrada.
Etapa del mapa
Reduzca la cantidad de derrames : al ajustar los valores de los parámetros mapreduce.task.io.sort.mb y mapreduce.map.sort.spill.percent, aumente el límite de memoria que activa los derrames, reduzca la cantidad de derrames y reduzca la E/S del disco.
Reduzca el número de fusiones (Fusionar) : al ajustar el parámetro mapreduce.task.io.sort.factor, aumente el número de archivos de fusión y reduzca el número de fusiones, acortando así el tiempo de procesamiento de MR .
Después de Map, sin afectar la lógica comercial , el procesamiento de Combime se realiza primero para reducir IO.
Reducir etapa
Establezca razonablemente el número de Map y Reduce : no se puede establecer demasiado poco ni demasiado. Demasiado poco hará que la tarea espere y prolongue el tiempo de procesamiento; demasiado provocará una competencia de recursos entre las tareas Map y Reduce, lo que resultará en un tiempo de espera de procesamiento y otros errores.
Configure Map y Reduce para que coexistan : ajuste el parámetro mapreducejob.reduce.slowstart.completedmaps para que después de que Map se ejecute hasta cierto punto, Reduce también comience a ejecutarse, lo que reduce el tiempo de espera para Reduce.
Evite usar Reduce : porque Reduce generará mucho consumo de red cuando se use para conectar conjuntos de datos.
Establezca razonablemente el búfer en el lado de reducción : de forma predeterminada, cuando los datos alcanzan un umbral, los datos en el búfer se escribirán en el disco y luego Reducir obtendrá todos los datos del disco. Es decir, Buffer y Reduce no están directamente relacionados, y el proceso de escribir en disco -> leer disco varias veces en el medio, ya que existe esta desventaja, se puede configurar a través de parámetros para que parte de los datos en Buffer ser enviado directamente a Reduce Para reducir la sobrecarga de IO: mapreduce.reduce.input.buffer.percent, el valor predeterminado es 0.0. Cuando el valor es mayor que 0, la proporción especificada de memoria se reservará para leer los datos en el búfer y usarlos directamente para reducir. De esta manera, se requiere memoria para establecer búferes, se requiere memoria para leer datos y se requiere memoria para reducir cálculos, por lo que se deben realizar ajustes de acuerdo con el estado de ejecución del trabajo.
estándar de E/S
Utilice el método de compresión de datos : reduzca el tiempo de E/S de la red. Instale codificadores de compresión Sappy y LZO.
Utilice archivos binarios de SequenceFile.
problema de sesgo de datos
problema de sesgo de datos
Fenómeno de sesgo de datos:
Sesgo de frecuencia de datos : la cantidad de datos en un área determinada es mucho mayor que en otras áreas;
Sesgo en el tamaño de los datos : algunos registros tienen un tamaño mucho mayor que el promedio.
Formas de reducir el sesgo de datos
Muestreo y partición de rango : los valores límite de partición se pueden preestablecer a través del conjunto de resultados obtenidos al muestrear los datos originales.
Particionamiento personalizado : Realice un particionamiento personalizado basado en el conocimiento previo de la clave de salida. Por ejemplo, si la clave de salida del mapa tiene palabras de un libro. Y algunos de ellos tienen un vocabulario más profesional. Luego puede personalizar la partición para enviar estas palabras profesionales a una parte fija de la instancia de Reduce. Y envía los demás a las instancias de Reduce restantes.
Combiner: el uso de Combiner puede reducir en gran medida el sesgo de datos. El propósito de Combimner es agregar y condensar datos cuando sea posible.
Use Map Join e intente evitar Reduce Join.
