Directorio de artículos
Pre-importación
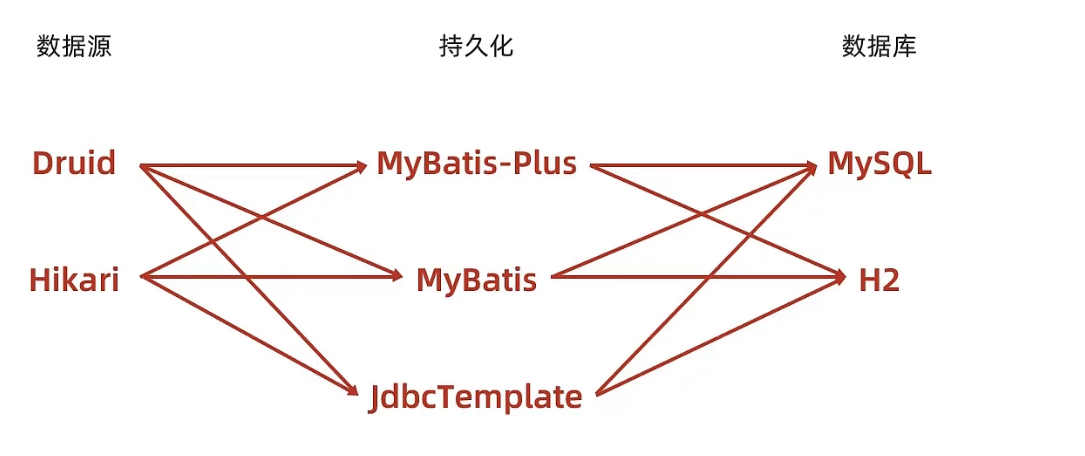
Al hacer la integración de SSMP antes, la solución de capa de datos involucraba la base de datos MySQL y el marco MyBatisPlus, y luego involucró la configuración de la fuente de datos Druid, por lo que ahora se puede decir que la solución de capa de datos es Mysql + Druid + MyBatisPlus. Las tres tecnologías corresponden a los tres niveles de operaciones de la capa de datos:
- Tecnología de fuente de datos: Druid
- Tecnología de Persistencia: MyBatisPlus
- Tecnología de base de datos: MySQL
La siguiente investigación se divide en tres niveles de investigación, correspondientes a los tres aspectos enumerados anteriormente, comencemos con la primera tecnología de fuente de datos.
tecnología de fuente de datos
Actualmente, la tecnología de fuente de datos que utilizamos es Druid, y la información de inicialización de la fuente de datos correspondiente se puede ver en el registro en tiempo de ejecución, de la siguiente manera:
INFO 28600 --- [ main] c.a.d.s.b.a.DruidDataSourceAutoConfigure : Init DruidDataSource
INFO 28600 --- [ main] com.alibaba.druid.pool.DruidDataSource : {dataSource-1} inited
Si no se utiliza la fuente de datos de Druid, ¿cómo se ve el programa después de ejecutarse? ¿Es un objeto de conexión de base de datos independiente o es compatible con otras tecnologías de agrupación de conexiones? Retire el arrancador correspondiente a la tecnología Druid y vuelva a ejecutar el programa para encontrar la siguiente información de inicialización en el registro:
INFO 31820 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Starting...
INFO 31820 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Start completed.
Aunque no hay información relacionada con DruidDataSource, encontramos que hay información sobre HikariDataSource en el registro. Incluso si no sabe qué tecnología es esta, puede verla mirando el nombre. El nombre que termina con DataSource debe ser una tecnología de fuente de datos. No agregamos esta tecnología manualmente, ¿de dónde vino esta tecnología? Es la fuente de datos incrustada Springboot.
La tecnología de capa de datos es utilizada por todas las aplicaciones de nivel empresarial, en las que se debe realizar la administración de la conexión de la base de datos. Springboot se basa en los hábitos del desarrollador. El desarrollador proporciona la tecnología de fuente de datos, solo use lo que usted proporciona, pero el desarrollador no la proporciona. Entonces no puede administrar cada objeto de conexión de base de datos manualmente. ¿Qué debo hacer? Solo le daré uno predeterminado, lo que le ahorrará preocupaciones y problemas, y es conveniente para todos.
springboot proporciona 3 tecnologías de fuentes de datos integradas, de la siguiente manera:
- HikariCP
- Tomcat proporciona fuente de datos
- Comunes DBCP
El primero es HikartCP, que es la tecnología de fuente de datos recomendada oficialmente por springboot.Utilizar como fuente de datos integrada predeterminada. ¿Qué quieres decir? Si no configura una fuente de datos, use esto.
