1. Información general
La base de datos DolphinDB es una base de datos de series de tiempo distribuida de alto rendimiento (base de datos de series de tiempo), una base de datos relacional en columnas, escrita en C ++, con un marco de computación distribuido y paralelo incorporado, que se puede utilizar para procesar datos en tiempo real y datos históricos masivos.
Además de proporcionar su propio lenguaje de scripting, DolphinDB también proporciona API de lenguaje de programación como C ++, Java, C #, Python, R, etc., para que los desarrolladores puedan usar DolphinDB en una variedad de entornos de desarrollo diferentes.
Este artículo probará el rendimiento de la interfaz API (C ++, Java, C #, Python, R) y la interacción DolphinDB, incluidos los siguientes escenarios:
- Datos de carga de un solo usuario a la tabla de memoria
- Varios usuarios cargan datos simultáneamente en una base de datos distribuida (DFS)
- Los múltiples usuarios descargan simultáneamente datos de DolphinDB al cliente
- Los usuarios múltiples envían simultáneamente tareas de cálculo (calculan la línea k a nivel de minutos de una determinada acción en un día determinado) a DolphinDB y devuelven el resultado
2. Entorno de prueba
2.1 Configuración de hardware
Esta prueba utiliza tres servidores con la misma configuración (SERVER1, SERVER2, SERVER3), y la configuración de cada servidor es la siguiente:
Anfitrión: PowerEdge R730xd
CPU: E5-2650 24 núcleos 48 hilos
Memoria: 512G
Disco duro: HDD 1.8T * 12
Red: 10 Gigabit Ethernet
SO: CentOS Linux versión 7.6.1810
2.2 Configuración del software
C ++: GCC 4.8.5
JRE: 1.8.0
C #: .net 2.2.105
Python: 3.7.0
R: 3.5.2
DolphinDB: 0.94.2
2.3 Marco de prueba
El clúster de DolphinDB se implementa en SERVER1, y el programa API se ejecuta en SERVER2 y SERVER3, y está conectado al nodo de datos DolphinDB en SERVER1 a través de la red para realizar pruebas.
La configuración del clúster de DolphinDB es la siguiente:
El clúster contiene 1 nodo de control y 6 nodos de datos;
Memoria: 32G / nodo * 6 nodos = 192G
Subproceso: 8 subprocesos / nodo * 6 nodos = 48 subprocesos
Disco duro: cada nodo está equipado con un disco duro HDD independiente, 1.8T / nodo * 6 = 9.6T
3. Prueba de rendimiento de carga de datos de un solo usuario
Esta sección prueba a un solo usuario para cargar datos al servidor DolphinDB a través de la API. Cree una tabla de memoria en el clúster DolphinDB de SERVER1, ejecute el programa API en SERVER2 y escriba los datos en la tabla de memoria de SERVER1.
Los campos de la tabla de datos escritos incluyen diferentes tipos de campos como STRING, INT, LONG, SYMBOL, DOUBLE, DATE, TIME, etc., con un total de 45 columnas, cada una con 336 bytes, y un total de 1 millón de filas cargadas. con un tamaño de aproximadamente 336Mb. Pruebe el rendimiento y la latencia al cargar de 10 a 100,000 filas cada vez.
