Antes de la introducción del árbol modelo pertenece a la debilidad de los alumnos, el propio algoritmo es relativamente sencillo, pero después de que el algoritmo de fusión e integración producirá mejores resultados. Por ejemplo: + = embolsado de árboles forestales al azar; + = impulsar árbol de impulsar el árbol
que aquí se describe brevemente el algoritmo de integración, y luego los árboles del bosque aleatorio do realce descrito.
algoritmos integrados
algoritmos integrados: por más modelos combinados para resolver problemas prácticos.
Una pluralidad de modelo integrado se convierte en un modelo llamado el evaluador integrado para cada modelo, la composición del evaluador se llama un integrado evaluador grupo .

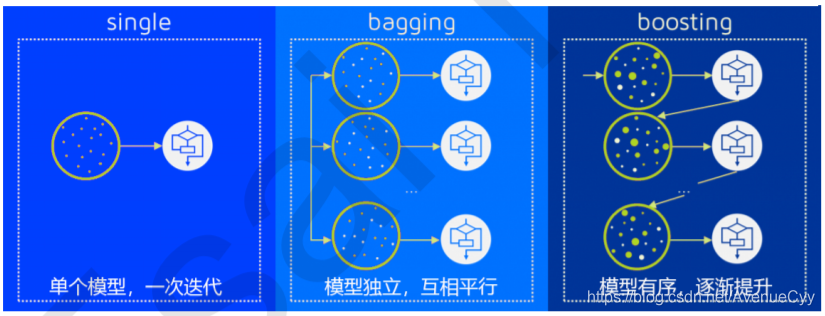
La "combinación" de esta realización tiene principalmente los dos siguientes: ensacado (en Bagging), levantando método (Intensificación)
en ensacado y Impulsar para aprendiz mismo tipo individual, tal integración es homogénea , y para diferentes tipos de aprendiz individual, tal integración es heterogénea .
De acuerdo con la homogeneidad de los estudiantes débiles si existe una dependencia entre la homogeneidad puede ser integrados categorías de clasificación:
- Existe entre el alumno débil fuerte dependencia, una serie de aprendiz débil básicamente requerido Serial generado (la débil aprendiz es un resultado del procesamiento de los alumnos débiles) algoritmo representativo es una serie de Impulsar algoritmos;
- No hay diferencia entre las dependencias fuertes débil aprendiz puede ser una serie de débil aprendiz generado en paralelo , (aprendiz débil co-tratamiento, independientes unos de otros) algoritmo es representante de la familia de ensacado de los algoritmos.
Harpillera
Por datos de muestreo al azar de atrás hay , datos diferentes producirán diferentes modelos, T T producirá un modelo de datos, y luego a través de algunos política de unión resultados obtenidos de estos modelos de unión.

Aproximadamente 1/3 de los datos no está marcada, el azar forestal (bosques aleatorios tienen fuera de banda), se puede probar, hay un conjunto de validación cruzada separada se divide.

Estrategia de integración
método de la media
Si este valor es la media como salida.

Ley de votación
Mayoría.

aprendizaje
apilamiento: el alumno primaria M como los nuevos datos, y luego se coloca en un nuevo modelo (alumno secundario) en el aprendizaje, el resultado final obtenido. Los resultados de bosque tales azar en regresión lineal, múltiples modelos superponen para obtener un resultado final.

impulsar
Embolsado entre el débil aprendiz hay dependencia, y hay una relación de dependencia entre Impulsar débil alumno, de modo que débil aprendiz se genera en serie, usando los resultados de la etapa anterior.
Primero con los alumnos débiles para entrenar, los resultados se compararon con el valor real de los valores de error de predicción dado mayor peso, y luego se colocan bajo una debilidad de los alumnos en la formación, con el fin de corresponder.

Embolsado e impulsar comparar
En embolsado : pequeña varianza (fuerte generalización), las grandes desviaciones (precisión debilidad de los alumnos no), por lo que con el fin de mejorar la capacidad de ajuste de los débiles alumno reducir el parpadeo, seleccione una mayor profundidad del árbol (árbol de gran profundidad se exceso de ajuste, basta con una pequeña desviación característica).
Sobre Intensificación : gran varianza (generalización débil), pequeñas desviaciones (precisión debilidad de los alumnos pueden ser), de manera ajustada con el fin de reducir la débil reducción de la varianza de aprendizaje, árboles de decisión para seleccionar una profundidad menor (la profundidad de profundidad pequeña en relación con el cuanto mayor es menos aptos, sólo para hacer una gran característica de dispersión).
Cuando, también se puede lograr esto al azar bosques y ajuste de parámetros GBDT la magnitud de la profundidad del árbol de decisión .


