antecedentes
Liulishuo dijo que la mayoría de las tareas actuales de computación fuera de línea provienen de bases de datos comerciales. La precisión, estabilidad y puntualidad del acceso a los datos de la base de datos comerciales determina la precisión y la puntualidad de todo el proceso de computación fuera de línea aguas abajo. Al mismo tiempo, todavía tenemos algunos requisitos comerciales. Necesitamos realizar consultas conjuntas casi en tiempo real de datos en DB y datos en Hive.
Antes de la introducción de Alibaba Cloud EMR Delta Lake, completamos el acceso a los datos de la base de datos empresarial encapsulando DataX. Con la arquitectura maestro-esclavo, el maestro mantiene la información de metadatos de las tareas de DataX que se ejecutarán a diario, y el nodo trabajador se adelanta continuamente Obtén las tareas de DataX con estado de inicio y restablecimiento en el método para ejecutarlas hasta que se hayan ejecutado todas las tareas de DataX del día.
El diagrama de arquitectura es aproximadamente el siguiente:

El proceso de procesamiento del trabajador es el siguiente:

Para requisitos casi en tiempo real, abrimos directamente una biblioteca esclava y configuramos el conector presto para conectarlo a la biblioteca esclava para lograr requisitos de consulta conjunta casi en tiempo real para datos en BD comerciales y datos en colmena.
Las ventajas de este esquema de arquitectura son simples y fáciles de implementar. Sin embargo, a medida que aumenta la cantidad de datos, las deficiencias se exponen gradualmente:
Cuellos de botella de rendimiento: a medida que el negocio crece, el rendimiento de esta forma de acceder a los datos a través de SELECT empeorará cada vez más, afectado por los cuellos de botella de rendimiento de la base de datos. No se puede aliviar agregando nodos de trabajo.
Las tablas a gran escala solo se pueden extraer de la biblioteca, lo que genera costos de acceso a los datos cada vez más altos.
La empresa no puede cumplir con los requisitos de consulta en tiempo casi real, y la consulta en tiempo casi real solo se puede consultar desde la base de datos, lo que aumenta aún más el costo de acceso.
Para resolver estos problemas, centramos nuestra atención en la solución de acceso en tiempo real de los CDC.
Selección de esquema técnico
Para las soluciones de acceso en tiempo real de CDC, existen principalmente las siguientes en la industria: solución CDC + Merge, CDC + Hudi, CDC + Delta Lake y CDC + Iceberg. Entre ellos, la solución CDC + Merge se implementó antes de que apareciera la solución del lago de datos. Esta solución puede ahorrar el costo de la base de datos de base de datos, pero no puede satisfacer las necesidades de las consultas comerciales en tiempo real y otras funciones, por lo que el pase se descartó al principio. Al comienzo de nuestra selección, Iceberg no estaba lo suficientemente maduro, y no había ningún caso de referencia en la industria, por lo que también fue aprobado, al final, elegimos entre CDC + Hudi y CDC + Delta Lake.
Al seleccionar modelos, las funciones de Hudi y Delta Lake son similares, por lo que consideramos principalmente estas soluciones: estabilidad, fusión de archivos pequeños, soporte SQL, soporte para proveedores en la nube, soporte para idiomas Espere varias consideraciones.

En base a los indicadores anteriores y toda nuestra plataforma de datos se basa en Alibaba Cloud EMR, elegir Delta Lake ahorrará mucho trabajo de desarrollo de adaptación, por lo que finalmente elegimos la solución CDC + Delta Lake.
Estructura general
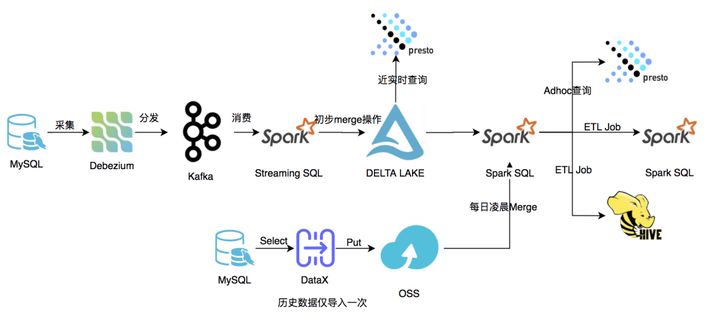
Diagrama de arquitectura general
La arquitectura general se muestra en la figura anterior. Los datos a los que accedemos se dividirán en dos partes, los datos históricos de acciones y los nuevos datos. Los datos históricos de acciones se exportan desde MySQL usando DataX y se almacenan en OSS, y los nuevos datos se recopilan y almacenan en la tabla Delta Lake usando Binlog. Antes de ejecutar las tareas ETL en las primeras horas de la mañana de cada día, realice operaciones de combinación en datos históricos y datos nuevos. Las tareas de ETL utilizan los datos después de la combinación.