Debido a que este escenario es un usuario único y no involucra operaciones de disco, principalmente prueba el rendimiento de conversión del formato de datos del programa API al formato de datos DolphinDB. El rendimiento de la CPU y la red tendrán un mayor impacto en los resultados de la prueba. Los resultados de las pruebas de cada API son los siguientes:
Tabla 1. Resultados de la prueba de carga de un solo usuario de la API de C ++ a la tabla de memoria
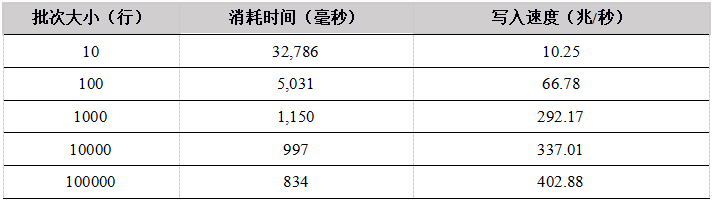
Tabla 2. Resultados de la prueba de datos de carga de un solo usuario de la API de Java a la tabla de memoria
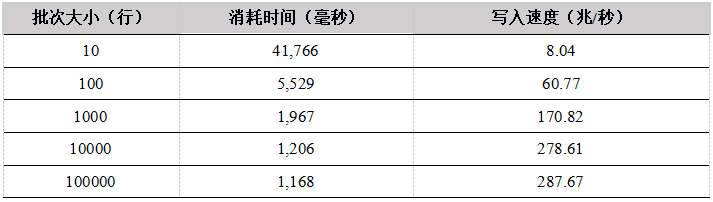
Tabla 3. Resultados de la prueba de carga de un solo usuario de API de C # a la tabla de memoria
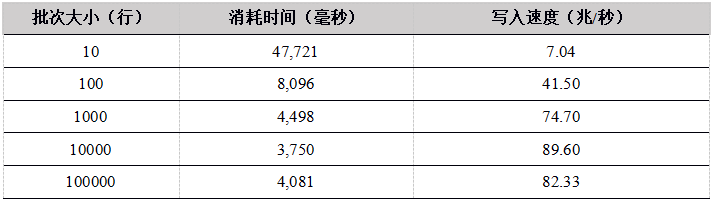
Tabla 4. Resultados de la prueba de carga de un solo usuario de la API de Python a la tabla de memoria
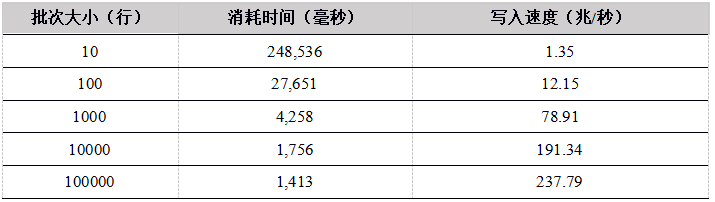
Tabla 5. Resultados de la prueba de datos de carga de un solo usuario de R API a la tabla de memoria
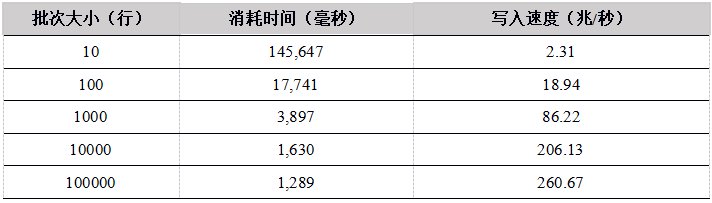
Tabla 6. Comparación de la velocidad de escritura de cada usuario de API que carga datos en la tabla de memoria (unidad: mega / segundo)
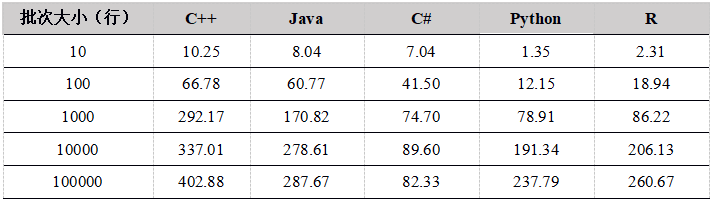
Figura 1. Comparación del rendimiento de la API de carga de datos a la tabla de memoria
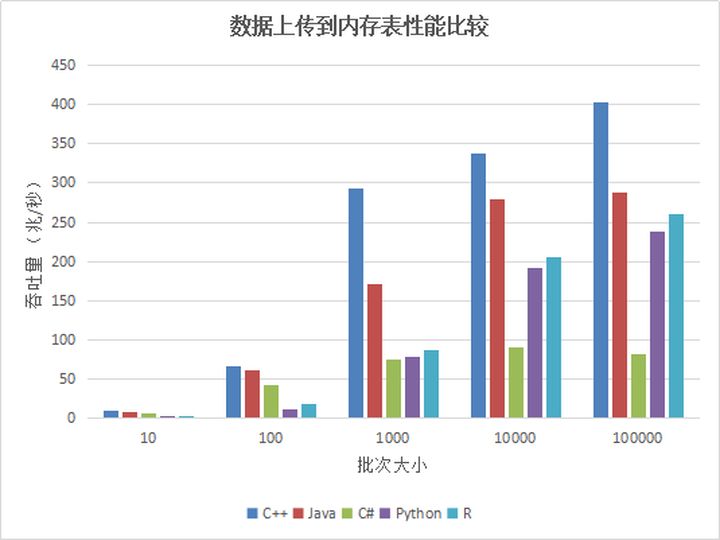
Desde los resultados de la prueba de escritura en la tabla de memoria por un solo usuario, a medida que aumenta el tamaño del lote, el rendimiento mejora significativamente. Esto se debe a que cuando la cantidad total de datos es la misma, cuantas más filas de datos se cargan al mismo tiempo, Menos tiempos de carga., Menos comunicaciones de red.
C ++ tiene el mejor rendimiento y C # tiene un rendimiento deficiente. Las implementaciones subyacentes de Python y R se han reescrito en C ++ y las tendencias de rendimiento son las mismas. Cuando el tamaño del lote es pequeño, el módulo C ++ se llama más veces, lo que provocará una mayor pérdida de rendimiento y un peor rendimiento. Cuando el tamaño del lote alcanza más de 1000 filas, el rendimiento mejora significativamente. Recomendamos que al cargar datos con Python y R, intente aumentar el tamaño del lote de carga.
4. Prueba de rendimiento de datos de carga simultánea de múltiples usuarios
En esta sección, la prueba usa la API para cargar simultáneamente datos a la tabla de datos DFS de SERVER1 por varios usuarios.En SERVER2 y SERVER3, varios usuarios inician simultáneamente operaciones de escritura a través de la red.
Cada usuario escribe un total de 5 millones de filas y cada uno escribe 25.000 filas, cada una con 336 bytes, por lo que la cantidad total de datos escritos por cada usuario es de 840Mb. Pruebe la latencia y el rendimiento de las escrituras simultáneas cuando el número de usuarios simultáneos es 1 ~ 128.
