Una descripción general rápida de los aspectos más destacados en un minuto
En la etapa actual, no existe una ruta de ejecución unificada para la construcción de la observabilidad. Cada empresa formará un conjunto único de prácticas basadas en sus propias necesidades comerciales, modelo operativo y escala. Para hacer frente a la expansión de la escala empresarial y los cambios en los requisitos, el equipo observable debe optimizar y actualizar continuamente su arquitectura y garantizar siempre la alta disponibilidad del propio sistema observable.
Este artículo describe en detalle los desafíos técnicos que Didi ha encontrado en cuatro etapas diferentes desde 2017 hasta la actualidad, como cuellos de botella de recursos en la etapa de aplicación única, aumento de los costos de operación y mantenimiento, problemas de comunicación en servicios distribuidos, etc. Didi ha superado gradualmente estos problemas técnicos encontrando y aplicando soluciones técnicas apropiadas, de modo que su arquitectura observable siempre pueda brindar un sólido soporte para su negocio.
Sobre el Autor
Didi Chuxing líder de arquitectura observable——Qian Wei
Miembro del equipo de expertos de la comunidad de estabilidad TakinTalks y jefe de la arquitectura observable de Didi Chuxing. Ha estado profundamente involucrado en el campo observable durante muchos años, enfocándose en el diseño y optimización de la arquitectura. Lideró el equipo para completar las iteraciones de arquitectura de segunda a cuarta generación de Didi. Colaborador de múltiples proyectos observables de código abierto. La atención se centra actualmente en la construcción de la estabilidad de la observabilidad de Didi y la realización e implementación de la observabilidad en escenarios de Didi.
Recordatorio: este artículo tiene aproximadamente 7500 palabras y se tarda unos 12 minutos en leerlo.
El backend de la cuenta pública "TakinTalks Stability Community" responde "Comunicación" para ingresar al grupo de comunicación de lectores, responde "1026" para obtener información sobre el material educativo;
fondo
Primero echemos un vistazo a una historia——
"A principios del siglo XX, Ford se encontraba en un período de rápido desarrollo. Un día, un motor se averió y los trabajos de producción relacionados se vieron obligados a detenerse. Muchos trabajadores y expertos no pudieron encontrar el problema. Hasta que un hombre llamado Steinmenz fue invitado Después de inspeccionar la máquina, Steinmenz trazó una línea con tiza en la carcasa del motor y le dijo que encendiera el motor y redujera la bobina en la marca en 16 vueltas. Después de que el técnico lo hizo, el fallo fue eliminado y la producción se reanudó inmediatamente."
Cuando estamos trabajando o en el proceso de desarrollo, a menudo nos encontramos con este tipo de escenarios: problemas que lo confunden y no saben por dónde empezar, pero siempre hay uno o dos "expertos" que pueden ver el problema de un vistazo. Entonces, debemos pensar en ello: ¿es esto algo bueno o malo?
Como plataforma de viajes, el negocio de Didi cubre trenes expresos, automóviles privados, viajes compartidos, bicicletas compartidas y otros campos. Decenas de millones de usuarios y conductores interactúan y utilizan la plataforma todos los días, formando dependencias complejas entre servicios. En un sistema distribuido a tan gran escala, la resolución de problemas y la optimización del rendimiento es, sin duda, una tarea compleja.
Obviamente, confiar cada vez en la experiencia de expertos individuales está fuera de control y no se pueden garantizar los resultados. Por lo tanto, preferimos respaldar la rápida iteración e innovación empresarial mediante la evolución continua de la arquitectura observable.
1. ¿Qué problemas resuelve la evolución de la arquitectura observable?
1.1 Arquitectura general del sistema observable Didi
La arquitectura general del sistema observable de Didi incluye principalmente varias partes, como se muestra en la siguiente figura.
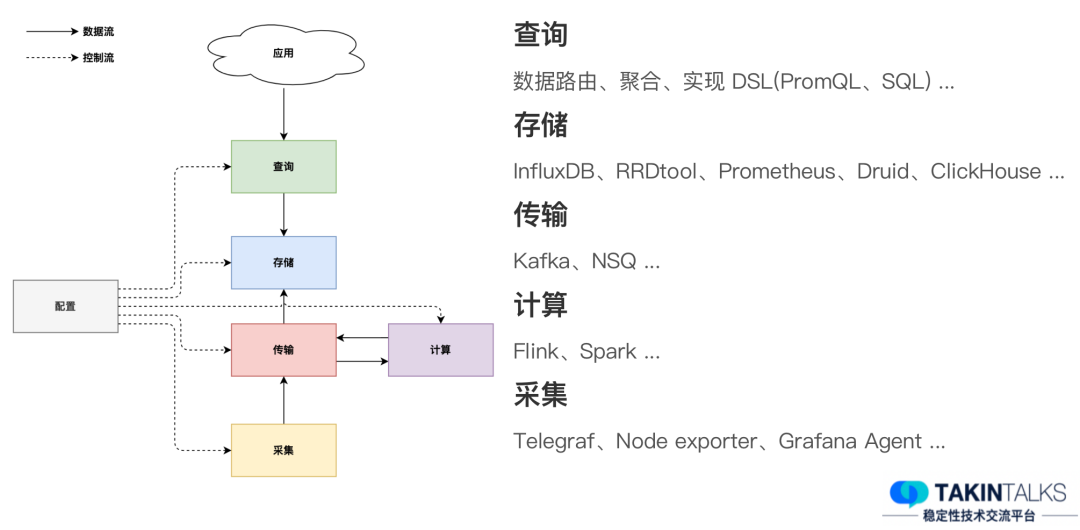
Recopilaremos el host de destino u otros indicadores relacionados. Después de pasar por el enlace de transmisión, el módulo informático puede procesar algunos indicadores y luego volver a escribirlos en el sistema. Estos datos luego se almacenan. Con base en estos datos almacenados, la función de consulta puede proporcionar visualización de datos para aplicaciones de capa superior, como paneles, paneles de datos, alarmas y eventos, etc.
