1. Escribe al principio
El servicio en la nube vivo brinda a los usuarios la capacidad de realizar copias de seguridad de datos como contactos, mensajes de texto, notas y marcadores en sus teléfonos móviles. El almacenamiento subyacente utiliza la base de datos MySQL para el almacenamiento de datos.
Con el desarrollo del negocio de servicios en la nube en vivo, la cantidad de usuarios de servicios en la nube ha crecido rápidamente y la cantidad de datos almacenados en la nube se ha vuelto cada vez más grande. Los datos masivos han traído enormes desafíos al almacenamiento de back-end. El mayor problema del negocio de servicios en la nube en los últimos años es cómo resolver el problema de almacenar datos masivos de los usuarios.
2. Hacer frente a los desafíos
De 2017 a 2018, los indicadores básicos de los productos de servicios en la nube se centraron en aumentar la cantidad de usuarios. El servicio en la nube ha realizado ajustes importantes en la estrategia del producto. Después de que los usuarios inician sesión en la cuenta de vivo, el interruptor de sincronización de datos del servicio en la nube se activa de forma predeterminada.
Esta estrategia de producto ha traído un crecimiento explosivo a la cantidad de usuarios de servicios en la nube. La cantidad de usuarios saltó directamente de un millón a diez millones, y la cantidad de datos almacenados en el back-end también saltó de decenas de miles de millones a cientos de miles de millones.
Para resolver el problema del almacenamiento masivo de datos, el servicio en la nube ha implementado las cuatro estrategias de la subtabla de subbase de datos: subtabla horizontal, subtabla vertical, subbase de datos horizontal y subbase de datos vertical.
1. Tabla de puntuación de nivel
Path of Thorns 1: ¿Qué debo hacer si la cantidad de datos en una sola tabla supera los 100 millones en los marcadores del navegador, la biblioteca de listas de notas y la tabla única?
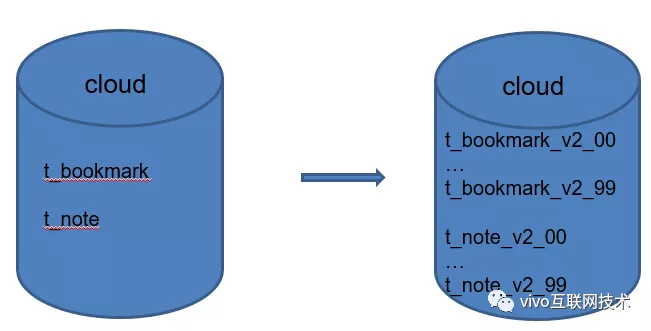
Creo que los hermanos que comprenden el sistema de conocimiento de la subbase de datos y la subtabla pronto podrán responder: si la cantidad de datos en una sola tabla es demasiado grande, entonces la tabla se dividirá. Hicimos lo mismo, dividimos la tabla única de marcadores del navegador y módulos de notas en 100 tablas.
Migre el volumen de datos de miles de millones de marcadores del navegador y hojas de notas a 100 subtablas, cada una de las cuales tiene un volumen de datos de 1000 W.
Este es el primer ataque con el que todo el mundo está familiarizado: la tabla de puntuación de nivel .
