1. Introducción
Transformer mejora las deficiencias del entrenamiento más criticado de RNN, que utiliza el mecanismo de auto atención para lograr un paralelismo rápido. Y Transformer se puede aumentar a una profundidad muy profunda, explorar completamente las características del modelo DNN y mejorar la precisión del modelo. Un factor clave en el éxito de BERT es el poderoso papel de Transformer.
Transformer fue propuesto por el documento "Atención es todo lo que necesita" y ahora es el modelo de referencia recomendado por Google Cloud TPU.
La atención es todo lo que necesita: https: //arxiv.org/abs/1706.03762
2. Comience desde una perspectiva macro
Primero considere este modelo como una operación de caja negra. En la traducción automática, es ingresar un idioma y generar otro idioma.

Luego abra este cuadro negro, podemos ver que está compuesto de componentes de codificación, componentes de decodificación y las conexiones entre ellos.

La parte del componente de codificación consta de un grupo de codificadores (en el documento, 6 codificadores se apilan juntos; el número 6 no tiene nada de mágico, también puedes probar otros números). La parte componente de decodificación también está compuesta por el mismo número de decodificadores ( correspondientes a los codificadores ).

Todos los codificadores tienen una estructura idéntica , pero no comparten parámetros .
Cada decodificador se puede descomponer en dos subcapas.
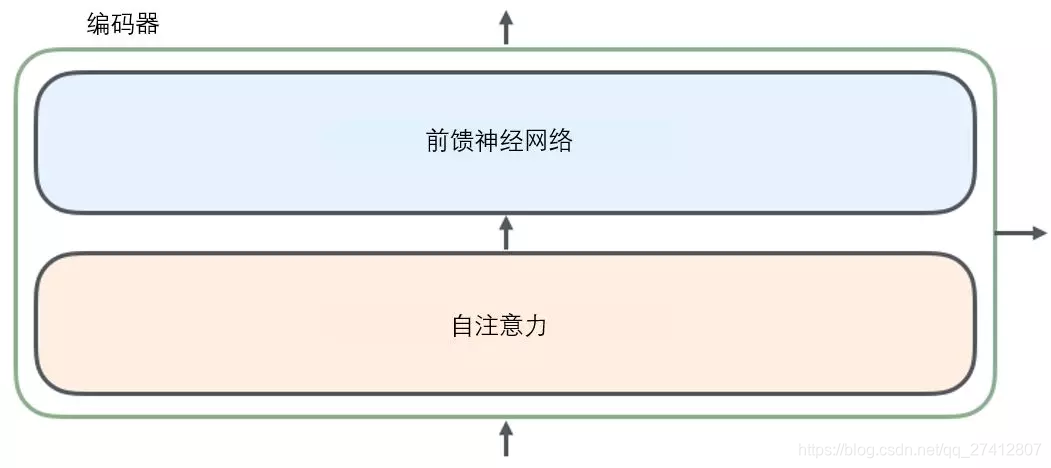
La entrada de oraciones desde el codificador pasará primero por una capa de auto atención (auto atención) , que ayuda al codificador a enfocarse en otras palabras de la oración de entrada cuando codifica cada palabra. Estudiaremos la auto-atención con más profundidad en un artículo posterior.
La salida de la capa de atención se pasa a la red neuronal de avance . La red neuronal de retroalimentación correspondiente a la palabra en cada posición es exactamente la misma (Anotación: otra interpretación es una red neuronal convolucional unidimensional con una ventana de una palabra).
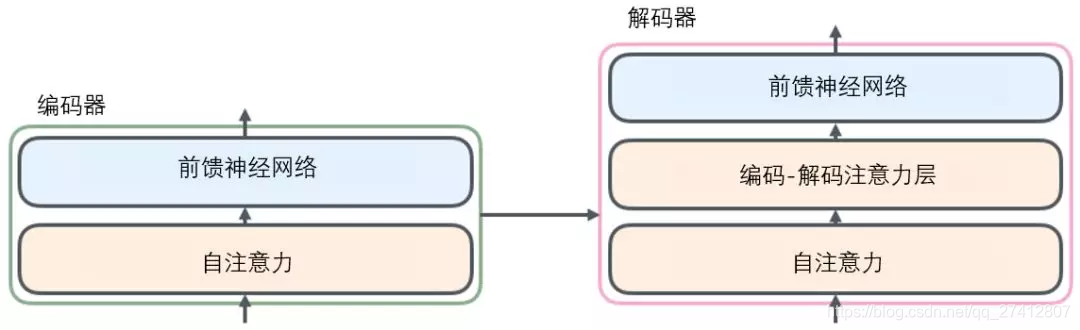
El decodificador también tiene las capas de autoatención y avance del codificador . Además, hay una capa de atención entre estas dos capas, que se utiliza para centrarse en las partes relevantes de la oración de entrada (similar a la función de atención del modelo seq2seq).
3. Introduce el tensor en la imagen.
Ahora que hemos entendido la parte principal del modelo, echemos un vistazo a varios vectores o tensores. Cómo convertir entradas en salidas en diferentes partes del modelo.
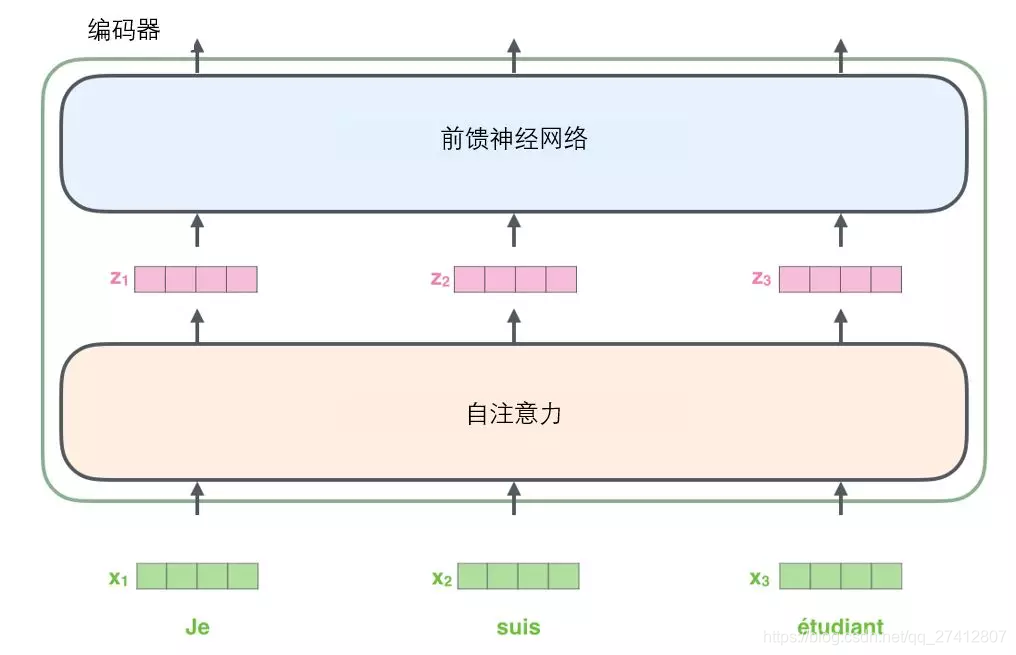
Como la mayoría de las aplicaciones de PNL, primero convertimos cada palabra de entrada en un vector de palabras a través de un algoritmo de inclusión de palabras .

Cada palabra está incrustada como un vector de dimensión 512. Utilizamos estos cuadros simples para representar estos vectores.
El proceso de incrustación de palabras solo se produce en el codificador inferior .
Todos los codificadores tienen la misma característica, es decir, reciben una lista de vectores, y cada vector en la lista tiene un tamaño de 512 dimensiones. En el codificador inferior (inicial) es la palabra vector, pero en otros codificadores, es la salida del siguiente codificador de capa (también una lista de vectores). El tamaño de la lista de vectores es un hiperparámetro que podemos establecer, generalmente la longitud de la oración más larga en nuestro conjunto de entrenamiento.
Después de que la palabra incorpore la secuencia de entrada, cada palabra fluirá a través de dos subcapas en el codificador.