Random Forests
Embolsado es un árbol de decisión y de productos forestales al azar de la combinación. Sin embargo, la adición de algunas características de su propia:
- Embolsado en comparación con sólo los datos sobre el número de muestreo aleatorio, bosques aleatorios ha aumentado características muestreo aleatorio.
- árbol de decisión se utiliza en CART, porque la característica es seleccionada al azar (modelo en un número menor que el número de funciones de datos característicos de la original), y por lo tanto los árboles forestales Carro Carro aleatoria de menor escala normal, el conjunto de entrenamiento y ensayo de deformación resultados similares, robusta mejor.
flujo algoritmo Random Forest es :
donde la poda de árboles no se debe a una gran desviación de las características de la toma de ensacado.
Para los resultados de la regresión usando la media; clasificar un voto de la mayoría.

ventajas y desventajas Random Forests
1. Parallel Computing, velocidad
2. Basándose en el árbol de CART, también puede ser de regresión clasificada
3. Puesto que la característica se selecciona al azar, y por lo tanto no toda la cantidad característica extraída, a resolver el problema de la característica dimensional alta, exceso de montaje adicional se puede prevenir . Sin embargo, las características seleccionadas al azar de las ventajas y desventajas, que afectará a los resultados.


AdaBoost
AdaBoost algoritmo: se reforzarán unas muestras mal clasificadas básicos preclasificador, toda la muestra se pesa de nuevo a la formación básica en virtud de un clasificador. Mientras que la adición de un nuevo clasificadores débiles en cada ronda, hasta una tasa de error suficientemente pequeño predefinido o un número máximo predeterminado de iteraciones alcanzaron .
- modelo aditivo: el número final de la fuerte clasificador es un ponderado promedio de clasificadores débiles.
- algoritmo de distribución hacia adelante: Después de actualizar los resultados del algoritmo es conseguir a través de una ronda de debilidad de los alumnos, utilizando la ronda previa de la debilidad de los alumnos una formación Pesos Pesos débil alumno.
Proceso algoritmo AdaBoost:
1. ¿Cómo calcular una tasa de error de
2 débil coeficiente de peso alumno [alfa]
3. Actualizar los pesos de la muestra D
4. ¿Qué estrategia de combinación

función de pérdida Adaboost
La rueda k-1 y el k-ésimo fuerte aprendiz rueda como:
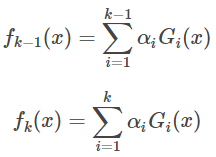
se puede obtener:
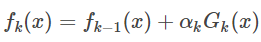
Desde la clasificación de Adaboost función de pérdida es una función exponencial (función exponencial puede ser claro que los datos de clasificación condición correcta o error), por lo que su función de pérdida como
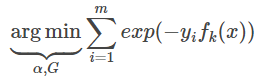
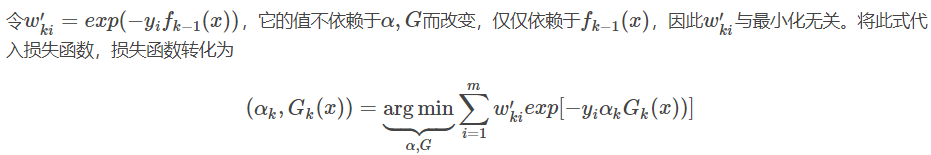
I (x = y) es la función de indicador.
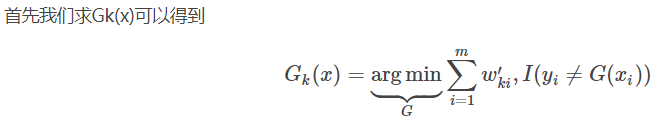