2. Subbiblioteca horizontal
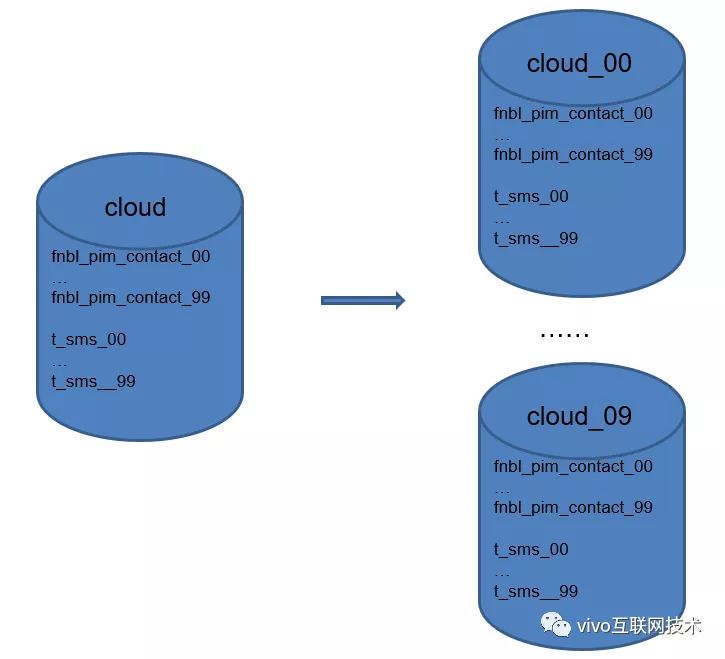
Path of Thorns 2: Los datos de contacto y SMS se han dividido en tablas, pero inicialmente solo se dividieron 50 tablas y no se dividió ninguna base de datos. Después del crecimiento explosivo del número de usuarios, la cantidad total de datos de contacto en una sola base de datos ha alcanzado varios miles de millones y la cantidad de datos en una sola tabla ha alcanzado los 5000 W. El crecimiento continuo afectará seriamente el rendimiento de mysql. ¿Qué debo hacer?
El segundo truco consiste en dividir la biblioteca horizontalmente : si una biblioteca no puede admitirla, divídala en varias bibliotecas más. Nos dividimos la base de datos solo original en 10 bases de datos , y amplió la base de datos original de una sola de 50 mesas de contactos y SMS a 100 mesas. Durante el mismo período, la migración y el cambio de ruta de mil millones de datos almacenados fue muy dolorosa.
3. Subbiblioteca vertical, submesa vertical
Path of Thorns 3: Inicialmente, el almacenamiento de datos de cada módulo del servicio en la nube está mezclado.
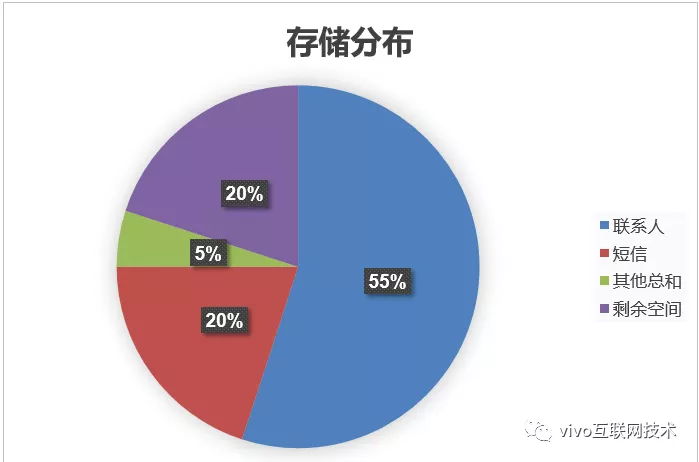
Cuando hay un cuello de botella en el espacio, analizamos la distribución del espacio de almacenamiento de los datos de cada módulo, y la situación es la siguiente:
La capacidad del disco de una biblioteca es 5T , los datos de contacto ocupan 2,75T (55%) de espacio de almacenamiento , los datos de SMS ocupan 1T (20%) de espacio de almacenamiento , todos los demás datos del módulo ocupan un total de 500G (5%) de espacio de almacenamiento y el espacio libre restante es 1T . Los datos de personas y SMS ocupan el 75% del espacio total .
El 1T restante de capacidad espacial no puede soportar el crecimiento continuo de los datos de los usuarios y la situación no es optimista. Si no hay suficiente espacio, todos los módulos no estarán disponibles debido a problemas de espacio ¿Qué debo hacer?
(La siguiente figura muestra la distribución del espacio de almacenamiento de datos para los servicios en la nube en ese momento)
El tercer y cuarto eje, subbase de datos vertical y subtabla vertical: almacenamos y desacoplamos datos de contacto, datos de SMS y otros datos del módulo. Separe los datos de contacto y los datos de SMS en bibliotecas.