El segundo, el DataSource proporcionado por Tomcat,Si no desea usar HikartCP y usar Tomcat como servidor web para el desarrollo de programas web, use esto. ¿Por qué Tomcat, no cualquier otro servidor web? Porque después de que la tecnología web se importa al iniciador, el tomcat incorporado se usa de forma predeterminada. Dado que es la tecnología utilizada de forma predeterminada, se usa hasta el final y la fuente de datos también la usa. ¿Alguien propuso cómo no usar el objeto de fuente de datos predeterminado proporcionado por HikartCP con tomcat? Está bien excluir las coordenadas de la tecnología HikartCP .
El tercer tipo, DBCP, las condiciones para este uso son aún más duras.Cuando no se usa HikartCP ni el DataSource de tomcat, esto se usa de forma predeterminada para usted.
Las preocupaciones de Springboot también están rotas. Me temo que no puedes administrar el objeto de conexión tú mismo. Te daré una recomendación. Es realmente el asistente más fuerte en el mundo del desarrollo. Ya que te han dado leche, entonces puedes usarla ¿Cómo configurar y usar estas cosas? Cuando configuramos druid antes, la configuración correspondiente al starter de druid es la siguiente:
spring:
datasource:
druid:
url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: ************
Después de cambiar a la fuente de datos predeterminada HikariCP, simplemente elimine el druida, de la siguiente manera:
Nota: este lugar también necesita eliminar el iniciador de druida.
spring:
datasource:
url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: *****************
Por supuesto, también puede escribir la configuración para hikari, pero la dirección url debe configurarse por separado, de la siguiente manera (es decir, otra forma de escribir):
spring:
datasource:
url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
hikari:
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: *************
Así es como se configura la fuente de datos hikari. Si desea seguir configurando hikari, puede continuar configurando sus propiedades independientes. P.ej:
spring:
datasource:
url: jdbc:mysql://localhost:3306/ssm_db?serverTimezone=UTC
hikari:
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: **************
maximum-pool-size: 50
Si no desea utilizar la fuente de datos hikari, utilice la fuente de datos tomcat o el formato de configuración DBCP es el mismo. En el futuro, cuando hagamos la capa de datos, la selección del objeto de origen de datos ya no será un uso único de la tecnología de origen de datos de druida y se podrá seleccionar de acuerdo con las necesidades.
Resumir
- La tecnología springboot proporciona 3 tecnologías de fuentes de datos integradas, a saber, Hikari, fuente de datos integrada de tomcat, DBCP
Tecnología de persistencia
Después de hablar de la solución de fuente de datos, hablemos de la solución de persistencia. Springboot aprovecha al máximo sus características auxiliares más sólidas y proporciona a los desarrolladores un conjunto de tecnología de capa de datos lista para usar llamada JdbcTemplate. De hecho, no se puede decir que springboot proporcione esta tecnología, ya que se puede utilizar sin el uso de la tecnología springboot.¿Quién la proporciona? Lo proporciona la tecnología spring, por lo que en la categoría de tecnología springboot, esta tecnología también existe.Después de todo, la tecnología springboot se crea para acelerar el desarrollo de programas spring.