Acceso a datos de Delta Lake
En términos de recopilación en tiempo real de Binlog, utilizamos el código abierto Debezium, que es responsable de extraer Binlog de MySQL en tiempo real y completar el análisis adecuado. Cada tabla corresponde a un tema, y las sub-bases de datos y sub-tablas se fusionan en un tema y se distribuyen a Kafka para su consumo inicial. Una vez que los datos de Binlog están conectados a Kafka, necesitamos crear una tabla de origen de Kafka para apuntar al tema de Kafka correspondiente. El formato de la tabla es:
CREATE TABLE kafka_{db_name}_{table_name} (key BINARY, value BINARY, topic STRING, partition INT, offset BIGINT, timestamp TIMESTAMP, timestampType INT)
USING kafka
OPTIONS (
kafka.sasl.mechanism 'PLAIN',
subscribe 'cdc-{db_name}-{table_name}',
serialization.format '1',
kafka.sasl.jaas.config '*****(redacted)',
kafka.bootstrap.servers '{bootstrap-servers}',
kafka.security.protocol 'SASL_PLAINTEXT'
)Los campos principales que utilizamos son valor y compensación. El formato de valor es el siguiente:
{
"payload": {
"before": {
db记录变更前的schema及内容,op=c时,为null
},
"after": {
db记录变更后的schema及内容,op=d时,为null
},
"source": {
ebezium配置信息
},
"op": "c",
"ts_ms":
}
}Al mismo tiempo, cree una tabla de Delta Lake, la ubicación apunta a HDFS u OSS, la estructura de la tabla es:
CREATE TABLE IF NOT EXISTS delta.delta_{dbname}{table_name}(
{row_key_info},
ts_ms bigint,
json_record string,
operation_type string,
offset bigint
)
USING delta
LOCATION '------/delta/{db_name}.db/{table_name}'Entre ellos, row_key_info es el campo de índice único de la tabla Delta Lake. Para una sola base de datos y una sola tabla, row_key_info es el campo de clave principal de la tabla mysql, por ejemplo: id long. Para la subtabla de la base de datos y la subbase de datos de instancia, row_key_info es la subtabla El campo de la subtabla de la base de datos está compuesto por el campo de clave principal en la tabla única, por ejemplo: user_id es el campo de la subtabla, e id es la clave principal en cada tabla, luego la correspondiente row_key_info es id long y user_id long.
StreamingSQL procesa los datos en Kafka. Principalmente extraemos el desplazamiento, los campos de valor y la información de CDC en el campo de valor en la tabla de origen de Kafka, como op, ts_ms y los campos after y before de la carga útil.
En StreamingSQL, usamos un mini lote de 5 minutos. La razón principal es que si el mini lote es demasiado pequeño, se generarán muchos archivos pequeños y la velocidad de procesamiento será cada vez más lenta, lo que también afectará el rendimiento de lectura. Si es demasiado grande, no puede cumplir con la consulta en tiempo real. Reclamación. Para la tabla de Delta Lake, no analizamos los campos antes o después. La razón principal es que el esquema de nuestra tabla de negocios cambia con frecuencia. Cuando el esquema de la tabla de negocios cambia, los datos deben repararse, lo cual es relativamente costoso.
Durante el procesamiento de StreamingSQL, insertaremos directamente los datos con op = 'c', y json_record toma el campo after. Para datos con op = 'u' u op = 'd', si los datos no existen en la tabla de Delta Lake, entonces realice la operación de inserción, si existe, luego realice la operación de actualización; el valor de asignación de json_record, op = 'd', json_record toma antes Field, op = 'u', jsonrecord toma el campo posterior. Mantenga el campo op = 'd', principalmente considerando que los datos eliminados pueden estar en la tabla del historial del inventario. Si se eliminan directamente, los datos de la combinación de datos de la madrugada no se eliminarán.