A continuación, echemos un vistazo a una característica central de Transformer, donde las palabras en cada posición de la secuencia de entrada tienen su propia ruta única en el codificador. ** En la capa de auto atención, existe una relación de dependencia entre estas rutas. La capa de avance no tiene estas dependencias. ** Por lo tanto, se pueden ejecutar varias rutas en paralelo en la capa de avance.
Luego tomaremos una oración más corta como ejemplo para ver qué sucede en cada subcapa del codificador.
4. Ahora comenzamos a "codificar"
Como ya se mencionó anteriormente, un codificador recibe la lista de vectores como entrada , luego pasa los vectores en la lista de vectores a la capa de auto atención para su procesamiento, y luego la pasa a la capa de red neuronal de alimentación hacia adelante, pasando el resultado de salida a la siguiente codificación器 中.

Cada palabra de la secuencia de entrada se somete a un proceso de autocodificación . Luego, cada uno pasa a través de la red neuronal de propagación directa, exactamente la misma red , y cada vector lo atraviesa por separado.
5. Vea el mecanismo de auto-atención desde una perspectiva macro
No se confunda con la palabra auto-atención, parece que todos deberían estar familiarizados con este concepto. De hecho, no he visto este concepto hasta que leí Atención es todo lo que necesitas. Vamos a refinar cómo funciona.
Por ejemplo, la siguiente oración es la oración de entrada que queremos traducir:
El animal de no cruzar la calle , ya que estaba demasiado cansado
¿Qué significa este "eso" en esta oración? ¿Se refiere a la calle o al animal? Este es un problema simple para los humanos, pero no para los algoritmos.
Cuando el modelo procesa la palabra "it", el mecanismo de auto-atención permitirá que "it" establezca una conexión con "animal" .
A medida que el modelo procesa cada palabra de la secuencia de entrada, la auto atención se centrará en todas las palabras de la secuencia de entrada completa, ayudando al modelo a codificar mejor la palabra.
Si está familiarizado con RNN (red neuronal recurrente), recuerde cómo mantiene la capa oculta. RNN combinará la representación de todas las palabras / vectores anteriores que ha procesado con la palabra / vector actual que está procesando. El mecanismo de auto-atención integrará la comprensión de todas las palabras relacionadas en las palabras que estamos tratando .
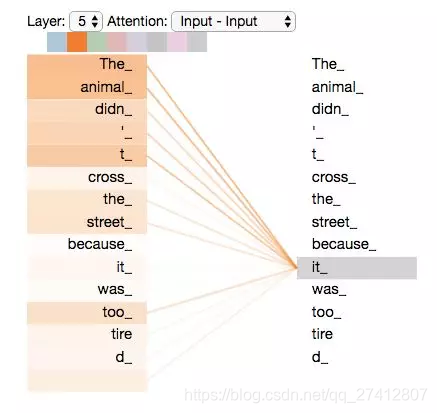
Cuando codificamos la palabra "it" en el codificador n. ° 5 (el codificador superior de la pila), la parte del mecanismo de atención prestará atención a "The Animal" y codificará parte de su representación en "it" Codificación
Asegúrese de revisar el cuaderno Tensor2Tensor, donde puede descargar un modelo Transformer y verificarlo con una visualización interactiva.
6. Viendo el mecanismo de auto-atención desde una micro perspectiva
Primero, comprendamos cómo usar vectores para calcular la auto atención, y luego veamos cómo se puede implementar usando una matriz.
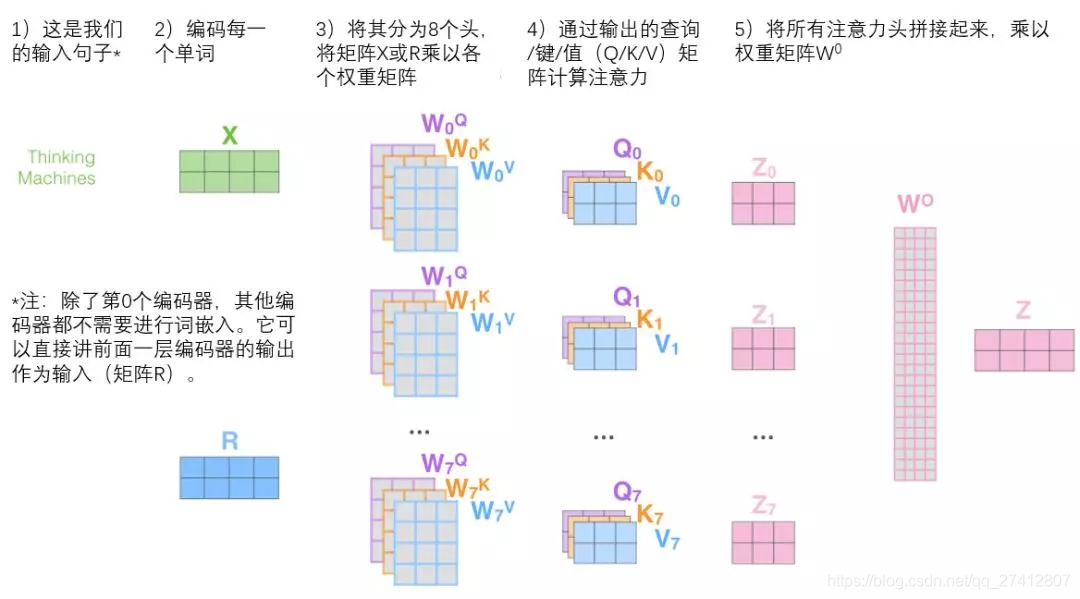
(1) El primer paso para calcular la auto atención es generar tres vectores a partir del vector de entrada de cada codificador (vector de palabras para cada palabra).
En otras palabras, para cada palabra, creamos un vector de consulta, un vector clave y un vector de valores . Estos tres vectores se crean mediante la inclusión y multiplicación de palabras por tres matrices de peso.
Se puede encontrar que estos nuevos vectores son de menor dimensión que los vectores de incrustación de palabras. Su dimensión es 64, y la dimensión de la inserción de palabras y el vector de entrada / salida del codificador es 512. Sin embargo, en realidad no se requiere que sea más pequeña. Esta es solo una opción arquitectónica, que puede hacer que la atención sea de múltiples cabezas (atención de múltiples cabezas) ) La mayoría de los cálculos permanecen sin cambios.
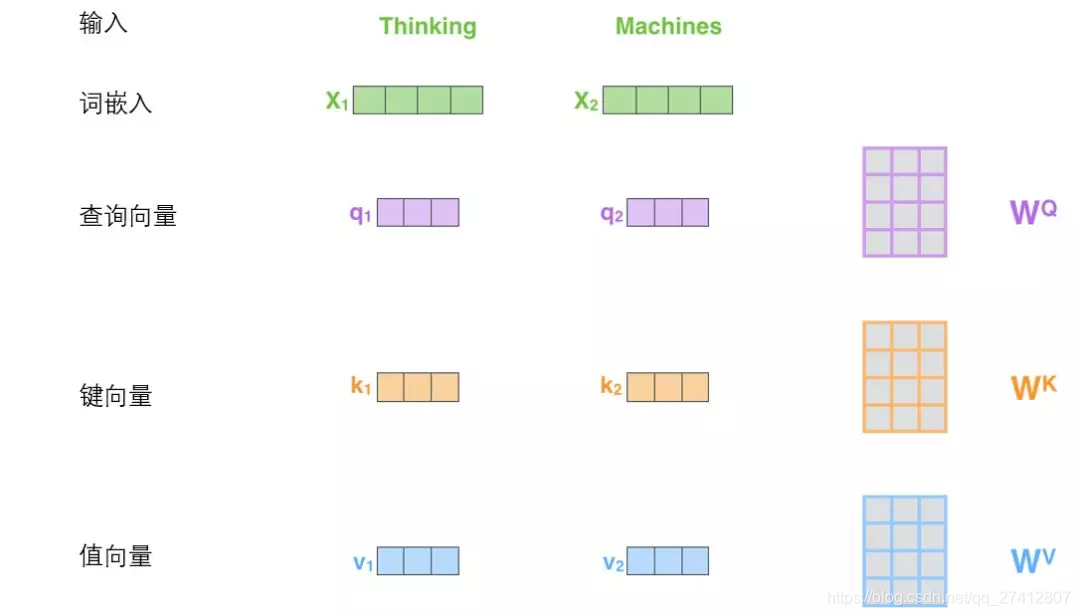
La matriz de peso X1 y Wq se multiplica para obtener q1, que es el vector de consulta relacionado con esta palabra. Finalmente, cada consulta de la secuencia de entrada crea un vector de consulta, un vector clave y un vector de valores.
