Minería de datos: estados modelo de evaluación
Modelo de evaluación antes sólo en la forma de evaluar la precisión de la predicción del modelo, el modelo no encaja encima y por debajo de ajuste de estado a tener en cuenta. En otras palabras, el modelo de acondicionamiento, queremos optimizarlo, y cómo optimizar un estado que depende del modelo actual exceso de ajuste, underfitting y así sucesivamente. Tenemos que ser optimizado para el modelo.
En primer lugar, el modelo de estado
modelo de estado se puede dividir en dos categorías:
- Sobreajuste: modelo eficaz en el conjunto de entrenamiento, el efecto de la diferencia de prueba.
- Underfitting: efecto de modelo en la formación y la prueba no son buenas.
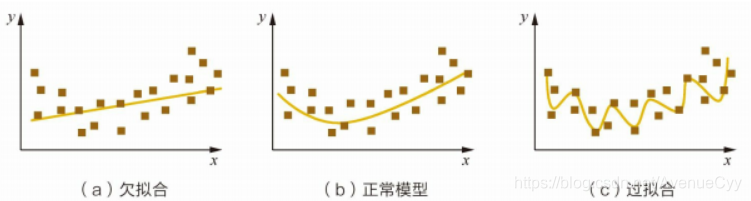
Y este efecto es la exactitud de la evaluación del modelo. Precisión desde la cara posterior, el error es demasiado grande.
Error: diferencia entre la salida y la predicción muestras de salida real de alumno
de acuerdo con la división del conjunto de datos, hay la siguiente definición:
- El entrenamiento de error de diferencia (error de entrenamiento): también conocido como error empírico (empírico de error), el aprendizaje error en el conjunto de entrenamiento.
- Error de test (prueba de error): el aprendizaje de error en la prueba.
- generalización de error (error de generalización): aprendiz errores desconocidos en la nueva muestra.
Significado modelo de formación: obtener la generalización de error es pequeño aprendiz. Sin embargo, la nueva muestra desconoce de antemano, realmente hacer es tratar de hacer que se reduzca al mínimo el error de experiencia. Pero tienen que ser claras, incluso si la tasa de errores de clasificación de 0, 100% de precisión del alumno, no será capaz de obtener buenas predicciones sobre la nueva muestra. En realidad, esperamos que en la nueva muestra puede mostrar una muy buena estudiante.
Con este fin, un estudio debe ser aplicable a todas las muestras posibles de la "ley universal" de la muestra de entrenamiento tanto como sea posible, a fin de hacer el juicio en la cara de las nuevas muestras. Debido a que la generalización de error no se puede medir, por lo tanto, vamos a probar error típicamente aproximadamente equivalente a la generalización de error.
En segundo lugar, la desviación y la varianza
¿Cómo evaluar el estado de nuestro modelo, se utiliza una curva de aprendizaje aquí. Con el aumento de tamaño de la muestra, que puede reflejar los cambios en el sesgo de datos de datos de entrenamiento y de prueba y la varianza.
Generalmente, se utiliza la desviación modelo (Bias) y el modelo de varianza (varianza) para describir la generalización de rendimiento, que se llama skew - descomposición de la varianza (descomposición sesgo-varianza).
Desviación : Diferencia entre el valor medio obtenido a partir de todo el tamaño de la muestra de m conjuntos de datos de entrenamiento para entrenar el modelo y la salida de toda la producción del modelo real. La desviación es generalmente porque hemos hecho las suposiciones erróneas sobre el aprendizaje algoritmo causado. Medir el aprendizaje algoritmo para predecir el grado de desviación de las expectativas y los resultados reales, que caracteriza el aprendizaje propio algoritmo encajan capacidad . Modelo en comparación con otros modelos, se compararon diferentes modelos de la exactitud de entrenamiento y prueba.
Varianza : varianza obtenida de todo el tamaño de la muestra de los datos de entrenamiento conjunto de m salidas de todos los modelos de formación. En pocas palabras, las medidas de estudio del cambio en el rendimiento del mismo tamaño como resultado de los cambios en el conjunto de entrenamiento, que caracteriza el cambio en el liderazgo conjunto de datos a los cambios en el rendimiento de aprendizaje, es decir, el aprendizaje de la estabilidad del algoritmo . En comparación con el modelo en sí, el mismo modelo de precisión en el conjunto de entrenamiento y de prueba para la comparación.
Ruido : Expresión de la deseada límite inferior en el error de generalización de la tarea actual en cualquier algoritmo de aprendizaje que se puede alcanzar, es decir, caracteriza a los datos de indicador de error establecen en sí .