Distribuimos uniformemente el número de usuarios que se ejecutarán en SERVER2 y SERVER3. Por ejemplo, cuando se prueban 16 usuarios, dos servidores ejecutan cada uno 8 programas cliente. La prueba implica escritura simultánea. Los datos escritos se transmiten al SERVER1 a través de la red y se almacenan en el disco. Por lo tanto, se puede probar si el sistema DolphinDB puede hacer un uso completo de la CPU del servidor, el disco duro, la red y otros recursos. Los resultados de las pruebas de cada API son los siguientes:
Tabla 7. Carga simultánea de datos de múltiples usuarios de la API de C ++ a los resultados de la prueba de la tabla DFS
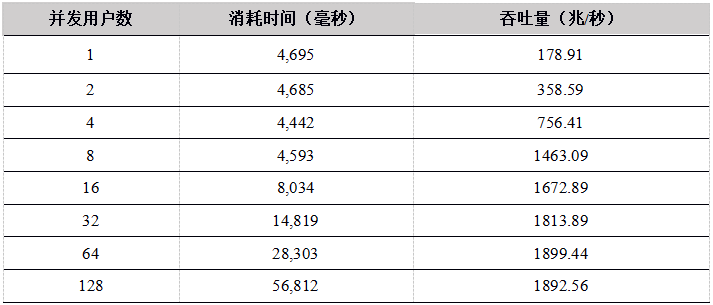
Tabla 8. Datos de carga simultánea multiusuario de la API de Java a los resultados de la prueba de la tabla DFS
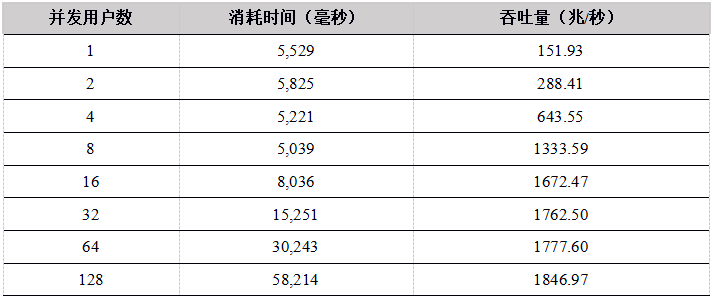
Tabla 9. Datos de carga simultánea de múltiples usuarios de C # API a los resultados de la prueba de la tabla DFS
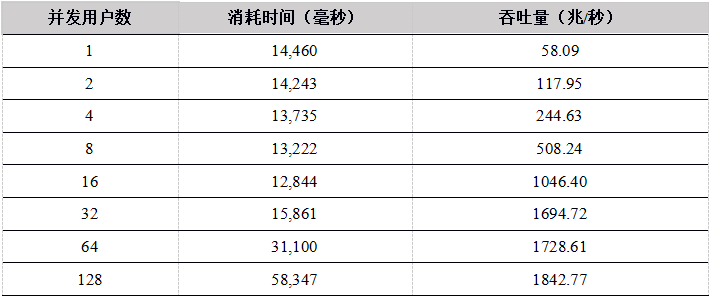
Tabla 10. Datos de carga simultánea multiusuario de la API de Python a los resultados de la prueba de la tabla DFS
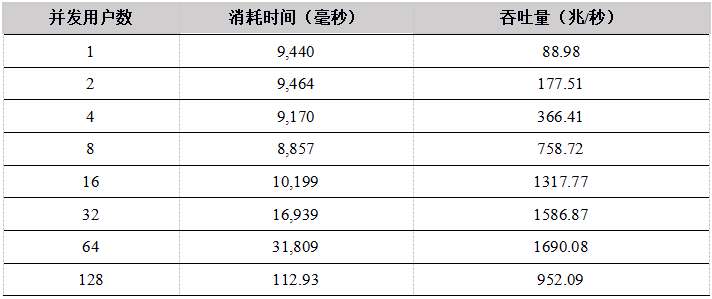
Tabla 11. Datos de carga simultánea de múltiples usuarios de R API a los resultados de la prueba de la tabla DFS
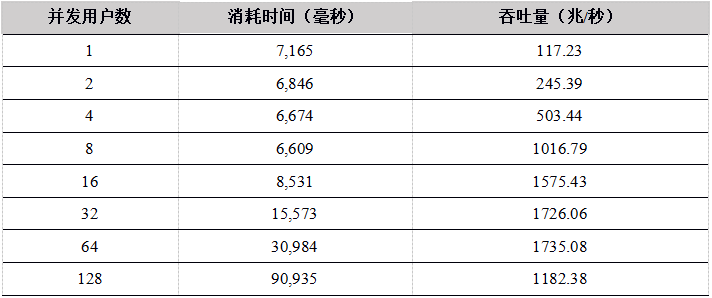
Tabla 12. Comparación de los resultados de las pruebas de carga de varios datos API en la tabla DFS (unidad: mega / segundo)
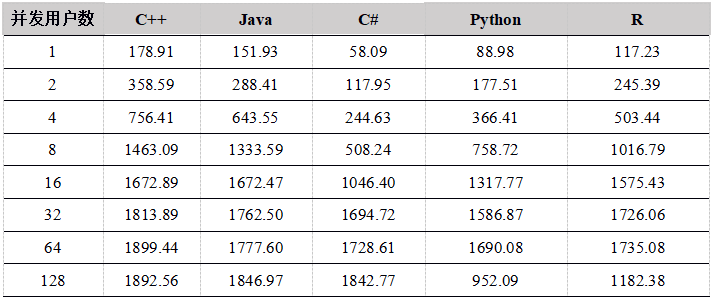
Figura 2. Comparación de rendimiento de la carga de datos de API a la tabla DFS
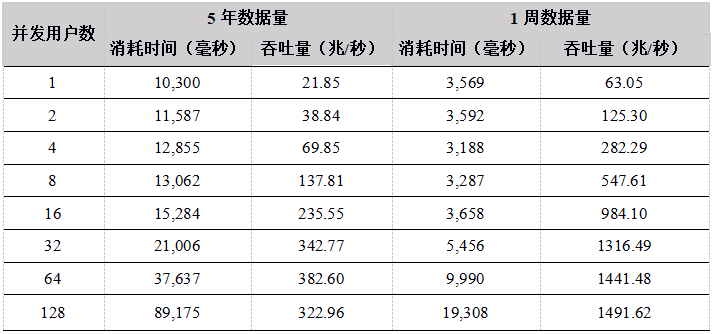
Los resultados de la prueba muestran que cuando el número de usuarios es menor a 16, las ventajas de rendimiento de C ++ y Java son obvias, mientras que el rendimiento de Python y C # es ligeramente peor y el rendimiento aumenta básicamente de forma lineal. Cuando el número de usuarios supera los 16, la transmisión de la red alcanza su límite, convirtiéndose en un cuello de botella de rendimiento, y el rendimiento se mantiene básicamente en el límite de la red. La red es 10 Gigabit Ethernet con un límite de 1G, pero debido a que los datos transmitidos están comprimidos, el rendimiento del sistema puede alcanzar hasta 1.8G / seg.