Parámetros de afinación comunes
1) Parámetros relacionados con los recursos
(1) Los siguientes parámetros solo pueden surtir efecto después de la configuración en la propia aplicación MR del usuario ( mapred-default.xml )
parámetros de configuración |
Descripción de parámetros |
mapreduce.map.memoria.mb |
El límite superior de recursos (unidad: MB) que puede usar una MapTask, el valor predeterminado es 1024. Si la cantidad de recursos realmente utilizados por MapTask excede este valor, se eliminará a la fuerza. |
mapreduce.reduce.memory.mb |
El límite superior de recursos (unidad: MB) que puede utilizar ReduceTask, el valor predeterminado es 1024. Si la cantidad de recursos realmente utilizados por ReduceTask excede este valor, se eliminará a la fuerza. |
mapreduce.map.cpu.vcores |
La cantidad máxima de núcleos de CPU que puede usar cada MapTask, valor predeterminado: 1 |
mapreduce.reduce.cpu.vcores |
La cantidad máxima de núcleos de CPU que puede usar cada ReduceTask, valor predeterminado: 1 |
mapreduce.reduce.shuffle.parallelcopies |
El número paralelo de cada Reducir para obtener datos del Mapa. El valor predeterminado es 5 |
mapreduce.reduce.shuffle.merge.percent |
El porcentaje de los datos en el búfer para comenzar a escribir en el disco. El valor predeterminado es 0,66 |
mapreduce.reduce.shuffle.input.buffer.percent |
Tamaño del búfer como porcentaje de la memoria disponible de Reduce. Valor predeterminado 0,7 |
mapreduce.reduce.input.buffer.percent |
Especifique cuánta memoria se usa para almacenar los datos en Buffer, el valor predeterminado es 0.0 |
(2) Debe configurarse en el archivo de configuración del servidor antes de que YARN comience a tener efecto ( yarn-default.xml )
parámetros de configuración |
Descripción de parámetros |
yarn.scheduler.minimum-asignación-mb |
La memoria mínima asignada al contenedor de la aplicación, valor predeterminado: 1024 |
yarn.scheduler.maximum-allocation-mb |
给应用程序Container分配的最大内存,默认值:8192 |
yarn.scheduler.minimum-allocation-vcores |
每个Container申请的最小CPU核数,默认值:1 |
yarn.scheduler.maximum-allocation-vcores |
每个Container申请的最大CPU核数,默认值:32 |
yarn.nodemanager.resource.memory-mb |
给Containers分配的最大物理内存,默认值:8192 |
(3)Shuffle性能优化的关键参数,应在YARN启动之前就配置好(mapred-default.xml)
配置参数 |
参数说明 |
mapreduce.map.maxattempts |
每个Map Task最大重试次数,一旦重试次数超过该值,则认为Map Task运行失败,默认值:4。 |
mapreduce.reduce.maxattempts |
每个Reduce Task最大重试次数,一旦重试次数超过该值,则认为Map Task运行失败,默认值:4。 |
mapreduce.task.timeout |
Task超时时间,经常需要设置的一个参数,该参数表达的意思为:如果一个Task在一定时间内没有任何进入,即不会读取新的数据,也没有输出数据,则认为该Task处于Block状态,可能是卡住了,也许永远会卡住,为了防止因为用户程序永远Block住不退出,则强制设置了一个该超时时间(单位毫秒),默认是600000(10分钟)。如果你的程序对每条输入数据的处理时间过长(比如会访问数据库,通过网络拉取数据等),建议将该参数调大,该参数过小常出现的错误提示是:“AttemptID:attempt_14267829456721_123456_m_000224_0 Timed out after 300 secsContainer killed by the ApplicationMaster.”。 |
4.2 Hadoop小文件优化方法
4.2.1 Hadoop小文件弊端
HDFS上每个文件都要在NameNode上创建对应的元数据,这个元数据的大小约为150byte,这样当小文件比较多的时候,就会产生很多的元数据文件,一方面会大量占用NameNode的内存空间,另一方面就是元数据文件过多,使得寻址索引速度变慢。