¿Qué son los vectores de consulta, los vectores clave y los vectores de valor?
Todos son conceptos abstractos que ayudan a calcular y comprender el mecanismo de atención. Continúe leyendo a continuación, sabrá qué papel juega cada vector en el cálculo del mecanismo de atención.
(2) El segundo paso para calcular la auto atención es calcular el puntaje.
Supongamos que estamos calculando el vector de auto atención para la primera palabra "Pensamiento" en este ejemplo, necesitamos calificar "Pensamiento" para cada palabra en la oración de entrada. Estas puntuaciones determinan cuánta atención se presta a otras partes de la oración en el proceso de codificación de la palabra "Pensamiento".
Estos puntajes se calculan por el producto de puntos del vector clave de las palabras calificadas (todas las palabras en la oración de entrada) y el vector de consulta de "Pensamiento". ** Entonces, si tratamos con la auto-atención de la palabra superior, la primera puntuación es el producto de punto de q1 y k1, y la segunda puntuación es el producto de punto de q1 y k2.
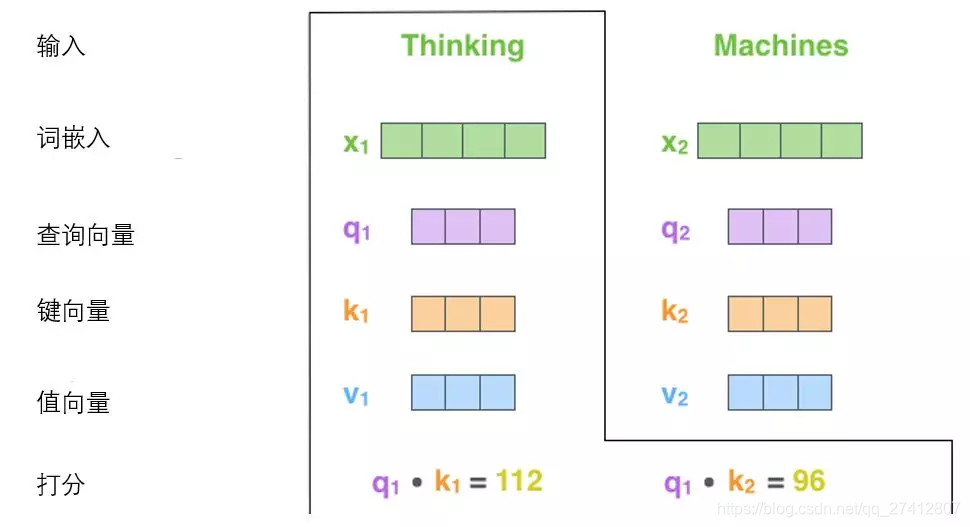
(3) Los pasos tercero y cuarto son dividir la puntuación entre 8 (8 es la raíz cuadrada de la dimensión 64 del vector clave utilizado en el documento, lo que hace que el gradiente sea más estable. Aquí también se pueden usar otros valores, 8 es el valor predeterminado ), Y luego pasa el resultado a través de softmax. La función de softmax es normalizar los puntajes de todas las palabras, y los puntajes obtenidos son positivos y la suma es 1.
Este puntaje softmax determina la contribución de cada palabra a la posición actual del código ("Pensamiento"). Obviamente, la palabra que ya está en esta posición obtendrá la puntuación más alta de softmax, pero a veces puede ser útil centrarse en otra palabra relacionada con la palabra actual.
(4) El quinto paso es multiplicar cada vector de valor por la puntuación softmax (esto es resumirlos después de la preparación). La intuición aquí es que desea centrarse en palabras relacionadas semánticamente y debilitar palabras irrelevantes (por ejemplo, multiplíquelas por un decimal como 0.001).
(5) El sexto paso es sumar los vectores de valor ponderado. Por el producto punto de la representación de la palabra (vector clave) y la representación de la palabra codificada (vector de consulta) y obtenida por softmax.), Entonces se obtiene la salida de la capa de auto atención en esta posición (en nuestro ejemplo, es Palabras).
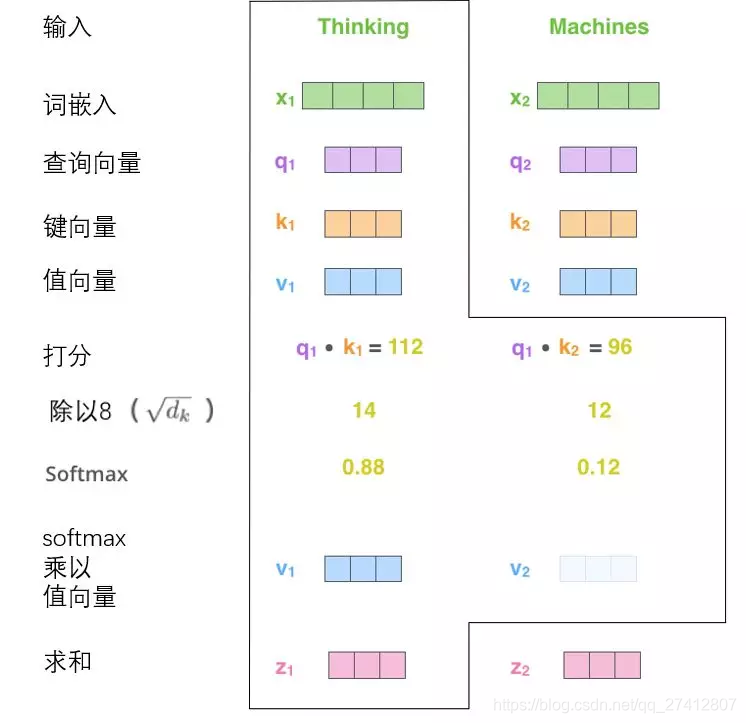
Esto completa el cálculo de la autoatención. El vector resultante se puede pasar a la red neuronal de avance. Sin embargo, en la práctica, estos cálculos se realizan en forma de matriz para calcular más rápido. Entonces echemos un vistazo a cómo usar la matriz.
7. Mecanismo de auto atención mediante operación matricial
(1) El primer paso es calcular la matriz de consulta, la matriz de claves y la matriz de valores. Para este fin, integraremos las palabras de la oración de entrada en la matriz X y la multiplicaremos por la matriz de peso (Wq, Wk, Wv) que entrenamos.
** Cada fila en la matriz x corresponde a una palabra en la oración de entrada. ** Nuevamente vemos la diferencia de tamaño entre el vector de incrustación de palabras (512 o 4 cuadrículas en la figura) y el vector q / k / v (64 o 3 cuadrículas en la figura).
(2) Finalmente, dado que estamos tratando con matrices, podemos combinar los pasos 2 a 6 en una fórmula para calcular la salida de la capa de auto atención .
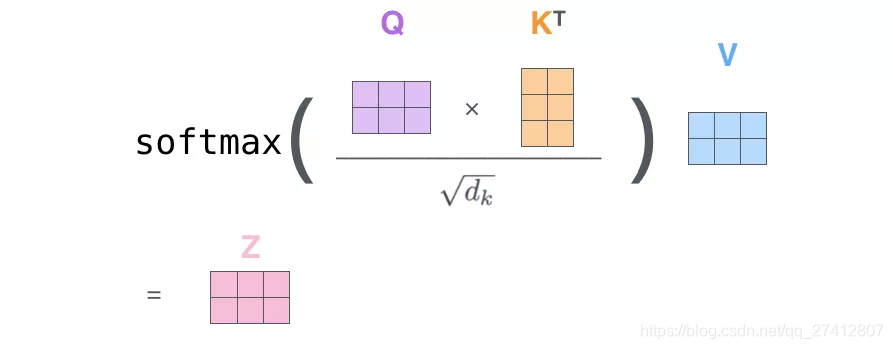
Forma de operación de matriz de auto atención
8. "Guerra contra los toros"
Al agregar un mecanismo llamado atención "multi-encabezada", el papel perfecciona aún más la capa de auto atención y mejora el rendimiento de la capa de atención de dos maneras:
1. Expande la capacidad del modelo para enfocarse en diferentes ubicaciones.
En el ejemplo anterior, aunque cada código se refleja más o menos en z1, puede estar dominado por la palabra en sí misma. Si traducimos una oración, como "El animal no cruzó la calle porque estaba demasiado cansado", nos gustaría saber a qué palabra "se refiere", y luego funcionará el mecanismo de atención "largo" del modelo.
