Como el sistema OLAP más potente de la industria, ClickHouse se utiliza ampliamente en Xiaohongshu en múltiples campos comerciales, como publicidad, comunidades, transmisiones en vivo y comercio electrónico. Sin embargo, la arquitectura nativa de ClickHouse MPP tiene importantes limitaciones en términos de costos de operación y mantenimiento, expansión elástica y recuperación de fallas. Para afrontar el desafío, el equipo de flujo de datos de Xiaohongshu desarrolló de forma independiente el almacén de datos en tiempo real nativo de la nube RED ClickHouse (en adelante, "REDck") basado en ClickHouse de código abierto.
Sobre la base de mantener el rendimiento ultraalto original de ClickHouse, hemos llevado a cabo una profunda transformación nativa de la nube para lograr capacidades elásticas de expansión y contracción de las capas informáticas y de almacenamiento, reduciendo así efectivamente la carga de operación y mantenimiento y reduciendo los costos. REDck tiene capacidades de análisis interactivo del usuario que admiten datos a nivel de PB y puede satisfacer de manera flexible diversas necesidades de análisis de datos para satisfacer las crecientes necesidades comerciales y de análisis de datos de Xiaohongshu.
En la actualidad, REDck se ha implementado con éxito en más de 10 escenarios comerciales, como comercio electrónico empresarial, publicidad, comunidad y transmisión en vivo, con una escala de almacenamiento total de más de 30 PB. Ha logrado resultados notables en la reducción de costos y el aumento de la eficiencia, especialmente en escenarios típicos como plataformas experimentales y plataformas de análisis del comportamiento del usuario. Tomando la plataforma experimental como ejemplo, en los últimos 2 años, el período de almacenamiento de datos de la plataforma experimental ha aumentado de 2 meses a 2 años, y el número de indicadores experimentales y escenarios de análisis también ha aumentado más de 10 veces. Con un crecimiento empresarial tan rápido, REDck ofrece una garantía de disponibilidad del 99,9 % para la plataforma experimental y su fuerte escalabilidad se ha convertido en un fuerte apoyo para la expansión empresarial.

1.1 Desarrollo de OLAP en tiempo real de Xiaohongshu
Desde el nacimiento de Xiaohongshu, todo el sistema de infraestructura se ha construido en la nube pública, lo que la convierte en nativa de la nube.
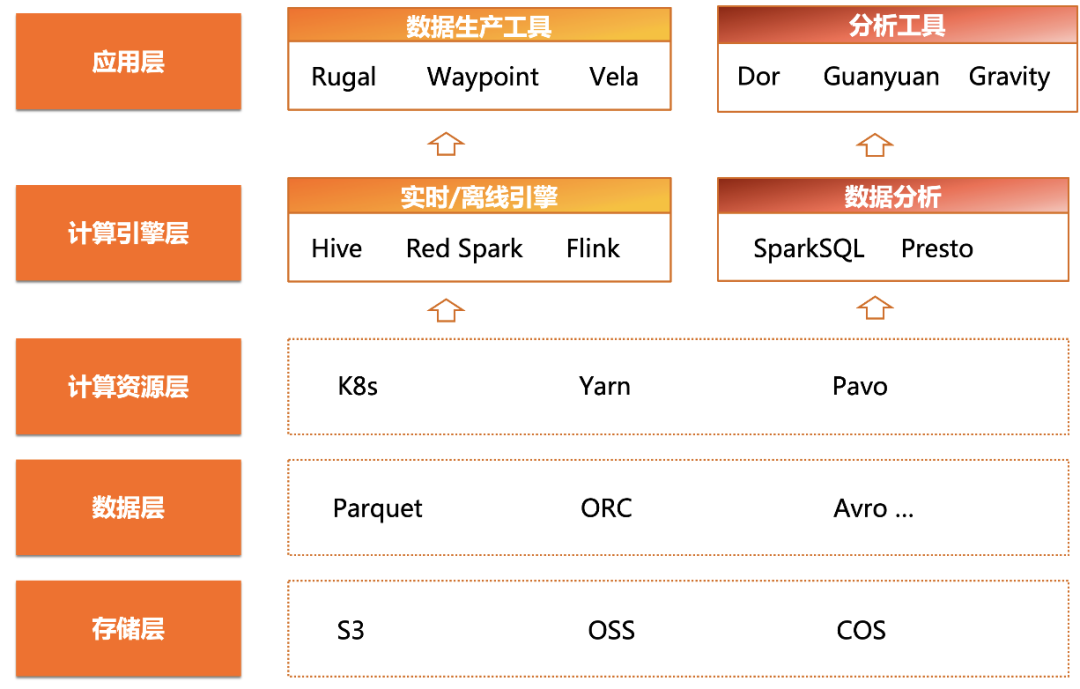
Como se muestra en la figura anterior, el sistema de arquitectura de big data nativo de la nube de Xiaohongshu consta de una capa de aplicación, una capa de motor informático, una capa de recursos informáticos, una capa de datos y una capa de almacenamiento de arriba a abajo.
● El núcleo de la capa de almacenamiento es el servicio de almacenamiento de objetos proporcionado por los principales proveedores de la nube. La capa de datos utiliza formatos de datos comunes como Parquet, ORC, Avro, etc., y proporciona servicios de metainformación unificados a través de Hive Metastore.
● En la capa informática , Xiaohongshu utiliza marcos de recursos informáticos como Kubernetes y YARN para proporcionar agrupación de recursos y capacidades de expansión elástica.
● En la capa del motor informático , los enlaces ETL fuera de línea y en tiempo real se implementan con la ayuda de tecnologías como Spark y Flink, y las funciones de análisis de datos e informes fuera de línea se proporcionan externamente a través de herramientas como Presto y SparkSQL.
Esta arquitectura típica nativa de la nube proporciona a Xiaohongshu un alto grado de flexibilidad y escalabilidad para el procesamiento de datos. Sin embargo, en esta arquitectura, la falta de un motor OLAP en tiempo real limita el desarrollo del negocio de análisis de datos de Xiaohongshu; existe una necesidad urgente de introducir un motor OLAP en tiempo real con un potente rendimiento de análisis para satisfacer la creciente demanda de análisis de datos.