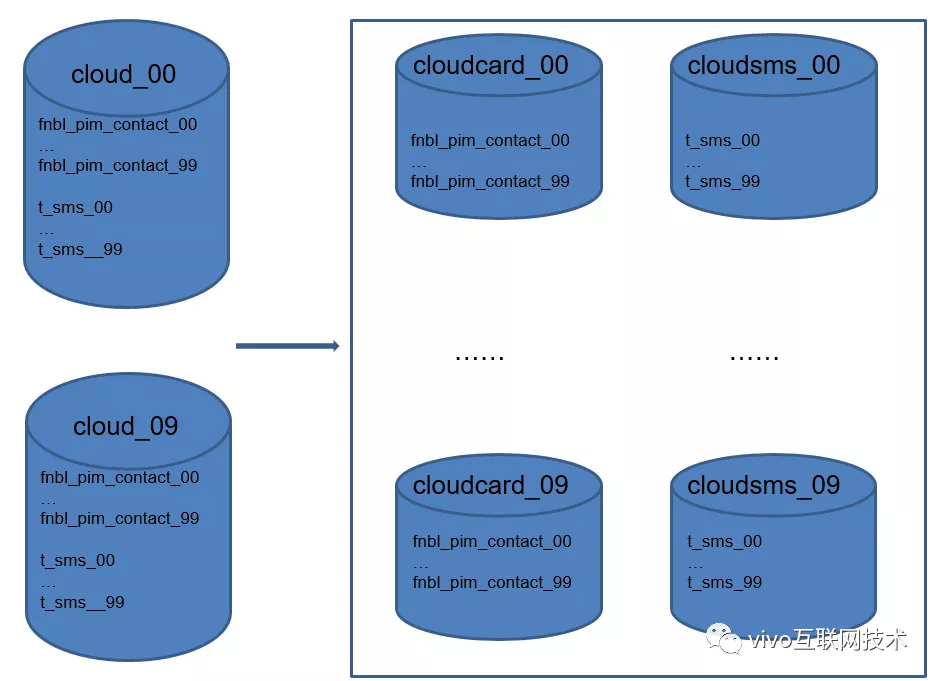
Hasta ahora, el servicio en la nube ha practicado los cuatro trucos de la subbase de datos y las subtablas. Los datos deben dividirse y la división debe dividirse.
4. Esquema de expansión dinámica basado en la tabla de enrutamiento.
Path of Thorns 4: a partir de la descripción anterior, se sabe que la base de datos de contactos divididos adopta una estrategia de subbase de datos fija de 10 bases de datos. La evaluación preliminar de 10 bases de datos * 100 tablas puede satisfacer las necesidades del crecimiento de datos comerciales. Pensé que podría sentarse y relajarse, pero La tasa de crecimiento de los datos de contacto superó las expectativas.
Nueve meses después de que la base de datos de contactos se dividió por separado , el espacio de almacenamiento de una sola base de datos aumentó del 35% al 65% . De acuerdo con esta tasa de crecimiento, después de otros 6 meses de soporte, la base de datos de contactos dividida de forma independiente enfrentará una vez más el problema de espacio insuficiente.
¿Cómo resolver? La expansión continua es afirmativa, y el punto central es qué estrategia de expansión se adopta. Si adoptamos el plan de expansión convencional, nos enfrentaremos al problema de la migración y el redireccionamiento de datos masivos de existencias, que es demasiado costoso.
Después de la comunicación y discusión por parte del grupo técnico, combinado con las características del negocio de contactos del servicio en la nube (el número de contactos para los usuarios antiguos es básicamente estable, y no se agregan muchos contactos con frecuencia, y la tasa de crecimiento de los datos de contacto para los usuarios antiguos es controlable) Finalmente adoptamos un esquema de expansión dinámica basado en la tabla de enrutamiento.