2. Da múltiples "subespacios de representación" de la capa de atención.
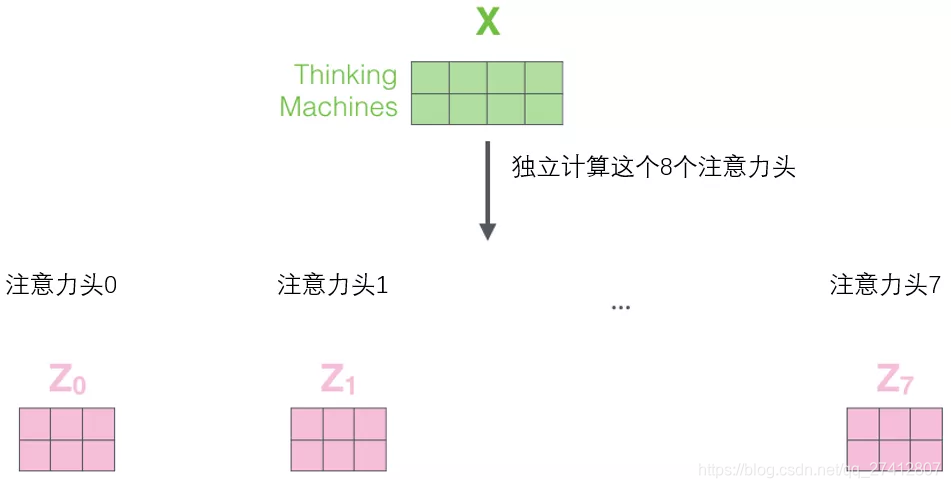
A continuación, veremos que para el mecanismo de atención de "cabezales múltiples", tenemos múltiples conjuntos de matriz de peso de consulta / clave / valor (Transformer utiliza ocho cabezales de atención, por lo que tenemos ocho conjuntos de matriz para cada codificador / decodificador ) Cada uno de estos conjuntos se inicializa aleatoriamente, y después del entrenamiento, cada conjunto se utiliza para incrustar las palabras de entrada (o vectores de codificadores / decodificadores inferiores) en diferentes subespacios de representación.
Bajo el mecanismo de atención "multi-head", mantenemos una matriz de ponderación de consulta / clave / valor independiente para cada cabeza, lo que resulta en diferentes matrices de consulta / clave / valor . Como antes, multiplicamos X por la matriz Wq / Wk / Wv para generar la matriz de consulta / clave / valor.
Si hacemos el mismo cálculo de auto-atención que el anterior, solo necesitamos ocho operaciones de matriz de peso diferentes , y obtendremos ocho matrices Z diferentes.
Esto nos trae un pequeño desafío. La capa de avance no necesita 8 matrices, solo necesita una matriz (que consiste en el vector de representación de cada palabra). Entonces, necesitamos una forma de comprimir estas ocho matrices en una matriz. Que debo hacer De hecho, estas matrices se pueden unir directamente y luego multiplicar por una matriz de peso adicional W.
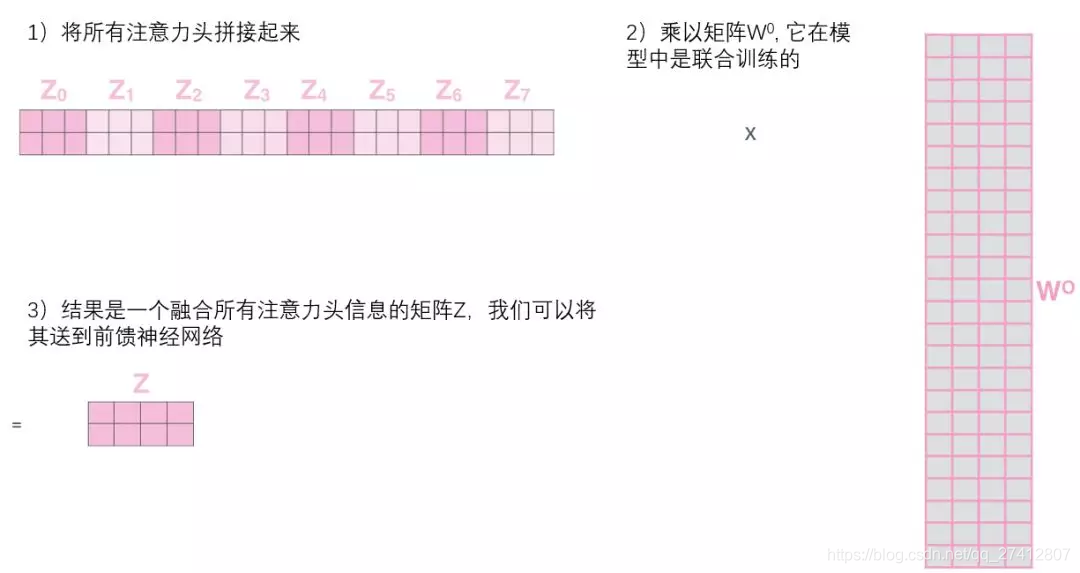
Esta es casi toda la atención de los toros. De hecho, hay muchas matrices, tratamos de juntarlas en una imagen, para que pueda verlas de un vistazo.
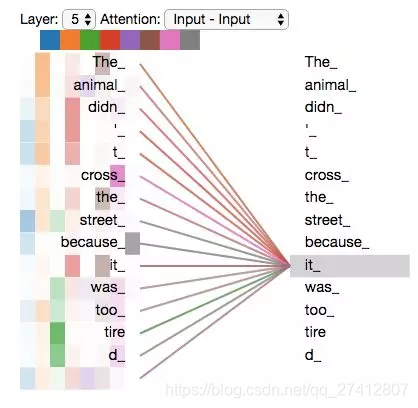
Ahora que hemos tocado tantas "cabezas" del mecanismo de atención, revisemos el ejemplo anterior y veamos dónde nos enfocamos en las diferentes "cabezas" de atención cuando codificamos la palabra "it" en la oración de ejemplo:
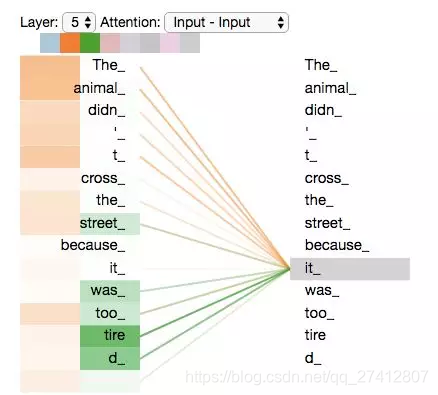
Cuando codificamos la palabra "it", uno se enfoca en "animal" y el otro en "cansado". En cierto sentido, el modelo expresa la palabra "it" de cierta manera. Hasta cierto punto, es el representante de "animal" y "cansado".
Sin embargo, si agregamos toda la atención a la ilustración, las cosas son más difíciles de explicar:
9. Use los códigos de posición para indicar el orden de secuencia
Hasta ahora, nuestra descripción del modelo carece de una forma de entender el orden de las palabras de entrada.
Para resolver este problema, Transformer agrega un vector a cada incrustación de palabras de entrada. Estos vectores siguen patrones específicos aprendidos por el modelo, lo que ayuda a determinar la ubicación de cada palabra o la distancia entre diferentes palabras en la secuencia. La intuición aquí es que agregar vectores de posición a las incrustaciones de palabras les permite expresar mejor la distancia entre palabras en operaciones posteriores .