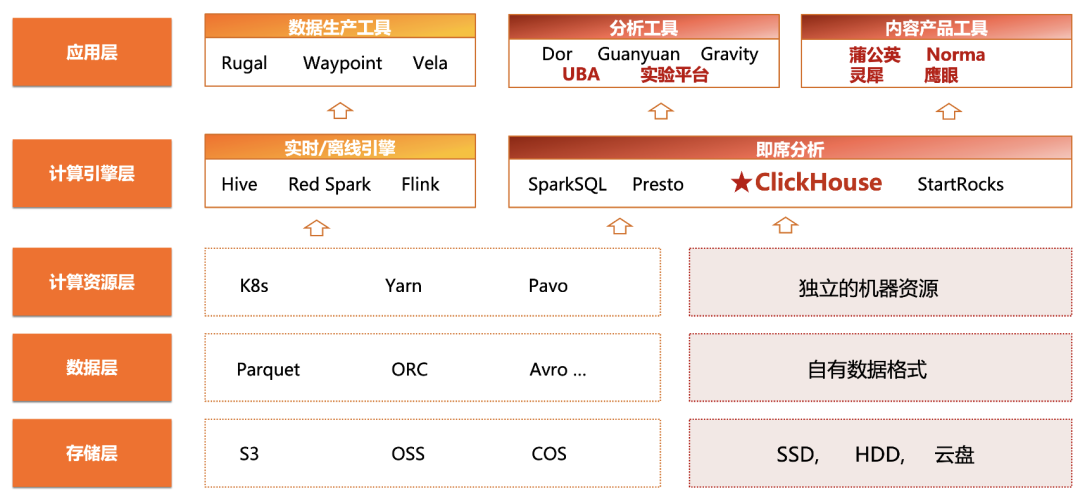
Como base de datos OLAP en tiempo real de alto rendimiento, las principales empresas prefieren ClickHouse por su excelente rendimiento extremo, iteraciones de actualización rápidas y estables y su comunidad de código abierto con capacidad de respuesta activa. Para lograr consultas y análisis más rápidos, el equipo de flujo de datos de Xiaohongshu creó un clúster ClickHouse para la plataforma experimental de la empresa.
1.2 Problemas enfrentados
En la etapa inicial, ClickHouse demostró un rendimiento excelente, con una velocidad de respuesta de consultas extremadamente rápida, flexibilidad y rendimiento en tiempo real, y proporcionó capacidades de análisis Ad-Hoc más potentes para los servicios de análisis de datos de Xiaohongshu. Sin embargo, con la acumulación de datos, el tamaño del clúster continúa expandiéndose y el sistema OLAP en tiempo real existente encuentra los siguientes problemas durante su uso:
● Dificultad en la expansión elástica.
Con el rápido desarrollo del negocio de Xiaohongshu, la expansión de la capacidad se ha convertido en una operación frecuente de operación y mantenimiento para el equipo. ClickHouse adopta una arquitectura Share-Nothing y los recursos informáticos y de almacenamiento de cada nodo están fuertemente vinculados, lo que hace que la expansión del clúster esté limitada por el ciclo de programación de la máquina. Al mismo tiempo, el proceso de expansión introducirá trabajos de migración de datos semanal o incluso mensual, lo que tendrá un impacto en las consultas de los usuarios, incluidos problemas de estabilidad y coherencia.
● Baja utilización de recursos
ClickHouse utiliza un mecanismo de copias múltiples para mejorar la confiabilidad general, pero también conduce a una duplicación geométrica de los recursos. Debido al desequilibrio entre el almacenamiento y la informática, en la mayoría de los escenarios, la demanda de almacenamiento de datos es mucho mayor que la demanda informática, pero la unión del almacenamiento y la informática da como resultado un grave desperdicio de potencia informática. Además, muchas empresas tienen altibajos obvios, y la falta de capacidades de expansión elástica conduce a una grave redundancia de recursos.
● Problemas de estabilidad
ClickHouse tiene capacidades débiles de aislamiento de recursos y puede causar fácilmente inestabilidad en la experiencia de consulta del usuario. Durante los períodos pico de consultas, las limitaciones de recursos conducirán a un aumento significativo en las tasas de fallas y retrasos en las consultas. Además, el mecanismo de copia múltiple de ClickHouse depende en gran medida de Zookeeper. Cuando la escala del clúster alcanza un cierto nivel, la frecuencia de fallas de Zookeeper aumenta, lo que limita las capacidades de expansión del clúster.
● Problemas de sincronización de datos
El problema que los usuarios han criticado a ClickHouse es que carece de un sistema de transacciones distribuidas maduro y que a menudo se producen inconsistencias de datos durante la sincronización de datos.
● Problemas de mantenimiento
Las tablas distribuidas de ClickHouse y los modos de tablas replicadas subyacentes aumentan en gran medida la dificultad de la administración de tablas. Al mismo tiempo, carecen de las funciones de administración distribuida necesarias, como la unión de nodos, la salida de nodos y el equilibrio de copias, lo que hace que el mantenimiento sea costoso una vez que aumenta el número de clústeres.
Por las razones anteriores, es difícil que la versión comunitaria de código abierto de ClickHouse satisfaga las aplicaciones a gran escala de la empresa en publicidad, comunidad, transmisión en vivo, comercio electrónico y otras necesidades comerciales. Es urgente que el equipo resuelva los problemas críticos de límite de almacenamiento y operación y mantenimiento del clúster.
1.3 Selección de solución
Opción 1: expansión del clúster
La expansión del clúster es una solución común para resolver problemas de cuellos de botella en el almacenamiento. Sin embargo, la versión comunitaria de código abierto de ClickHouse no tiene soporte integrado para el equilibrio automático de carga de datos, por lo que los nodos recién agregados deben equilibrar manualmente la carga y sincronizar las estructuras de tablas de otros clústeres. Además, la expansión de la capacidad no puede resolver realmente los desafíos de los servicios de datos masivos. Al final, aún es necesario agregar TTL para eliminar datos históricos. Al mismo tiempo, el clúster ampliado tiene riesgos en términos de disponibilidad: es necesario invertir el doble de recursos de la máquina para evitar la pérdida de datos causada por puntos únicos de falla, lo que aumenta el costo y la complejidad.
En resumen, la solución de expansión del clúster no solo aumenta en gran medida la dificultad de operación y mantenimiento, sino que tampoco resuelve fundamentalmente el problema del cuello de botella del almacenamiento. El problema del almacenamiento sigue siendo una "Espada de Damocles" que siempre pende sobre la cabeza del equipo.
Opción 2: Separación de almacenamiento y cálculo
Otra opción es un camino más difícil, que consiste en desarrollar un almacén de datos en tiempo real nativo de la nube de desarrollo propio. Aunque esta solución enfrenta muchos desafíos, como la centralización de metainformación, la transformación de la separación de cálculos y almacenamiento, la contenedorización, etc., y requiere que el equipo pase de las capacidades de operación y mantenimiento a la investigación y el desarrollo independientes, fundamentalmente puede resolver el problema de escalabilidad.
En los sistemas de bases de datos tradicionales, el almacenamiento y la informática suelen estar fuertemente vinculados, es decir, comparten los mismos recursos de la máquina. Gracias al rápido desarrollo de la tecnología nativa de la nube, cada vez más sistemas de bases de datos eligen adoptar la separación del almacenamiento y la arquitectura informática, desacoplando la capa de almacenamiento de la capa informática, lo que permite expandir elásticamente los recursos de almacenamiento y los recursos informáticos, respectivamente. La arquitectura de separación de almacenamiento e informática aporta muchos beneficios: en primer lugar, almacenar datos en el almacenamiento de objetos proporcionado por los proveedores de la nube proporciona al almacenamiento de datos capacidades de expansión casi infinitas. En segundo lugar, ajustar dinámicamente los recursos informáticos según la demanda para cumplir con los requisitos de rendimiento de la informática de alta frecuencia en tiempo real y los costos de control. Finalmente, ante una falla, el almacenamiento de datos externo se puede migrar y restaurar rápidamente, lo que mejora en gran medida la confiabilidad de los datos.