A continuación se describen las características de este programa:
- Agregue una tabla de enrutamiento del usuario para registrar a qué base de datos y tabla se enrutan los datos de contacto del usuario;
- Los datos de contacto del nuevo usuario se enrutarán a la base de datos recién expandida, lo que no ejercerá presión sobre el almacenamiento de datos en la base de datos antigua original.
- Los datos del usuario anterior no se moverán y aún se almacenan en la base de datos original.
- La característica de esta solución es garantizar que la base de datos antigua original solo necesita garantizar el crecimiento de datos de los usuarios antiguos, y que todos los usuarios nuevos sean transportados por la base de datos recién ampliada.
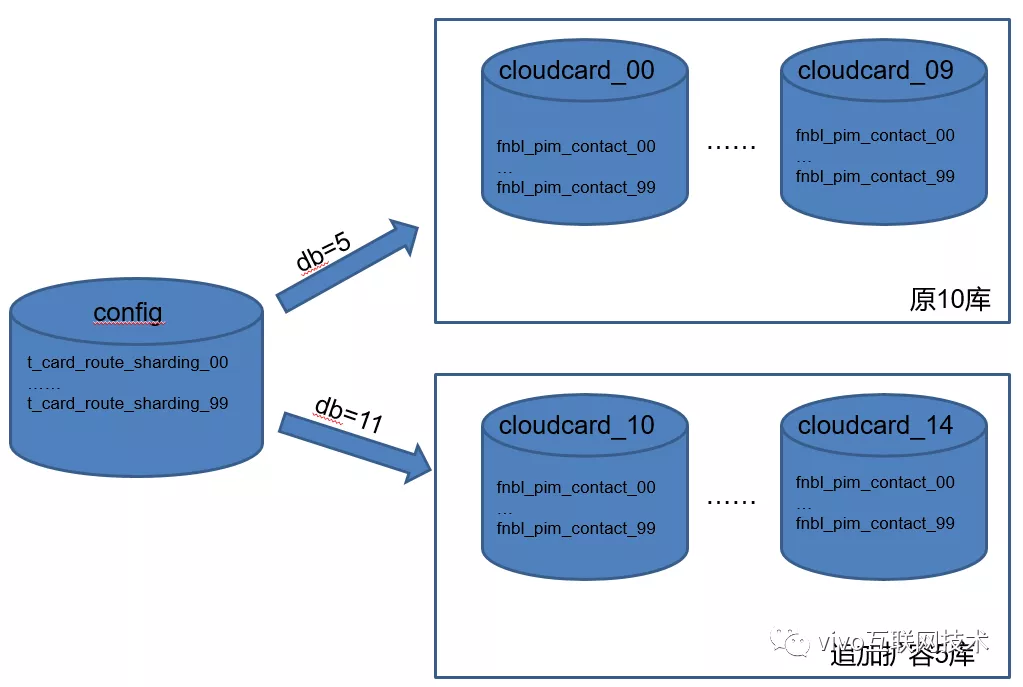
Aunque la tasa de crecimiento de los contactos de usuarios antiguos es controlable, esperamos que la biblioteca original pueda reservar el 60% del espacio de almacenamiento para respaldar el crecimiento de datos de los usuarios antiguos. En la actualidad, solo queda el 35% del espacio disponible en la antigua biblioteca, lo que no cumple con nuestros requisitos.
Para reducir el espacio de almacenamiento ocupado por los datos de la base de datos antigua, naturalmente pensamos en comenzar desde el nivel de compresión de datos .
3. Investigación previa sobre el esquema de compresión
El servicio en la nube ha realizado una investigación previa sobre las siguientes 3 soluciones para la compresión de datos de bases de datos:
Esquema 1: el programa implementa la compresión de datos por sí mismo y los guarda en la base de datos después de la compresión
Ventaja:
No hay necesidad de modificar la base de datos, la modificación es completamente convergente por el propio programa y los campos que necesitan ser comprimidos se pueden controlar libremente.
