Prefacio:
Debido al estudio reciente del problema de nomenclatura de entidades del gráfico de conocimiento, en el experimento usamos word2vec para reducir el procesamiento de palabras, por lo que para esta herramienta es necesario comprender la situación básica.
10.1 Incrustación de palabras (word2vec)
10.1.1 ¿Por qué no usar vectores one-hot?
Un vector one-hot representa una palabra (los caracteres son palabras). Suponiendo que el índice de una palabra es iii, para obtener la representación del vector one-hot de la palabra, creamos un vector de longitud NNN con todos 0 y establecemos su iii 1. El vector de una palabra activa no puede expresar con precisión la similitud entre diferentes palabras, como la similitud de coseno que usamos a menudo
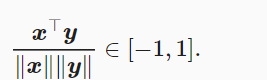
Dado que la similitud de coseno de los vectores one-hot de dos palabras diferentes es 0
Representa cada palabra como un vector de longitud fija y permite que estos vectores expresen mejor la relación de similitud y analogía entre diferentes palabras. La herramienta word2vec contiene dos modelos, a saber, el modelo skip-gram [2] y el modelo de bolsa continua de palabras (CBOW)
10.1.2 Modelo de palabra de salto
Suponga que la secuencia de texto es "el" "hombre" "ama" "su" "hijo". Con "amores" como palabra central, establezca el tamaño de la ventana de fondo en 2.

关于 SoftMax: https://blog.csdn.net/lz_peter/article/details/84574716
Expandir a más general:
Suponiendo que la generación de palabras de fondo es independiente entre sí cuando se da la palabra central, cuando el tamaño de la ventana de fondo es mm, la función de probabilidad del modelo de omisión de palabras es la probabilidad de generar todas las palabras de fondo dada cualquier palabra central

10.1.2.1. Modelo de salto de tren¶

10.1.3. Modelo de bolsa continua de palabras¶
El modelo de bolsa de palabras continua asume que se genera una palabra central basada en las palabras de fondo antes y después de la secuencia de texto.
Continuará. . .
referencias:
Enlace original: https://zh.d2l.ai/chapter_natural-language-processing/word2vec.html
Estimación de máxima verosimilitud: http://fangs.in/post/thinkstats/likelihood/
Función softmax: https://blog.csdn.net/lz_peter/article/details/84574716
Campo aleatorio condicional, CRF