Hoy en día, la mayoría de las bases de datos nativas de la nube se implementan en base a una arquitectura de separación de computación y almacenamiento, como SnowFlake, Redshift, TiDB, etc. Se puede decir que la separación del almacenamiento y el cálculo se ha convertido en la dirección principal de las bases de datos distribuidas.
1.4 Nuestras elecciones
Al final, elegimos el camino correcto pero difícil. Esperamos que al desarrollar una arquitectura de separación informática y de almacenamiento de desarrollo propio, podamos resolver fundamentalmente los problemas de expansión, operación y mantenimiento del motor OLAP en tiempo real, y respaldar mejor la rápida desarrollo del negocio de análisis de Xiaohongshu. La autoinvestigación nos permite responder rápidamente a las necesidades del negocio y facilita el control de costes.
Basándonos en la versión comunitaria de código abierto de ClickHouse, creamos una versión separada de cálculo y almacenamiento de Red ClickHouse basada en el almacenamiento de objetos, denominada REDck .

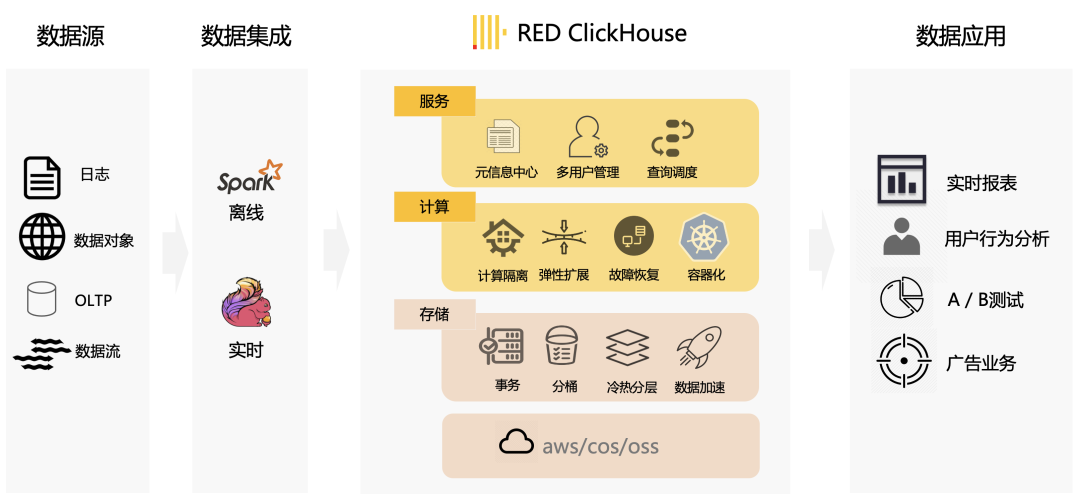
En la figura anterior se muestra el diagrama de diseño general de la base de datos analítica nativa de la nube de desarrollo propio de Xiaohongshu. REDck tiene la capacidad de proporcionar análisis complejos de segundo nivel en tiempo real con datos masivos y ha respaldado ampliamente muchos escenarios comerciales dentro de la empresa, como análisis de pruebas A / B, análisis del comportamiento del usuario y agrupación de usuarios publicitarios.
2.1 Arquitectura de separación de almacenamiento y cálculo
La arquitectura de separación de almacenamiento y cálculo de REDck se muestra a continuación, que incluye específicamente tres capas:
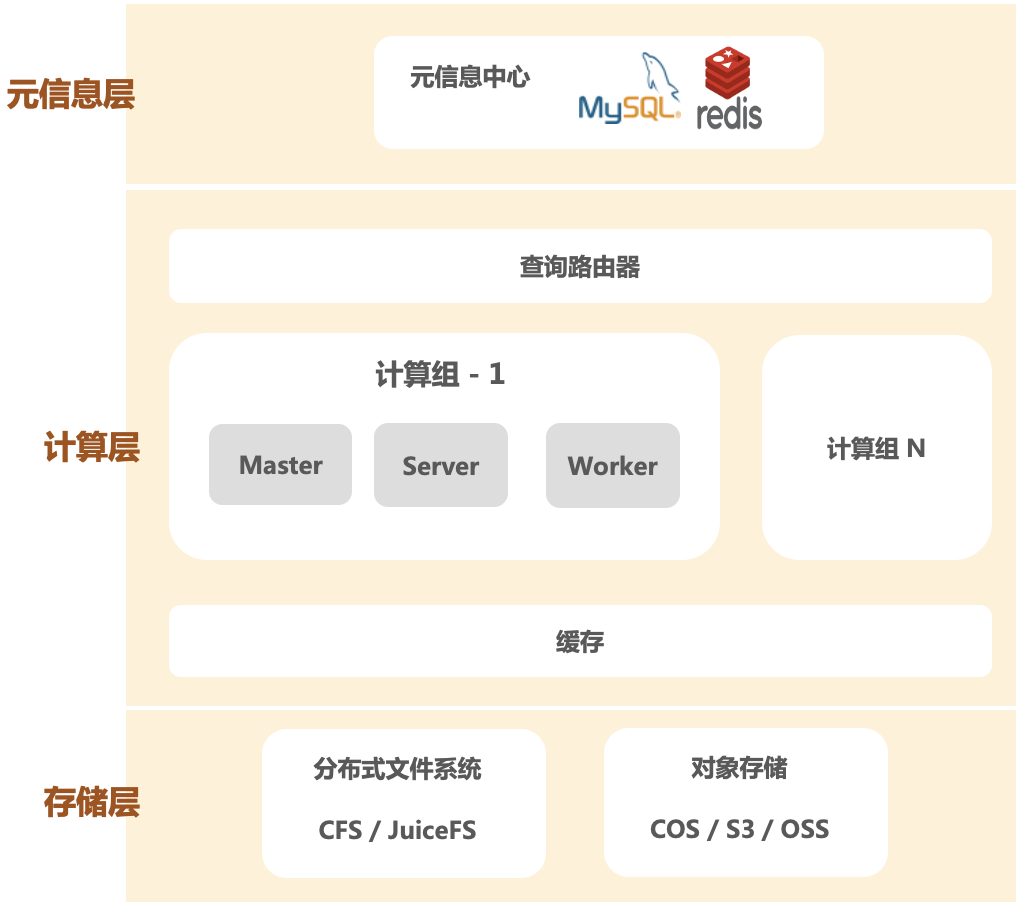
● Centro de metainformación unificado
En ClickHouse de código abierto, la metainformación se almacena en el directorio del disco local de cada nodo y la metainformación correspondiente se construye leyendo la lista de directorios. El servicio unificado de metainformación creado por REDck es un servicio centralizado sin estado, que incluye múltiples métodos de almacenamiento, como almacenamiento interno y almacenamiento externo; el modelo de almacenamiento interno elige una base de datos relacional (como MySQL) o una base de datos de valores clave (como Redis) y el modelo de almacenamiento externo El modelo de almacenamiento se puede integrar profundamente con el almacén de datos de Hive y el lago de datos Iceberg.