Desventajas:
Los datos existentes deben desarrollar tareas de compresión adicionales para la compresión de datos, y la cantidad de datos existentes es demasiado grande, y la compresión de datos por programas consume mucho tiempo y es incontrolable.
Una vez comprimidos y almacenados los datos en la base de datos, el contenido del campo de consulta de selección que debe realizarse directamente desde la plataforma db ya no es legible, lo que aumenta la dificultad de los problemas de ubicación posteriores.
Opción 2: la base de datos MySQL InnoDB viene con capacidades de compresión de datos
Ventaja:
Utilice las capacidades existentes de InnoDB para la compresión de datos, sin ninguna modificación en el programa de nivel superior, y no afecta las consultas de datos seleccionados posteriores.
Desventajas:
Es adecuado para escenarios empresariales con una gran cantidad de datos y menos lecturas y escrituras, y no es adecuado para empresas que requieren un alto rendimiento de consultas.
Solución 3: cambie el motor de almacenamiento InnoDB a TokuDB y use las capacidades naturales de compresión de datos del motor TokuDB
Ventaja:
TokuDB, naturalmente, admite la compresión de datos y admite múltiples algoritmos de compresión, admite escenarios de escritura de datos frecuentes y tiene ventajas naturales para el almacenamiento de datos de gran tamaño.
Desventajas:
MySQL necesita instalar complementos adicionales para admitir el motor TokuDB, y la compañía actualmente no tiene negocios con la experiencia madura de TokuDB, se desconoce el riesgo después del acceso y el mantenimiento posterior del DBA también es un desafío.
Después de una consideración exhaustiva, finalmente decidimos adoptar el segundo esquema de compresión: las propias capacidades de compresión de InnoDB .
Las principales razones son las siguientes:
- Operación simple: cambie el formato de archivo de la tabla de datos innodb existente por dba para comprimir los datos;
- Velocidad de compresión controlable: después de la prueba, se puede utilizar una tabla de datos de 2000 W para comprimir toda la tabla en 1-2 días;
- Bajo costo de transformación: todo el proceso de transformación solo requiere que dba ejecute SQL relacionado, cambie el formato de archivo de la tabla de datos y no sea necesario realizar ningún cambio en el código del programa superior;
- Más adecuado para escenarios comerciales de servicios en la nube: la copia de seguridad y recuperación de datos del usuario no son escenarios comerciales de alto rendimiento y alto QPS, y las tablas de datos del servicio en la nube se ajustan principalmente a las características de una gran cantidad de campos de cadenas, que son muy adecuados para la compresión de datos.
Cuarto, la verificación del esquema de compresión
1. Introducción a las capacidades de compresión InnoDB
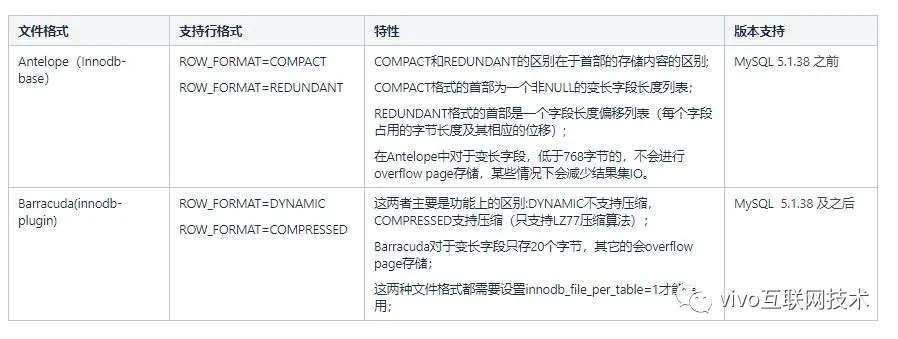
Antes de MySQL versión 5.1.38, solo existía un motor de almacenamiento innodb-base. El formato de archivo predeterminado es Antelope. Este formato de archivo admite dos formatos de fila (ROW_FORMAT): COMPACT y REDUNDANT, ninguno de los cuales es un formato de fila del tipo de compresión de datos.