Para que el modelo entienda el orden de las palabras, agregamos vectores de codificación de posición cuyos valores siguen un patrón específico.
Si suponemos que la dimensión de la inclusión de palabras es 4, el código de posición real es el siguiente:
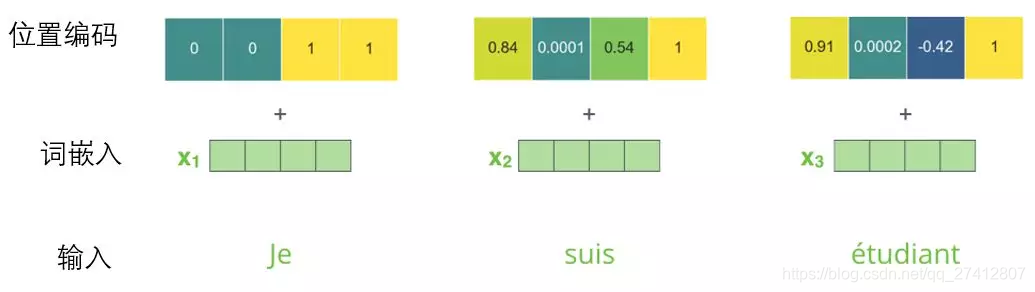
Ejemplo de codificación de posición para mini palabras de tamaño 4
¿Cómo será este modelo?
En la figura siguiente, cada línea corresponde al código de posición de un vector de palabras, por lo que la primera línea corresponde a la primera palabra de la secuencia de entrada. Cada fila contiene 512 valores, con cada valor entre 1 y -1. Los hemos codificado por colores, por lo que el patrón es visible.
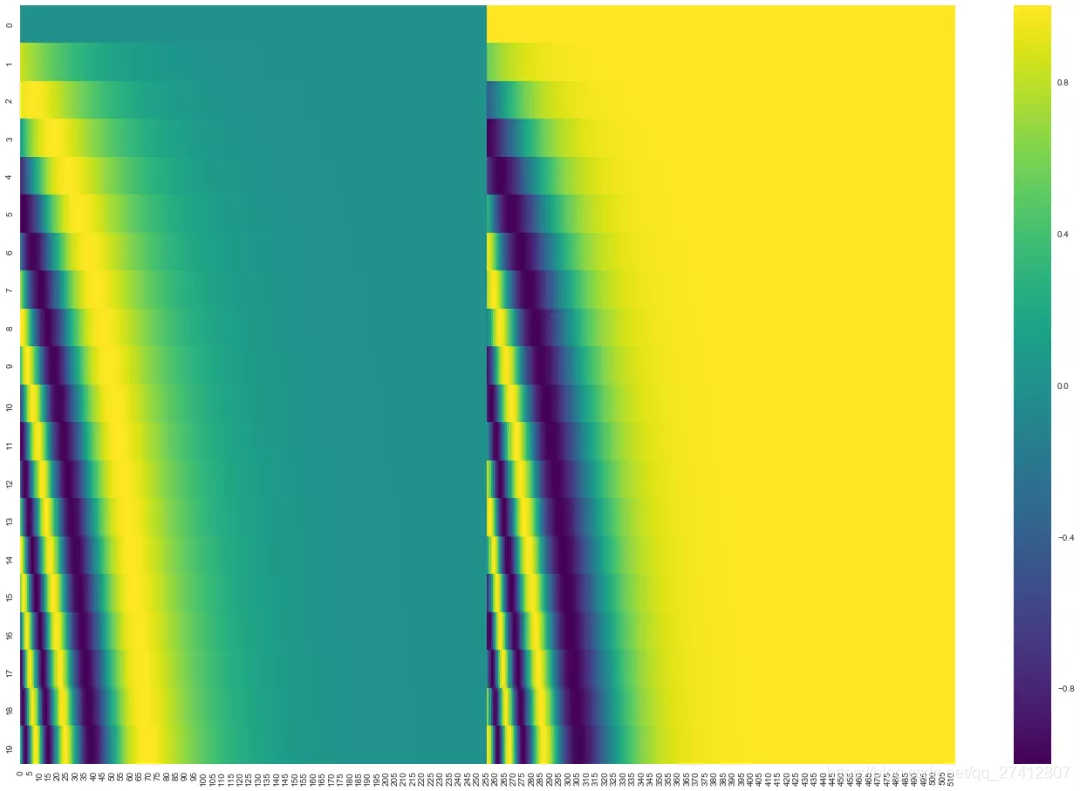
Ejemplo de codificación de posición de 20 palabras (fila), el tamaño de inserción de palabras es 512 (columna). Puedes verlo dividido por la mitad desde el medio. Esto se debe a que la mitad izquierda del valor es generada por una función (usando seno), mientras que la mitad derecha es generada por otra función (usando coseno). Luego póngalos juntos para obtener cada vector de codificación de posición.
El documento original describe la fórmula de codificación de posición (Sección 3.5). Puede ver el código que genera el código de posición en get_timing_signal_1d (). Este no es el único método de codificación de posición posible. Sin embargo, su ventaja es que puede extenderse a una longitud de secuencia desconocida (por ejemplo, cuando el modelo que entrenamos necesita traducir oraciones que son mucho más largas que las oraciones en el conjunto de entrenamiento).
10. Módulo residual
Antes de continuar, debemos mencionar los detalles de una arquitectura de codificador: hay una conexión residual alrededor de cada subcapa (auto-atención, red de avance) en cada codificador , y todos siguen Un paso de " normalización de capa ".
Pasos de normalización de capa: https://arxiv.org/abs/1607.06450
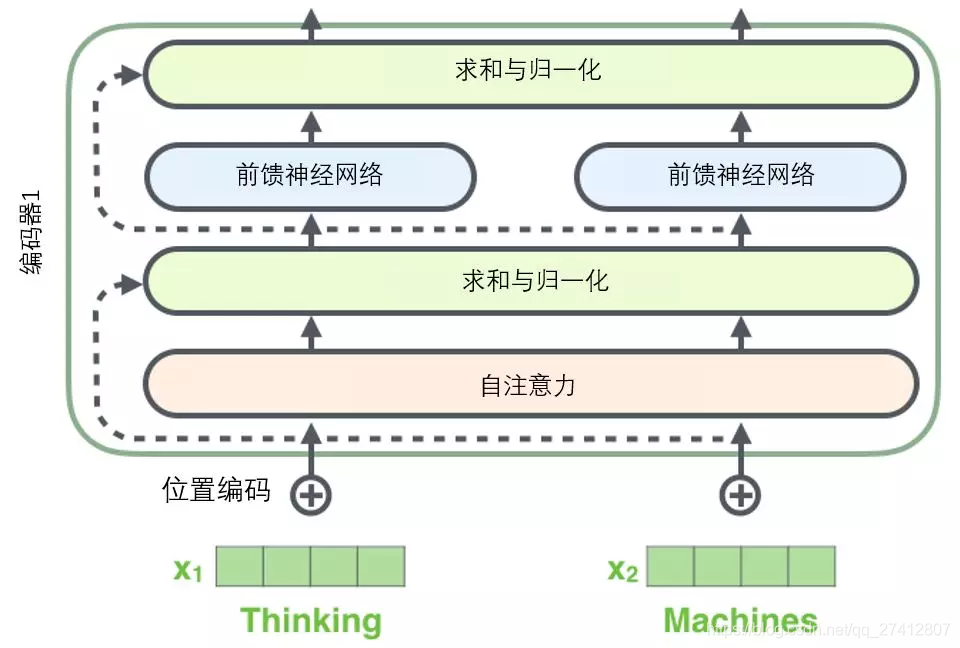
Si visualizamos estos vectores y la operación de normalización de capa asociada con la auto atención, se ve como en la siguiente imagen:
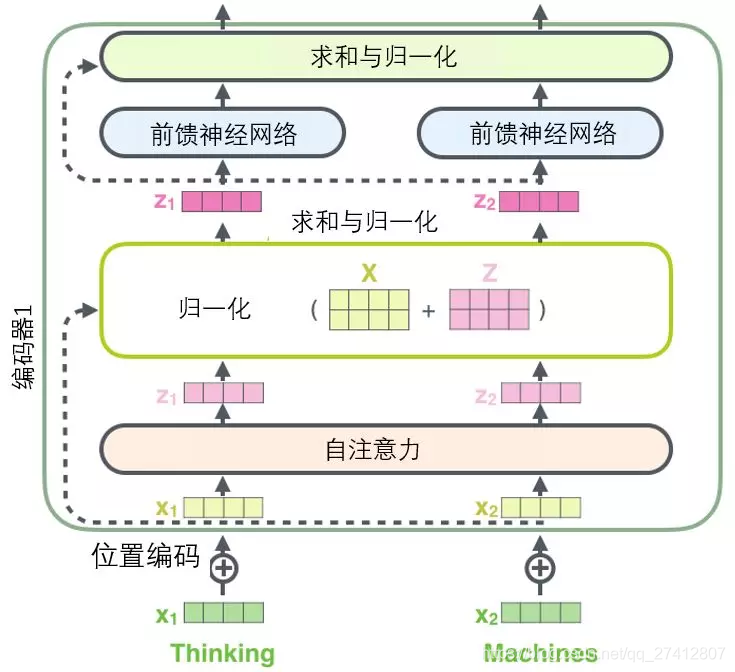
La subcapa del decodificador es la misma. Si imaginamos un transformador con una estructura de codificación-decodificación de 2 capas, se verá como en la siguiente imagen:
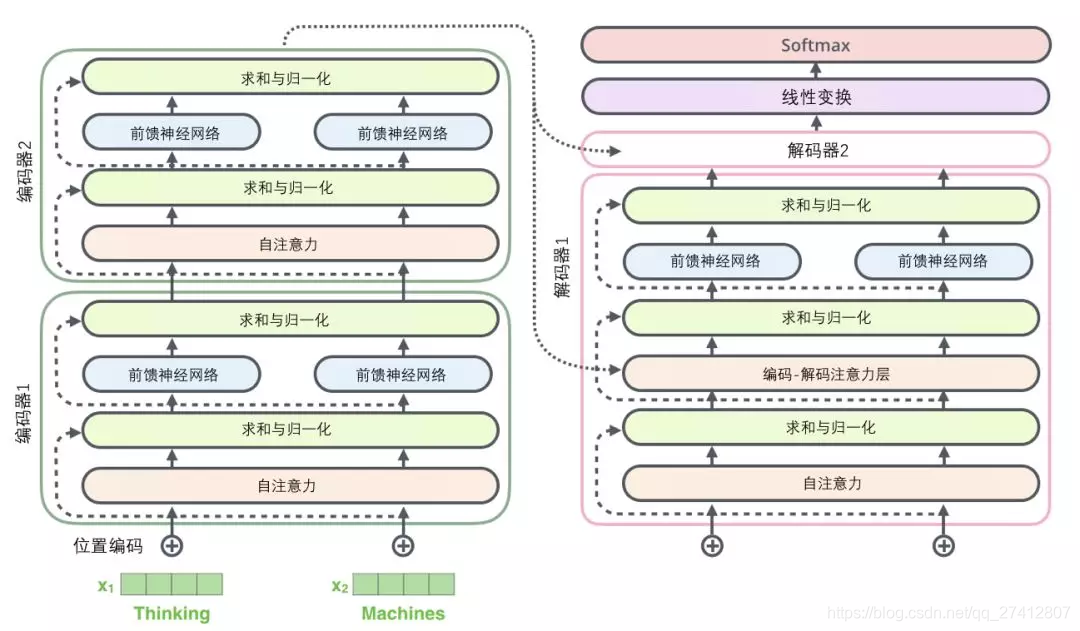
11. Componente de decodificación
Ahora que hemos hablado sobre el concepto de la mayoría de los codificadores, básicamente sabemos cómo funciona el decodificador. Pero es mejor mirar los detalles del decodificador.