Seleccionar el modelo, evaluar y optimizar - en
El siguiente gráfico bien puede comprender la diferencia entre la desviación y la varianza **. Eso significa que el nivel de modelo de desviación precisión; medios de estabilidad que el nivel de modelo de varianza **.
Suponiendo que una dosis es un modelo de aprendizaje de máquina para predecir una muestra. Hit la posición de ojo de buey representa la precisión de la predicción, mayor es la desviación del centro de la diana más representativa de error de predicción.
Nos obtener una formación muestra de tamaño n m del conjunto, n los modelos de formación, las predicciones realice en la misma muestra, correspondiente a n veces hicimos el rodaje, el resultado de tiro como se muestra por n muestras.
Nuestro resultado más deseado es el resultado de la esquina superior izquierda, el tiro y resultados precisos y enfoque, lo que indica modelos sesgo y la varianza son pequeñas;
parte superior derecha, aunque el centro de la diana en torno a los resultados de la toma, pero la distribución más dispersa, lo que indica que las desviaciones más pequeñas modelo Sin embargo, las variaciones más grandes;
del mismo modo, el modelo inferior izquierda describen pequeña varianza, mayor es la desviación;
figura inferior derecha muestra un gran modelo de varianza, las desviaciones más grandes.
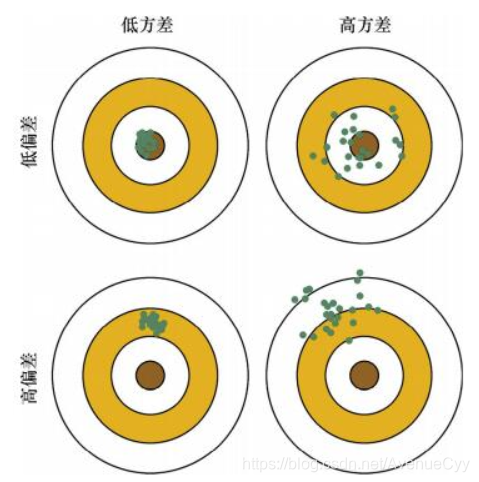
Por lo tanto, cuando queremos modelo de sesgo y la varianza son relativamente pequeñas.
Evaluación del modelo: Modelo de Evaluación de estado
Sobreajuste es: pequeña desviación, la varianza es grande.
Underfitting es: Desviación grande y pequeña variación.
Por lo tanto, el ajuste del modelo de estado que es un compromiso entre sesgo y la varianza.
En tercer lugar, la curva de aprendizaje
Por precisión y validación cruzada del conjunto de entrenamiento se extrae cuando diferentes conjuntos de entrenamiento pueden ser vistos en el nuevo modelo de datos de rendimiento, y luego determina si el modelo de varianza demasiado alta o desviación, y el aumento del conjunto de entrenamiento puede reducirse si exceso de ajuste. 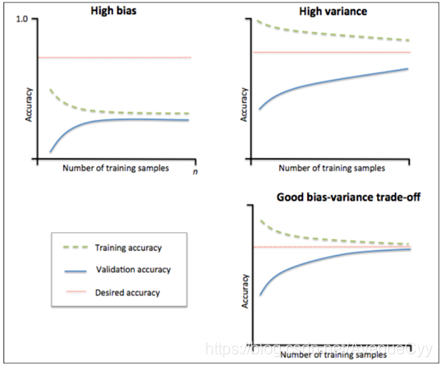
Cuando la formación y equipos de prueba de la convergencia y la exactitud de las converge baja precisión, con el clasificador de referencia (línea roja) en la desviación de comparación es alta.
La esquina superior izquierda representa el alto clasificador desviación, la exactitud de los conjuntos de entrenamiento y validación son muy bajos, es probable que sea menos conveniente.