La ventaja de construir una capa de servicio de metainformación unificada es que la información general del clúster se puede captar de forma centralizada en lugar de dispersarse en nodos de máquinas individuales. La capacidad de gestión de información centralizada hace que el motor de base de datos sea más conveniente para realizar la separación del almacenamiento y el cálculo y el mecanismo de transacción. Actualmente, cada clúster tiene su propio servicio de metainformación independiente, y en el futuro se pueden implementar aún más servicios de metadatos de múltiples clústeres, es decir, solo hay una copia del servicio de metadatos y puede ser compartida por múltiples clústeres.
● Capa informática
Tomando el grupo de computación como unidad básica, cada grupo de computación es un clúster de computación distribuido de múltiples nodos. Los usuarios acceden al almacén de computación a través de la puerta de enlace sin preocuparse por los detalles del nodo de servidor y del nodo de trabajo subyacentes. Las tareas informáticas serán programadas por el nodo servidor para el nodo trabajador para su ejecución bajo demanda. Además de esto, el clúster también tiene una función maestra responsable de gestionar y coordinar el estado del centro del clúster. Gracias a la separación del almacenamiento y la informática, el clúster puede expandirse fácilmente horizontal y verticalmente.
● Capa de almacenamiento
La capa de almacenamiento implementa una variedad de métodos de almacenamiento de bajo costo, como sistemas de archivos distribuidos y almacenamiento de objetos, proporcionando capacidades de almacenamiento eficientes y escalables para que la base de datos satisfaga las necesidades del procesamiento masivo de datos.
2.2 Servicio de metadatos unificados
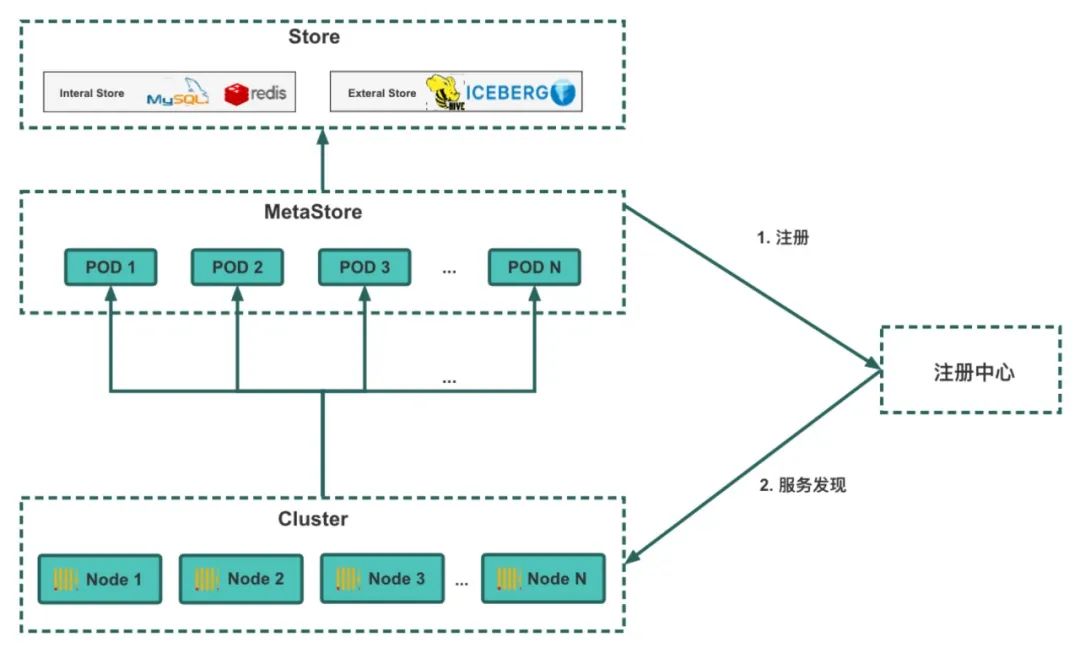
Una vez que los datos se almacenan en un almacenamiento de objetos en la nube, garantizar que cada nodo tenga acceso a la metainformación de los datos es una tarea desafiante. En ClickHouse de código abierto, la metainformación proviene del directorio en el disco y la metainformación correspondiente se construye leyendo la lista de directorios. Sin embargo, la metainformación está dispersa dentro de cada nodo y cada nodo tiene un estado único. Cuando un nodo deja de funcionar, todo el clúster queda inutilizable. Para lograr que cada nodo comparta información de metadatos unificada y mejorar la confiabilidad, REDck introduce una base de metadatos unificada y la función Metastore. Metastore es responsable de la gestión unificada de la metainformación del clúster. Una vez iniciado cada nodo informático, solo necesita acceder a Metastore para obtener la metainformación más reciente.
El almacenamiento de base de metadatos unificado se divide en dos métodos: almacenamiento interno y almacenamiento externo.Utilizamos MySQL como almacenamiento interno para almacenar metadatos y utilizamos las características de transacción de MySQL para garantizar la coherencia general. Metastore se hace cargo y mantiene la información de todo el clúster, de modo que ya no es necesario administrar el clúster a través de Zookeeper, eliminando así las restricciones de Zookeeper en ClickHouse. Al mismo tiempo, para el almacenamiento de metainformación, utilizamos REDkv desarrollado internamente (análogo al Redis de código abierto) para implementar un conjunto de mapeo del sistema de archivos, que rompe completamente con las limitaciones del sistema de archivos del disco y permite que el clúster se vuelva verdaderamente nativo de la nube. En términos de almacenamiento externo, nos estamos integrando activamente con el almacén de datos de Hive y el lago de datos Iceberg, para que REDck pueda leer directamente metainformación del almacenamiento externo.
El proceso de comunicación entre Metastore y REDck se muestra en la siguiente figura: Primero, MetaStore implementado enviará una solicitud de registro al centro de registro para registrar el servicio. Cuando se implemente el clúster REDck, solicitará el descubrimiento de servicios al centro de registro y accederá a los servicios descubiertos para obtener información de metadatos.
2.3 Optimización del acceso al almacenamiento de objetos
El almacenamiento de objetos tiene las características de expansión ilimitada, bajo costo y confiabilidad extremadamente alta. Al utilizar el almacenamiento de objetos para almacenar datos, podemos resolver fundamentalmente las crecientes necesidades de almacenamiento de datos y decir adiós a los problemas causados por el almacenamiento de datos tradicional. La confiabilidad del almacenamiento de objetos nos permite abandonar el mecanismo de copia, resolviendo así una serie de problemas espinosos como la coherencia de la copia, el desperdicio de recursos y la estabilidad de Zookeeper, y proporciona una base para la falta de estado de los nodos REDck.
Pero el almacenamiento de objetos no es perfecto. Después de introducir el almacenamiento de objetos, encontramos los siguientes problemas:
● Velocidad de acceso : el límite superior del rendimiento total del almacenamiento de objetos está teóricamente limitado sólo por el ancho de banda, pero la velocidad de acceso de un solo subproceso es baja, mucho menor que la del disco.