El codificador comienza a funcionar procesando la secuencia de entrada. La salida del codificador superior se transformará en un conjunto de vectores de atención que contienen los vectores K (vector clave) y V (vector de valor) . Cada decodificador utilizará estos vectores para su propia "capa de atención de codificación-decodificación", y estas capas pueden ayudar al decodificador a centrarse en dónde es adecuada la secuencia de entrada:
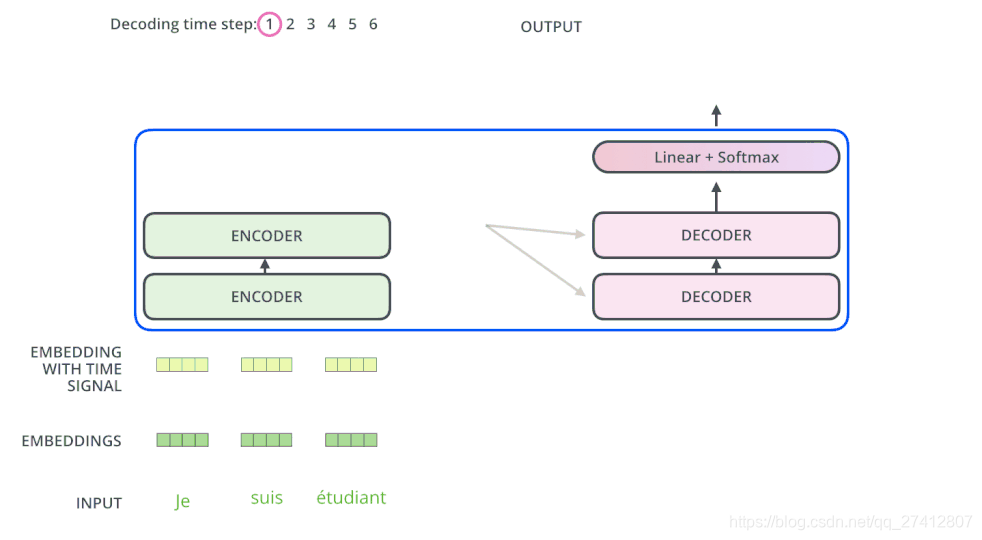
Después de completar la fase de codificación, comienza la fase de decodificación. Cada paso de la etapa de decodificación genera elementos de una secuencia de salida (en este ejemplo, una oración traducida al inglés)
El siguiente paso repite este proceso hasta que alcanza un símbolo de terminación especial, que indica que el decodificador del transformador ha completado su salida. La salida de cada paso se proporciona al decodificador de fondo en el siguiente paso de tiempo, y como lo hizo el codificador antes, estos decodificadores emitirán sus resultados de decodificación. Además, tal como lo hicimos con la entrada al codificador, incrustaremos y agregaremos códigos de posición a esos decodificadores para representar la posición de cada palabra.
src = “https://v.qq.com/txp/iframe/player.html?vid=m13563cy49o” allowfullscreen = “true” width = “600” height = “400”>
y la auto atención en esos decodificadores El modo de representación de capa es diferente del del codificador: en el decodificador, la capa de auto atención solo puede procesar las posiciones más altas en la secuencia de salida . Antes del paso softmax, ocultará las últimas posiciones (configúrelas en -inf).
Esta "capa de atención de codificación-decodificación" funciona básicamente como una capa de auto atención de múltiples encabezados, excepto que crea una matriz de consulta a través de las capas debajo de ella y obtiene la matriz de clave / valor de la salida del codificador.
12. La transformación lineal final y la capa Softmax
El componente de decodificación finalmente generará un vector real. ¿Cómo convertimos los números de coma flotante en una palabra? Este es el trabajo de la capa de transformación lineal, seguida de la capa Softmax.
La capa de transformación lineal es una red neuronal simple completamente conectada que puede proyectar el vector generado por el componente de decodificación en un vector llamado logits que es mucho más grande que él.
Supongamos que nuestro modelo aprende 10,000 palabras diferentes en inglés del conjunto de entrenamiento (el "vocabulario de salida" de nuestro modelo). Por lo tanto, el vector de probabilidad logarítmica es un vector de 10.000 longitudes de celda: cada celda corresponde al puntaje de una palabra determinada.