algoritmo de clasificación Adaboost
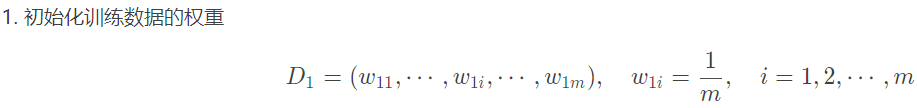

3. Calcular la clasificadores débiles Gk (x) tasa de error de clasificación en el conjunto de entrenamiento;
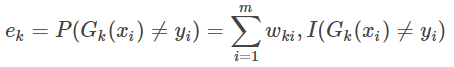
4. clasificadores débiles de k Gk (x) es el factor de ponderación:
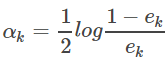
coeficiente peso clasificación binaria, la clasificación se puede ver que si cuanto mayor sea la relación de error e, los clasificadores débiles adecuadas correspondientes a la menor coeficiente α peso, es decir, pequeño coeficiente de peso clasificador débil cuanto mayor es la tasa de error.
5. Actualizar los pesos de datos de entrenamiento
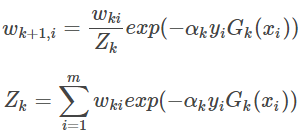

6. estrategia de integración

algoritmo de regresión Adaboost

5. Calcular-ésima k baja tasa de error y los pesos del regresor coeficientes de ponderación
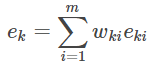
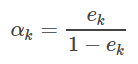

de arriba es la gente Fórmula detallada. Para AdaBoost para recordar:
- Modelo: modelo aditivo, es decir, una pluralidad de clasificadores débiles obtenidos por adición ponderada del resultado final.
- La función objetivo es una función exponencial.
- Aprender algoritmo es un algoritmo por pasos hacia adelante, que es justo después de un dato débil alumno antes de re-entrenamiento a través de una actualización débil alumno.
Los derechos relacionados con el peso de los clasificadores débiles donde un (calculado de acuerdo con la tasa de error), no hay errores de clasificación de pesos de la muestra. Categoría: tasa de error de retorno: el error cuadrático medio.
ventajas y desventajas algoritmo AdaBoost

árbol de impulsar
Además de mejorar el árbol es un modelo de árbol de modelo CART, residuos aptos siguen acercarse al valor verdadero.
Por ejemplo:

algoritmo de árbol de actualización

Aquí minimización del riesgo empírico, para diferentes problemas, diferentes funciones de pérdida. Regresión utilizando la función de pérdida error al cuadrado, la clasificación de la función de pérdida exponencial. problema de decisión general utilizando una función de pérdida general.
Los árboles de regresión mejorar siguiente paso previo a la algoritmo:
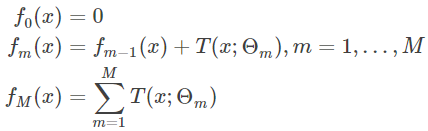
Para los problemas de regresión, de acuerdo con el valor verdadero y el último árbol se reduce al mínimo error al cuadrado, M Solución parámetro árbol θ. Finalmente Simplificar ecuación obtenida (RT) ^ 2 se reduce al mínimo, es decir, el último árbol antes de colocar un árbol residual minimizada.

Flujo de retorno impulsar el árbol

Impulsar árbol y AdaBoost algoritmo
AdaBoost algoritmo usando un algoritmo por pasos hacia adelante, es decir, por la parte delantera a los alumnos débiles tasa de error de ponderaciones de los datos de formación de actualización;
es un algoritmo por pasos hacia adelante, el alumno débil único modelo de árbol de impulsar el árbol utilizado (típicamente CART )
Mejorar las ventajas y desventajas del árbol
Para los árboles de regresión actualización, solo tiene que ajustar residuos del modelo actual .