● Latencia : en la actualidad, se accede al almacenamiento de objetos principalmente a través del protocolo HTTP, que tiene un gran retraso (incluido el retraso de operaciones como el establecimiento de una conexión, que puede alcanzar los 20 milisegundos), lo que es extremadamente hostil para algunos archivos pequeños.
● Estabilidad : cómo reducir el impacto de los problemas de estabilidad del almacenamiento de objetos de múltiples proveedores de nube en la capa informática.
El almacenamiento de objetos es la piedra angular de REDck y sus problemas de rendimiento se convertirán en el cuello de botella de todo el sistema de base de datos. Con este fin, hemos realizado las siguientes optimizaciones para los problemas de lectura y escritura del almacenamiento de objetos:
● Mejorar el mecanismo de almacenamiento en caché : mejore la velocidad de acceso al almacenamiento de objetos a través del mecanismo de almacenamiento en caché, logrando así una mejora cien veces mayor en el rendimiento de las consultas (consulte la estrategia de almacenamiento en caché para obtener más detalles). Para los datos no almacenados en caché, se utilizan métodos de paralelización para aumentar la velocidad de descarga de datos y lograr una mejora del rendimiento diez veces mayor.
● Optimice el proceso de cálculo de consultas : reduzca el retraso de HTTP a un nivel que los usuarios puedan ignorar mediante el reordenamiento del plan de ejecución de consultas, la optimización adaptativa de subprocesos múltiples y otros medios.
● Reconstruir el módulo de acceso : Optimice y reconstruya el módulo de acceso al almacenamiento de objetos, agregue inspección de datos, detección de tiempo de espera y mecanismo de reintento fallido para mejorar la estabilidad del acceso.
El proceso específico se muestra en la siguiente figura:
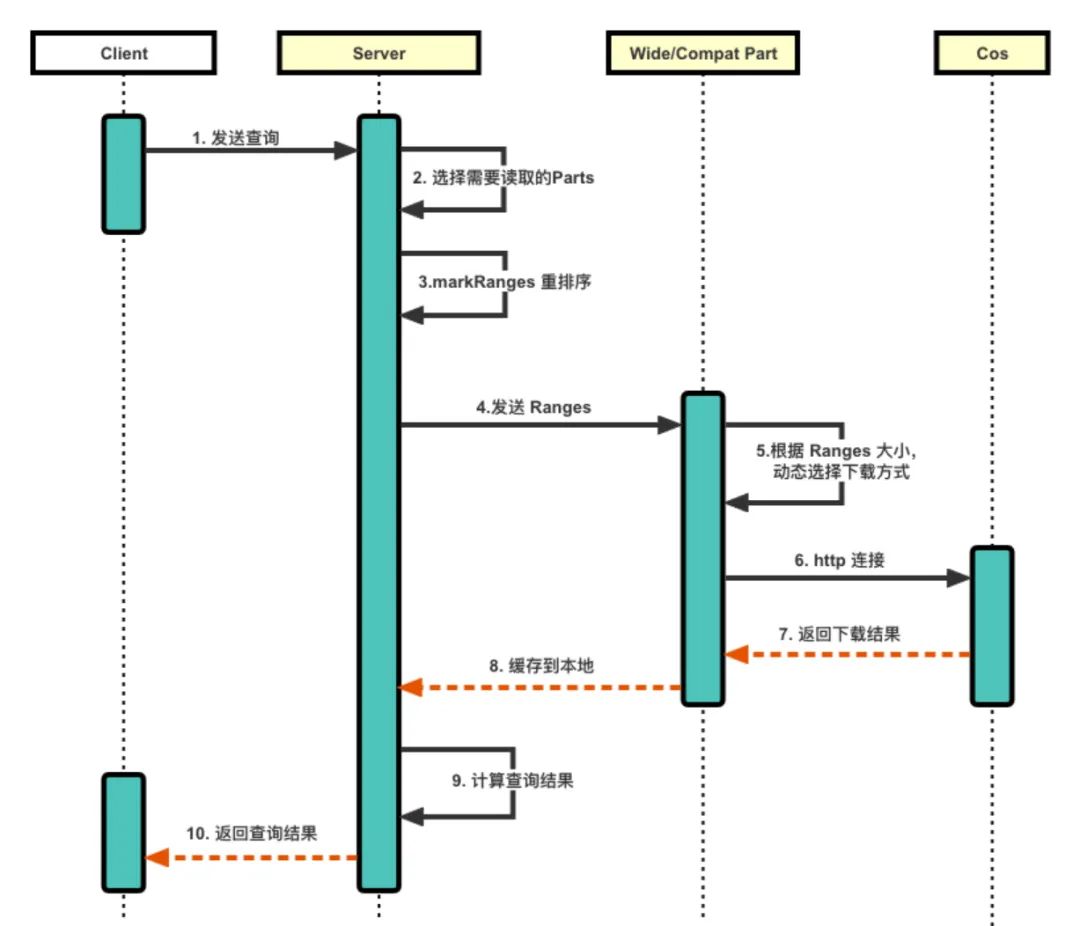
1. El cliente envía la consulta al servidor y el servidor selecciona las Partes que deben leerse en función de la consulta y, al mismo tiempo, reordena los rangos de marcas de las Partes para que cada hilo de conexión lea la Marca de la misma Parte. , lo que reduce la cantidad de conexiones y, por lo tanto, reduce el retraso de HTTP.
2. Pase los rangos reordenados a la clase de pieza correspondiente. La pieza selecciona dinámicamente el método de descarga (dividido en tres tipos) según el tamaño de los rangos, lo que puede reducir la presión de descarga.
a. Para piezas grandes, utilice la descarga de subprocesos múltiples y segmentos múltiples y, finalmente, combine los múltiples segmentos en una sola pieza.
b. Para piezas pequeñas, primero colóquelas en la memoria caché y luego descárguelas localmente.
C. Para otras partes, elija descargar directamente al local.
3. El servidor obtiene la pieza descargada, calcula los resultados de la consulta y los devuelve al cliente.
2.4 Optimización de caché
El almacenamiento de objetos nos proporciona la base para realizar la separación del almacenamiento y el cálculo, pero también trae el problema del retraso cuando las consultas deben extraerse de la nube. Aunque la optimización del almacenamiento de objetos resuelve el problema de recuperación en la mayoría de los escenarios, para algunos datos candentes a los que se accede con frecuencia, la recuperación repetida de la nube no es eficiente. Por esta razón, propusimos una estrategia de almacenamiento en caché que utiliza el disco de la máquina como disco de caché para el almacenamiento de objetos para proporcionar una garantía de alto rendimiento para los requisitos de consultas de alta frecuencia.
