Concepto de agrupación
La agrupación en clústeres es un método de aprendizaje automático no supervisado que descubre principalmente patrones y estructuras en los datos al encontrar muestras similares en un conjunto de datos y agruparlas. Los algoritmos de agrupamiento pueden dividir datos en grupos con características similares, y cada grupo se denomina clúster.
Los algoritmos de agrupamiento comunes incluyen los siguientes:
-
Algoritmo de agrupamiento de K-medias: es uno de los algoritmos de agrupamiento más comunes. Su objetivo es dividir el conjunto de datos en K grupos para que los puntos de datos en cada grupo tengan la mayor similitud y las mayores diferencias entre diferentes grupos.
-
Algoritmo de agrupación jerárquica: este algoritmo fusiona gradualmente las muestras del conjunto de datos hasta que se forma una estructura de agrupación completa, formando así un árbol de agrupación.
-
Algoritmo de agrupación de densidad: es un algoritmo de agrupación basado en la densidad de los puntos de datos, que divide los puntos de datos en áreas densas y áreas dispersas, y trata el área densa como un grupo.
-
Algoritmo de agrupación por desplazamiento medio: este algoritmo utiliza la estimación de la densidad del núcleo para encontrar máximos locales de puntos de datos para determinar los centroides de los conglomerados.
-
Algoritmo de agrupamiento DBSCAN: determina el número y la forma de los grupos en función de la densidad del conjunto de datos y puede identificar grupos de cualquier forma.
Introducción a K-medias
K-means es un algoritmo de agrupamiento basado en la métrica de distancia. Su idea principal es dividir el conjunto de datos en K grupos, y cada grupo contiene los K puntos de datos más cercanos. Este algoritmo ajusta continuamente la división del conglomerado optimizando iterativamente el punto central del conglomerado y finalmente obtiene un conjunto de resultados óptimos de la división del conglomerado.
En términos sencillos, el algoritmo K-means es como un estudiante de escuela primaria supuestamente inteligente que juega un juego de "adivina el número". Primero adivinará un número y luego dividirá el rango de números donde se encuentra la respuesta en dos áreas según la distancia entre la suposición y la respuesta correcta (cuanto más cerca esté la respuesta, menor será la distancia). Luego, repetirá este proceso hasta que el rango digital se divida en K áreas y registrará el punto central de cada área. Finalmente, te dirá a qué región (o grupo) debe pertenecer cada número y te dirá el punto central de cada región.
En el algoritmo K-medias, debemos especificar el número de grupos K y luego seleccionar aleatoriamente K puntos de datos como puntos centrales iniciales. A continuación, calculamos la distancia de cada punto de datos desde cada punto central y lo clasificamos en el grupo más cercano. Luego, vuelva a calcular el punto central de cada grupo y repita el proceso anterior (reclasificando cada punto en un grupo después de calcular el nuevo centro) hasta que el punto central del grupo ya no cambie. Con el tiempo, obtendremos K grupos, cada grupo contiene un conjunto de puntos de datos más cercanos y cada punto de datos pertenece a un solo grupo.
Cabe señalar que dado que el punto central inicial del algoritmo K-medias se selecciona aleatoriamente, se pueden obtener diferentes resultados de división de conglomerados. Para obtener mejores resultados, el algoritmo se puede ejecutar varias veces y se selecciona el resultado óptimo de partición del clúster.
La diferencia entre K-medias y KNN
K-Means y K-NN son dos algoritmos de aprendizaje automático diferentes, cuyas diferencias son las siguientes:
-
K-Means es un algoritmo de agrupación que divide un conjunto de datos en K grupos y asigna cada punto de datos a su centro de grupo más cercano. K-NN es un algoritmo de clasificación que predice la etiqueta de un nuevo punto de datos en función de la etiqueta de su vecino más cercano.
-
K-Means requiere especificar el número de grupos K, pero K-NN no.
-
K-Means es un algoritmo de aprendizaje no supervisado que no requiere datos etiquetados, mientras que K-NN es un algoritmo de aprendizaje supervisado que requiere datos etiquetados.
-
K-Means usa la distancia euclidiana para calcular la similitud entre puntos de datos, mientras que K-NN puede usar diferentes medidas de distancia, como la distancia de Manhattan, la similitud del coseno, etc.
-
K-Means puede encontrar problemas de rendimiento al procesar datos a gran escala, mientras que K-NN puede manejar datos a gran escala fácilmente.
En general, K-Means y K-NN son dos algoritmos de aprendizaje automático diferentes adecuados para diferentes problemas y conjuntos de datos.
Proceso de cálculo de Kmedias
(1) Seleccione apropiadamente los centros iniciales de c clases;
(2) En k iteraciones, para cualquier muestra, encuentre la distancia ( distancia euclidiana ) a cada centro de c, y clasifique la muestra al centro con una clase de distancia más corta;
( 3) Utilice métodos como la media para actualizar el valor central de la clase;
(4) Para todos los centros del clúster c, si el valor permanece sin cambios después de la actualización utilizando el método iterativo de (2) (3), entonces itere Fin; de lo contrario, continúe iteración.
Supongamos que hay 4 conjuntos de datos, cada conjunto de datos tiene 2 dimensiones, agrúpelos en 2 categorías y visualícelos.
A = ( 1 , 1 ) , B = ( 2 , 1 ) , C = ( 4 , 3 ) , D = ( 5 , 4 ) A=(1,1),B=(2,1),C=( 4,3),D=(5,4)A=( 1 ,1 ) ,B=( 2 ,1 ) ,C=( 4 ,3 ) ,D=( 5 ,4 )
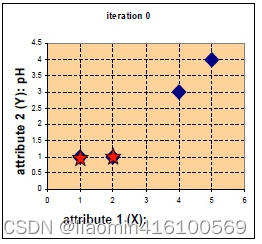
Supongamos que las posiciones de las dos estrellas se seleccionan como centros inicialesc 1 = ( 1 , 1 ) , c 2 = ( 2 , 1 ) c_1=(1,1),c_2=(2,1)C1=( 1 ,1 ) ,C2=( 2 ,1 ) , calcule la distancia desde cada punto al centro inicial, use la distancia euclidiana para obtener las distancias de 4 puntos desde los dos centros iniciales respectivamente y clasifíquelos en la clase más cercana:

D 0 La primera línea representa un ejemplo de cuatro puntos ABCD a c 1, y la segunda línea representa un ejemplo de cuatro puntos ABCD a c 2. El ejemplo se calcula usando la fórmula de distancia euclidiana. Tomando C como ejemplo, el grupo a c 1 El ejemplo de este grupo es 3.61, y el ejemplo de este grupo para c 2 es 2.83, lo que indica que la primera iteración C pertenece al grupo − 2 D ^ 0. La primera línea de D ^ 0 representa el ejemplo de cuatro puntos. ABCD a c1, y la segunda línea representa los cuatro puntos de ABCD. El ejemplo para c2 se calcula usando la fórmula de distancia euclidiana. Tomando C como ejemplo, el ejemplo para el grupo c1 es 3,61 y el ejemplo para el grupo c2 es 2,83, indicando que la primera iteración C pertenece al grupo 2.D0 La primera línea representacuatro puntosABCDc1, y la segunda línea representacuatro puntosABCDc2.El ejemplo se calcula utilizando la fórmula de distancia euclidiana. TomandoCcomo ejemplo, ac1Un ejemplo de este grupo es3,61,El ejemplo del grupo c 2 es 2.83 , lo que indica que la primera iteración C pertenece al grupo−2
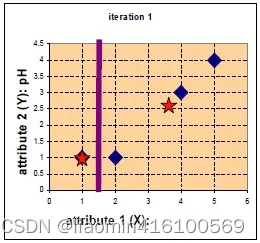
Clasifícalos por comparación. Y utilice el método de promediado para actualizar la posición central. Dado que solo hay un punto que pertenece al grupo1, la posición central c 1 = ( 1 , 1 ) c_1=(1,1)
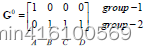
después de una actualizaciónC1=( 1 ,1 ) , yc 2 = ( 11 3 , 8 3 ) c_{2} = (\frac{11}{3}, \frac{8}{3})C2=(311,38)
El nuevo punto central del grupo2 es x = ( x 1 + x 2 + x 3 ) 3 = ( 2 + 4 + 5 ) 3 = 11 3 x={(x1+x2+x3)\over 3} ={(2 +4+5)\sobre3}={11\sobre3}X=3( x1 + x2 + x3 ) . _ _=3( 2 + 4 + 5 )=311
y = ( y 1 + y 2 + y 3 ) 3 = ( 1 + 3 + 4 ) 3 = 8 3 y={(y1+y2+y3)\sobre 3} ={(1+3+4)\sobre3 }={8\sobre3}y=3( y1 + y2 + y3 ) _ _ _=3( 1 + 3 + 4 )=38
Nuevamente calcule la distancia de cada punto desde el centro de ubicación actualizado

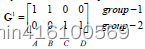
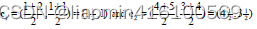
Continúe iterando.
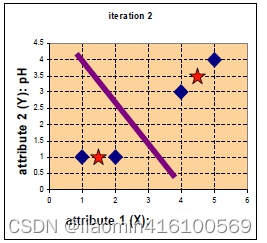

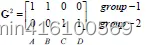
En este momento, si no hay cambios desde la última marca de categoría, puede detenerse.
Implementación de programación de Kmeans.
#%%
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 生成随机数据
X, y = make_blobs(n_samples=300, centers=4, random_state=42)
# 使用KMeans算法进行聚类
kmeans = KMeans(n_clusters=4, random_state=42)
kmeans.fit(X)
# 绘制聚类结果
plt.scatter(X[:, 0], X[:, 1], c=kmeans.labels_, cmap='viridis')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], marker='*', s=150, color='red')
plt.show()