El procesamiento de todo el StreamingSQL es aproximadamente el siguiente:
CREATE SCAN incremental{dbname}{tablename} on kafka{dbname}{table_name} USING STREAM
OPTIONS(
startingOffsets='earliest',
maxOffsetsPerTrigger='1000000',
failOnDataLoss=false
);
CREATE STREAM job
OPTIONS(
checkpointLocation='------/delta/{db_name}.db/{table_name}checkpoint',
triggerIntervalMs='300000'
)
MERGE INTO delta.delta{dbname}{table_name} as target
USING (
SELECT * FROM (
SELECT ts_ms, offset, operation_type, {key_column_sql}, coalesce(after_record, before_record) as after_record, row_number() OVER (PARTITION BY {key_column_partition_sql} ORDER BY ts_ms DESC, offset DESC) as rank
FROM (
SELECT ts_ms, offset, operation_type, before_record, after_record, {key_column_include_sql}
FROM ( SELECT get_json_object(string(value), '$.payload.op') as operation_type, get_json_object(string(value), '$.payload.before') as before_record,
get_json_object(string(value), '$.payload.after') as after_record, get_json_object(string(value), '$.payload.ts_ms') as tsms,
offset
FROM incremental{dbname}{table_name}
) binlog
) binlog_wo_init ) binlog_rank where rank = 1) as source
ON {key_column_condition_sql}
WHEN MATCHED AND (source.operation_type = 'u' or source.operation_type='d') THEN
UPDATE SET {set_key_column_sql}, ts_ms=source.ts_ms, json_record=source.after_record, operation_type=source.operation_type, offset=source.offset
WHEN NOT MATCHED AND (source.operation_type='c' or source.operation_type='u' or source.operation_type='d') THEN
INSERT ({inser_key_column_sql}, ts_ms, json_record, operation_type, offset) values ({insert_key_column_value_sql}, source.ts_ms, source.after_record, source.operation_type, source.offset);Después de ejecutar StreamingSQL, se generarán datos en el siguiente formato:
Part-xxxx.snappy.parquet guarda los archivos de datos de la tabla DeltaLake, y el directorio _deltalog guarda los metadatos de la tabla DeltaLake, incluidos los siguientes:
Donde xxxxxxxx representa la información de la versión, y la información del archivo de parquet válido se guarda en el archivo xxxxxxxx.json, donde el tipo de adición es un archivo de parquet válido y la eliminación es un archivo de parquet no válido.
Delta Lake admite viajes en el tiempo, pero si accedemos a los datos de los CDC, no necesitamos una estrategia de reversión de datos. Si se guardan varias versiones de los datos, esto tendrá un cierto impacto en nuestro almacenamiento, por lo que debemos eliminar las versiones obsoletas con regularidad. Actualmente, los datos solo conservan los datos de la versión en 2 horas. Al mismo tiempo, Delta Lake no admite la función de fusionar automáticamente archivos pequeños, por lo que también necesitamos fusionar archivos pequeños con regularidad. Nuestra práctica actual es utilizar OPTIMIZE y VACCUM para fusionar archivos pequeños y limpiar archivos de datos caducados cada hora:
optimize delta{dbname}{tablename};
set spark.databricks.delta.retentionDurationCheck.enabled = false;
VACUUM delta{dbname}{table_name} RETAIN 1 HOURS;Dado que Hive y Presto no pueden leer directamente la tabla Delta Lake creada por Spark SQL, pero para el monitoreo y los requisitos de consulta casi en tiempo real, la tabla Delta Lake debe consultarse, por lo que también hemos creado una consulta para las tablas Hive y Presto.