Gradiente de árbol de impulsar
GBRT es adecuado para tener un método para mejorar cualquier derivado orden de la función de pérdida.
gradiente de actualización
Impulsar árbol utilizando el modelo aditivo para optimizar el proceso de aprendizaje paso por el algoritmo de la etapa anterior. Cuando la función de pérdida es la pérdida cuadrática y la función de índice de pérdida, la optimización de cada paso es muy simple. Sin embargo, para la función de pérdida general a menudo no es tan fácil de optimizar cada paso. Función general pérdida
a este problema, Friedman propuesto algoritmo de árbol de elevación gradiente , que es un método que utiliza un descenso más agudo aproximada, la clave es el uso del gradiente negativo de la función de pérdida de levantar el residual aproximación algoritmo de árbol .

principio algoritmo GBDT

caso de regresión GBDT
mostrar los datos :
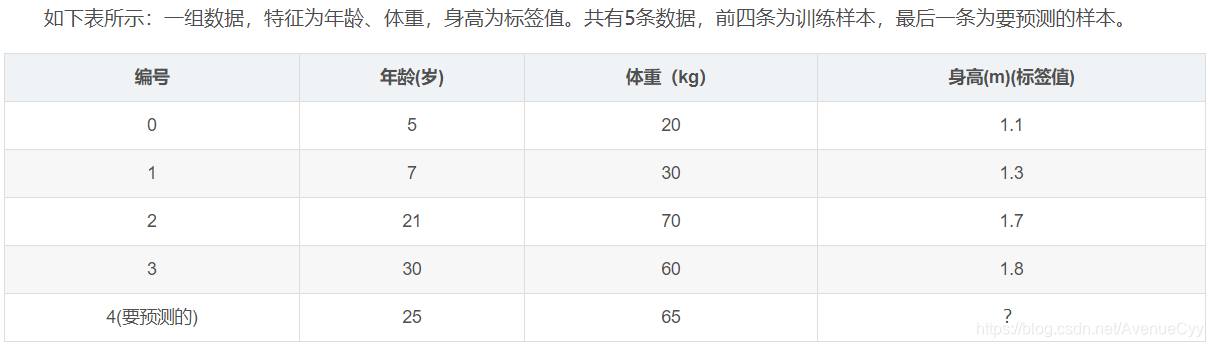
los ajustes de parámetros :

