1 Marco de red neuronal
1.1 Uso de la clase Módulo
NN (red neuronal): Red neuronal
Contenedores: Convolución de contenedores
Capas: Capa convolucional
Capas de agrupación: Capa de agrupación Capas de relleno
: Capa de relleno
Activaciones no lineales (suma ponderada, no linealidad): Activación no lineal
Activaciones no lineales (otras): No lineales Activación
Capas de normalización: Capa de normalización
Capas recurrentes: Capa recursiva
Capas de transformador: Capa de transformación
Capas lineales: Capa lineal
Capas de abandono: Capa de abandono
Funciones de pérdida: Función de pérdida
...
Los contenedores incluyen:
(1) Module: la clase base para todas las redes neuronales
https://pytorch.org/docs/stable/generated/torch.nn.Module.html#torch.nn.Module
Clase torch.nn.Module(*args, **kwargs)
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
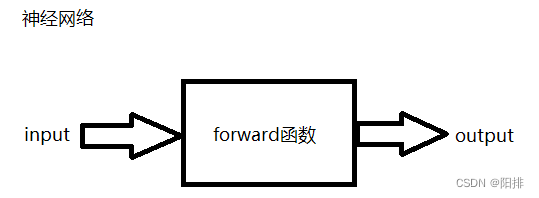
def forward(self, inputX):
x = F.relu(self.conv1(inputX))
return F.relu(self.conv2(inputX))
En la función directa: relu() es la función de activación y conv es la función de convolución. Ingrese inputX-> convolución-> procesamiento no lineal (relu)-> convolución-> no lineal (relu).
código pitón:
from torch import nn
import torch
class MyNN(nn.Module):
def __init__(self):
super().__init__()
def forward(self, inputX):
outputX = inputX + 1
return outputX
mynn = MyNN()
x = torch.tensor(1.0)
output = mynn(x)
print(output)
Resultado de salida:
tensor(2.)
2 Capas de convolución Capas de convolución
2.1 Cálculo de convolución bidimensional
Tanto los tipos de matriz de entrada como de salida de la convolución bidimensional conv2d() necesitan(N, C_{in}, H_{in}, W_{in})
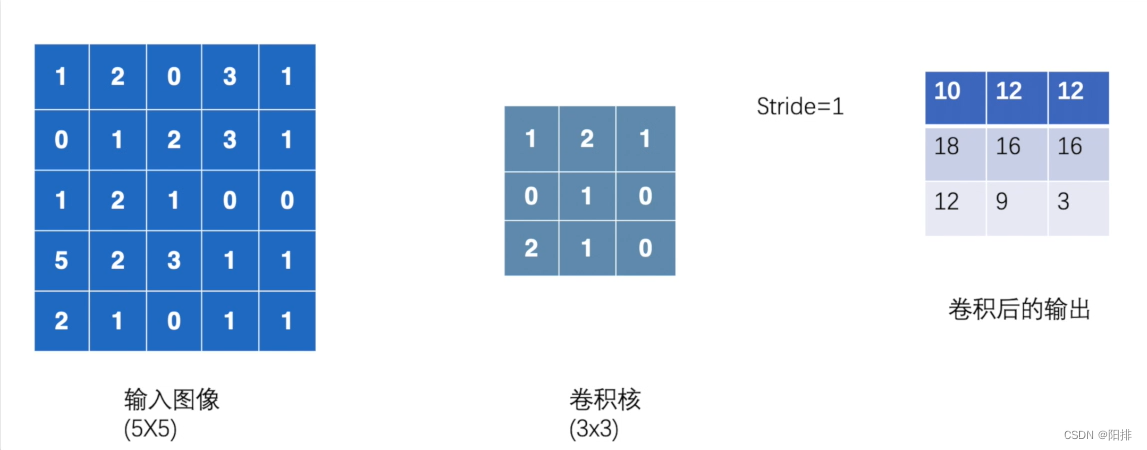
La imagen de entrada es 1024x800, el núcleo de convolución es 3x3, cada vez que se multiplican y suman 9 elementos, y el cálculo se mueve continuamente hacia la derecha, después de moverse hacia el extremo derecho; luego se mueve hacia abajo y calcula, después de moverse hacia abajo, el volumen se completa el cálculo del producto.
import torch
import torch.nn.functional as F
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
print("input:")
print(input)
print("kernel:")
print(kernel)
output = F.conv2d(input, kernel, stride=1)
print("output:")
print(output)
Resultado de salida:
input:
tensor([[[[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]]]])
kernel:
tensor([[[[1, 2, 1],
[0, 1, 0],
[2, 1, 0]]]])
output:
tensor([[[[10, 12, 12],
[18, 16, 16],
[13, 9, 3]]]])
Si el paso de zancada se modifica a 2.
output2 = F.conv2d(input, kernel, stride=2)
print("output2:")
print(output2)
La salida es:
output2:
tensor([[[[10, 12],
[13, 3]]]])
El relleno llena la imagen original con un círculo de 0, por lo que la dimensión del resultado del cálculo de la convolución será mayor.