Los datos de Delta Lake y los datos de inventario se fusionan
Dado que solo accedemos a nuevos datos para los datos de Delta Lake, importamos los datos históricos de existencias a la vez a través de DataX, y la tabla de Delta Lake Hive no se puede consultar directamente, por lo que debemos fusionar las dos partes de los datos cada mañana. , Escrito en la nueva tabla para el uso unificado de Spark SQL y Hive. La arquitectura de este módulo es aproximadamente la siguiente:
Imagen
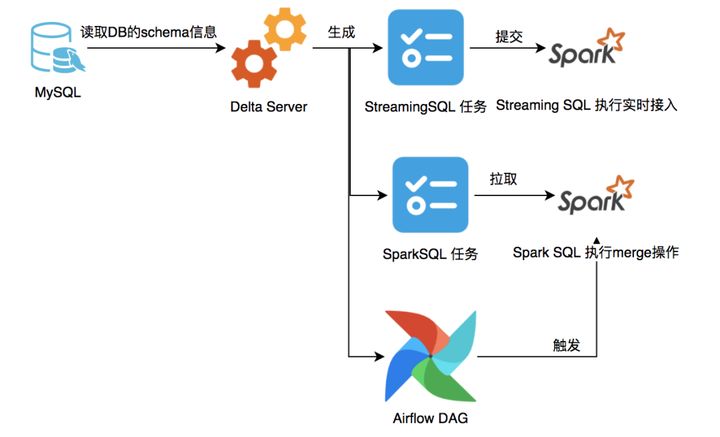
Antes de las 0 am todos los días, llame a la API de DeltaService y genere automáticamente la información de la tarea, el script spark-sql y el archivo DAG de flujo de aire correspondiente de la tarea de combinación de acuerdo con la configuración de la tarea de Delta Lake.
La información de la tarea de combinación incluye principalmente la siguiente información:
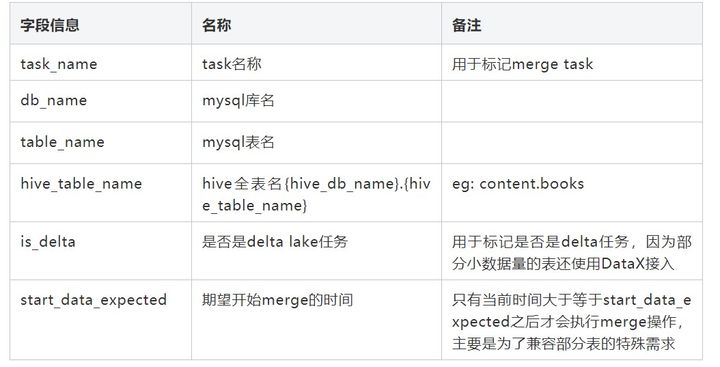
El script Merge se genera automáticamente, principalmente para obtener la información del esquema de la tabla mysql a partir de la configuración de la tarea de Delta Lake, eliminar la tabla histórica de Hive y luego recrear la tabla externa de Hive basada en la información del esquema, y luego usar el nuevo esquema del campo json_record de la tabla de Delta Lake Obtenga el valor de campo correspondiente de la tabla de datos de existencias históricas y realice la operación de unión total. El valor que falta adopta el valor predeterminado de mysql. Después de la unión, se agrupa de acuerdo con row_key, y el primero se ordena por ts_ms, y los datos con operation_type = 'd' se eliminan al mismo tiempo . El conjunto es el siguiente:
CREATE DATABASE IF NOT EXISTS {db_name} LOCATION '------/delta/{db_name}.db';
DROP TABLE IF EXISTS {db_name}.{table_name};
CREATE TABLE IF NOT EXISTS {db_name}.{table_name}(
{table_column_infos}
)
STORED AS PARQUET
LOCATION '------/delta/{db_name}.db/{table_name}/data_date=${
{data_date}}';
INSERT OVERWRITE TABLE {db_name}.{table_name}
SELECT {table_columns}
FROM ( SELECT {table_columns}, _operation_type, row_number() OVER (PARTITION BY {row_keys} ORDER BY ts_ms DESC) as ranknum
FROM (
SELECT {delta_columns}, operation_type as _operation_type, tsms
FROM delta{dbname}{table_name}
UNION ALL
SELECT {hive_columns}, 'c' as _operation_type, 0 as ts_ms
FROM {db_name}.{table_name}_delta_history
) union_rank
) ranked_data
WHERE ranknum=1
AND _operation_type <> 'd'Después de las 0 a. M., Airflow programará y ejecutará automáticamente el script Spark SQL de la fusión de acuerdo con el archivo DAG de Airflow. Una vez que el script se haya ejecutado correctamente, el estado de la tarea de fusión se actualizará a correcto y el ETL DAG de Airflow programará automáticamente las tareas ETL posteriores de acuerdo con el estado de la tarea de fusión.
Monitoreo de datos de Delta Lake
Para el monitoreo de los datos de Delta Lake, tenemos principalmente dos propósitos: monitorear si los datos están retrasados y si los datos de monitoreo se pierden, principalmente entre las tablas de MySQL y Delta Lake y entre las tablas de Kafka Topic y Delta Lake a las que acceden los CDC.