Esta tecnología es en realidad un regreso a la forma de programación más primitiva de jdbc para el desarrollo de la capa de datos.Los siguientes pasos se realizan directamente:
Paso 1 : Importe las coordenadas correspondientes a jdbc, recuerde el motor de arranque
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
Paso 2 : ensamble automáticamente el objeto JdbcTemplate
@SpringBootTest
class Springboot15SqlApplicationTests {
@Test
void testJdbcTemplate(@Autowired JdbcTemplate jdbcTemplate){
}
}
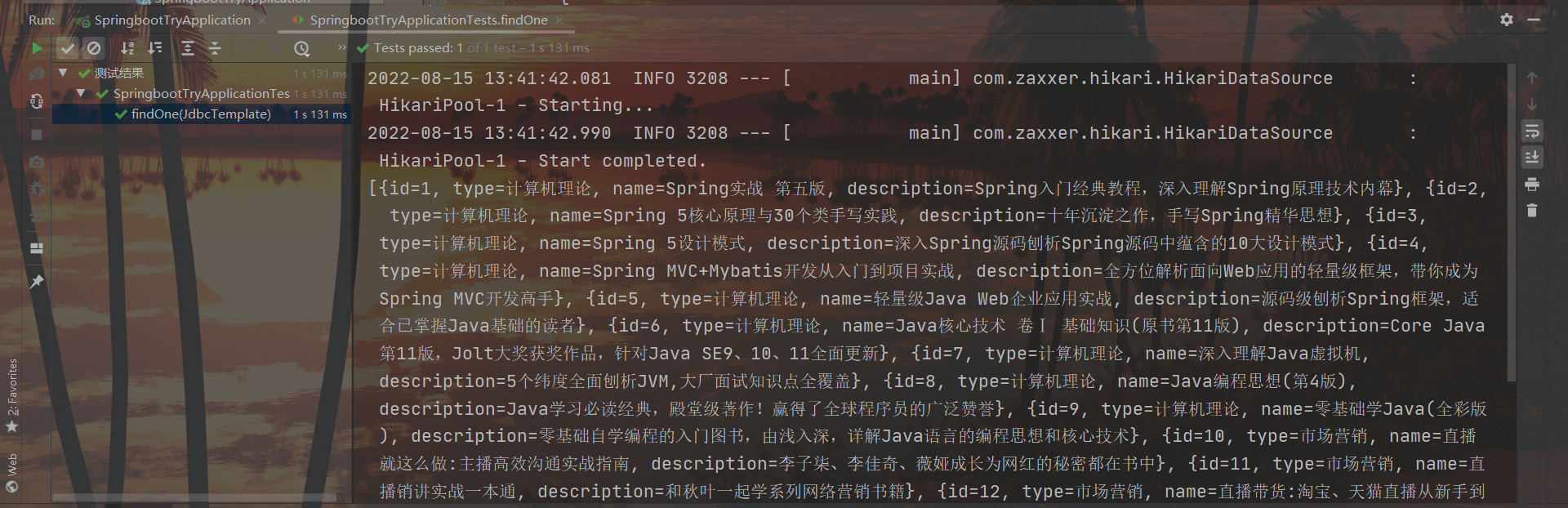
Paso 3 : use JdbcTemplate para implementar operaciones de consulta (operaciones de consulta para datos encapsulados de clase que no son de entidad)
@Test
void testJdbcTemplate(@Autowired JdbcTemplate jdbcTemplate){
String sql = "select * from tbl_book";
List<Map<String, Object>> maps = jdbcTemplate.queryForList(sql);
System.out.println(maps);
}
resultado:
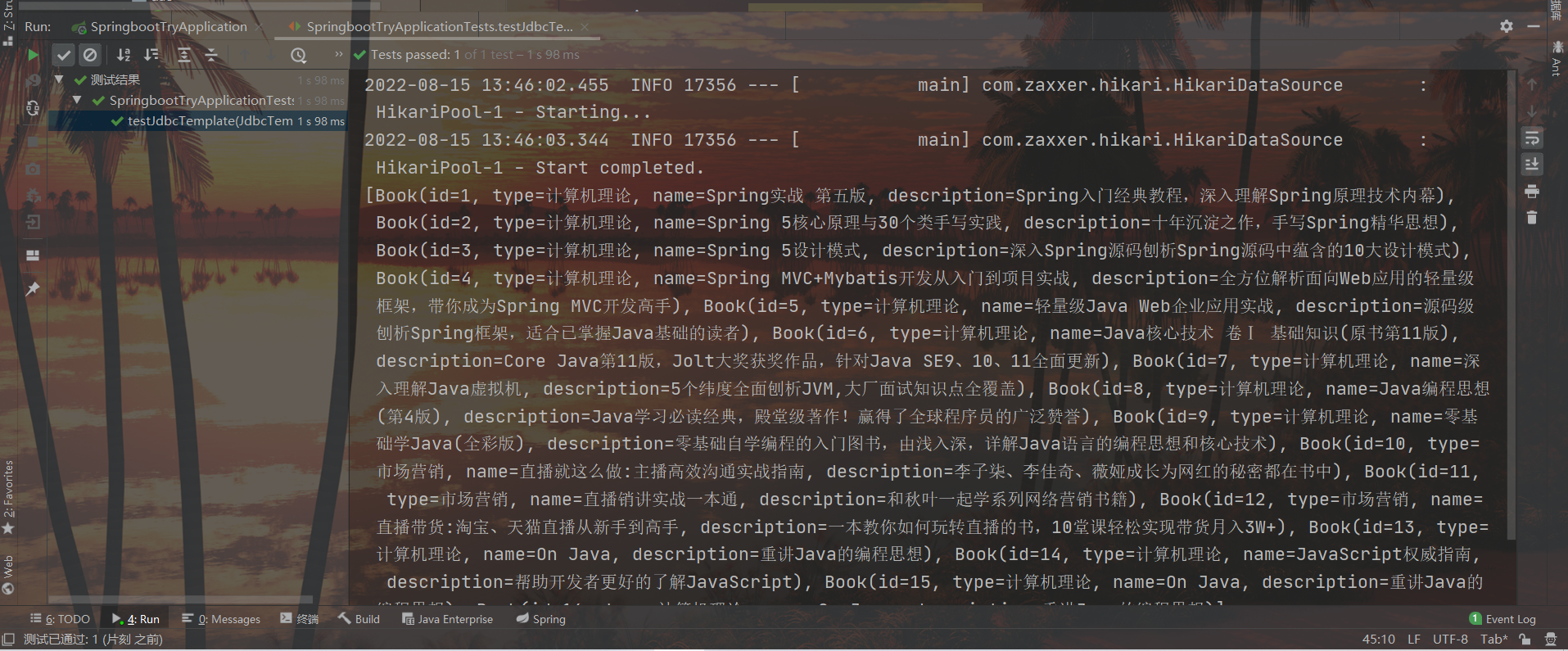
Paso 4 : use JdbcTemplate para implementar operaciones de consulta (las clases de entidad encapsulan las operaciones de consulta de datos)
@Test
void testJdbcTemplate(@Autowired JdbcTemplate jdbcTemplate){
String sql = "select * from tbl_book";
RowMapper<Book> rm = new RowMapper<Book>() {