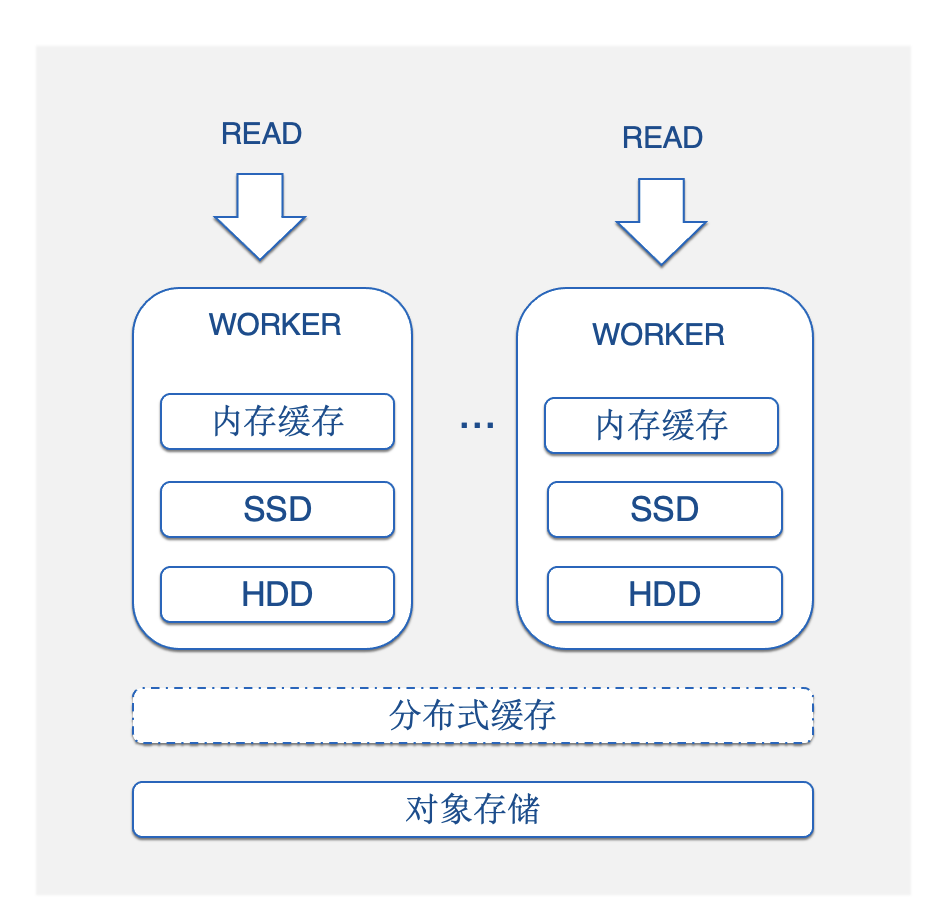
Toda la arquitectura de caché multinivel se muestra en la figura: memoria caché -> caché del disco local -> caché distribuida . De arriba a abajo, el rendimiento de la caché es de mayor a menor, y la disponibilidad y la capacidad son de menor a mayor, lo que es adecuado para diferentes tipos y niveles de datos. Esta arquitectura de caché multinivel nos ayuda a brindar a los usuarios la mejor experiencia de rendimiento de consultas al menor costo. Según las características de los datos, proporcionamos dos estrategias de almacenamiento en caché:
● Almacenamiento en caché pasivo: adecuado para datos impredecibles. Cuando los usuarios realizan consultas, los datos correspondientes se almacenan temporalmente en caché para mejorar el rendimiento de consultas posteriores.
● Almacenamiento en caché activo: adecuado para datos a los que se puede predecir que se accederá con frecuencia. Una vez iniciado el clúster, el sistema calculará activamente los datos que el usuario puede consultar hoy de acuerdo con las reglas establecidas por el usuario y el historial de consultas del usuario en segundo plano, y almacenará en caché los datos del almacenamiento de objetos en el disco local con anticipación. Cuando el usuario realiza una consulta, recuperará directamente los datos del disco local. Lectura, el rendimiento es comparable al del disco local.
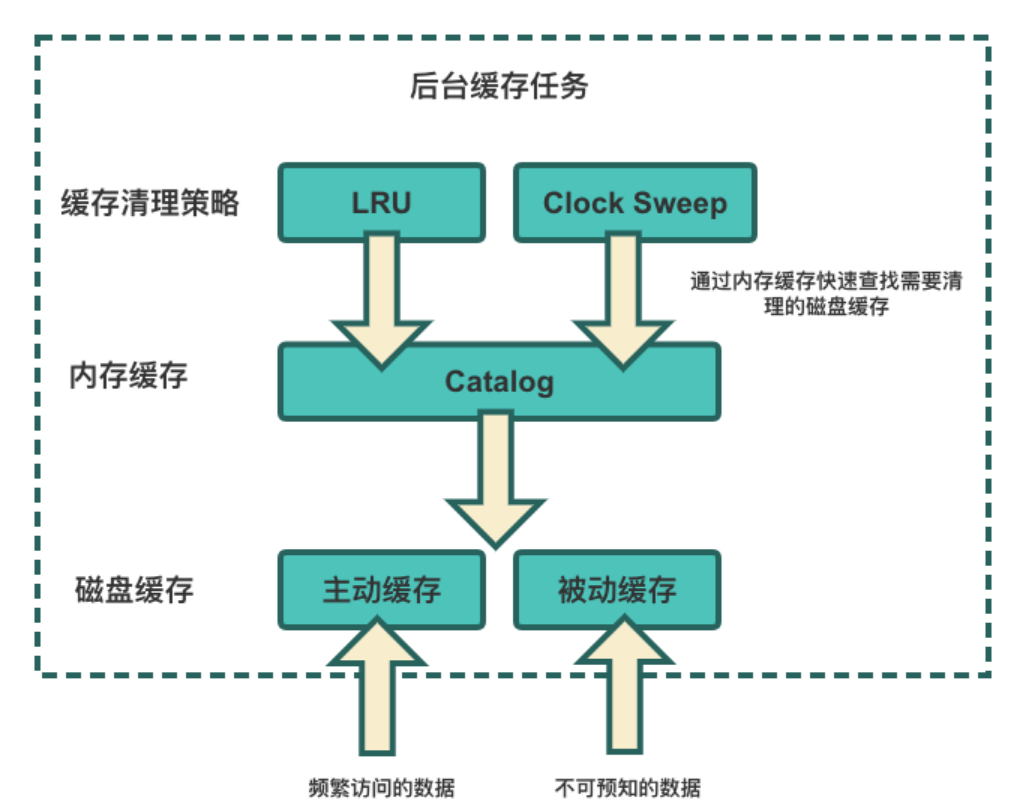
Al mismo tiempo, debido al espacio limitado en el disco local, proporcionamos dos estrategias de eliminación de caché: LRU y Clock Sweep. Para optimizar aún más la velocidad de la limpieza de la caché, creamos un catálogo de discos en la memoria para filtrar rápidamente los datos de la caché que deben eliminarse.