5. Prueba de rendimiento de datos de descarga simultánea multiusuario
Esta sección prueba la velocidad de descarga de datos de DolphinDB simultáneamente por varios usuarios a través de la API. La base de datos se implementa en SERVER1, varios usuarios descargan datos al mismo tiempo en SERVER2 y SERVER3, y cada usuario selecciona aleatoriamente un nodo de datos para conectarse. La cantidad total de datos descargados por cada usuario es de 5 millones de filas, cada fila es de 45 bytes, un total de 225 Mb, y cada descarga de datos es de 25,000 filas, y el rendimiento simultáneo en el escenario en el que el número de usuarios simultáneos es de 1 a 128 son probados.
Probamos el rendimiento de los datos de descarga de clientes simultáneos en los dos escenarios siguientes:
- Volumen de datos de 5 años: seleccione aleatoriamente la fecha y el símbolo para descargar de los datos de 5 años, la cantidad de datos involucrados es de aproximadamente 12T. Dado que la cantidad de datos supera en gran medida la memoria del sistema, cada descarga necesita cargar datos desde el disco;
- Volumen de datos de 1 semana: seleccione aleatoriamente símbolos de los datos de la última semana para descargar, el volumen de datos involucrado es de aproximadamente 60G. La memoria asignada a DolphinDB es suficiente para almacenar 60 G de datos, y todos los datos están en la caché, por lo que no es necesario cargar datos desde el disco para cada descarga.
Los resultados de la prueba de rendimiento de cada API son los siguientes:
Tabla 13. Resultados de la prueba de datos de descarga de datos de la API de C ++
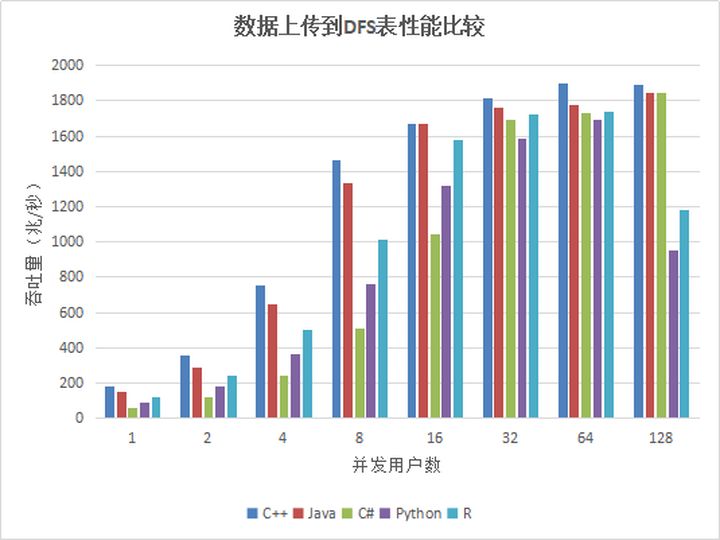
Tabla 14. Resultados de la prueba de datos de descarga de datos de la API de Java
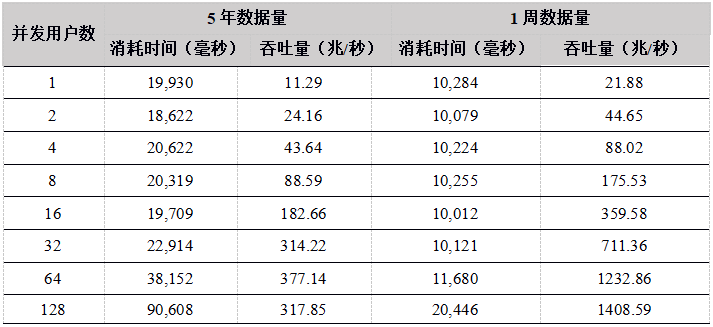
Tabla 15. Resultados de la prueba de descarga de datos de la API de C #
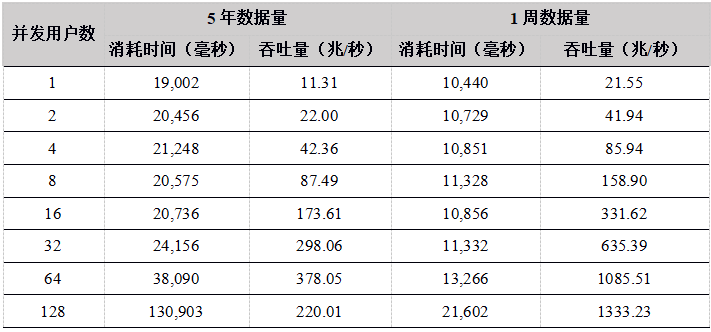