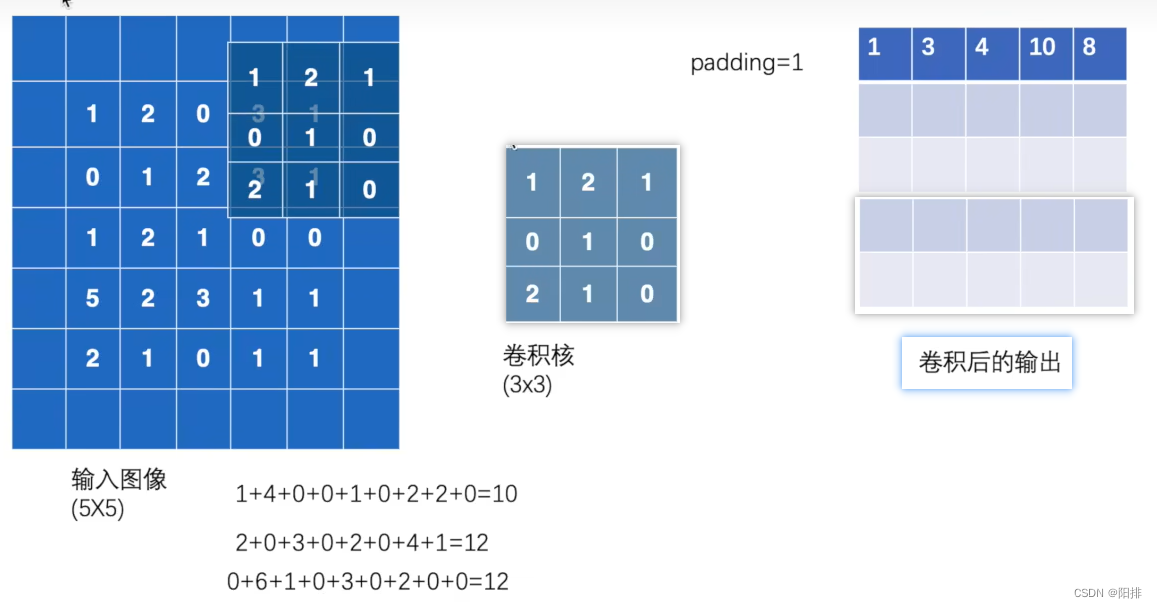
output3 = F.conv2d(input, kernel, stride=1, padding=1)
print("output3:")
print(output3)
Resultado de salida:
tensor([[[[ 1, 3, 4, 10, 8],
[ 5, 10, 12, 12, 6],
[ 7, 18, 16, 16, 8],
[11, 13, 9, 3, 4],
[14, 13, 9, 7, 4]]]])
2.2 Operación de convolución de imagen
Enlace de aprendizaje:
https://pytorch.org/docs/stable/generated/torch.nn.Conv2d.html#torch.nn.Conv2d
CLASS torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilatation=1, groups=1, bias=True, padding_mode='ceros', device=Ninguno, dtype=Ninguno)
- in_channels (int) – número de canales de imagen de entrada
- out_channels (int) – número de canales de imagen de salida
- kernel_size (int o tuple) – tamaño del kernel de convolución
- zancada (int o tupla, opcional) – zancada de convolución (predeterminado 1).
- relleno (int, tupla o str, opcional): la longitud de los lados para agregar a la imagen de entrada (predeterminado 1)
- padding_mode (str, opcional): el tipo de longitud lateral: 'ceros', 'reflejar', 'replicar' o 'circular'. Predeterminado: 'ceros'
- dilatación (int o tupla, opcional): espaciado entre núcleos de convolución (predeterminado 1), convolución dilatada.