Cabe señalar que cada módulo necesita completar diferentes tareas o implementar diferentes funciones. Por ejemplo, el módulo de consulta puede ser responsable del enrutamiento, agregación e implementación de funciones DSL de datos, que generalmente se implementan en la capa de consulta.
Hay muchas formas de implementar el almacenamiento de datos, como InfluxDB, RRDtool, Prometheus, Druid, ClickHouse, etc., que pueden usarse como soluciones de almacenamiento para sistemas observables.
El módulo de transmisión desempeña el papel de conexión en el sistema y en este módulo se utiliza la cola de mensajes común. Cuando mencionamos colas de mensajes, lo primero que nos viene a la mente puede ser Kafka. Por supuesto, también hay algunas opciones más especializadas, como NSQ.
La tarea del módulo de cálculo es convertir una gran cantidad de indicadores al formato que necesitamos, posiblemente eliminando algunas dimensiones para el cálculo. Herramientas como Flink y Spark son opciones comunes en este módulo.
Para la recopilación de datos, hay muchas herramientas ricas para elegir, como Telegraf, Node Exporter y Grafana Agent, lanzado recientemente.
1.2 4 etapas de evolución de la arquitectura observable
1.2.1 Fase 1: Antes de 2017
Cuando los requisitos comerciales cambian, los problemas de rendimiento del módulo de almacenamiento suelen ser los primeros en quedar expuestos. Antes de 2017, Didi utilizaba principalmente InfluxDB como opción de almacenamiento. Dividimos la instancia de InfluxDB según las dimensiones de los servicios comerciales y este diseño causó algunos problemas.
En primer lugar, existe un cuello de botella en el rendimiento de la versión independiente. Por ejemplo, podemos encontrarnos con una situación en la que el volumen de consultas es grande, como la duración de la consulta es larga o los datos de la consulta son grandes, en este caso es probable que se produzca un problema de falta de memoria (OOM). Este también es un tema frecuentemente discutido en la comunidad.
Además, también existen problemas con el método de fragmentación que adoptamos. Lo dividimos por servicio, de modo que, por ejemplo, si hoy tiene 50 servicios, es posible que necesite 50 instancias o menos. Pero si mañana el número de servicios aumenta a 500, los costos de operación y mantenimiento aumentarán significativamente. Especialmente en la situación actual en la que se adopta ampliamente la arquitectura de microservicios, este tipo de costo de operación y mantenimiento será muy alto.
1.2.2 Fase 2: 2017-2018
Para resolver los problemas anteriores, presentamos RRDTool en 2017. Durante este período, RRDTool reemplazó a InfluxDB y se convirtió en la principal herramienta de almacenamiento de Didi Observable.
En el diseño de RRDTool, utilizamos un algoritmo hash consistente para realizar la fragmentación de múltiples instancias de RRDTool en los enlaces de lectura y escritura. El proceso de este algoritmo hash consiste en nivelar primero todas las etiquetas, luego ordenarlas y, finalmente, realizar un hash y distribuirlas a cada instancia.

Además de esto, también presentamos un servicio llamado "Índice". La principal tarea de este servicio es satisfacer las necesidades del producto. Por ejemplo, es posible que necesitemos proporcionar una lista de servicios. Después de que los usuarios elijan su propio servicio, necesitan saber qué indicadores hay bajo el servicio y qué etiquetas hay bajo cada indicador. Este requisito requiere un servicio de indexación eficiente para completarse.
Las mejoras arquitectónicas basadas en RRDTool han traído dos resultados importantes. Primero, resuelve los puntos calientes de InfluxDB. Originalmente dividimos las instancias según los servicios, pero ahora distribuimos estas curvas a cada instancia. En segundo lugar, esto también reduce los costos de operación y mantenimiento de InfluxDB porque adoptamos un método de fragmentación relativamente automatizado.
1.2.3 Tercera Fase: 2018-2020
Después de 2018, enfrentamos nuevos desafíos. Dado que el principio de diseño de RRDTool es un archivo para cada curva, cuando aumenta la escala de datos, la demanda de IO también aumenta. Nuestro IOPS ha superado los 30.000, lo que requiere que agreguemos más dispositivos, como máquinas con alto rendimiento de IO, para resolver este problema. Sin embargo, esto conduce a un aumento gradual de los costos y a un empeoramiento del problema. Al mismo tiempo, la lectura y la escritura en observabilidad son ortogonales, y existe un conflicto en la optimización de lectura y escritura: la escritura generalmente escribe la última parte de todas las curvas, mientras que la lectura generalmente lee datos de múltiples curvas o de una determinada curva durante mucho tiempo. .
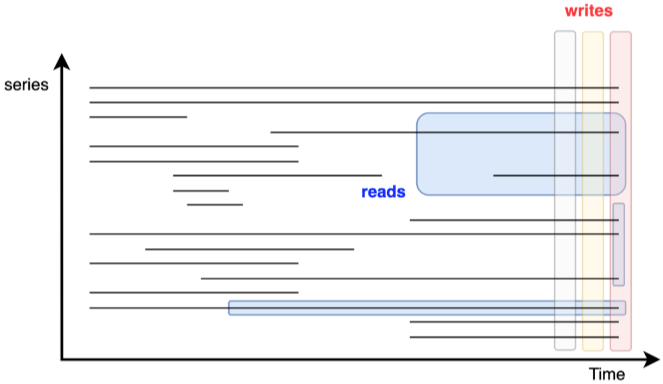
(Vertical es Escritura, horizontal es Lectura)
Entonces, ¿cómo solucionamos este problema? Después del análisis, encontramos que el 80% de las consultas se concentraron en las últimas dos horas, por lo que diseñamos una estrategia de niveles fríos y calientes. El núcleo de esta estrategia es almacenar los datos comprimidos en la memoria. La compresión se centra principalmente en dos aspectos: uno es la marca de tiempo y el otro es el valor. Dado que el intervalo de tiempo entre la generación de marcas de tiempo suele ser relativamente fijo y los cambios de valores tienden a ser relativamente suaves, esto proporciona una base para nuestra estrategia de compresión.