@Override
public Book mapRow(ResultSet rs, int rowNum) throws SQLException {
Book temp = new Book();
temp.setId(rs.getInt("id"));
temp.setName(rs.getString("name"));
temp.setType(rs.getString("type"));
temp.setDescription(rs.getString("description"));
return temp;
}
};
List<Book> list = jdbcTemplate.query(sql, rm);
System.out.println(list);
}
resultado:
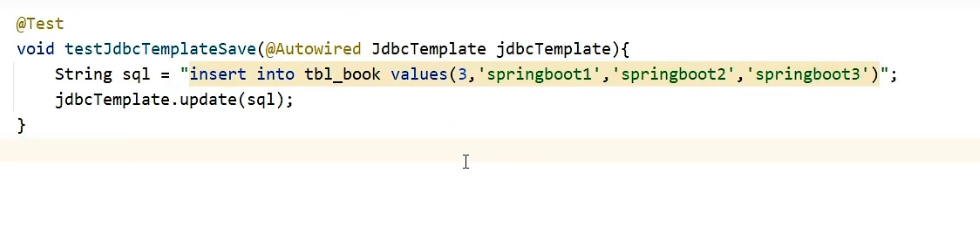
Paso ⑤ : use JdbcTemplate para implementar operaciones de adición, eliminación y modificación
@Test
void testJdbcTemplateSave(@Autowired JdbcTemplate jdbcTemplate){
String sql = "insert into tbl_book values(3,'springboot1','springboot2','springboot3')";
jdbcTemplate.update(sql);
}
Si desea configurar el objeto JdbcTemplate, puede configurarlo en el archivo yml, de la siguiente manera:
spring:
jdbc:
template:
query-timeout: -1 # 查询超时时间
max-rows: 500 # 最大行数
fetch-size: -1 # 缓存行数
fetch-sizePuede mejorar el rendimiento de nuestras consultas. Por ejemplo, ahora comprobamos 10.000 datos, ¿cuántos datos nos dan a la vez? Esto puedefetch-sizeser controlado por. Si damos cincuenta a la vez, y también usamos estos cincuenta, entonces la eficiencia será muy alta. Y si usamos más de 50, volverá y la eficiencia se reducirá.