*grupos (int, opcional): número de conexiones de bloqueo de los canales de entrada a los canales de salida (predeterminado 1). - sesgo (bool, opcional): si es Verdadero, agregue un sesgo aprendible a la salida (valor predeterminado Verdadero).
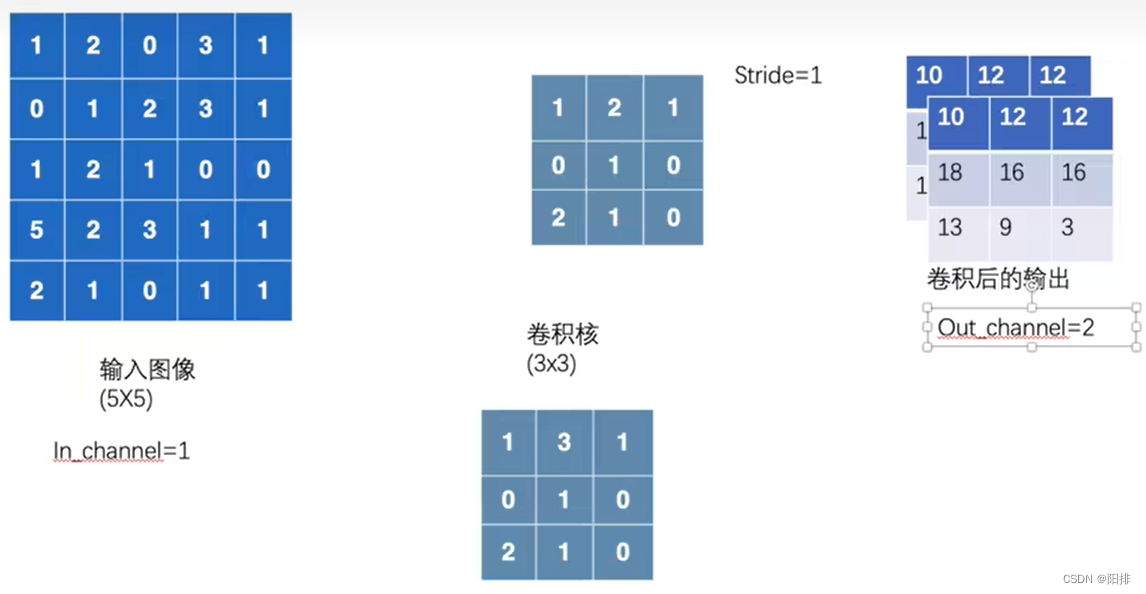
Si in_channel=1, out_channel=2, se utilizarán dos núcleos de convolución para calcular la imagen de entrada y generar los datos de dos canales:
Fórmula de convolución:
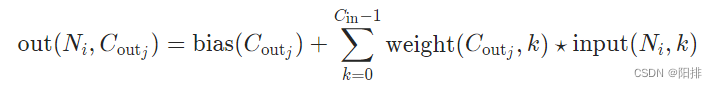
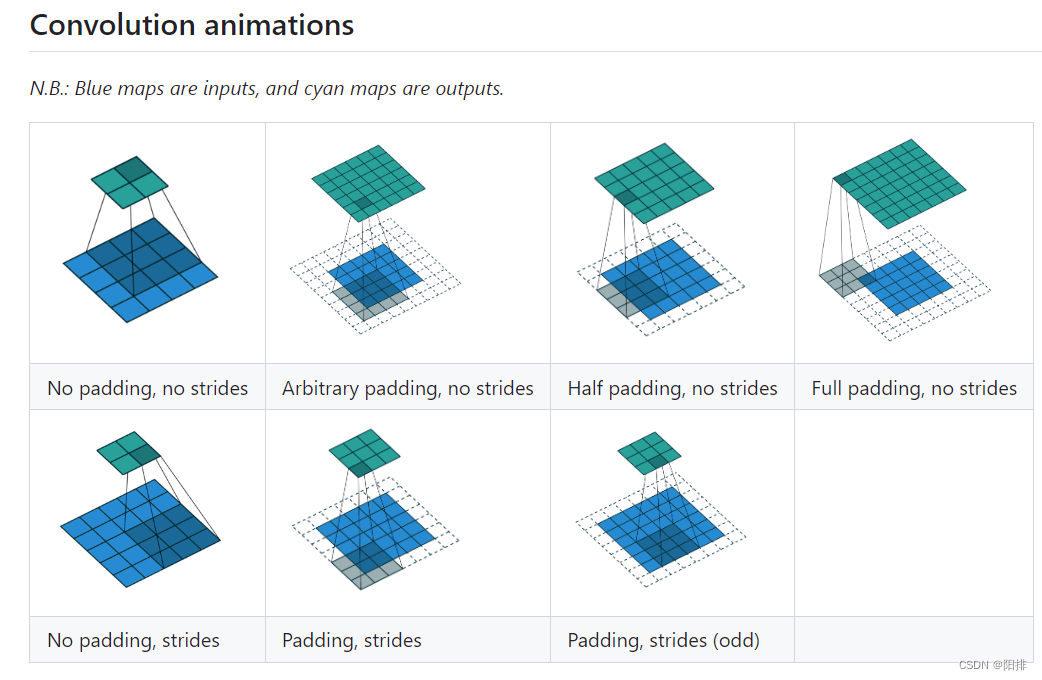
Animación de convolución bidimensional:
https://github.com/vdumoulin/conv_arithmetic/blob/master/README.md
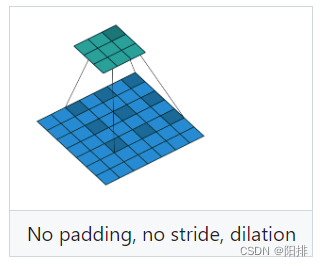
Cuando dilatación=2, el método de convolución:
Código de Python de convolución bidimensional de la imagen:
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(root="G:\\Anaconda\\pycharm_pytorch\\learning_project\\dataset_CIFAR10",
train=False,
transform=torchvision.transforms.ToTensor(),
download=False)
dataloader = DataLoader(dataset, batch_size=64)
class MyNN(nn.Module):
def __init__(self):
super(MyNN, self).__init__()
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
myNN = MyNN()
print(myNN)
writer = SummaryWriter("G:/Anaconda/pycharm_pytorch/learning_project/logs")