Con base en este principio, creamos internamente un servicio llamado "Cacheserver", que sirve principalmente los datos de las últimas dos horas y adopta un diseño de memoria completa. Este diseño reduce el retraso de la consulta del usuario de 10 segundos a menos de 1 segundo, y el almacenamiento de cada punto de datos se reduce de los 16 bytes originales a 1,64 bytes.
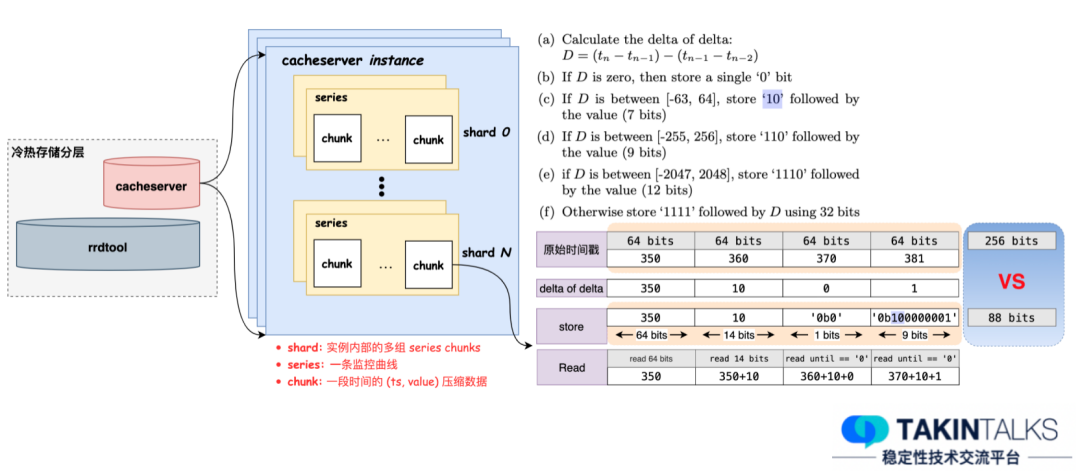
Todo el diseño se puede entender a través del diagrama anterior. El primero son los niveles frío y caliente: RRDTool y Cacheserver completan conjuntamente toda la tarea de almacenamiento. Tomando como ejemplo la mitad derecha de la figura, las marcas de tiempo originales son 350, 360, 370 y 381, y se requieren 256 bits para almacenar estos datos. Pero después de la compresión, sólo 88 bits son suficientes. Este es solo el caso con cuatro marcas de tiempo. Si hay más marcas de tiempo, el efecto de compresión será más significativo.
1.2.4 Fase 4: 2020-presente
A medida que la cantidad de componentes a los que acceden los usuarios continúa aumentando, las necesidades de consulta de los usuarios se vuelven cada vez más complejas. En nuestro escenario de uso, una vez que RRDTool realiza la reducción de escala, ya no podemos ver los datos originales.
Ante esta situación comenzamos a pensar en cómo diseñar un sistema que pueda satisfacer las necesidades actuales y futuras de los usuarios. Cambiamos nuestra estrategia de resolución de problemas y ya no diseñamos soluciones individuales para cada situación específica. Por ejemplo, si hubiera nuevos formularios de consulta en el pasado, necesitaríamos codificar e iniciar una nueva función. Ahora, elegimos utilizar directamente el ecosistema de la industria.
En aquella época, Prometeo era muy popular. Cambiamos nuestro objetivo de presentar el ecosistema a presentar el ecosistema Prometheus. La razón para elegir Prometheus es que con la popularidad de los K8, Prometheus se ha convertido en el estándar de facto para sistemas de monitoreo. Muchos actores importantes de la industria y proveedores populares continúan contribuyendo con código y arquitectura a Prometheus.
Sin embargo, si optamos por introducir el ecosistema Prometheus, no podremos seguir usando RRDTool porque no es compatible con el ecosistema Prometheus. Esto requiere que encontremos nuevas soluciones de almacenamiento.
Dificultad 1: ¿Cómo elegir una nueva solución de almacenamiento?
A la hora de elegir nuevas soluciones de almacenamiento, consideramos principalmente Cortex, Thanos y VictoriaMetrics (VM para abreviar). Estas soluciones están diseñadas para compensar algunas de las deficiencias del propio Prometheus, porque Prometheus se ha posicionado como un almacenamiento independiente desde el principio, no admite el almacenamiento a largo plazo y no tiene alta disponibilidad. Como resultado, Cortex y Thanos se convirtieron en las soluciones dominantes en la industria en ese momento.