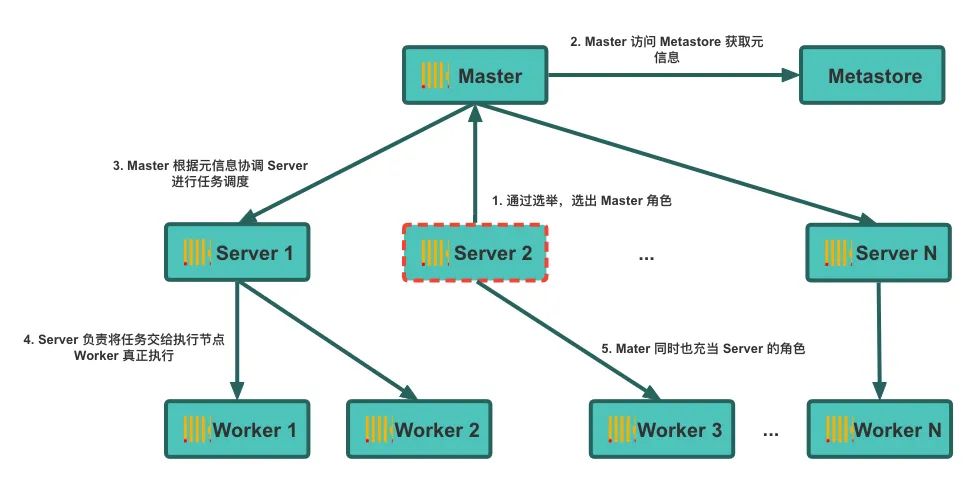
2.5 Programación de tareas distribuidas
A través del almacenamiento de objetos y estrategias de almacenamiento en caché, los nodos del clúster de REDck pueden compartir datos almacenados en los proveedores de la nube, lo que reduce la presión sobre los discos locales, pero al mismo tiempo plantea el desafío de los conflictos en la ejecución de tareas. Los tipos de tareas aquí incluyen tareas de compactación, mutación, inserción y caché. En la arquitectura original, cada instancia es independiente entre sí y no es necesario considerar conflictos en la programación de tareas. Una vez que se logra la separación del almacenamiento y la computación, es necesario planificar la programación de tareas entre diferentes nodos para lograr una programación ordenada y evitar conflictos. Esto plantea dos retos fundamentales para nosotros:
1. Cómo programar uniformemente planes de tareas globales;
2. Durante el proceso de expansión y contracción del clúster, cómo ajustar automáticamente el plan de programación para garantizar que no haya conflictos de tareas.
Para lograr una programación unificada, introdujimos la elección global de un rol de Maestro único, que designa a un servidor específico como coordinador global de tareas para toda la tabla. El coordinador asigna diferentes tareas de acuerdo con la estrategia de programación preestablecida (como la programación por segmento) para garantizar que todas las tareas se ejecuten de manera ordenada. Sin embargo, bajo condiciones anormales en el clúster, pueden ocurrir problemas como división del cerebro y duplicación de la asignación de tareas. Para resolver estos problemas, hemos agregado lógica de gestión de transacciones y detección de excepciones durante todo el proceso de ejecución de tareas para garantizar que no haya No habrá conflictos de tareas y mantenimiento. Precisión de los datos.
2.6 agrupación de datos
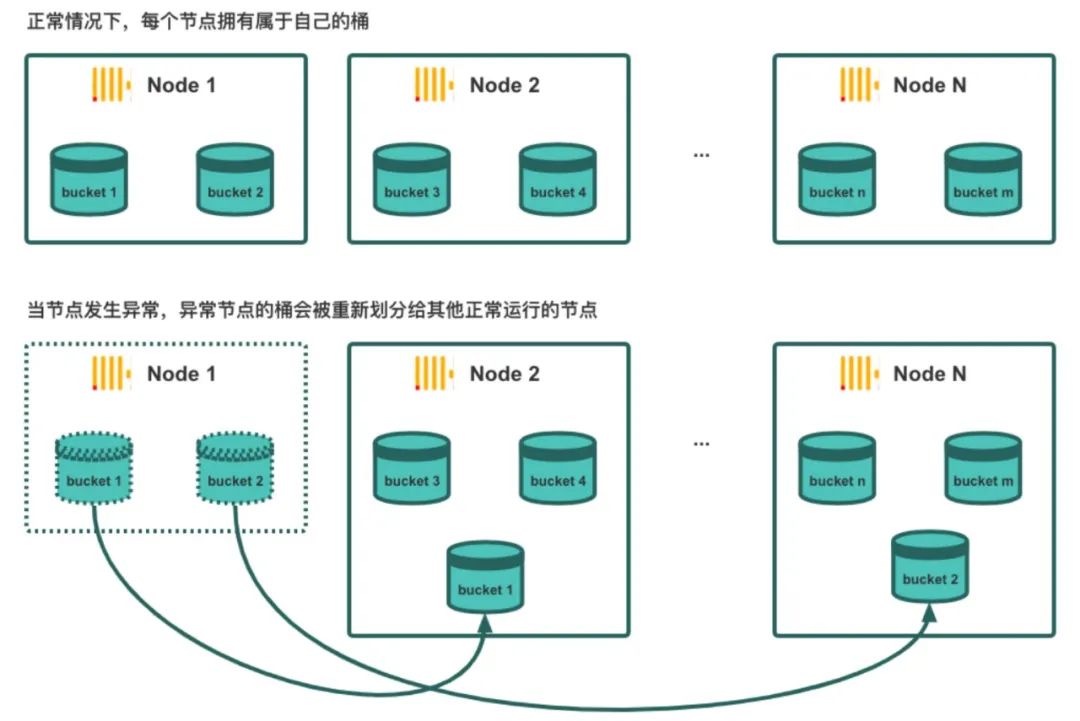
Como se mencionó anteriormente, para implementar la programación de tareas distribuidas, introducimos un rol Maestro elegido globalmente. Sin embargo, durante la ejecución de las tareas de asignación, si no existe una estrategia de programación adecuada, la distribución de datos puede estar demasiado dispersa, lo que provoca una degradación del rendimiento de la agregación y las uniones de varias tablas y, a menudo, va acompañada de problemas como el desbordamiento de la memoria de la máquina (OOM). y sesgo de cálculo. Para resolver estos problemas, introdujimos el concepto de depósito en REDck .
El depósito se refiere a aplicar hash al valor de una columna específica en una tabla o partición como una clave y convertirlo en un depósito específico. Por ejemplo, en la plataforma experimental, la ID de usuario se especifica como la clave de la división del depósito. A través del agrupamiento de datos, obtenemos los siguientes efectos de optimización:
● Durante la consulta de un solo punto, las claves de depósito se pueden utilizar para un filtrado rápido para lograr una indexación de alta velocidad, reduciendo así la cantidad de datos leídos.
● Optimice el rendimiento de las consultas de agregación y de conexión de varias tablas mediante el agrupamiento para evitar la mezcla de datos.
Al dividir los datos por Bucket, utilizamos Bucket como unidad durante el proceso de programación de tareas para programar de manera flexible la relación de mapeo entre Bucket y los nodos, lo que proporciona una base para la expansión y contracción elástica.
2.7 Transacciones distribuidas
Después de una serie de medidas de optimización, como la optimización del almacenamiento de objetos, agregar estrategias de almacenamiento en caché, agregar programación de tareas distribuidas, introducir el concepto de Bucket, etc., el uso básico de REDck se ha vuelto relativamente estable. Sin embargo, después de implementar el clúster a gran escala, descubrimos que durante el proceso de importación de datos de Hive/Spark a ClickHouse, el problema de escribir datos duplicados a menudo ocurría porque el mecanismo de transacción no era compatible. Esto se debe a que el propio ClickHouse de código abierto carece de un mecanismo de transacción maduro, lo que ha sido criticado por muchos usuarios. Aunque existe un mecanismo de transacción en ClickHouse, solo se aplica al modo independiente y no se puede aplicar al clúster distribuido que implementamos. Por lo tanto, para implementar la función Exactamente una vez de REDck, reducir las fallas y las inconsistencias de los datos durante el proceso de importación de datos y mejorar la estabilidad de los derivados del sistema, los beneficios son considerables.