step = 0
for data in dataloader:
imgs, targets = data
output = myNN(imgs)
print(imgs.shape) # torch.Size([64, 3, 32, 32])
print(output.shape) # torch.Size([64, 6, 30, 30])
writer.add_images("input", imgs, step)
# torch.Size([64, 6, 30, 30]) -> # torch.Size([xxx, 3, 30, 30])
output = torch.reshape(output, (-1, 3, 30, 30))
writer.add_images("output", output, step)
step = step + 1
writer.close()
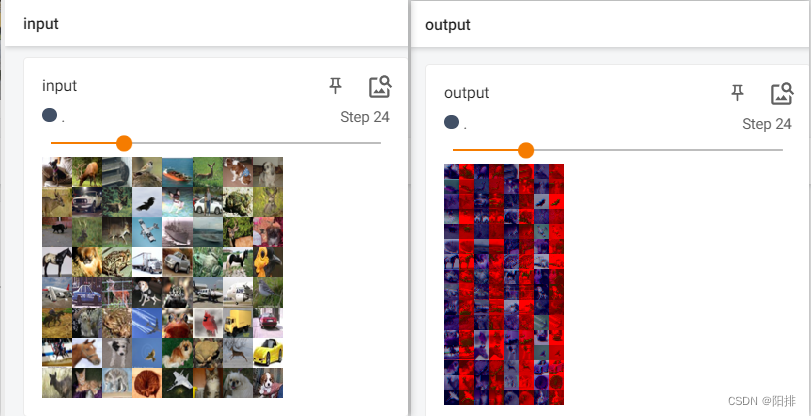
Después de que se ejecute el código, ingrese en la terminal tensorboard --logdir=logspara abrir tensorboard.
Se puede ver que la imagen de salida es parte del canal después de la convolución.
3 Capas de agrupación Capas de agrupación
Enlace de aprendizaje:
https://pytorch.org/docs/stable/nn.html#pooling-layers
El papel de la capa de agrupación: (1) reducción de muestreo (reducción de muestreo), reducción de la dimensión de los datos, reducción del tamaño de la memoria consumida por la operación de reenvío de la red; (2) mantenimiento de las características de entrada, expansión del campo de percepción del modelo de red; (3) ) evitar el sobreajuste o el ajuste insuficiente.
3.1 Agrupación máxima MaxPool2d
Aplica agrupación máxima 2D en una señal de entrada que consta de varios planos de entrada.