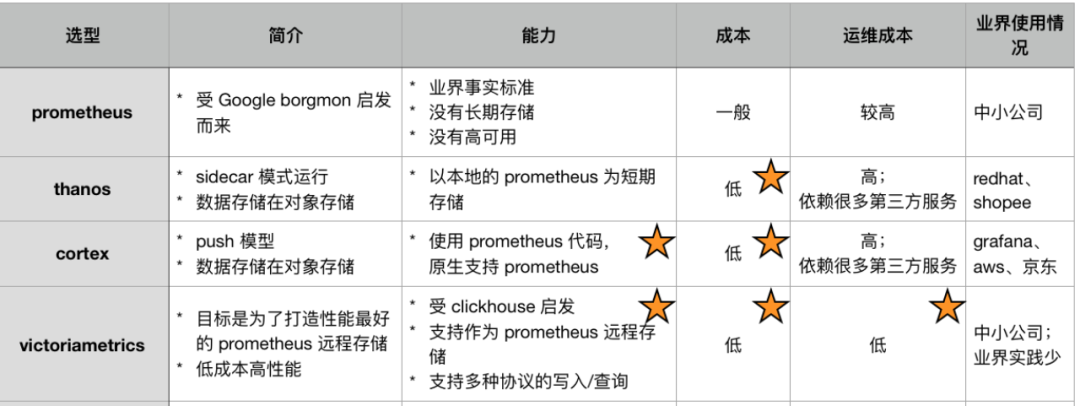
(Investigación sobre soluciones relacionadas con Prometheus en la industria)
Al comparar estas soluciones, descubrimos que tanto Cortex como Thanos pueden resolver eficazmente las deficiencias nativas de Prometheus. Desde una perspectiva de costos, dado que tanto Thanos como Cortex usan almacenamiento de objetos, sus costos son relativamente bajos. Sin embargo, estas dos soluciones utilizan una gran cantidad de servicios de terceros. Si la empresa no tiene almacenamiento de objetos o servicios en la nube, es posible que el equipo de observabilidad deba completar el mantenimiento de estos componentes.
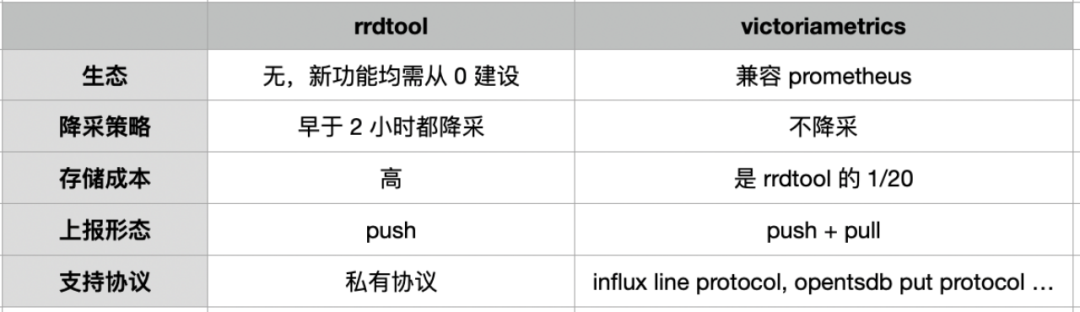
(Comparación de las soluciones RRDTool y VictoriaMetrics)
Por el contrario, VM es totalmente compatible con Prometheus en comparación con RRDTool. Además, mencionamos la estrategia de reducción antes. Los datos de RRDTool se reducirán después de más de dos horas. Una vez que se reduzca la extracción, no podremos ver los datos originales. La VM en sí no reduce la minería, lo que nos brinda más posibilidades. En términos de reducción de costos de almacenamiento, VM tiene un mejor rendimiento. En nuestra prueba de entorno, su costo de almacenamiento es solo aproximadamente 1/20 del de RRDTool. En términos de formulario de informe de datos, Prometheus está en formato Pull, mientras que RRDTool solo admite formulario Push y solo admite protocolos privados. Sin embargo, VM admite tanto Pull como Push, y también tiene un buen soporte para protocolos de informes de datos populares.
Dificultad 2: ¿Cómo introducir el ecosistema Prometheus?
Entonces, ¿podemos simplemente reemplazar la solución de almacenamiento con VM? En realidad, la respuesta es no. Al introducir un nuevo ecosistema, primero debemos considerar las soluciones corporativas existentes. Introducir un nuevo ecosistema no significa subvertir por completo la arquitectura del producto existente y no puede simplemente reemplazarla.
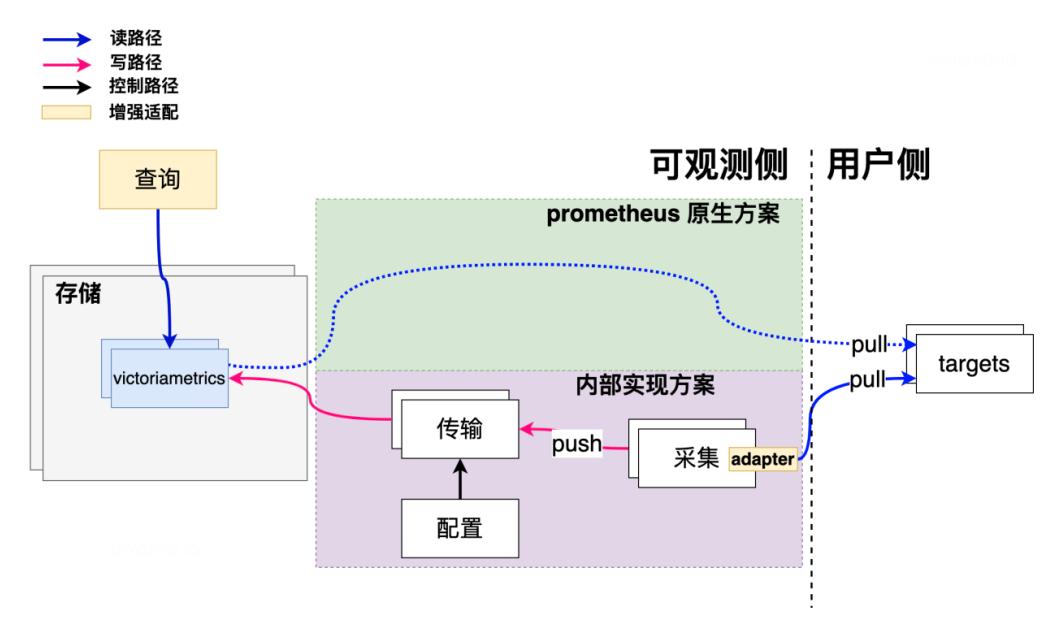
Para introducir una nueva ecología, Didi ha realizado algunos cambios. Como se muestra en la figura, la parte verde es el trabajo necesario para utilizar la solución nativa de Prometheus. Siempre que el objeto monitoreado admita una interfaz como "/metrics", Prometheus puede extraer datos. Para Didi, nuestra arquitectura original se basó en el modelo Push de recopilación, transmisión y almacenamiento. Por eso, agregamos un Adaptador compatible con Prometheus en la parte de colección. Sobre la base original, para aquellos nuevos servicios que admiten la extracción de Prometheus, también podemos utilizar nuestros propios métodos de recopilación para extraer datos.