1. Inicializar los débiles aprendiz :

2. 1,2 iteración count = m, ..., M :
El primer paso en la inicialización débil aprendiz, se calcula el valor residual para el montaje.
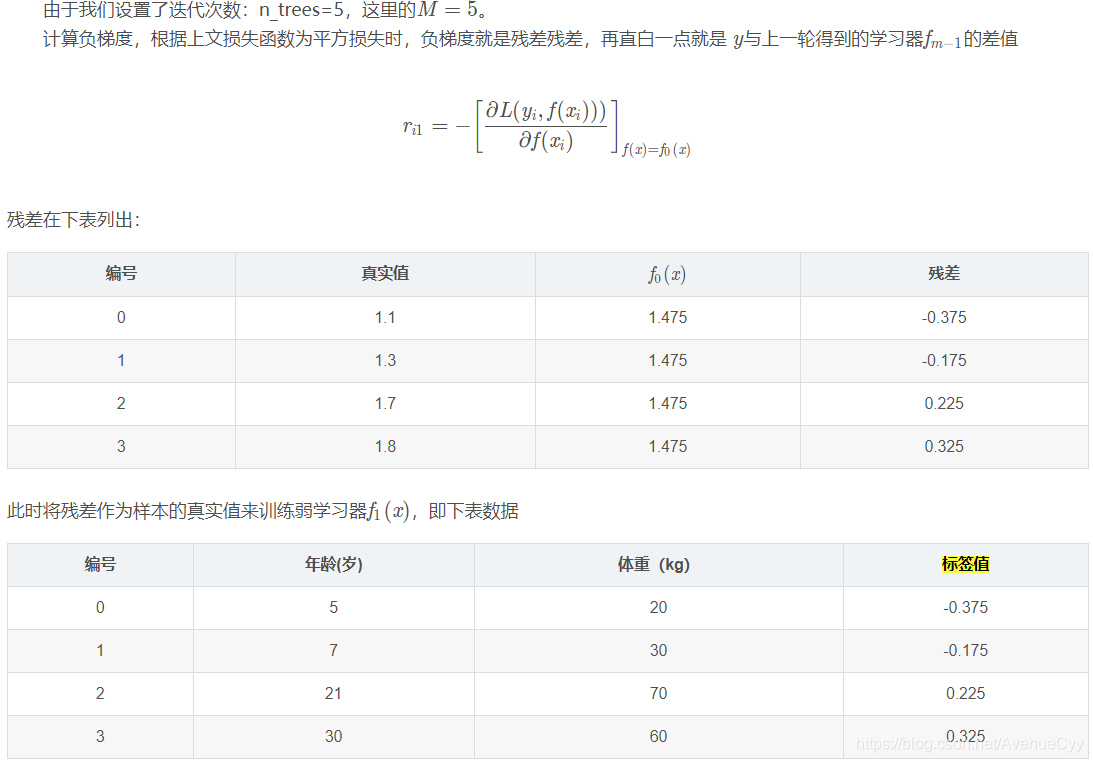
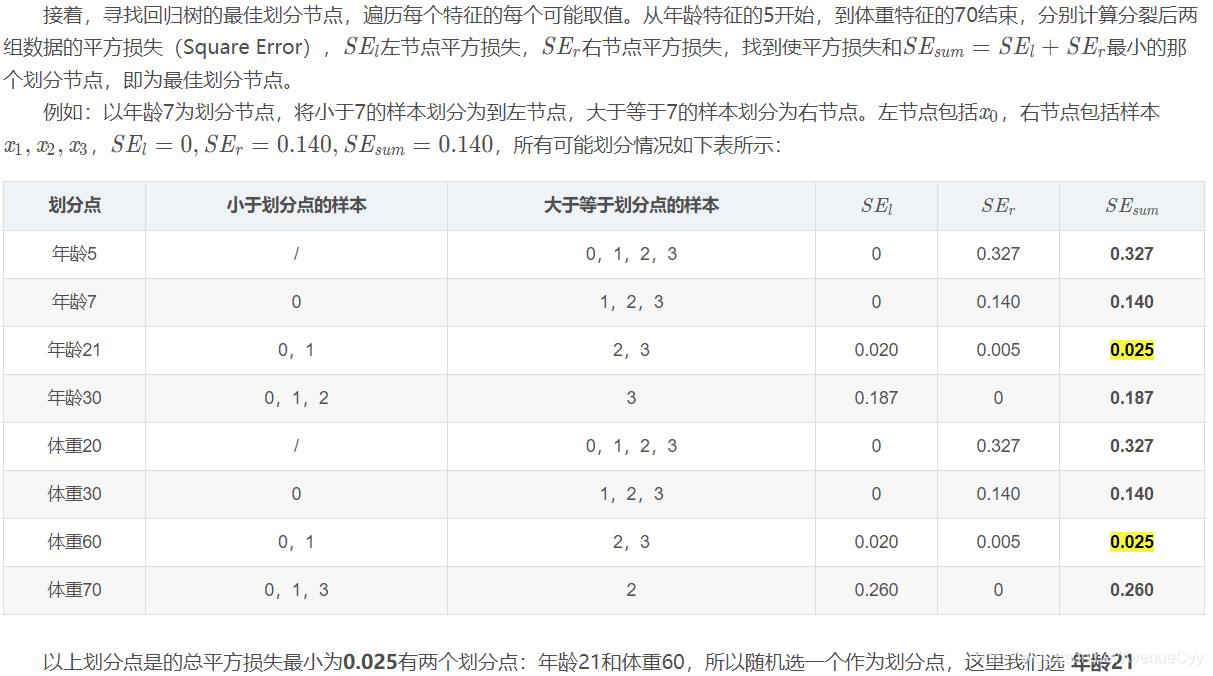
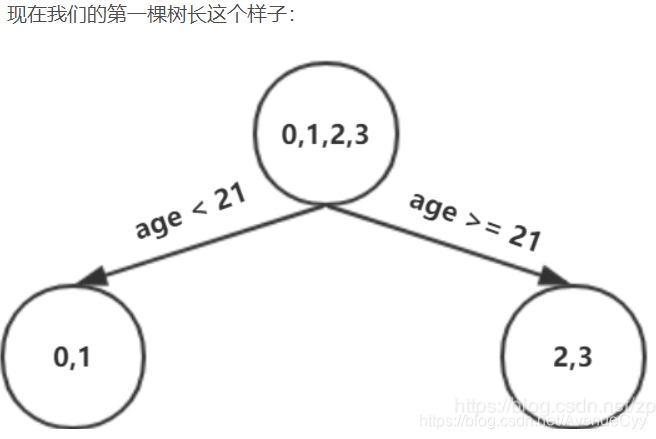