CLASE torch.nn.MaxPool2d(kernel_size, stride=Ninguno, padding=0, dilatación=1, return_indices=False, ceil_mode=False)
- kernel_size (Union[int, Tuple[int, int]]): el tamaño máximo de la ventana de agrupación.
- stride (Union[int, Tuple[int, int]]) – zancada de la ventana de agrupación (el valor predeterminado es kernel_size ).
- padding (Union[int, Tuple[int, int]]): agrega implícitamente un relleno infinito negativo en ambos lados.
- dilatación (Union[int, Tuple[int, int]]): un parámetro que controla el tamaño de paso de los elementos en la ventana.
- return_indices (bool): si es verdadero, devolverá índices máximos junto con la salida. Útil después de torch.nn.MaxUnpool2d.
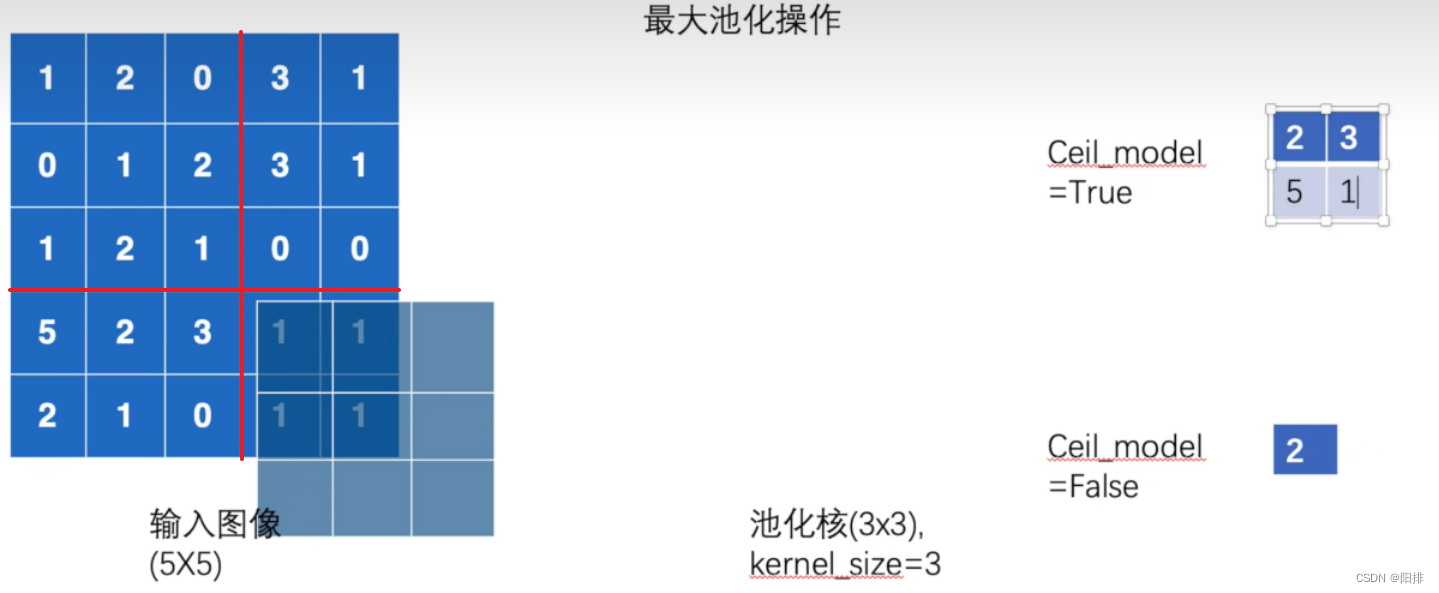
- ceil_mode (bool): cuando es verdadero, usará ceil en lugar de floor para calcular la forma de salida.
Ceil significa modo de techo (techo), piso significa modo de piso (piso). Si es Ceil, significa redondear hacia arriba cuando se redondea un número entero; si piso significa redondear hacia abajo cuando se redondea un número entero.

En la convolución bidimensional, cuando se dan las siguientes condiciones, cuando ceil_mode es True, es necesario conservar la convolución de los 6 números restantes; si ceil_mode es False, no es necesario conservar la convolución.