En términos de los resultados de la introducción ecológica, hemos respaldado la recopilación de datos de Prometheus y podemos admitir dos escenarios comunes de visualización y alarma de gráficos de PromQL. Además, también hemos agregado algunas funciones nuevas en la dimensión de visualización del gráfico, como agregar la capacidad de valores atípicos de TopK/BottomK y otras dimensiones del gráfico. De esta manera, si un servicio tiene muchas instancias, podemos usar funciones como TopK/BottomK para encontrar valores atípicos.
En términos de retribuir a la comunidad, enviamos algunos RP a los funcionarios de VM y a la comunidad de Prometheus para contribuir a toda la comunidad.
2. ¿Cómo garantizar la estabilidad del propio sistema observable?
Como todos sabemos, el propósito de los sistemas observables es garantizar la estabilidad empresarial. Entonces, ¿cómo garantizamos la estabilidad del propio sistema observable? Primero, necesitamos explorar cómo monitorear este sistema observable. ¿Es posible configurar algunas políticas en mi propio sistema? ¿O crear algunos paneles? ¿O adoptar algún otro enfoque? En este sentido, compartiré algunos de nuestros experimentos y reflexiones.
2.1 ¿Cómo observar sistemas observables?
No podemos hacer que un sistema observable se observe a sí mismo. Por ejemplo, si el sistema de almacenamiento falla y la forma de consultar datos es consultarlos desde su propio almacenamiento, se formará una dependencia circular. Por tanto, el primer principio es que no se puede permitir que los sistemas observables se observen a sí mismos. El segundo principio, relacionado con el primero, es que se necesita un conjunto separado de servicios de alarma y recopilación de datos para realizar las observaciones.
En nuestra práctica, se utilizan dos métodos principales.
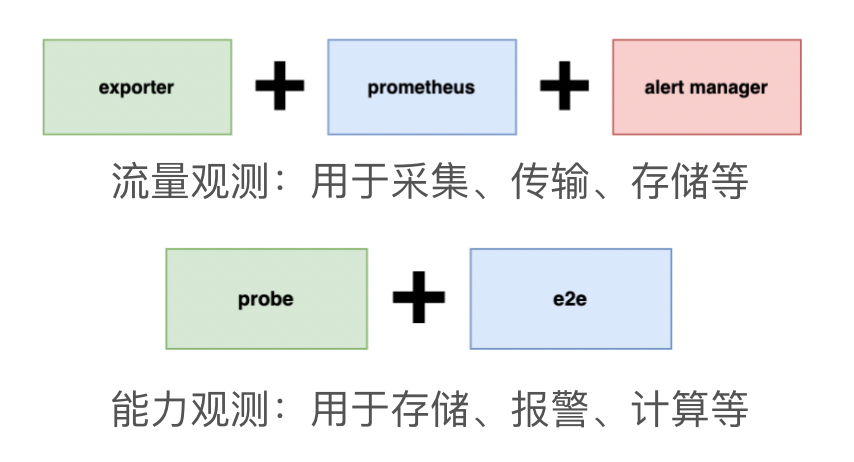
El primer método se utiliza para monitorear el tráfico y es adecuado para la recopilación, transmisión y almacenamiento de datos. Este enfoque realiza principalmente el autocontrol mediante Exporter, Prometheus y Alertmanager. Por ejemplo, si el tráfico de escritura del almacenamiento cambia repentinamente, puede utilizar este sistema para autocontrolarse.
Otro enfoque es el seguimiento de las capacidades. Tomando las alarmas como ejemplo, el método más simple es configurar una alarma que siempre active un umbral, pero que no envíe mensajes en tiempo real ni notificaciones SMS. Una vez que se interrumpe un evento de alarma, puede deberse a que hay un problema con el sistema de alarma en sí o hay un problema con la consulta de almacenamiento en la que depende el sistema de alarma. En este caso, podemos solucionar el problema instalando detectores y realizando inspecciones de un extremo a otro.
2.2 ¿Cómo garantizar que la arquitectura observable sea siempre estable?
Podemos considerarlo desde dos aspectos: uno es mediante la optimización arquitectónica y el otro es el uso de métodos de protección comunes.
2.2.1 Optimización de la arquitectura
Punto 1: No pongas todos los huevos en la misma canasta
Para la optimización arquitectónica, un principio simple es no poner todos los huevos en la misma canasta. Podemos lograr esto a través del siguiente diseño.
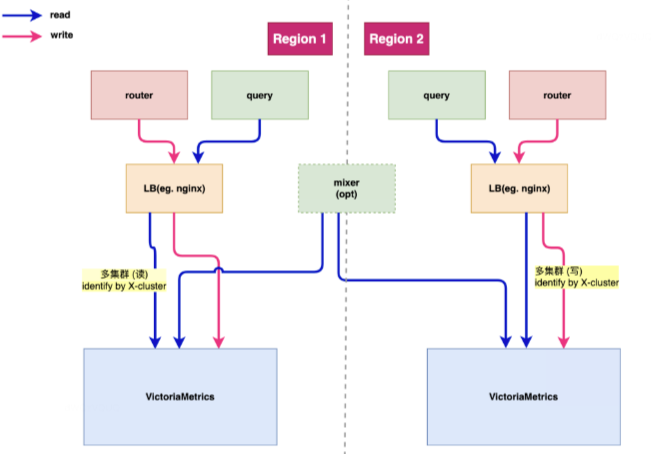
(Diseño de múltiples clústeres de almacenamiento de VictoriaMetrics)
Didi se dedica principalmente al negocio de viajes compartidos. Los datos de observación de nuestros negocios de viajes compartidos en línea y no en línea se almacenan en diferentes clústeres de almacenamiento. Este es el diseño de múltiples clústeres de VM que adoptamos. Por ejemplo, si ocurre un problema con una instancia comercial que no es de transporte compartido, esperamos que esto no afecte el negocio de transporte compartido y viceversa. Por lo tanto, diseñamos un sistema de almacenamiento de múltiples clústeres.