Tabla 16. Resultados de la prueba de descarga de datos de la API de Python
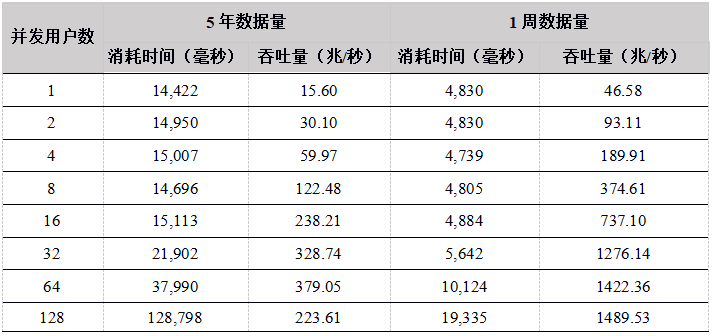
Tabla 17. Resultados de la prueba de datos de descarga de datos de R API
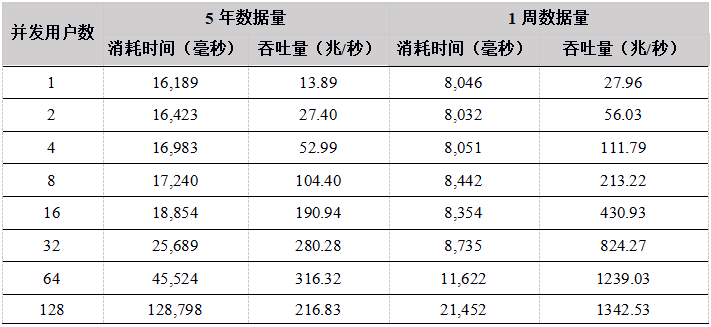
Tabla 18. Comparación del rendimiento de descarga de datos de cinco años de cada API (unidad: mega / segundo)
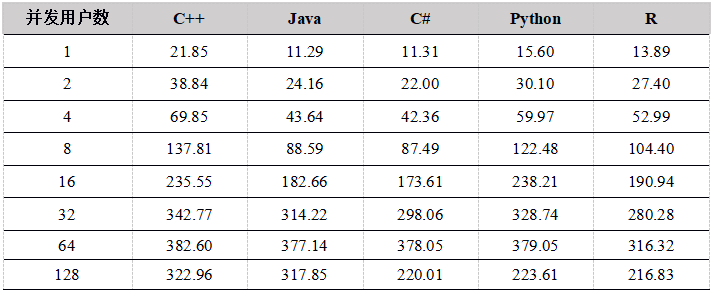
Figura 3. Comparación del rendimiento de descarga de datos de API de 5 años
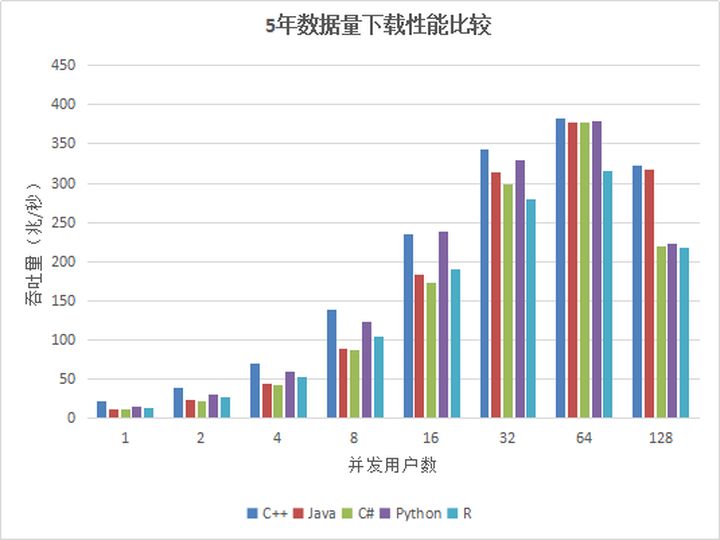
A partir de los resultados de la prueba, cuando el número de usuarios es inferior a 64, el rendimiento básicamente aumenta linealmente con el aumento del número de usuarios. El rendimiento de cada API no es muy diferente. El rendimiento máximo es de aproximadamente 350 millones. Dado que el conjunto de datos es 12T, DolphinDB no puede almacenar en caché todos los datos, debe cargarse desde el disco cada vez, y el disco se convierte en el cuello de botella del sistema.
Cuando el número de usuarios es 128, el rendimiento disminuye. La razón es que DolphinDB carga datos de acuerdo con las particiones. Si un usuario desea descargar los datos de un determinado stock en un día determinado, la partición completa se cargará en la memoria, y luego se devolverán los datos que el usuario necesita. Cuando hay demasiados usuarios concurrentes y las solicitudes de descarga de datos se inician al mismo tiempo, y debido a que la cantidad de datos es demasiado grande, los datos básicamente deben cargarse desde el disco. 128 usuarios leen el disco al mismo tiempo, lo que intensifica el IO competencia y reduce el rendimiento general.
Por lo tanto, se recomienda que los usuarios en el escenario de alta concurrencia de lectura de datos, cada nodo intente configurar múltiples volúmenes de datos independientes para mejorar la concurrencia de IO.