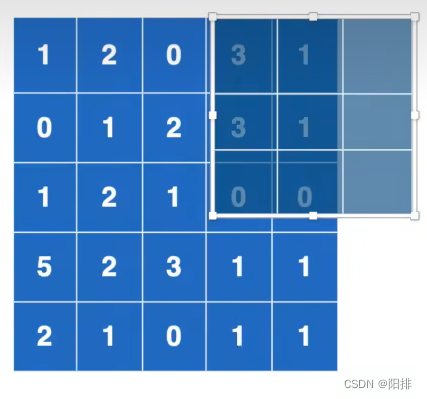
La operación de agrupación es diferente de la operación de convolución. La compensación de la agrupación es el tamaño del kernel de agrupación. El resultado de salida de la operación de agrupación se muestra en el lado derecho de la figura a continuación. Los resultados obtenidos por True y False de ceil_mode son diferente en tamaño.
Código Python de agrupación máxima:
import torch
from torch import nn
from torch.nn import MaxPool2d
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]], dtype=torch.float32)
input = torch.reshape(input, (-1, 1, 5, 5))
print(input)
class MYNN(nn.Module):
def __init__(self):
super(MYNN,self).__init__()
self.maxpool1 = MaxPool2d(kernel_size=3,ceil_mode=True)
self.maxpool2 = MaxPool2d(kernel_size=3, ceil_mode=False)
def forward(self, input):
output1 = self.maxpool1(input)
output2 = self.maxpool2(input)
return output1, output2
mynn = MYNN()
output1, output2 = mynn(input)
print(output1)
print(output2)
Ejecute el script para obtener el resultado:
tensor([[[[1., 2., 0., 3., 1.],
[0., 1., 2., 3., 1.],
[1., 2., 1., 0., 0.],
[5., 2., 3., 1., 1.],
[2., 1., 0., 1., 1.]]]])
tensor([[[[2., 3.],
[5., 1.]]]])
tensor([[[[2.]]]])
3.2 Operación de agrupación de imágenes
código pitón:
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(root="G:\\Anaconda\\pycharm_pytorch\\learning_project\\dataset_CIFAR10",
train=False,
transform=torchvision.transforms.ToTensor(),
download=False)
dataloader = DataLoader(dataset, batch_size=64)
class MYNN(nn.Module):
def __init__(self):
super(MYNN,self).__init__()
self.maxpool = MaxPool2d(kernel_size=3, ceil_mode=False)
def forward(self, input):
output = self.maxpool(input)
return output
mynn = MYNN()
writer = SummaryWriter("G:/Anaconda/pycharm_pytorch/learning_project/logs_maxpool")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, step)
# torch.Size([64, 6, 30, 30]) -> # torch.Size([xxx, 3, 30, 30])
output = mynn(imgs)
writer.add_images("output", output, step)
step = step + 1
writer.close()
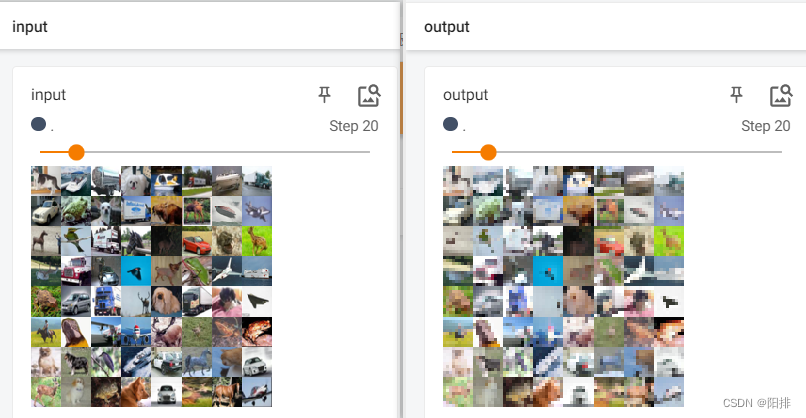
Después de que se ejecute el código, ingrese en la terminal tensorboard --logdir=logs_maxpoolpara abrir tensorboard. Puede verse que la imagen de salida se reduce en resolución después de la operación de agrupación.
4 capas de relleno
Enlace de aprendizaje:
https://pytorch.org/docs/stable/nn.html#padding-layers
Principales funciones utilizadas:
| Nombre de la función | ilustrar |
|---|---|
| nn.ZeroPad2d | Rellena los límites del tensor de entrada con ceros. |
| nn.ConstantPad2d | Rellena los límites del tensor de entrada con constantes. |
También se puede implementar en otras capas, por lo que se puede omitir esta capa.