(Diseño de transporte de múltiples clústeres)
En términos de transmisión de datos, nuestra filosofía de diseño es similar, pero una diferencia es que la transmisión y el almacenamiento utilizarán diferentes estrategias de fragmentación debido a sus diferentes características de carga. Por ejemplo, el volumen de transmisión de una determinada empresa es muy grande, pero el volumen de consultas de almacenamiento es muy pequeño. En este caso, dividiremos los datos en el lado de transmisión y solo necesitamos asegurarnos de que los datos se escriban en el almacenamiento. lado. Pueden compartir el mismo clúster de almacenamiento.
Punto 2: Deseche los huevos podridos lo antes posible
También existe un principio que llamamos "deseche los huevos podridos a tiempo". En el módulo de transmisión, además de escribir en el almacenamiento, existen otros módulos posteriores, como alarmas de transmisión, etc.
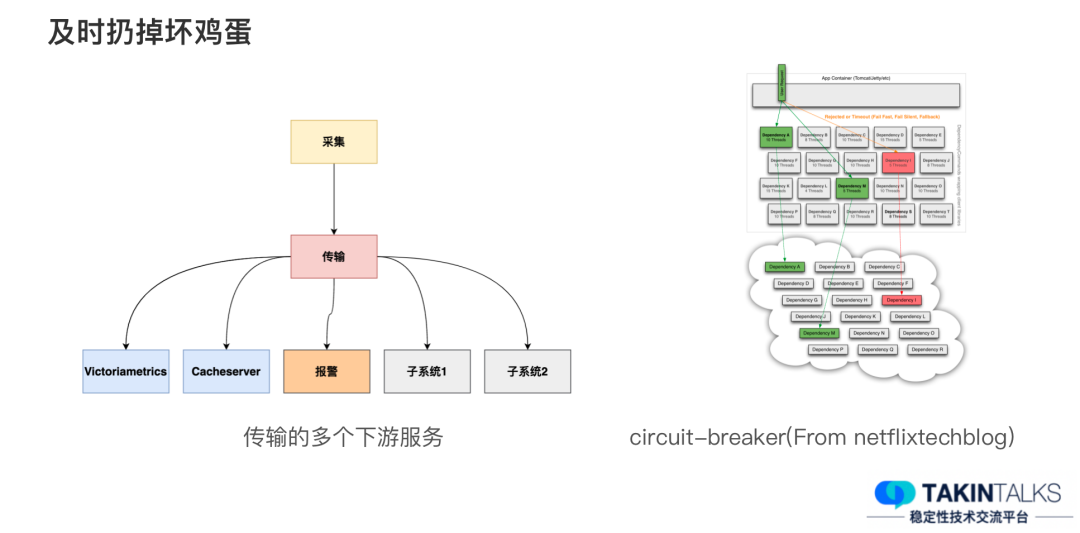
Por tanto, si un determinado subsistema se ralentiza por algún motivo, lo que afecta a todo el módulo de transmisión, no queremos verlo. Esperamos que cuando un subsistema se ralentice o se produzca un problema, se pueda eliminar del sistema a tiempo, es decir, la estrategia del disyuntor. En algunos casos, podemos realizar automáticamente una interrupción del circuito e intentar restaurar continuamente este subsistema. Si se recupera exitosamente, volveremos a conectar el sistema.
2.2.2 Otros métodos de protección comunes
Disyuntor, degradación, limitación de corriente multidimensional:
Además de los disyuntores y las degradaciones, también contamos con otras medidas de protección, como la limitación de corriente multidimensional. La limitación de corriente multidimensional utiliza estrategias flexibles para limitar las solicitudes. Por ejemplo, para algunas consultas continuas y de alta frecuencia que abarcan mucho tiempo, como consultas de datos durante meses o incluso años, aplicaremos métodos de limitación de corriente multidimensional.
Gestión de cheques lenta:
Otra salvaguardia es la gestión de controles lentos, que implica consultar un gran número de curvas. Por ejemplo, si una consulta involucra millones de curvas, debemos realizar una búsqueda lenta para descubrirlas y luego administrarlas. Durante algunos períodos de protección clave, habilitaremos estas estrategias. Una vez que se identifique una anomalía, usaremos limitación de corriente multidimensional y la limitaremos o directamente la deshabilitaremos en función de sus características.
Vive mas:
Para la multiactividad observable interna, el método que adoptamos es unificarla. Por ejemplo, si las líneas dedicadas entre la sala de ordenadores A y la sala de ordenadores B se interrumpen, debemos asegurarnos de que los usuarios puedan acceder de forma independiente a los datos en la sala de ordenadores correspondiente.
Sistema de evaluación de capacidad:
También disponemos de un sistema de evaluación de capacidades. Dado que el crecimiento de la arquitectura observable y del tráfico comercial o del volumen de pedidos puede no ser directamente proporcional, se necesita un conjunto de sistemas propios de evaluación de capacidad. El modelo de negocio de cada empresa puede ser diferente, por lo que es necesario establecer este sistema, que resulta útil como medio de protección.
Planos y simulacros:
También desarrollaremos planes y realizaremos simulacros para garantizar que estos métodos sean efectivos.