Resumir
- Solución de persistencia JdbcTemplate integrada de SpringBoot
- El uso de JdbcTemplate necesita importar las coordenadas de spring-boot-starter-jdbc
Tecnología de base de datos
Hasta ahora, Springboot ha brindado a los desarrolladores soluciones integradas de fuente de datos y soluciones de persistencia. Queda una base de datos en la solución de capa de datos de tres piezas. ¿Podría ser que Springboot también proporcione soluciones integradas? Hay, no uno, sino tres
springboot proporciona 3 bases de datos integradas, a saber:
- H2
- HSQL
- derby
Además de la instalación independiente de las tres bases de datos anteriores . Incrustado en el contenedor para ejecutarse, debe ser un objeto Java, sí, la capa inferior de estas tres bases de datos se desarrolla utilizando el lenguaje Java.
Hemos estado usando la base de datos MySQL todo el tiempo, entonces, ¿por qué es necesario usar esto?La razón es que estas tres bases de datos se pueden ejecutar en forma de contenedores incrustados.Después de que la aplicación se ejecuta, si realizamos un trabajo de prueba, los datos bajo prueba no necesitan almacenarse en el disco, pero deben usarse para prueba Conveniente, se ejecuta en la memoria, es hora de probar, es hora de ejecutar, y cuando el servidor se apaga, todo desaparece, lo cual es excelente, ya que le evita tener que mantener una base de datos externa. Esta es también la mayor ventaja de la base de datos integrada, que es conveniente para las pruebas funcionales.