5 Activación no lineal Activaciones no lineales (suma ponderada, no linealidad)
Introducir características no lineales a la red neuronal.
| Nombre de la función | ilustrar |
|---|---|
| nn.ReLU | Aplica la función de unidad lineal modificada por elementos. |
| nn.Sigmoide | Aplica una función por elementos. |
5.1 Función de activación
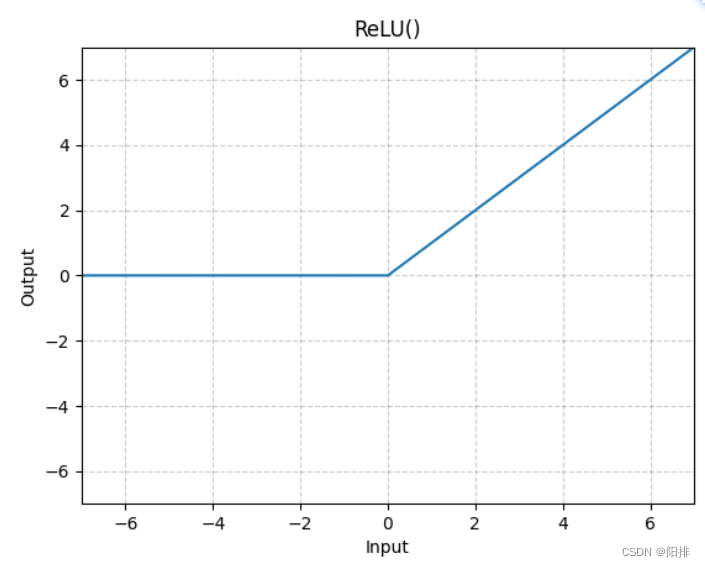
5.1.1 ReLU
Aplique la función de unidad lineal modificada por elementos:
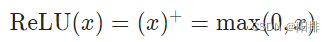
CLASE antorcha.nn.ReLU(inplace=False)
parámetro:
- inplace (bool): si se realizan opcionalmente operaciones en el lugar (por defecto, Falso).
Forma: - Entrada: (∗), donde ∗ se refiere a cualquier número de dimensiones.
- Salida: (∗), misma forma que la entrada.
5.1.2 Sigmod
Aplicar función de elemento:
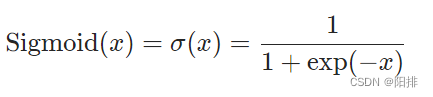
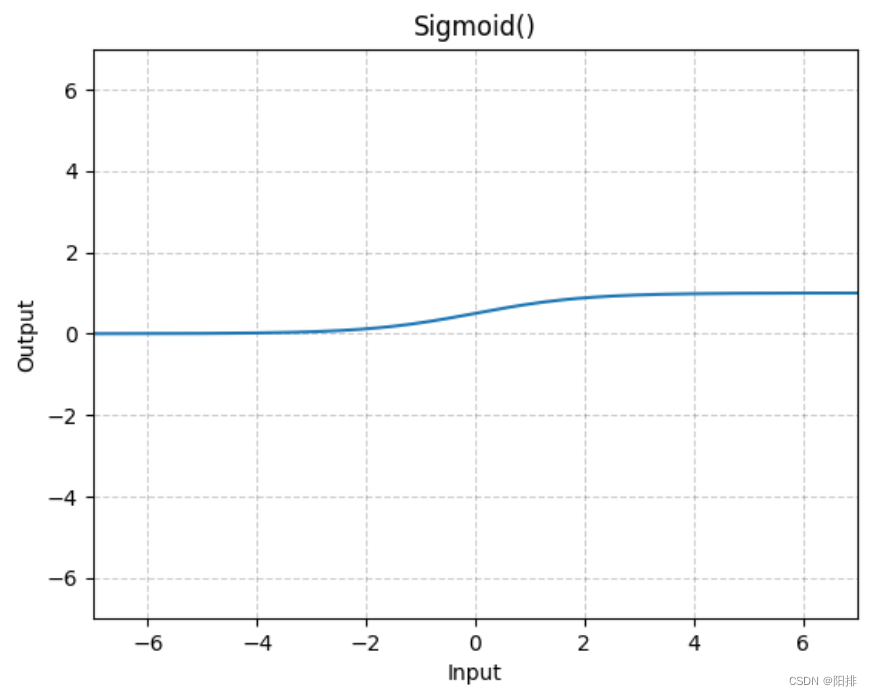
CLASE antorcha.nn.Sigmoide(*args, **kwargs)
Forma:
- Entrada: (∗), donde ∗ se refiere a cualquier número de dimensiones.