La siguiente capa de Softmax convertirá esas puntuaciones en probabilidades (ambas positivas, con un límite superior de 1.0). Se selecciona la celda con la probabilidad más alta, y su palabra correspondiente se usa como la salida de este paso de tiempo.
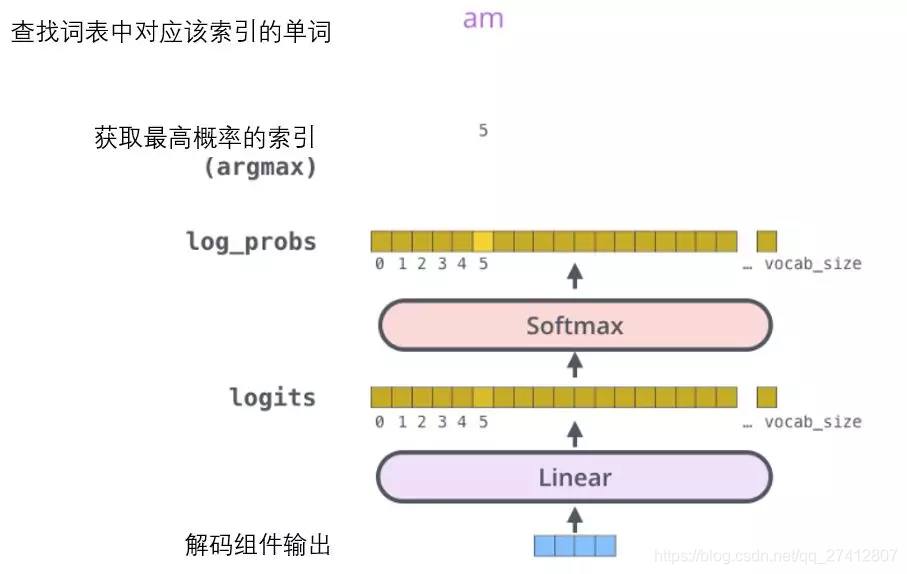
Esta imagen comienza en la parte inferior con el vector de salida generado por el componente decodificador. Luego convertirá una palabra de salida.
13. Resumen de la formación.
Ahora que hemos pasado por el proceso de propagación directa del transformador completo, podemos experimentar intuitivamente su proceso de capacitación.
Durante el entrenamiento, un modelo no entrenado se propagará exactamente de la misma manera. Pero debido a que lo entrenamos con un conjunto de entrenamiento etiquetado, podemos usar su salida para compararla con la salida real.
Para visualizar este proceso, supongamos que nuestro vocabulario de salida contiene solo seis palabras: "a", "am", "i", "gracias", "estudiante" y "" (forma abreviada del final de la oración).
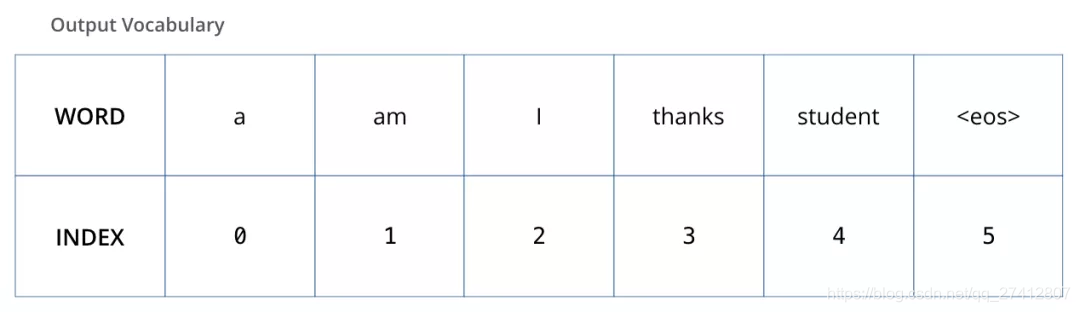
El vocabulario de salida de nuestro modelo se establece en el proceso de preprocesamiento antes de nuestra capacitación.
Una vez que hemos definido nuestro vocabulario de salida, podemos usar un vector del mismo ancho para representar cada palabra en nuestro vocabulario. Esto también se considera una codificación única. Por lo tanto, podemos usar el siguiente vector para representar la palabra "am":
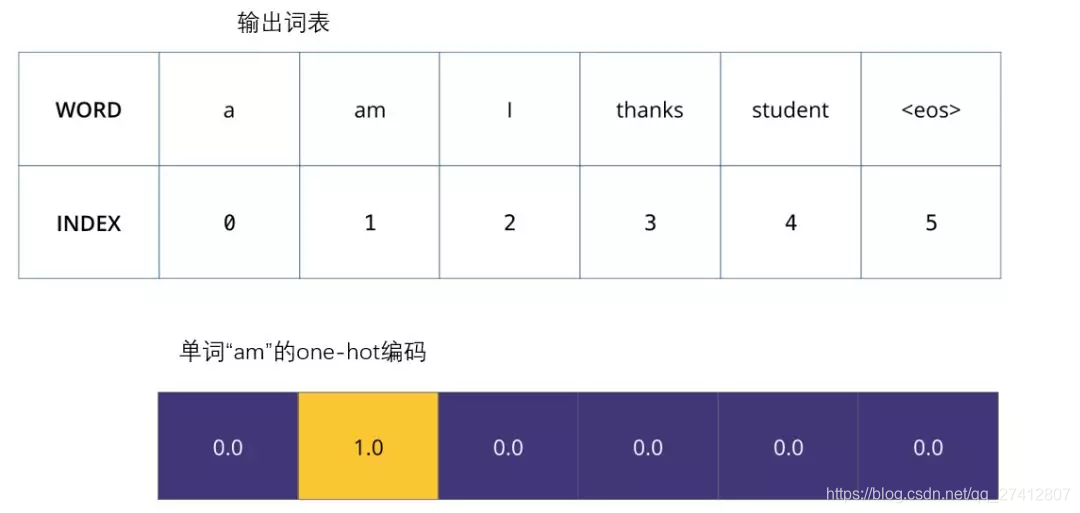
Ejemplo: codificación única de nuestro vocabulario de salida
A continuación, analizamos la función de pérdida del modelo: este es el criterio que utilizamos para optimizar durante el proceso de capacitación. Se puede usar para entrenar un modelo con el resultado más preciso posible.
14. Función de pérdida
Por ejemplo, estamos entrenando el modelo, ahora es el primer paso, un ejemplo simple: traducir "merci" a "gracias".
Esto significa que queremos una salida que represente la distribución de probabilidad de la palabra "gracias". Pero debido a que este modelo no se ha entrenado bien, es poco probable que este resultado aparezca ahora.
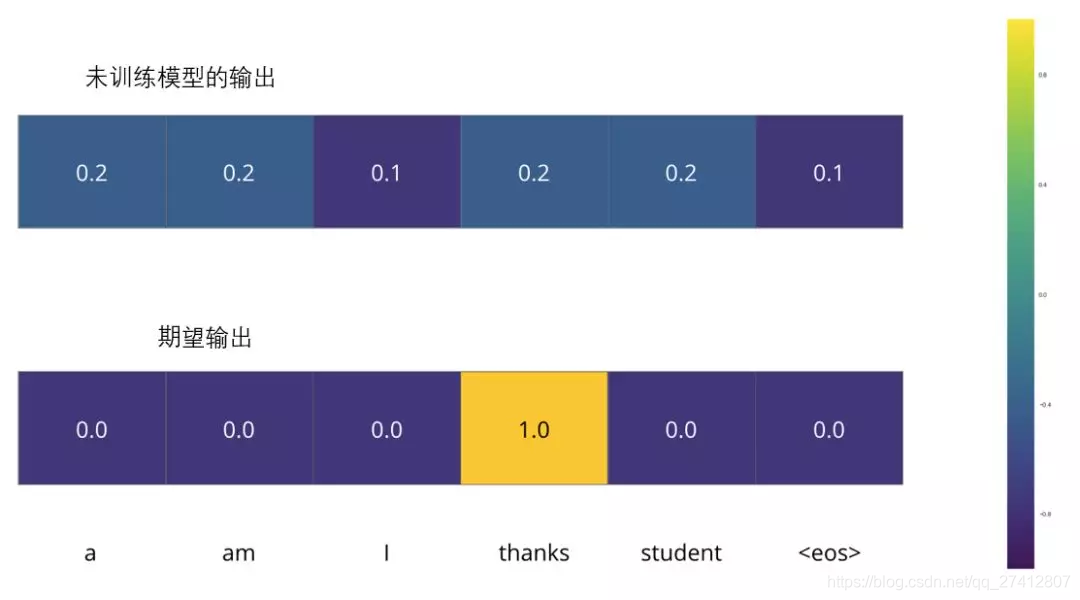
Debido a que los parámetros (pesos) del modelo se generan aleatoriamente, la distribución de probabilidad generada por el modelo (no entrenado) recibe un valor aleatorio en cada celda / palabra. Podemos compararlo con la salida real, y luego usar el algoritmo de propagación hacia atrás para ajustar ligeramente los pesos de todos los modelos para generar una salida más cercana al resultado.