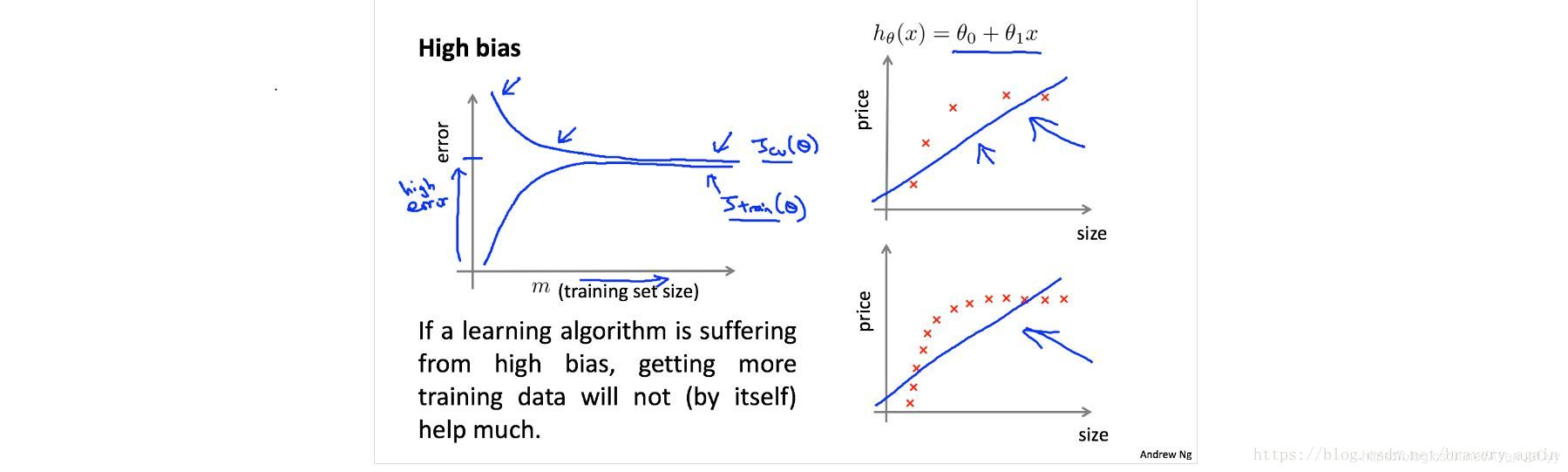
Entrenamiento y prueba la exactitud de la clasificación de referencia tiene una precisión similar, lo que indica un sesgo más bajo, pero la exactitud de la brecha en la prueba y el conjunto de entrenamiento es grande de alta varianza,.
esquina superior derecha de la varianza es alta, la precisión de la formación y conjuntos de validación mucha diferencia, es exceso de montaje.
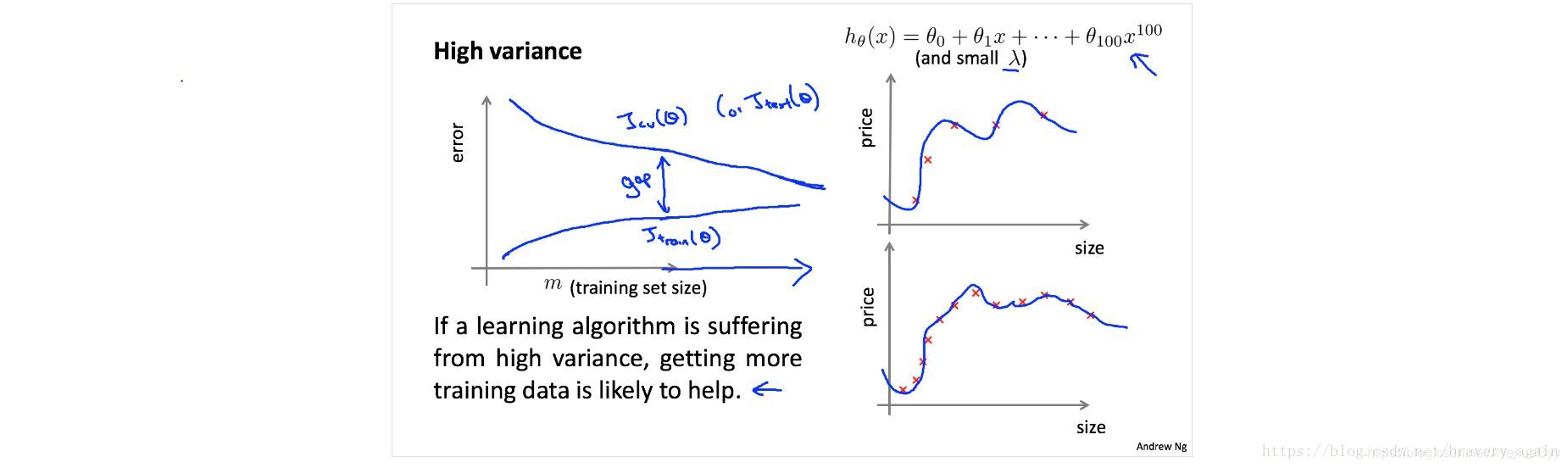
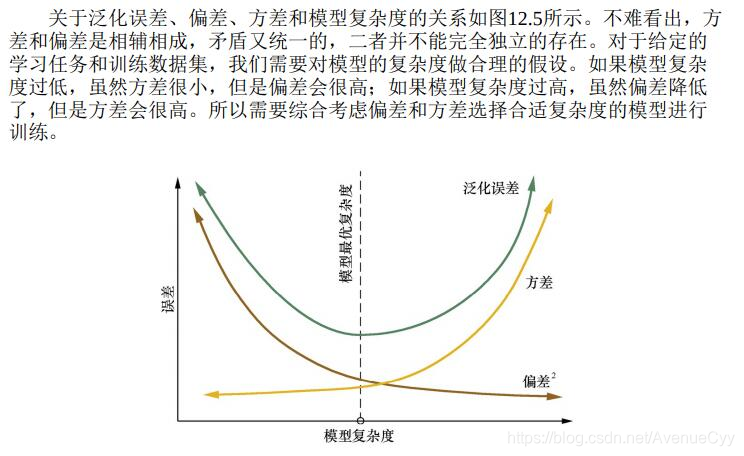
Los modelos más complejos, la capacidad de aprendizaje, por lo que el más pequeño es el error en el conjunto de entrenamiento. Sin embargo, para el error de prueba, cuando se reduce en cierta medida, el modelo puede ser porque no han sido demasiado complejos para ajuste fenómeno, pero los aumentos de error. En este momento, por la reducción de dimensionalidad, el aumento de regularización y otras medidas para reducir el exceso de montaje.