Después de MySQL 5.1.38, se introdujo el plugin innodb y también se introdujo el formato de archivo de tipo Barracude. Barracude es totalmente compatible con el formato de archivo de Antelope y admite los otros dos formatos de línea DYNAMIC y COMPRESSED (admite compresión de datos).
2. Preparación del entorno de compresión
Modificar la configuración de la base de datos: cambiar el formato de archivo de la base de datos, el predeterminado es Antelope, modificado a Barracuda
SET GLOBAL innodb_file_format = Barracuda;
SET GLOBAL innodb_file_format_max = Barracuda;
SET GLOBAL innodb_file_per_table = 1
Nota: innodb_file_per_table debe establecerse en 1. La razón es que el espacio de tabla del sistema InnoDB no se puede comprimir. El espacio de tabla del sistema no solo contiene datos de usuario, sino que también contiene la información interna del sistema de InnoDB, que nunca se puede comprimir, por lo que es necesario establecer diferentes espacios de tabla para diferentes tablas para admitir la compresión.
Después de configurar OK, puede ejecutar MOSTRAR VARIABLES GLOBALES COMO '% file_format%' y MOSTRAR VARIABLES GLOBALES COMO '% file_per%' para confirmar si la modificación tiene efecto.
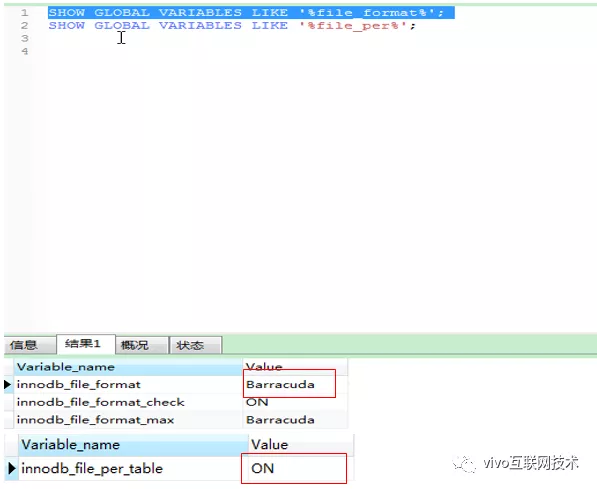
(Esta configuración solo es efectiva para la sesión actual, y dejará de ser válida después de reiniciar la instancia de mysql. Si necesita tener efecto de forma permanente, configúrelo en el archivo de configuración global de mysql)
3. Prueba de verificación del efecto de compresión
Prepare una tabla de datos que admita formato de compresión y una tabla de datos que no admita compresión Los formatos de campo son todos iguales.
Tabla de compresión:

Descripción: row_format = compressed, el formato de fila especificado está comprimido. Key_block_size recomendado = 8. El valor predeterminado de key_block_size es 16. Los valores opcionales 16, 8, 4 representan el tamaño de la página de datos InnoDB. Cuanto menor sea el valor, mayor será la compresión. Basado en la consideración integral de la CPU y la tasa de compresión, la configuración recomendada en línea es 8.
Tabla sin comprimir:
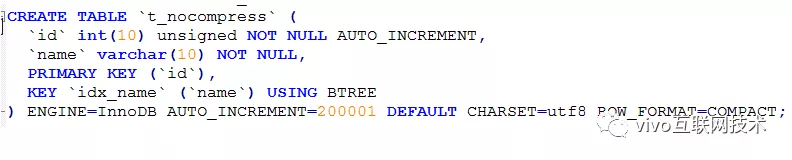
Prepare datos: utilice un procedimiento almacenado para insertar 10W de los mismos datos en la tabla t_nocompress y la tabla t_compress al mismo tiempo. El espacio que ocupan las 2 mesas es el siguiente:
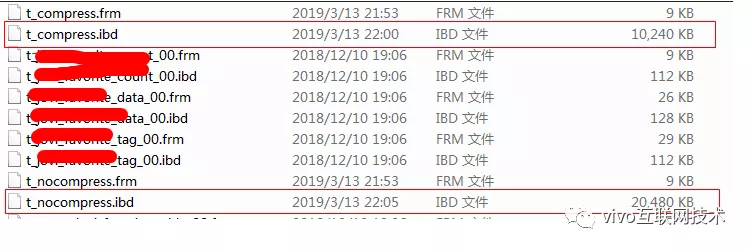
Los datos de la tabla t_compress ocupan 10M, los datos de la tabla t_nocompress ocupan 20M y la tasa de compresión es del 50%.