小文件过多,在进行MR计算时,会生成过多切片,需要启动过多的MapTask。每个MapTask处理的数据量小,导致MapTask的处理时间比启动时间还小,白白消耗资源。
4.2.2 Hadoop小文件解决方案
1)小文件优化的方向:
(1)在数据采集的时候,就将小文件或小批数据合成大文件再上传HDFS。
(2)在业务处理之前,在HDFS上使用MapReduce程序对小文件进行合并。
(3)在MapReduce处理时,可采用CombineTextInputFormat提高效率。
(4)开启uber模式,实现jvm重用
2)Hadoop Archive
是一个高效的将小文件放入HDFS块中的文件存档工具,能够将多个小文件打包成一个HAR文件,从而达到减少NameNode的内存使用
3)CombineTextInputFormat
CombineTextInputFormat用于将多个小文件在切片过程中生成一个单独的切片或者少量的切片。
4)开启uber模式,实现JVM重用。
默认情况下,每个Task任务都需要启动一个JVM来运行,如果Task任务计算的数据量很小,我们可以让同一个Job的多个Task运行在一个JVM中,不必为每个Task都开启一个JVM。
开启uber模式,在mapred-site.xml中添加如下配置:
<!-- 开启uber模式 -->
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>
<!-- uber模式中最大的mapTask数量,可向下修改 -->
<property>
<name>mapreduce.job.ubertask.maxmaps</name>
<value>9</value>
</property>
<!-- uber模式中最大的reduce数量,可向下修改 -->
<property>
<name>mapreduce.job.ubertask.maxreduces</name>
<value>1</value>
</property>
<!-- uber模式中最大的输入数据量,默认使用dfs.blocksize 的值,可向下修改 -->
<property>
<name>mapreduce.job.ubertask.maxbytes</name>
<value></value>
</property>第5章 Hadoop扩展
5.1 集群间数据拷贝
1)scp实现两个远程主机之间的文件复制
scp -r hello.txt root@hadoop103:/user/atguigu/hello.txt # 推push
scp -r root@hadoop103:/user/atguigu/hello.txt hello.txt #拉pull
scp -r root@hadoop103:/user/atguigu/hello.txtroot@hadoop104:/user/atguigu #是过本地主机中转实现两个远程主机的文件复制;如果在两个远程主机之间ssh没有配置的情况下可以使用该方式。采用distcp命令实现两个Hadoop集群之间的递归数据复制
hadoop distcp [在集群1中的文件路径] [在集群2中的文件路径]
[atguigu@hadoop102 hadoop-3.1.3]$
hadoop distcp hdfs://hadoop102:8020/user/atguigu/hello.txt hdfs://hadoop105:8020/user/atguigu/hello.txt5.2 小文件存档

1)案例实操
(1)需要启动YARN进程
[atguigu@hadoop102 hadoop-3.1.3]$ start-yarn.sh(2)归档文件
把/user/atguigu/input目录里面的所有文件归档成一个叫input.har的归档文件,并把归档后文件存储到/user/atguigu/output路径下。
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop archive -archiveName input.har-p /user/atguigu/input /user/atguigu/output
(3)查看归档
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -ls har:///user/atguigu/output/input.har(4)解归档文件
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -cp har:/// user/atguigu/output/input.har/* /user/atguigu5.3 回收站
开启回收站功能,可以将删除的文件在不超时的情况下,恢复原数据,起到防止误删除、备份等作用。
1)回收站参数设置及工作机制
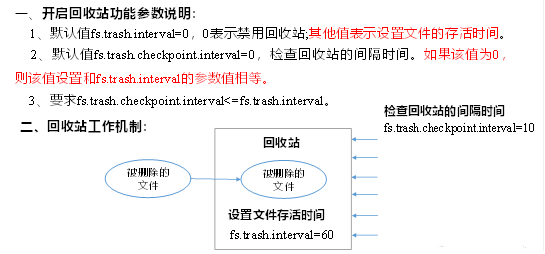
2)启用回收站
修改core-site.xml,配置垃圾回收时间为1分钟。
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property>3)查看回收站
回收站目录在hdfs集群中的路径:/user/atguigu/.Trash/….
4)通过程序删除的文件不会经过回收站,需要调用moveToTrash()才进入回收站
Configuration conf = new Configuration();
//设置HDFS的地址
conf.set("fs.defaultFS","hdfs://hadoop102:8020");
//因为本地的客户端拿不到集群的配置信息 所以需要自己手动设置一下回收站
conf.set("fs.trash.interval","1");
conf.set("fs.trash.checkpoint.interval","1");
//创建一个回收站对象
Trash trash = new Trash(conf);
//将HDFS上的/input/wc.txt移动到回收站
trash.moveToTrash(new Path("/input/wc.txt"));5)通过网页上直接删除的文件也不会走回收站。
6)只有在命令行利用hadoop fs -rm命令删除的文件才会走回收站。
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -rm -r /user/atguigu/input7)恢复回收站数据
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /user/atguigu/.Trash/Current/user/atguigu/input /user/atguigu/input