Con base en el centro de metadatos de administración unificada, implementamos el mecanismo de transacciones de REDck, realizamos la administración de transacciones en la ingestión de datos y administramos de manera uniforme la visibilidad de los datos globales a través de la función Metastore, logrando así la función de envío de transacciones de dos fases. Esta mejora nos permite asegurar la coherencia y confiabilidad de la escritura de datos y evitar la generación de datos duplicados.
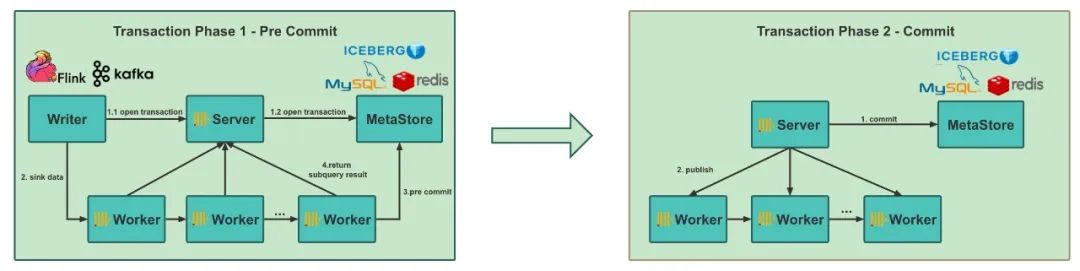
Después de implementar el envío de dos etapas de REDck, nos conectamos aún más con el mecanismo de punto de control de Flink e implementamos la semántica Exactamente una vez del enlace de datos Flink -> REDck para mejorar la precisión y confiabilidad del procesamiento de datos.
2.8 Optimización del enlace de sincronización sin conexión
En términos de ingesta de datos fuera de línea, utilizamos el método de importación fuera de línea de Spark en lugar del método de importación de lotes pequeños original de Flink, lo que reduce la complejidad del enlace de importación, mejora la eficiencia de los derivados y elimina el problema de amplificación de escritura causado por el trabajo de compactación adicional. . Al mismo tiempo, este método de importación sin conexión admite naturalmente la semántica de sobrescritura de inserción, por lo que los usuarios no leerán los datos que se importan, lo que proporciona una mejor experiencia de consulta.

Después de más de dos años de desarrollo, REDck se lanzó por completo, cubriendo más de 10 líneas de negocios en los campos de publicidad, comercio electrónico, transmisión en vivo y otros campos de la compañía, y ha logrado resultados notables:
● Reducción de costos: mediante la transformación del almacenamiento y la separación de cálculo, se ha resuelto el problema del límite limitado de recursos del clúster de plataforma experimental. Antes de la transformación, el espacio de almacenamiento del clúster era solo de nivel TB. Después de la transformación, teóricamente puede almacenar datos ilimitados. De hecho, hemos almacenado datos de nivel PB. La escala de grupo de computación más grande alcanza los 10,000 núcleos y la capacidad máxima de almacenamiento. de un solo cluster alcanza los 10.000 núcleos, diez petabytes . Además, el rango de tiempo de consulta del usuario también ha aumentado de meses a años . En comparación con el ClickHouse original, la cantidad de datos que REDck puede procesar por unidad de CPU ha aumentado 10 veces , lo que reduce significativamente el desperdicio de recursos de la CPU. Al mismo tiempo, basándonos en la arquitectura de separación de almacenamiento y computación, hemos ahorrado la presión de costos causada por el mecanismo de copia múltiple y el costo de almacenamiento unitario también se ha reducido hasta 10 veces .
● Mejora de la eficiencia: en términos de rendimiento de escritura, al utilizar Spark para transformar integralmente el enlace sin conexión, se ha duplicado el rendimiento de la importación sin conexión . En términos de rendimiento de consultas, a pesar de la introducción de servicios de metadatos distribuidos y almacenamiento de objetos de rendimiento más lento, REDck optimiza el rendimiento de consultas de una sola máquina mediante la optimización de lectura del almacenamiento de objetos , el almacenamiento en caché multinivel , el precalentamiento y otros medios técnicos, y el rendimiento de las consultas es comparable. a ClickHouse nativo. Al mismo tiempo, la separación del almacenamiento y la informática ofrece la ventaja de la expansión elástica: la expansión dinámica se puede realizar en el nivel de minutos durante los períodos de mayor actividad comercial , y los usuarios ya no tienen que preocuparse por la congestión de consultas durante los períodos de mayor actividad.
● Alta disponibilidad: abandonando el modelo de copia múltiple redundante y difícil de administrar de ClickHouse nativo, REDck se basa en el almacenamiento de objetos y utiliza una variedad de métodos de optimización para lograr una confiabilidad de datos del 99,9 % . Después de realizar la separación entre almacenamiento y computación, los datos se almacenan en la nube, el tiempo de inactividad de un solo nodo no afectará la ejecución normal de todo el clúster y el rendimiento de disponibilidad general alcanza el 99,9 % .
● Escalabilidad: las características nativas de la nube de REDck reducen significativamente la presión de operación y mantenimiento de la expansión del clúster, y el período de tiempo para la expansión del clúster se reduce del nivel semanal al nivel de minutos . Esto se debe a la eliminación del obvio cuello de botella centralizado de Zookeeper a través de servicios de metainformación unificados. El almacén virtual se puede expandir horizontalmente infinitamente para admitir la implementación de diferentes entornos comerciales. Los nodos del almacén virtual se pueden expandir verticalmente según sea necesario para Mejorar la resistencia a la presión y realizar la carga.Equilibrado . Actualmente, el almacén virtual más grande se puede ampliar a más de 100 nodos. Además, REDck utiliza un motor de tablas unificado para proteger a los usuarios de conceptos como tablas distribuidas, Zookeeper y Réplica, lo que hace que la gestión de operación y mantenimiento sea más conveniente.

Abedul blanco
Experto en I+D de OLAP en el Departamento de Plataforma de Datos de Xiaohongshu. Es responsable de la arquitectura y el trabajo de I+D en la dirección de OLAP de Xiaohongshu, que incluye principalmente la I+D y la implementación del almacén de datos en tiempo real nativo de la nube y la integración del almacén de lago. Arquitectura OLAP y experiencia práctica.
pangbo
Jefe del equipo LakeHouse del Departamento de Plataforma de Datos de Xiaohongshu, responsable de OLAP y la dirección del lago de datos.
Barba de Bronce
El departamento de I + D de OLAP de Xiaohongshu Data Platform es responsable de la investigación y el desarrollo de Xiaohongshu OLAP, incluido principalmente el desarrollo y la implementación de REDck.