Nota: El efecto de compresión depende del tipo de campo de la tabla. Los datos típicos suelen tener valores repetidos, por lo que se pueden comprimir de forma eficaz. CHAR, VARCHAR, TEXT, BLOB, etc.
Los datos de cadena generalmente se pueden comprimir bien. Sin embargo, los datos binarios (números enteros o de punto flotante) y los datos comprimidos (imágenes JPEG o PNG) generalmente no logran la compresión.
Cinco, práctica en línea
A partir de la verificación de prueba anterior, si la tasa de compresión puede alcanzar el 50%, el espacio ocupado por la base de datos de contactos se comprimirá del 65% al 33%, y se puede lograr el 60% del espacio restante.
Pero debemos estar asombrados por los datos en línea. Antes de la práctica en línea, debemos verificar el plan fuera de línea. Al mismo tiempo, también debemos considerar los siguientes problemas:
1. ¿La compresión y descompresión de datos afectan el rendimiento del servidor de base de datos?
Usamos pruebas de estrés de rendimiento para evaluar el impacto en la CPU del servidor de la base de datos antes y después de la compresión. El siguiente es el cuadro de comparación de CPU del servidor de base de datos antes y después de la compresión:
Bajo la premisa de que el volumen de datos de la lista de contactos ya es de 2000 W, los datos se insertan en esta tabla.
Antes de la compresión: inserte 50 contactos a la vez, con 200 simultáneos, 10 minutos, TPS 150, CPU 33%
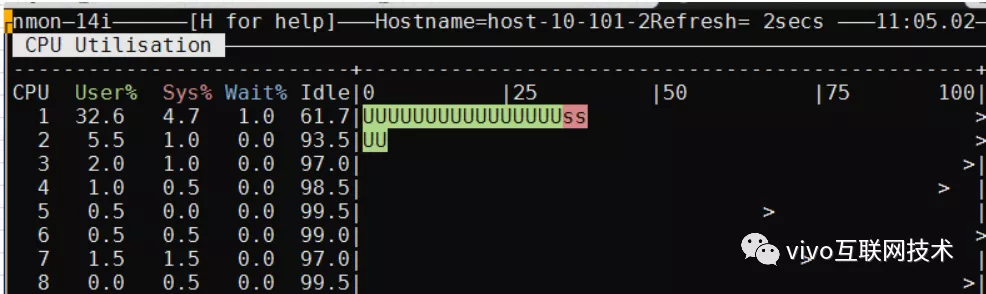
Después de la compresión: inserte 50 contactos a la vez, con 200 simultáneos, 10 minutos, TPS 140, CPU 43%
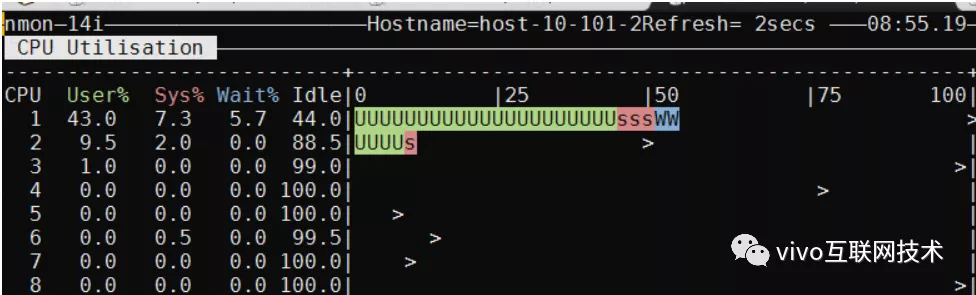
Una vez comprimida la tabla de datos, la CPU de la inserción frecuente de datos en la base de datos aumentará, pero el TPS no se verá muy afectado. Después de repetidas pruebas de esfuerzo, la CPU del servidor de la base de datos es básicamente estable en alrededor del 40%, lo que es aceptable para el negocio.