3. ¿Cómo se logra la observabilidad en Didi?
3.1 Selección de estrategia
El tema de la observabilidad es un tema muy candente en 2021 o 2022. Uno podría sentir que está bastante al revés si no habla de observabilidad. Primero echemos un vistazo a las definiciones de observabilidad de los principales fabricantes.
La observabilidad es una herramienta o solución técnica que ayuda a los equipos a depurar eficazmente sus sistemas. La observabilidad se basa en la exploración de propiedades y patrones que no están definidos de antemano. ——Fuente Google
La observabilidad es la capacidad de monitorear, medir y comprender el estado de un sistema o aplicación examinando su salida, registros y métricas de rendimiento. ——Fuente RedHat
La observabilidad es qué tan bien se comprende el estado o las condiciones internas de un sistema complejo basándose únicamente en lo que se sabe sobre el resultado externo. ——Fuente IBM
Cito aquí las definiciones de observabilidad de Google, RedHat e IBM respectivamente, y tienen dos consensos. La primera es que la observabilidad es la capacidad de comprender los estados internos de un sistema desde el exterior, y no es necesario conocer esos estados. El segundo consenso es que existen muchos medios de observabilidad, incluidos registros, indicadores, eventos, etc.
Entonces, ¿cómo lograr la observabilidad? Cada fabricante importante tiene su propio método de implementación. Google recomienda su plataforma en la nube GCP, RedHat recomienda OpenShift Observability, IBM tiene su propio producto Instana Observability y Grafana recomienda LGTM (Loki, Tempo, Mimir).
En conjunto, existen aproximadamente tres formas de lograr la observabilidad. El primero es adquirir los servicios de proveedores de SaaS, el segundo es recopilar y almacenar datos observables tan detallados como sea posible y el tercero es correlacionar múltiples datos de observación.
3.2 Comparación de esquemas
Para Didi, el primer método de implementación no es adecuado, por lo que lo excluimos primero.
En cuanto al segundo método de implementación, es "lo más detallado posible", por lo que dividimos los datos de observación en dos dimensiones, a saber, dimensionalidad y cardinalidad. La dimensionalidad es un concepto similar a las etiquetas, como marcas de tiempo, versiones, ID de clientes, etc. Cardinality toma como ejemplo el ID del cliente y puede tener datos del 10,01 al 19,999. La ventaja de esta solución es que puede recopilar una gran cantidad de datos, pero las desventajas son el alto costo de implementación, el gran consumo de recursos y la baja utilización de datos.
El tercer método de implementación es asociar múltiples datos de observación. Los datos de observación comunes incluyen métrica, seguimiento y registro. Los datos de métricas son una abstracción de alto nivel que puede indicar la cantidad de errores, pero no pueden proporcionar información de error específica. Los datos de seguimiento se utilizan principalmente para la correlación entre servicios, como qué servicios ha experimentado una solicitud. Los datos de registro son la información preferida de los desarrolladores y proporcionan los datos más detallados y legibles por humanos. Sin embargo, la desventaja de esta forma de correlacionar múltiples datos de observación es que la implementación de la arquitectura es relativamente compleja.
3.3 Diseño de arquitectura
En Didi, tomamos prestados los dos métodos anteriores y dividimos los datos en dos categorías: cardinalidad baja y cardinalidad alta. La cardinalidad baja se refiere a datos métricos, mientras que la cardinalidad alta se refiere a datos de registro. Almacenamos estos dos tipos de datos en diferentes bases de datos y establecemos su correlación.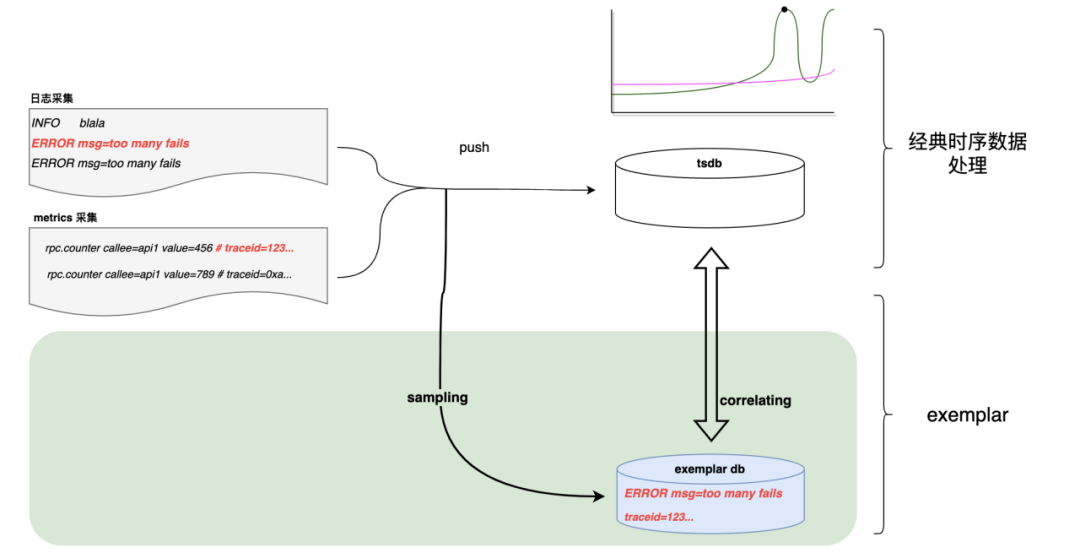
Por ejemplo, si recopilamos dos registros de errores dentro de un período de tiempo, informaremos el error número "2" a la base de datos de series temporales. Al mismo tiempo, tomaremos una muestra de uno de los registros de errores y lo almacenaremos en Exemplar DB. Luego, asociaremos la base de datos de series temporales con la base de datos Exemplar mediante etiquetas.