Supervisión de latencia entre las tablas de Kafka Topic y Delta Lake a las que accede CDC: obtenemos el contenido del campo row_key de MySQL correspondiente al desplazamiento máximo de cada partición de Kafka Topic cada 15 minutos, y los colocamos en la tabla MySQL supervisada delta_kafka_monitor_info , Y luego obtenga el contenido del campo row_key del ciclo anterior de delta_kafka_monitor_info, y consúltelo en la tabla Delta Lake. Si no se puede consultar, significa que los datos están retrasados o perdidos, y se emite una alarma.
Monitoreo entre MySQL y Delta Lake: Tenemos dos tipos. Uno es la solución de la sonda. Cada 15 minutos, la identificación más grande se obtiene de MySQL. Para las sub-bases de datos y sub-tablas, solo una tabla es monitoreada y almacenada en delta_mysql_monitor_info , Y luego obtener el ID máximo del período anterior de delta_mysql_monitor_info, y consultarlo en la tabla de Delta Lake. Si la consulta falla, indica que los datos están retrasados o perdidos, y se emite una alarma. El otro es el recuento directo (id). Este esquema se divide en una sola base de datos y una sola tabla y subtabla de subbase de datos. Los metadatos se almacenan en la tabla mysql id_based_mysql_delta_monitor_info, que contiene principalmente tres campos: min_id, max_id y mysql_count. La tabla de la lista de bibliotecas también obtiene el valor de recuento entre min_id y max_id de la tabla de Delta Lake cada 5 minutos y lo compara con mysql_count. Si es menor que el valor de mysql_count, indica que hay pérdida de datos o retraso, y se emite una alarma. A continuación, obtenga el valor de recuento entre max (id) y max_id y max (id) de mysql, y actualícelo a la tabla id_based_mysql_delta_monitor_info. Para el caso de sub-base de datos y tabla, de acuerdo con las reglas de sub-base de datos y tabla, se genera la información id_based_mysql_delta_monitor_info correspondiente a cada tabla, y el monitoreo se realiza cada media hora, y las reglas son las mismas que las de base de datos única y tabla única.
Desafíos encontrados
El esquema de la tabla de negocios cambia con frecuencia. Si la tabla de Delta Lake analiza directamente la información de campo del CDC, si los datos no se pueden encontrar y reparar a tiempo, el costo de reparar los datos en el período posterior será mayor. Actualmente, no analizamos los campos y esperamos hasta la fusión de la madrugada. .
A medida que aumenta la cantidad de datos, el rendimiento de las tareas de StreamingSQL empeorará. Actualmente estamos procesando demoras en StreamingSQL. Después de que ocurra una gran cantidad de alarmas de demora, los datos de inventario de Delta Lake se reemplazan con los datos posteriores a la fusión de ayer, y luego se elimina la tabla de Delta Lake, se eliminan los datos del punto de control y los datos de la tabla de KafkaSource se consumen desde el principio. Reduzca los datos de la tabla de Delta Lake, aliviando así la presión de StreamingSQL.
Hive y Presto no pueden consultar directamente la tabla Delta Lake creada por Spark SQL. En la actualidad, estamos creando tablas externas que admiten consultas de Hive y Presto para que las utilicen Hive y Presto, pero estas tablas no se pueden consultar a través de Spark SQL. Por lo tanto, la aplicación ETL de nivel superior no puede cambiar libremente entre los motores Hive y Spark SQL y Presto sin cambiar el código.
Beneficios
Ahorró el costo de la biblioteca esclava DB, después de adoptar CDC + Delta Lake, nuestro costo ahorró casi el 80%.
El costo de tiempo del acceso a los datos de la base de datos temprano en la mañana se reduce en gran medida, lo que puede garantizar que todo el acceso a los datos de la base de datos que no sea especialmente necesario se pueda completar en una hora.
Planificación de seguimiento
A medida que aumenta la cantidad de datos en la tabla de Delta Lake y empeora el rendimiento de la tarea StreamingSQL, realice un seguimiento.
Si la promoción puede resolver el problema de que la tabla Delta Lake creada por Spark SQL no se puede consultar directamente con Hive y Presto.
Este artículo es el contenido original de Alibaba Cloud y no se puede reproducir sin permiso.