- Salida: (∗), la misma forma que la entrada.
5.2 Prueba de función de activación de sustitución digital
código pitón:
import torch
from torch import nn
from torch.nn import ReLU
from torch.nn import Sigmoid
input = torch.tensor([[1, -0.5],
[-1, 3]])
output = torch.reshape(input, (-1, 1, 2, 2))
print(output)
class MYNN(nn.Module):
def __init__(self):
super(MYNN, self).__init__()
self.relu1 = ReLU()
self.sigmod1 = Sigmoid()
def forward(self, input):
output = self.relu1(input)
output2 = self.sigmod1(input)
return output, output2
mynn = MYNN()
output, output2 = mynn(input)
print(output)
print(output2)
resultado de la operación:
tensor([[[[ 1.0000, -0.5000],
[-1.0000, 3.0000]]]])
tensor([[1., 0.],
[0., 3.]])
tensor([[0.7311, 0.3775],
[0.2689, 0.9526]])
5.3 Operación de activación no lineal de imagen
El código Python para la operación de activación no lineal de imágenes:
# 使用数字显示relu和sigmod非线性激活函数的作用
import torch
import torchvision
from torch import nn
from torch.nn import ReLU
from torch.nn import Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10(root="G:\\Anaconda\\pycharm_pytorch\\learning_project\\dataset_CIFAR10",
train=False,
transform=torchvision.transforms.ToTensor(),
download=False)
dataloader = DataLoader(dataset, batch_size=64)
class MYNN(nn.Module):
def __init__(self):
super(MYNN, self).__init__()
self.relu1 = ReLU()
self.sigmod1 = Sigmoid()
def forward(self, input):
output_relu = self.relu1(input)
output_sigmod = self.sigmod1(input)
return output_relu, output_sigmod
mynn = MYNN()
writer = SummaryWriter("G:/Anaconda/pycharm_pytorch/learning_project/logs_relu")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input", imgs, step)
output_relu, output_sigmod = mynn(imgs)
writer.add_images("output_relu", output_relu, step)
writer.add_images("output_sigmod", output_sigmod, step)
step += 1
print(step)
writer.close()
print("Done")
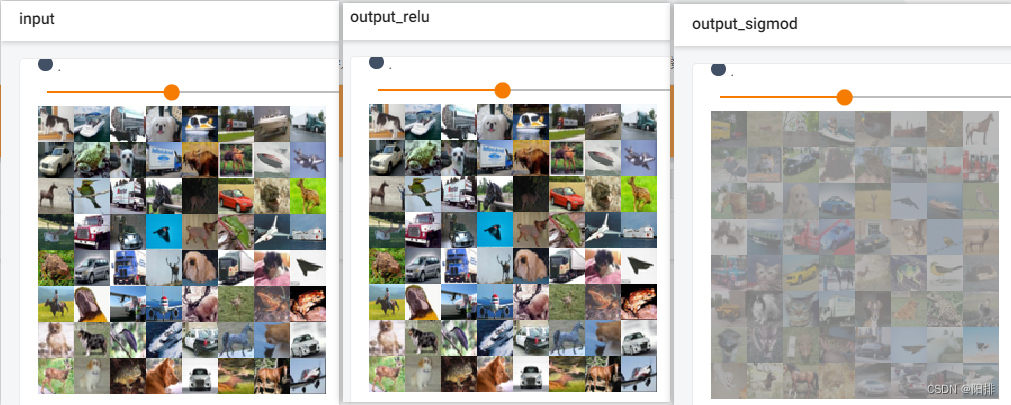
Después de que se ejecute el código, ingrese en la terminal tensorboard --logdir=logs_relupara abrir tensorboard. Puede verse que la imagen de salida se reduce en resolución después de la operación de agrupación.
Porque la operación relu es para corregir la asignación a 0, pero la imagen es 0-255, por lo que no hay diferencia entre input y output_relu; pero la operación sigmod es para corregir el valor de la imagen 0-255 de acuerdo con una determinada exponencial proporción, por lo que producirá Variedad en escala de grises.
6 Capa de regularización Capas de normalización
Enlace de aprendizaje:
https://pytorch.org/docs/stable/nn.html#normalization-layers
La regularización, también conocida como normalización, es un paso que acelera el aprendizaje de redes neuronales.