¿Cómo compararías dos distribuciones de probabilidad? Simplemente podemos restar uno del otro. Para obtener más detalles, consulte Cross Entropy y KL Divergence.
Entropía cruzada: https://colah.github.io/posts/2015-09-Visual-Information/
Dispersión de KL: https://www.countbayesie.com/blog/2017/5/9/kullback-leibler-divergence-explained
Pero tenga en cuenta que este es un ejemplo demasiado simplificado. La situación más realista es procesar una oración. Por ejemplo, ingrese "je suis étudiant" y espere que la salida sea "soy un estudiante". Entonces esperamos que nuestro modelo pueda generar con éxito la distribución de probabilidad en estos casos:
Cada distribución de probabilidad está representada por un vector cuyo ancho es el tamaño del vocabulario (6 en nuestro ejemplo, pero la realidad suele ser 3000 o 10000).
La primera distribución de probabilidad tiene la probabilidad más alta en la celda asociada con "i"
La segunda distribución de probabilidad tiene la probabilidad más alta en la celda asociada con "am"
Por analogía, la distribución de la quinta salida indica que la celda asociada con "" tiene la mayor probabilidad
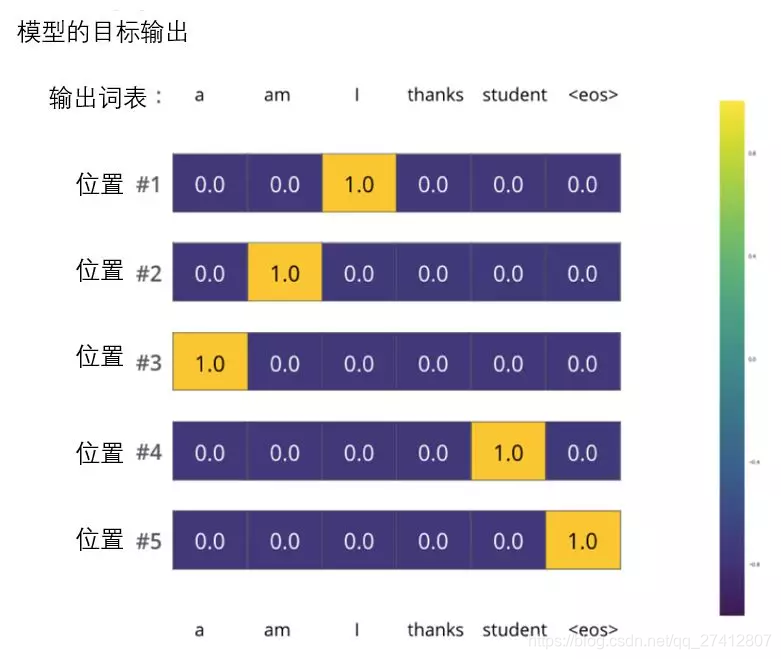
Distribución de probabilidad objetivo obtenida al entrenar un modelo de acuerdo con un ejemplo
Después de entrenar completamente en un conjunto de datos suficientemente grande, queremos que la distribución de probabilidad de la salida del modelo se vea así:
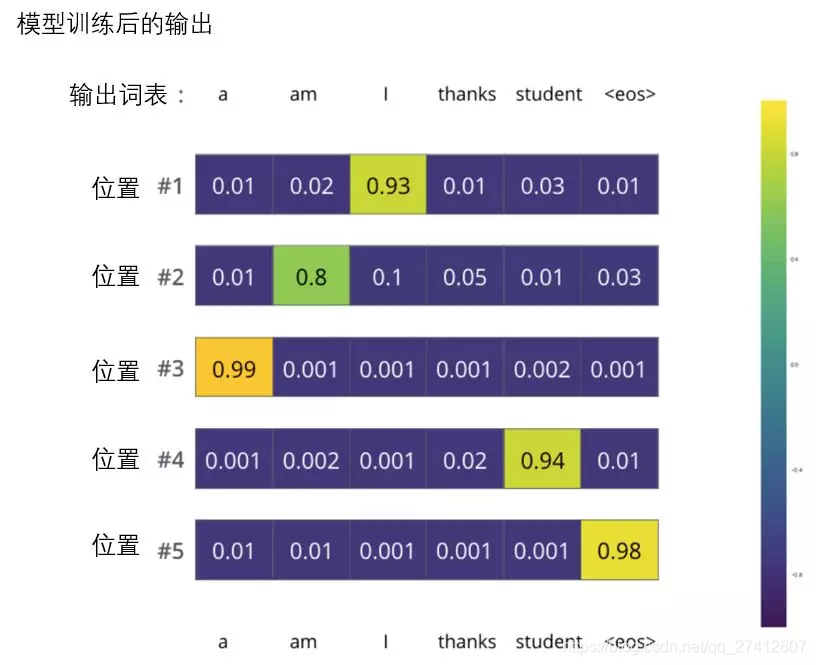
Esperamos que después del entrenamiento, el modelo genere la traducción correcta. Por supuesto, si este párrafo proviene completamente del conjunto de capacitación, no es un buen indicador de evaluación (referencia: validación cruzada, enlace https://www.youtube.com/watch?v=TIgfjmp-4BA). Tenga en cuenta que cada posición (palabra) tiene una pequeña probabilidad, incluso si es poco probable que sea la salida de ese paso de tiempo; esta es una propiedad útil de softmax, que puede ayudar a modelar el entrenamiento.
Debido a que este modelo produce solo una salida a la vez, se puede suponer que selecciona solo la palabra con mayor probabilidad y descarta las palabras restantes. Este es uno de los métodos (llamado decodificación codiciosa). Otra forma de realizar esta tarea es mantener las dos palabras con la mayor probabilidad (por ejemplo, I y a), luego, en el siguiente paso, ejecutar el modelo dos veces: una de ellas supone que la salida de la primera posición es la palabra "I", y Otra suposición es que la salida de la primera posición es la palabra "yo", y no importa qué versión produzca menos error, los dos resultados de traducción con la mayor probabilidad se conservan. Luego repetimos este paso para la segunda y tercera posición. Este método se llama búsqueda de haz. En nuestro ejemplo, el ancho del haz es 2 (porque se retienen los resultados de dos haces, como la primera y segunda posición), y también se devuelven los resultados de los dos haces (top_beams también es 2). Estos son parámetros que se pueden configurar de antemano.
Debido a que este modelo produce solo una salida a la vez, se puede suponer que selecciona solo la palabra con mayor probabilidad y descarta las palabras restantes. Este es uno de los métodos (llamado decodificación codiciosa). Otra forma de realizar esta tarea es mantener las dos palabras con la mayor probabilidad (por ejemplo, I y a), luego, en el siguiente paso, ejecutar el modelo dos veces: una de ellas supone que la salida de la primera posición es la palabra "I", y Otra suposición es que la salida de la primera posición es la palabra "yo", y no importa qué versión produzca menos error, los dos resultados de traducción con la mayor probabilidad se conservan. Luego repetimos este paso para la segunda y tercera posición. Este método se llama búsqueda de haz. En nuestro ejemplo, el ancho del haz es 2 (porque se retienen los resultados de dos haces, como la primera y segunda posición), y también se devuelven los resultados de los dos haces (top_beams también es 2). Estos son parámetros que se pueden configurar de antemano.