A continuación se toma la base de datos H2 como ejemplo para explicar cómo usar estas bases de datos integradas. Los pasos de operación también son muy simples. Simple es fácil de usar.
Paso 1 : Importar las coordenadas correspondientes a la base de datos H2, un total de 2
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
Paso 2 : configure el proyecto como un proyecto web e inicie la base de datos H2 al iniciar el proyecto
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
Paso ③ : Abra el programa de acceso a la consola de la base de datos H2 a través de la configuración, o use otro software de conexión a la base de datos para operar
spring:
h2:
console:
enabled: true
path: /h2
Después de eso, iniciamos el servidor y luego accedemos a localhost/h2 (el puerto se ha configurado en 80 de antemano), la página muestra:
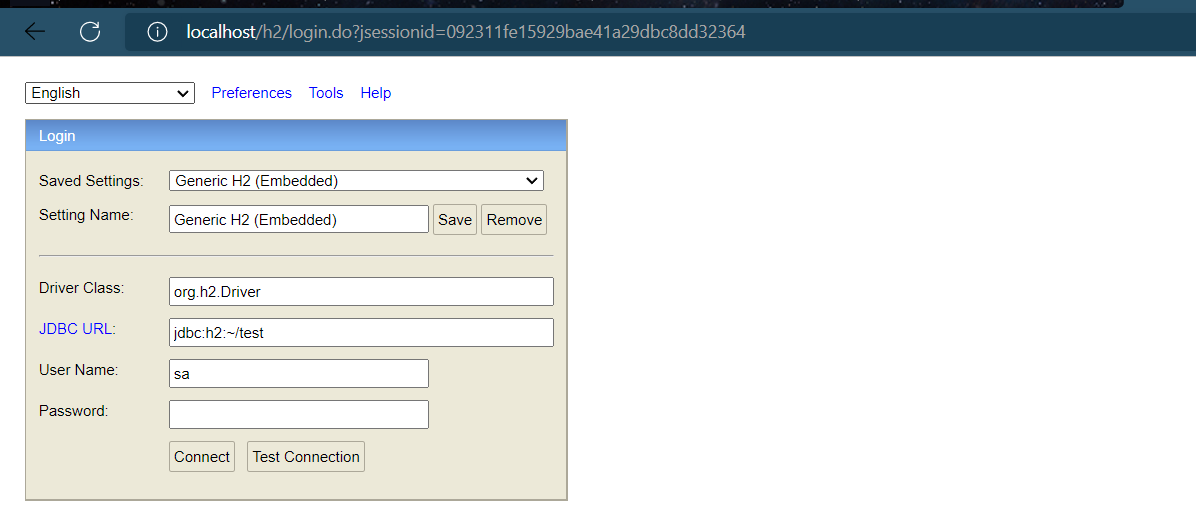
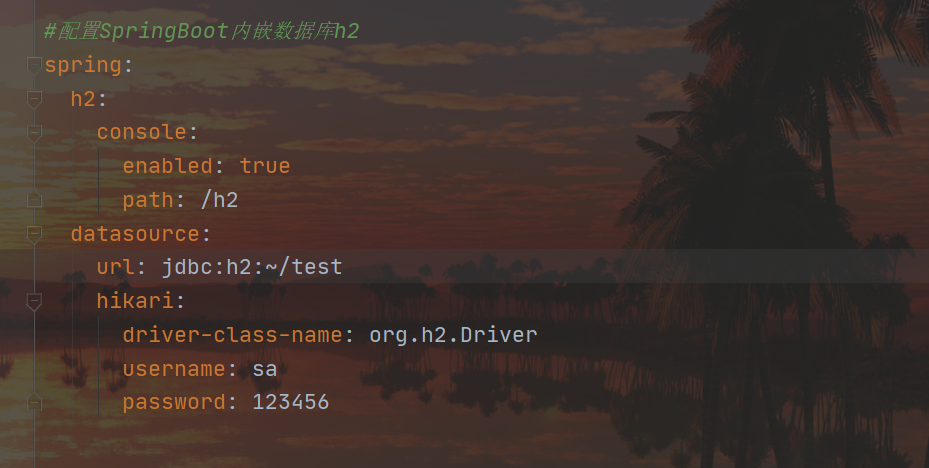
ruta de acceso del lado web /h2, contraseña de acceso 123456, si el acceso falla, configure lo siguiente fuentes de datos primero, después de que se ejecute el programa de inicio Acceda a la ruta /h2 nuevamente y podrá acceder a ella normalmente (después de un acceso exitoso, también puede eliminar el siguiente contenido)
datasource:
url: jdbc:h2:~/test
hikari:
driver-class-name: org.h2.Driver
username: sa
password: 123456
Luego ingresamos a la siguiente página web:
Podemos crear una tabla primero:
Luego miramos la tabla:
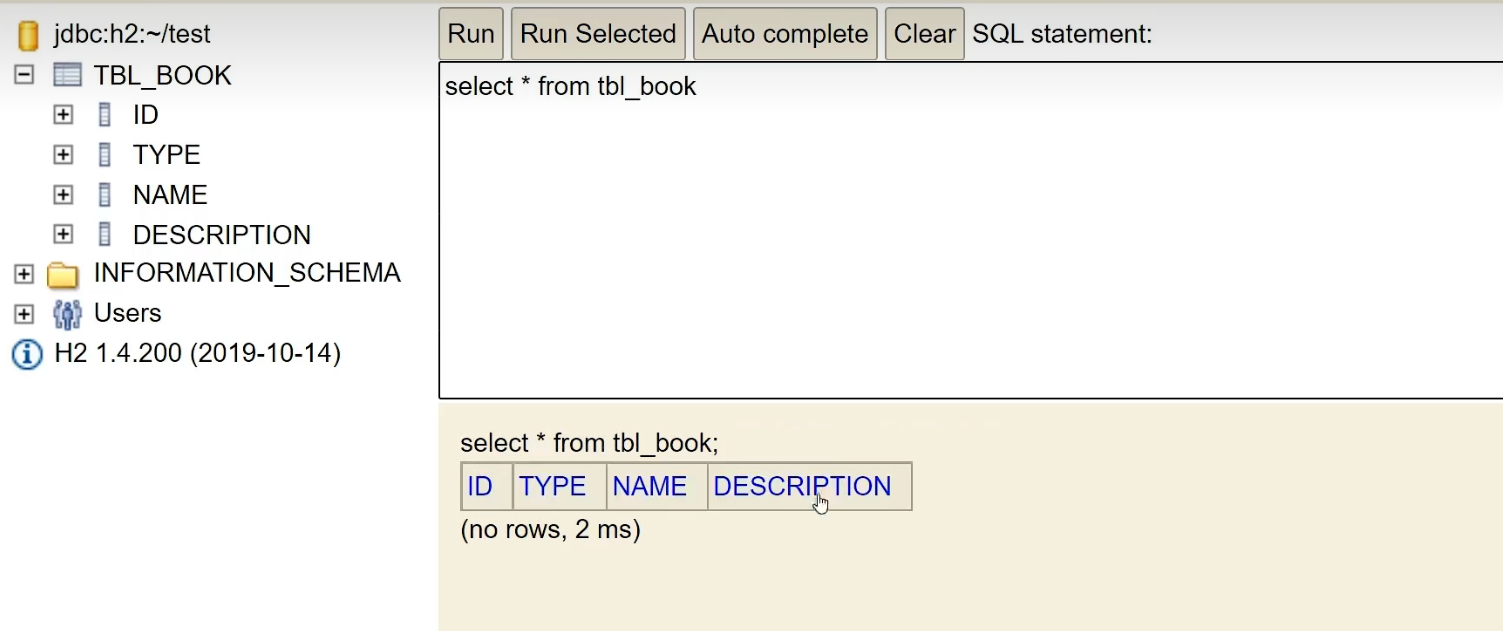
le agregamos dos datos:
insert into tbl_book values(1,'springboot','springboot','springboot')