Tabla 19. Comparación del rendimiento de descarga de datos de 1 semana de varias API (unidad: mega / segundo)
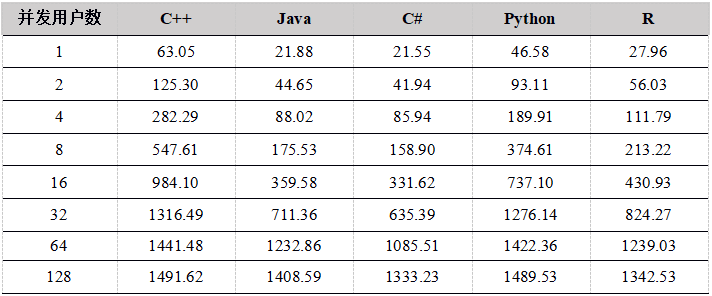
Figura 4. Comparación del rendimiento de descarga de datos simultáneos durante una semana de varias API
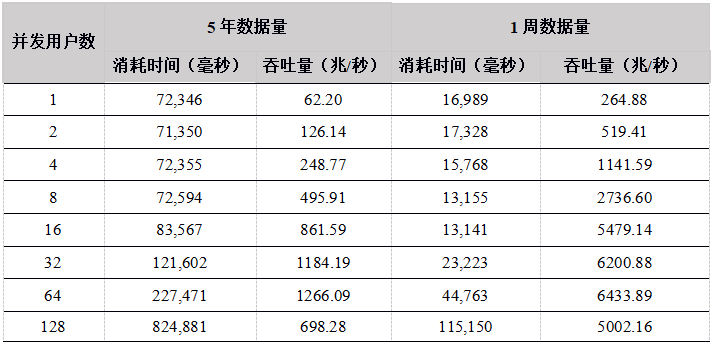
A partir de los resultados de la prueba, el rendimiento de cada API básicamente aumenta linealmente con el aumento en el número de usuarios concurrentes. La memoria asignada a DolphinDB puede contener todos los datos durante una semana y no es necesario cargar desde el disco cada vez. por lo que el rendimiento máximo es 1.4 Alrededor de G, se ha alcanzado el límite de la red (el límite de la red es 1G, debido a la compresión de datos, el volumen real de datos comerciales es 1.4G).
6. Calcular la prueba de rendimiento concurrente
La prueba en esta sección envía tareas de computación concurrentes a DolphinDB a través de la API y calcula la línea K de nivel de minutos de una determinada acción en un día determinado. El número total de cálculos es de aproximadamente 100 millones.
Probamos el rendimiento informático de diferentes números de usuarios simultáneos (1 ~ 128) en dos escenarios: volumen de datos de 5 años y volumen de datos de 1 semana.
- El volumen total de datos en 5 años es 12T, y la memoria no se puede almacenar en caché por completo, por lo que casi todos los cálculos necesitan cargar datos desde el disco, que es un escenario de aplicación intensivo de E / S, y se espera que el disco se convierta en un cuello de botella de rendimiento.
- El volumen de datos por semana es de aproximadamente 60G y los nodos de datos de DolphinDB se pueden almacenar en caché por completo, por lo que es un escenario de aplicación intensivo en computación.Cuando varios usuarios son concurrentes, se espera que la CPU se convierta en un cuello de botella de rendimiento.