Dado que la profundidad máxima se establece en 3, la profundidad del árbol es ahora sólo 2, es necesario hacer otra división, la división se debe dividir la izquierda y la derecha dos nodos, respectivamente.
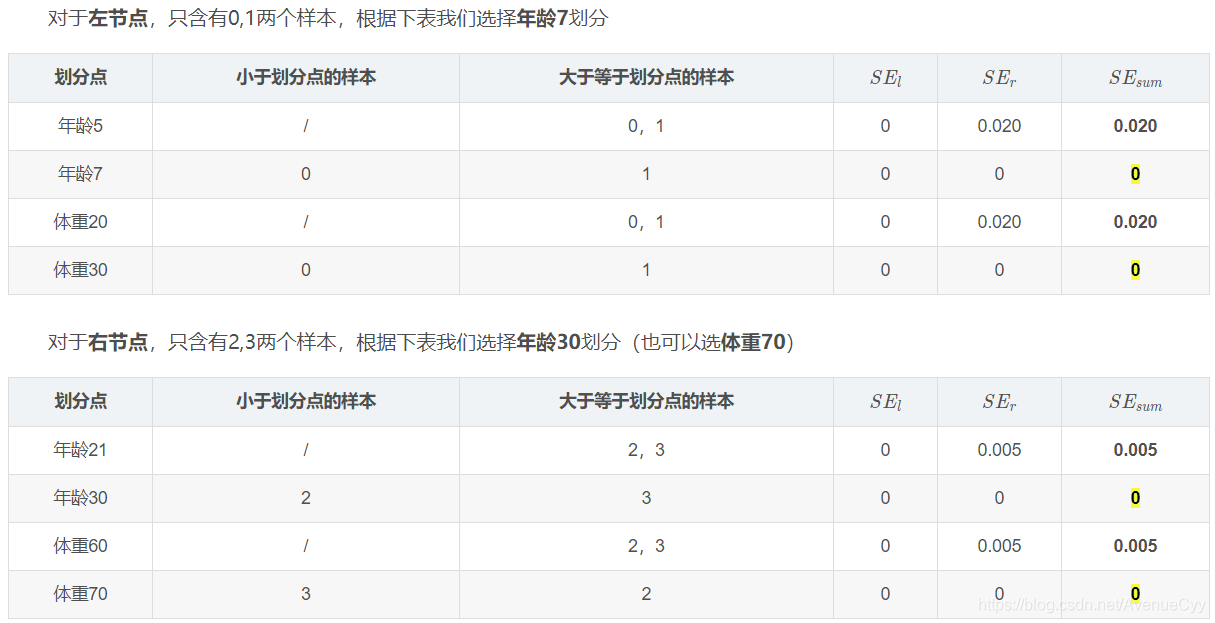
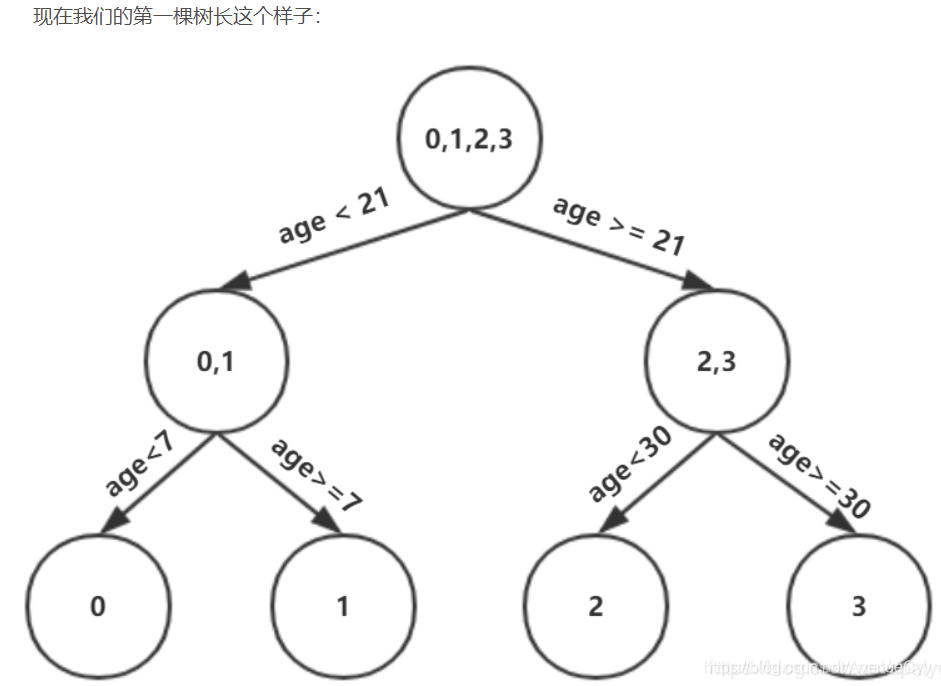
Calcular un primer árbol residual antes de montar resultados.