3.4 Resultados prácticos
Los resultados de la práctica de observabilidad de Didi son muy significativos. Antes de establecer la observabilidad, debemos iniciar sesión en la máquina y recuperar los registros al solucionar problemas. Si tiene la suerte de encontrar la máquina con el problema, considérese afortunado. Pero si el problema no es de esta máquina, ni siquiera de este servicio, tendremos que repetir las operaciones anteriores. Además, incluso después de tales operaciones, no está claro si se puede encontrar el problema.
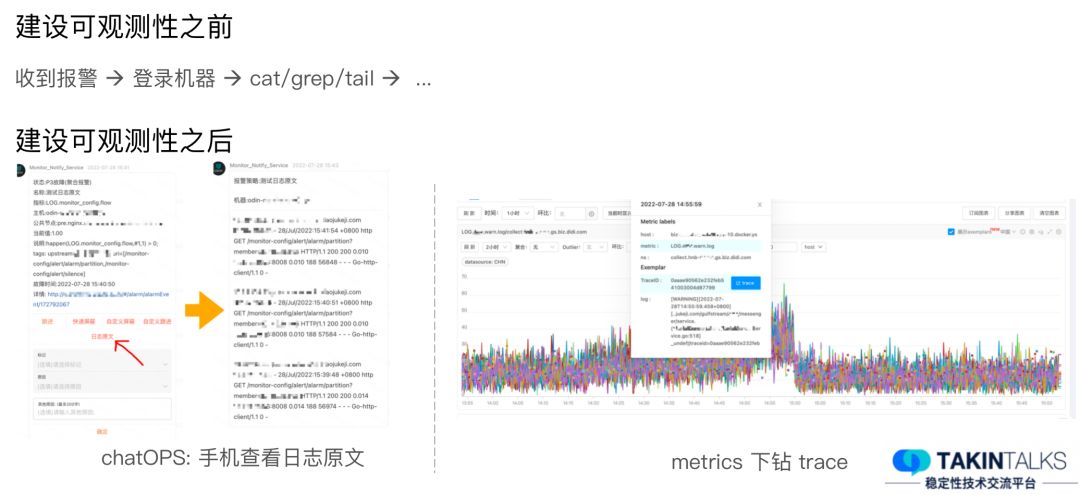
Sin embargo, después de establecer la observabilidad, cuando recibimos un mensaje de alarma, podemos ver directamente el texto del registro original asociado con la alarma. Después de comprobar el texto original del registro, si cree que no hay ningún problema importante, puede dejarlo así temporalmente. Si se trata de una emergencia, iniciaremos procedimientos de emergencia.
Además, cuando miramos el gráfico, si encontramos que un indicador sube repentinamente y queremos saber cuál es la causa, podemos utilizar la función de desglose. Esta función no solo nos permite ver el texto original del registro, sino que también extrae la información de seguimiento si el registro contiene información de seguimiento. La información de seguimiento se puede luego desglosar hasta productos de seguimiento especializados para su posterior procesamiento.
4. Resumen y perspectivas El desarrollo de la arquitectura de observabilidad de Didi en realidad se basa en diferentes necesidades, escenarios y antecedentes de época, y se selecciona la solución más adecuada.
Nos hemos conectado con algunos ecosistemas maduros en la industria y los hemos integrado en nuestro sistema, lo que nos ha ayudado enormemente a completar una gran cantidad de trabajo y mejorar nuestra eficiencia laboral. Al mismo tiempo, en el proceso de construcción de la plataforma de observabilidad, también adoptamos algunas estrategias para garantizar la estabilidad del propio sistema de observación.
Vale la pena señalar que no existe una forma unificada de implementar la observabilidad y que cada empresa tiene sus propias características. Por tanto, cada empresa necesita personalizar soluciones especializadas según sus propias características, y seleccionar y ajustar continuamente la solución más adecuada según la situación real. (Finaliza el texto completo)
Preguntas y respuestas
1. ¿Cuenta Didi con un equipo técnico dedicado a mantener la arquitectura observable? Prometheus tiene capacidades de escalabilidad horizontal relativamente limitadas. ¿Cuáles son los problemas específicos con InfluxDB?
2. ¿Cómo medir la observabilidad de una arquitectura? ¿Alguna sugerencia?
3. ¿Es necesario que la puntualidad de la Métrica esté en el segundo nivel?
4. La interfaz se agota ocasionalmente. La cadena de llamadas solo puede ver el nombre de la interfaz de tiempo de espera, pero no puede ver los métodos internos. No se puede localizar la causa raíz y es difícil de reproducir. ¿Qué debo hacer?
Para obtener las respuestas a las preguntas anteriores, haga clic en "Leer texto completo" para ver la versión completa de las respuestas.
Declaración: Este artículo fue escrito originalmente por la cuenta pública "TakinTalks Stability Community" y expertos de la comunidad. Si necesita reimprimir, responda "Reimprimir" en segundo plano para obtener autorización.
IntelliJ IDEA 2023.3 y JetBrains Family Bucket actualización anual de la versión principal nuevo concepto "programación defensiva": conviértase en un trabajo estable GitHub.com ejecuta más de 1200 hosts MySQL, ¿cómo actualizar sin problemas a 8.0? El equipo Web3 de Stephen Chow lanzará una aplicación independiente el próximo mes ¿ Se eliminará Firefox? Visual Studio Code 1.85 lanzado, ventana flotante Yu Chengdong: Huawei lanzará productos disruptivos el próximo año y reescribirá la historia de la industria. La CISA de EE. UU. recomienda abandonar C/C++ para eliminar las vulnerabilidades de seguridad de la memoria. TIOBE Diciembre: Se espera que C# se convierta en la programación idioma del año Un artículo escrito por Lei Jun hace 30 años: "Principio y diseño del sistema experto de determinación de virus informáticos"¡Este artículo es publicado por OpenWrite, un blog que publica varios artículos !