directorio
0 Introducción
la entrada de base cero de la minería de datos - Pronóstico del precio de la transacción de automóviles usados de la lucha por el título con los datos de
previsión del precio de la transacción de automóviles usados de la lucha por el título de entender - cero de entrada basada en la minería de datos
de entrada cero basado en la minería de datos - Pronóstico del precio de la transacción de automóviles usados de análisis de datos
cero Fundamentos del Data Mining - precio de transacción prevista del coche de segunda mano cuenta con la ingeniería
de entrada cero a base de de minería de datos - el precio de la transacción de coches ajuste de los parámetros de modelado previsión establecida
Este documento hace hincapié en la integración de las diversas formas en que los resultados del modelo.
1 Introducción
modelo de fusión es una parte importante del juego tarde, hablando en términos generales, los siguientes tipos de camino.
-
fusión ponderada simple:
- Return (probabilidad clasificación): la fusión media aritmética (Media aritmética), la fusión media geométrica (media geométrica);
- Categoría: Votación (votación)
- Integral: Ordenar fusión (Rango de promedio), la integración de registro
-
apilar / mezcla:
- La construcción del modelo de varios niveles y, a continuación, se ajusta usando el resultado predicho predicción.
-
aumentar / embolsado (ya utilizado en xgboost, Adaboost, en GBDT):
- Muchos árboles método de actualización
teoría 2 Stacking
2.1 ¿Qué es apilamiento
Brevemente, el estudio es que al apilar una pluralidad de los estudiantes de base con los datos de entrenamiento inicial, estos varios resultado predicción aprendiz como un nuevo conjunto de entrenamiento para aprender un nuevo aprendiz.
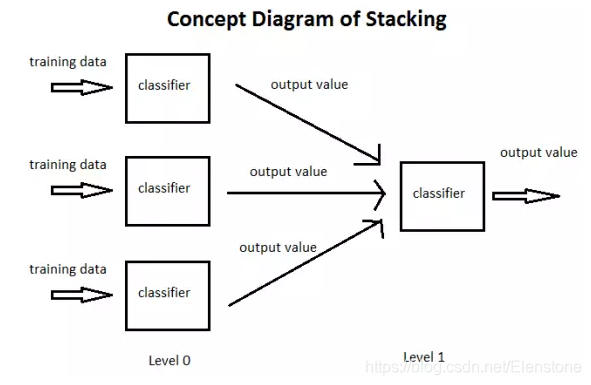
El método utiliza cuando el aprendiz individual junto llama estrategia combinada. Para problemas de clasificación, podemos optar por utilizar la salida de la mayor parte del método de votación clase. Para los problemas de regresión, podemos clasificar la salida de los resultados promedio.
Dicho lo anterior método de votación y el método de promedio es muy eficaz combinación de estrategias, hay una combinación Otra estrategia es utilizar un algoritmo de aprendizaje automático para combinar los resultados de dispositivo individual de aprendizaje de máquina, este método es apilable.
En el proceso de apilamiento, llamamos a la primaria alumno aprendiz individual, el alumno es llamado por la unión o el aprendizaje que aprende miembros secundario (meta-alumno), los datos del alumno secundarios utilizados para la formación del conjunto de entrenamiento se conoce como el secundario. El secundario está en el conjunto de entrenamiento usando un conjunto de entrenamiento de aprendiz primaria obtenida.
2.2 ¿Cómo se han apilado
Sandía libro dice:

- Proceso 1-3 está capacitado aprendiz individual, que es el alumno primaria.
- 5-9 es un proceso que utiliza una persona que aprende es entrenado resultados más predecibles, como resultado del conjunto de entrenamiento para predecir el alumno secundario.
- 11 es el resultado del proceso de formación de un alumno primaria predijo el aprendizaje secundario, un modelo que finalmente se entrenan.
2.3 modo de apilamiento de explicar
En primer lugar, comenzamos con un 'no tan correcta ", pero fácil de entender el método de apilamiento charla.
El apilamiento es el modelo es esencialmente una estructura jerárquica, donde la simplicidad, sólo dos análisis de apilamiento. Supongamos que tenemos dos grupos modelo Model1_1, Model1_2 y un modelo secundario Modelo2
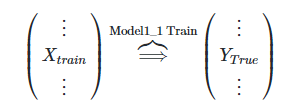
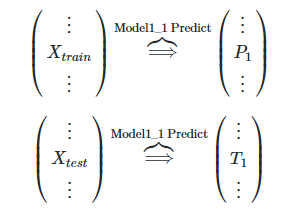
Paso 1. modelo il Model1_1, conjunto de entrenamiento de formación de tren, entonces la etiqueta para el tren y la prueba de las columnas de predicción, respectivamente, P1, T1
Model1_1 modelo de formación:
Modelo Model1_1 después del entrenamiento en cada tren y la prueba de la predicción, las etiquetas predichos se obtienen Pl, Tl
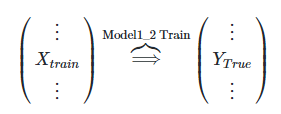
el Paso 2. modelo il Model1_2, conjunto de entrenamiento de formación de tren, entonces la etiqueta para el tren y probar las columnas de predicción, respectivamente, es P2, T2
Model1_2 modelo de formación:
Modelo Model1_2 después del entrenamiento en cada tren y poner a prueba la predicción para obtener las etiquetas predichos son P2, T2
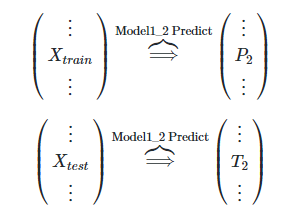
el Paso 3. respectivamente la P1, P2 y T1, T2 se combinaron para dar un nuevo conjunto de entrenamiento y ensayo de deformación TRAIN2, test2.
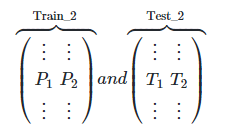
luego a modelo real secundario Modelo2 etiquetados formación de conjunto de entrenamiento, caracterizado formación TRAIN2, test2 predicción, para dar el conjunto prueba final predicho barra de pestañas
.
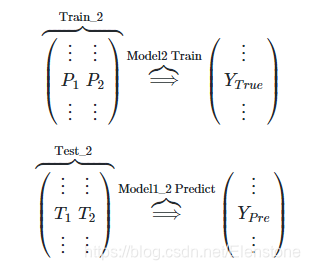
Esto es lo que apilan dos capas de una idea básica de la idea original. Además de un modelo de capas, la capacitación en los resultados sobre la base de diferentes modelos predicen, lo que resulta en un modelo predictivo final.
esencia de apilamiento es una idea tan sencilla, sino directamente lo que a veces para el caso si la distribución formación y equipos de prueba no es tan consistente es un pequeño problema, el problema radica en la etiqueta de la formación modelo inicial reutilización etiqueta verdadera re-entrenamiento, es, sin duda, dar lugar a algunos maqueta de tren exceso de ajuste, por lo que quizá capacidad de generalización del modelo en el set o el efecto de prueba habrá un cierto descenso, por lo que ahora la pregunta es cómo reducir la reconversión de la naturaleza exceso de ajuste aquí estamos por lo general dos métodos.
- modelos secundarios trate de elegir un modelo lineal simple
- Una validación cruzada K-fold


códigos ver mi Github