valor predictivo calculado del árbol.
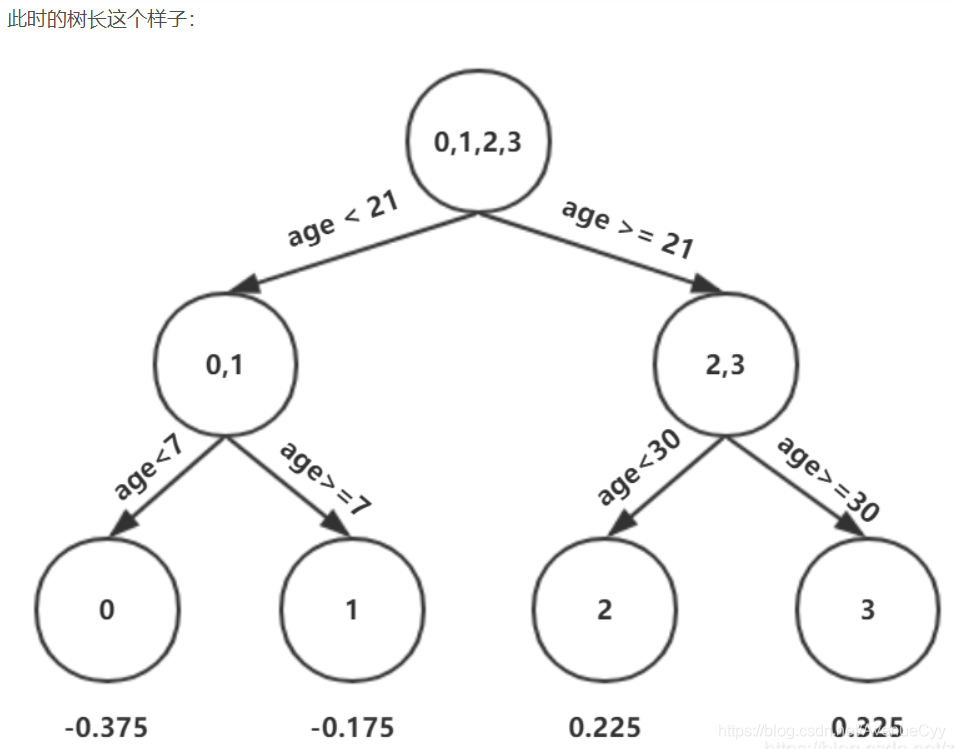
Tasa de aprendizaje :

Debido a que el número de iteraciones es 5, para generar cinco árboles diferentes.
Estos cinco árboles para integrar, obtener el modelo final
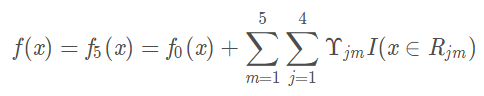

Clasificación GBDT cálculo de Caso
Desde la eliminación de aprendizaje automático algoritmos GBDT destacados de la entrevista Resumen - Parte I

diferencia GBDT y mejorar residuos gradiente alternos de los árboles, y cada grupo tiene el aprendizaje de los parámetros de pesos correspondientes .
Ventajas y desventajas de árbol gradiente de impulsar
Por esta deficiencia se puede utilizar para resolver Xgboost.

referencias
https://blog.csdn.net/weixin_46032351/article/list/3
https://weizhixiaoyi.com/category/jqxx/2/
https://blog.csdn.net/u012151283/article/details/77622609
https: //blog.csdn.net/zpalyq110/article/details/79527653