2. ¿Cambiar el formato del archivo de la tabla de datos afectará la lectura y escritura de SQL comercial y afectará las funciones comerciales normales?
Principalmente realizamos verificación fuera de línea y verificación en línea :
Verificación fuera de línea: el entorno de prueba ajustó todas las tablas de datos de contacto a un formato comprimido y dispuso que un ingeniero de pruebas ayudara a verificar las funciones completas de los contactos, y las funciones finales fueron todas normales.
El entorno previo al lanzamiento sigue de nuevo los pasos del entorno de prueba y no hay ninguna anomalía en la comprobación de funcionamiento.
Verificación en línea: seleccione la tabla de datos del módulo de registro de llamadas que no es sensible a la compresión de los usuarios, elija comprimir 1 tabla en 1 biblioteca, preste atención a la situación de lectura y escritura de datos de esta tabla y preste atención a las quejas de los usuarios.
Después de 1 semana de observación continua, los datos del registro de llamadas de este reloj se pueden leer y escribir normalmente, y no se han recibido comentarios anormales de ningún usuario durante este período.
3. La cantidad de datos de contacto en línea es enorme, ¿cómo garantizar la estabilidad del servicio durante la compresión?
Principalmente hacemos concesiones de acuerdo con las siguientes ideas:
- Seleccione una tabla de datos de contacto para comprimir y evalúe el tiempo dedicado a una sola tabla.
- Seleccione una sola base de datos, realice una compresión simultánea de varias tablas y observe el uso de la CPU. El DBA considera que el valor máximo de la CPU no puede exceder el 55% y ajusta gradualmente el número de compresiones simultáneas según este estándar para garantizar que la CPU sea estable en alrededor del 55% y, finalmente, obtener la cantidad máxima de tablas admitidas por una sola base de datos para la compresión al mismo tiempo.
- Combinando el primer y segundo paso, podemos calcular el tiempo aproximado que se tarda en comprimir todas las tablas de datos en todas las bibliotecas, y luego de sincronizar con el equipo del proyecto y los responsables relacionados, seguir los pasos para implementar el trabajo de compresión.
El efecto de la compresión de datos en la base de datos final de contactos en línea es el siguiente:

Seis, escribe al final
Este artículo presenta los desafíos planteados por los servicios en la nube con el desarrollo de almacenamiento masivo y empresarial de datos, así como algo de experiencia en servicios en la nube en subtabla de sub-bases de datos, compresión de datos de bases de datos, con la esperanza de proporcionar referencia.
La compresión de datos InnoDB es adecuada para los siguientes escenarios:
Empresas con gran cantidad de datos comerciales y presión de espacio en discos de bases de datos;
Es adecuado para escenarios comerciales que leen más y escriben menos, y no es adecuado para empresas que tienen altos requisitos de rendimiento y QPS;
- Es adecuado para una gran cantidad de datos de tipo cadena en la estructura de la tabla de datos comerciales. Este tipo de tabla de datos generalmente se puede comprimir de manera efectiva.
Al final:
Al seleccionar bases de datos y tablas para empresas, es necesario estimar completamente el crecimiento del volumen de datos El trabajo de migración de datos provocado por la expansión de la base de datos posterior dañará los huesos.
- Sorpréndase con los datos en línea y la solución debe aplicarse en línea solo después de una verificación repetida fuera de línea.
Autor: plataforma vivo para equipos de desarrollo de productos