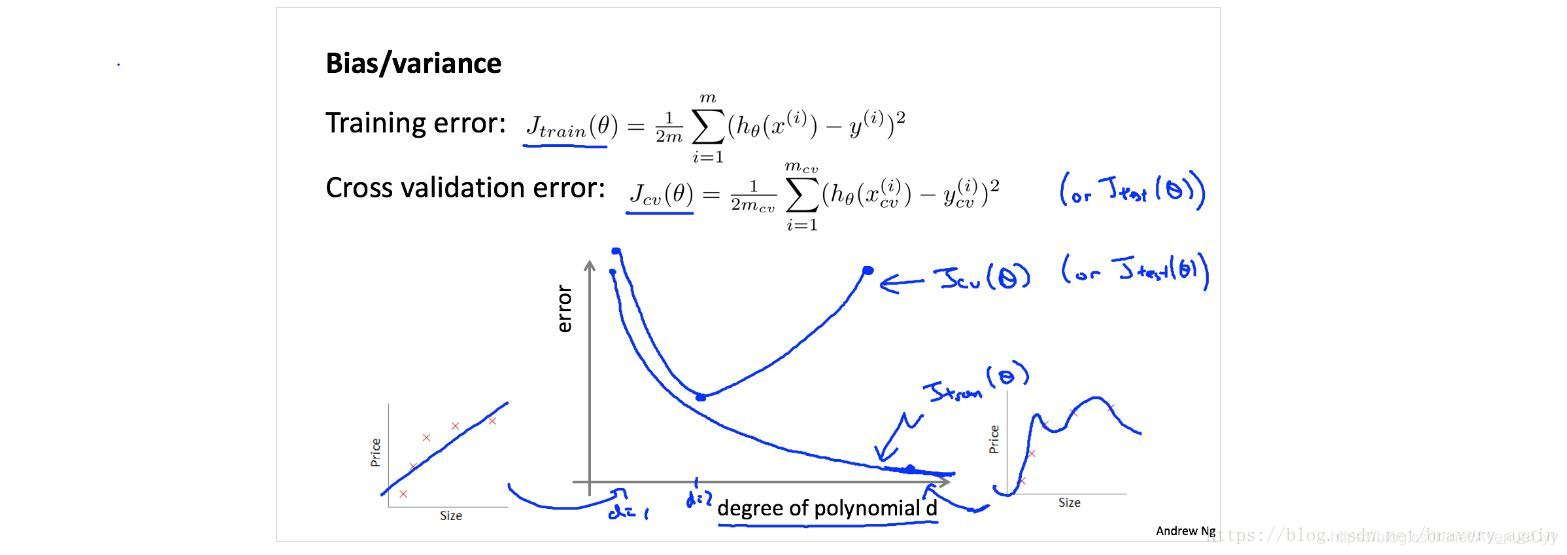
| medida | Para hacer frente a la situación |
|---|---|
| Sobreajuste: desviación baja, alta varianza | El aumento de la cantidad de datos, la reducción de la complejidad del modelo (reducción del número de funciones, aumenta regularización) |
| Underfitting: desviación alta, baja varianza | Aumentar la cantidad de datos no es válido. Mejorar la complejidad del modelo (el número de funciones, aumenta, reduciendo la regularización) |
A partir de la curva de aprendizaje, puede ir en línea para encontrar sklearn oficial.