Los resultados de las pruebas de cada API son los siguientes:
Tabla 20. Cálculo de API C ++ de los resultados de rendimiento de la barra de minutos
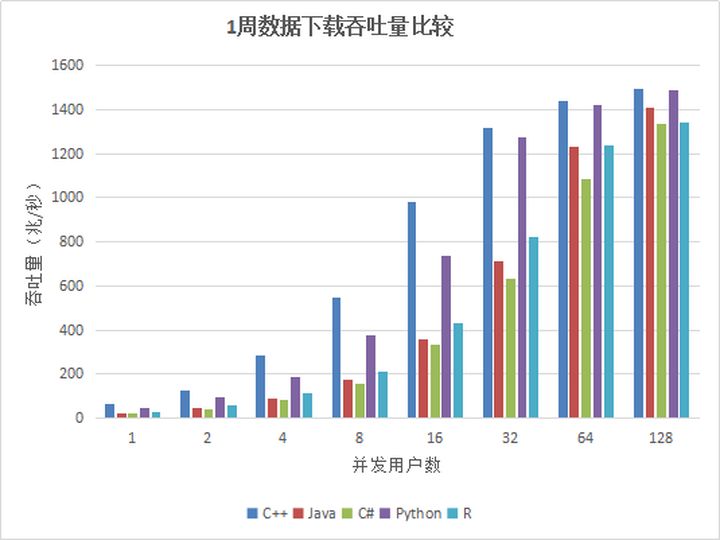
Tabla 21. Cálculo de la API de Java de los resultados de rendimiento de la barra de minutos
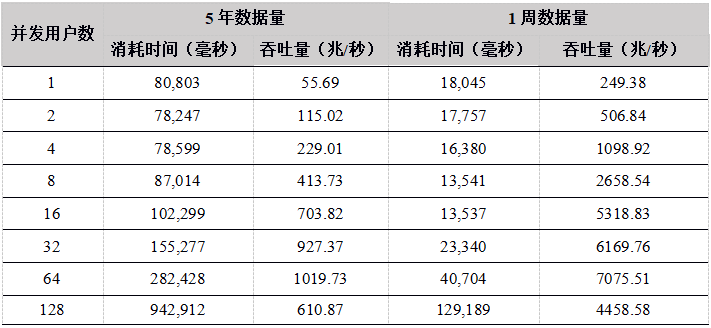
Tabla 22. La API de C # calcula los resultados de rendimiento de la barra de minutos
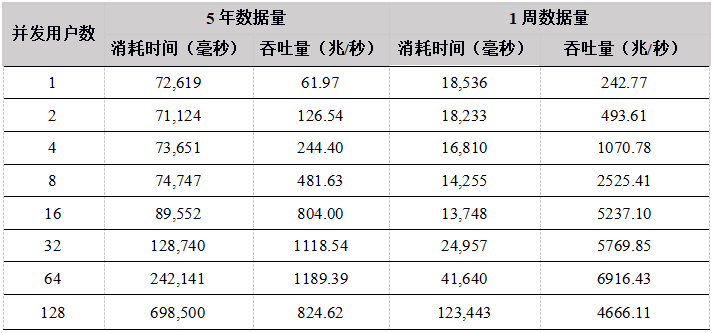
Tabla 23. La API de Python calcula los resultados de rendimiento de la barra de minutos
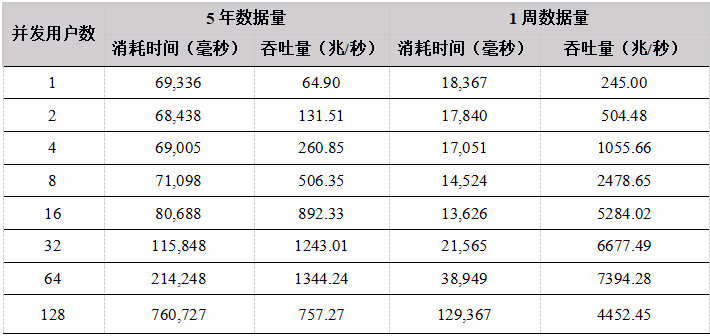
Tabla 24. Resultados de rendimiento calculados por API de R de la barra de minutos
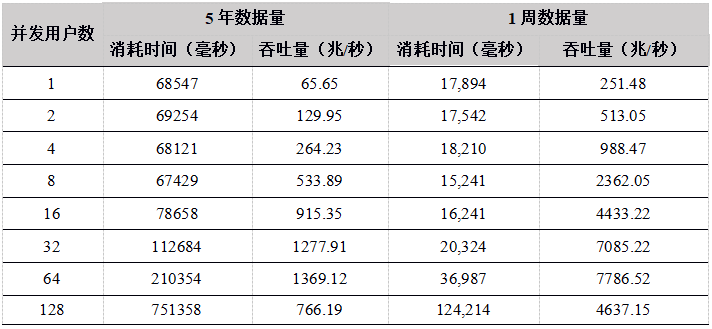
Tabla 25. Comparación del rendimiento de cálculo de datos de 5 años de varias API (Unidad: Mega / seg)
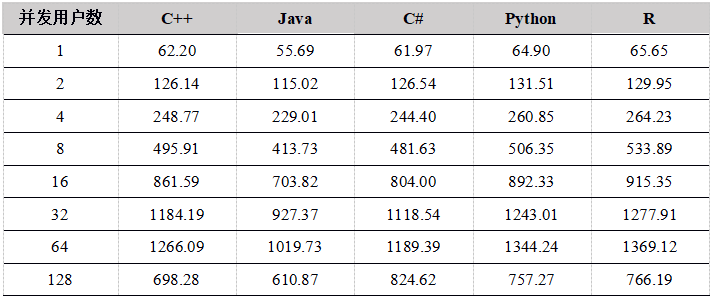
Figura 5. Comparación del rendimiento informático simultáneo de datos de cinco años de varias API
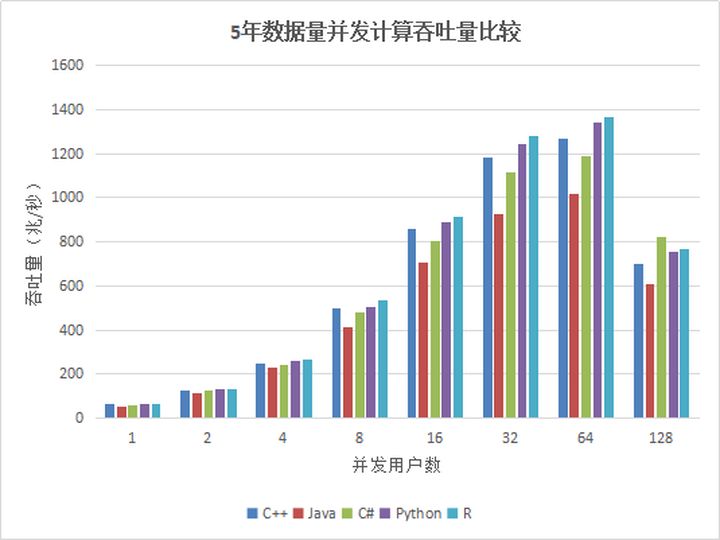
Se puede ver en la figura anterior que cuando el número de usuarios es menor a 16, el rendimiento de cada API aumenta básicamente de forma lineal. Cuando el número de usuarios llega a 64, el rendimiento alcanza el máximo; cuando el número de usuarios aumenta a 128 , el rendimiento cae en su lugar. Hay dos aspectos. Por un lado, un total de 12T de datos en 5 años, cada vez que la fecha y el símbolo se seleccionan al azar. Una vez que el número de usuarios simultáneos aumenta a un cierto número, la memoria DolphinDB no se puede acomodar completamente, lo que resulta en una gran cantidad de intercambio de datos entre la memoria y el disco, lo que resulta en caídas del rendimiento; por otro lado, demasiados usuarios simultáneos llevan a demasiadas tareas informáticas en el sistema y a una programación de tareas que consume mucho tiempo y la distribución aumenta, lo que resulta en un menor rendimiento.