insert into tbl_book values(2,'springboot2','springboot2','springboot2')
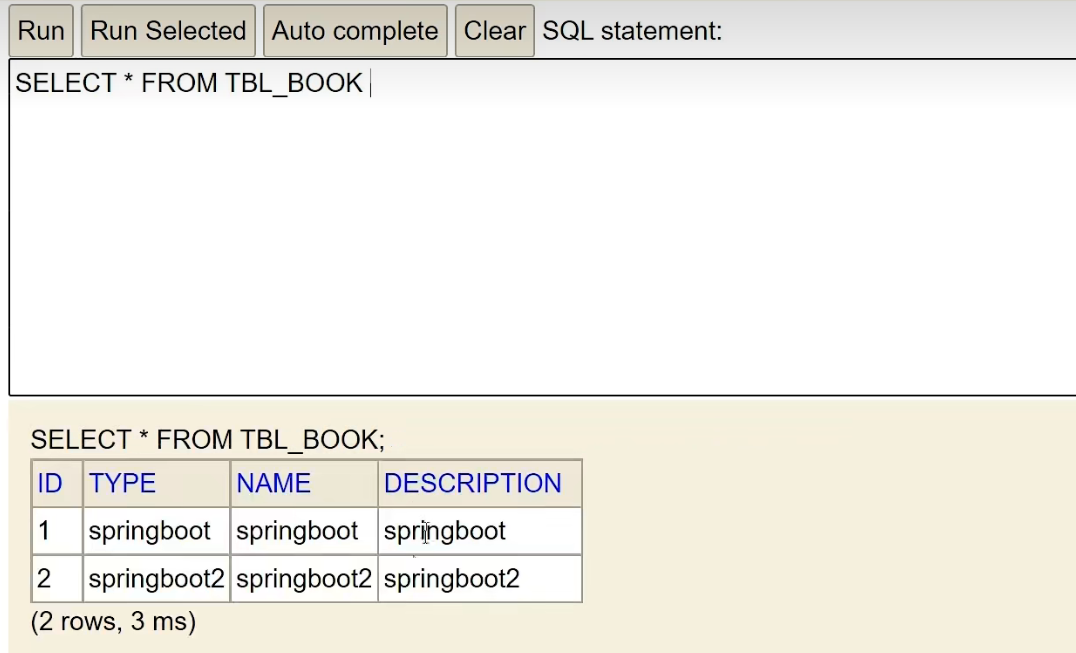
Revisemos la tabla nuevamente y descubramos que los datos se agregaron correctamente:
Paso ④ : Use la tecnología JdbcTemplate o MyBatisPlus para operar la base de datos
Aquí solo hablamos de JdbcTemplate, la tecnología MyBatisPlus es la misma que antes.
En este punto, la fuente de datos debe estar escrita:
la información de configuración de la fuente de datos se escribe cuando ingresamos por primera vez a la página web de h2
Probemos agregándole datos:

De hecho, acabamos de cambiar una base de datos, otras cosas no se ven afectadas. Un recordatorio importante, no olvide, cuando se conecte, cierre la base de datos en memoria y use la base de datos MySQL como esquema de persistencia de datos. La forma de cerrarla es establecer el atributo habilitado en falso.

Resumir
- Método de inicio de la base de datos integrada H2, agregar coordenadas, agregar configuración
- Asegúrese de cerrar la base de datos H2 cuando se esté ejecutando en línea
En este punto, hemos terminado de hablar sobre las soluciones de capa de datos relacionadas con SQL y ahora las tecnologías opcionales son mucho más ricas.
- Tecnología de fuente de datos: Druid, Hikari, tomcat DataSource, DBCP
- Tecnología de persistencia: MyBatisPlus, MyBatis, JdbcTemplate
- Tecnología de base de datos: MySQL, H2, HSQL, Derby
Ahora puede elegir una de las tecnologías anteriores para organizar una solución de base de datos al desarrollar un programa.