Tabla 22. Comparación del rendimiento de cálculo de datos de 1 semana de varias API (Unidad: Mega / seg)
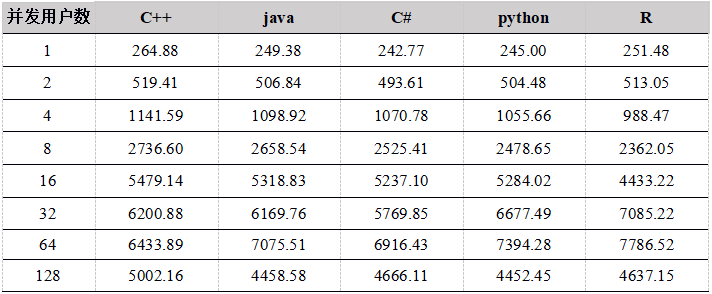
Figura 5. Comparación del rendimiento informático simultáneo de datos de 1 semana de varias API
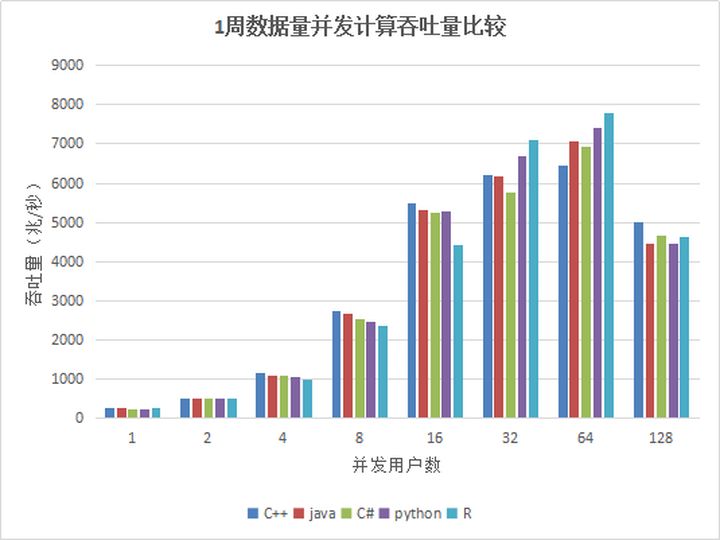
Se puede ver en los resultados de la prueba que cuando el número de usuarios es inferior a 64, el rendimiento aumenta de manera constante y el rendimiento de cada API no es muy diferente. Cuando hay 64 usuarios simultáneos, el rendimiento alcanza el máximo y el El rendimiento de los datos informáticos es cercano a 7G / seg. Alcanzar 128G, debido a demasiadas tareas del sistema, lo que excede en gran medida la cantidad de subprocesos de máquina física (la cantidad de máquinas físicas en el clúster es de 48 subprocesos), lo que resulta en frecuentes cambios de subproceso una gran cantidad de tareas dentro del clúster aumentan el tiempo de programación y distribución, y se reduce el rendimiento.
7. Resumen
Esta vez, probamos en detalle el rendimiento de DolphinDB C ++, Java, C #, Python y R API en carga de datos, descarga de datos y cálculo con diferentes números de usuarios concurrentes. Las conclusiones son las siguientes:
Carga de datos de un solo usuario en la tabla de memoria, C ++ tiene el mejor rendimiento, el rendimiento máximo puede alcanzar 265 Mbit / s, Java, Python, R también puede alcanzar 160-200 Mbit / s, el rendimiento de C # es ligeramente peor, el rendimiento máximo es de aproximadamente 60M. Y a medida que aumenta el tamaño del lote, el rendimiento aumenta significativamente, especialmente para Python y R. Por lo tanto, al escribir, siempre que el retraso y la memoria lo permitan, intente aumentar el tamaño del lote.
Los usuarios múltiples escriben en la tabla DFS distribuida al mismo tiempo. A medida que aumenta el número de usuarios, el rendimiento aumenta de manera constante antes de alcanzar el límite de la red. El rendimiento general C ++ y las ventajas de rendimiento de Java son obvias. Cuando el número de usuarios simultáneos es de aproximadamente 32, el network Se ha convertido en un cuello de botella, y el rendimiento de cada API es básicamente el mismo. Debido a la compresión de datos, el rendimiento máximo del sistema alcanza los 1.8G / seg.
Varios usuarios descargan datos al mismo tiempo . En el escenario donde el conjunto de datos es 12T durante 5 años, el rendimiento máximo se alcanza cuando el número de usuarios es 64, que es de aproximadamente 380 Mbit / s. En este escenario, todos los datos deben cargarse desde el disco y la lectura del disco se convierte en un cuello de botella en el rendimiento. Cuando el número de usuarios es 128, debido a que cada nodo tiene que aceptar una gran cantidad de usuarios para descargar, la competencia de E / S del disco es feroz , lo que resulta en una disminución del rendimiento general. En el escenario donde el conjunto de datos es de aproximadamente 60 G por semana, 6 nodos de datos pueden almacenar en caché todos los datos, por lo que todos los datos están en la memoria y no es necesario cargarlos desde el disco, y el rendimiento puede alcanzar el límite de la red. Debido a la compresión de datos, el rendimiento del clúster es de 1,8 G / seg, y con el aumento de usuarios simultáneos, el rendimiento aumenta de manera constante.
Computación concurrente multiusuario . Cada API envía una tarea de línea K de un minuto para calcular un determinado stock en un día determinado a DolphinDB y devuelve el resultado del cálculo. La cantidad de datos transmitidos a través de la red es muy pequeña y la mayoría de las veces es hecho en el lado del servidor Por lo tanto, cada API El rendimiento es básicamente el mismo. En los escenarios de volumen de datos de 5 años y 1 semana, la tendencia del rendimiento es básicamente la misma. Ambos alcanzan el rendimiento máximo cuando el número de usuarios es 64. Cuando el volumen de datos es de 5 años, el rendimiento máximo es 1,3G, mientras que el volumen de datos por semana se debe a Todos los datos están en la memoria y el rendimiento máximo alcanza los 7 GB. Cuando hay 128 usuarios, el rendimiento cae principalmente porque hay demasiadas tareas del sistema, que exceden en gran medida la cantidad de subprocesos de la máquina física (el clúster se encuentra en una máquina física con un total de 48 subprocesos), lo que conduce a frecuentes cambios de subprocesos y aumentos en la programación y distribución de una gran cantidad de tareas dentro del clúster.
En general, DolphinDB utiliza API para realizar tareas como la recuperación de datos, la carga de datos y el cálculo de datos. Con el aumento de la concurrencia, el rendimiento mejora constantemente y básicamente cumple con los requisitos de rendimiento de la mayoría de las empresas.