K-significa introducción
K-means es un algoritmo de agrupamiento no supervisado, que divide las muestras en grupos de K de acuerdo con la distancia entre los datos de cada muestra. (Es decir, categorías K) Después de dividirse en grupos K, el efecto deseado es que los puntos en cada grupo estén lo más cerca posible, y la distancia entre grupos sea lo más grande posible.
Flujo de algoritmo
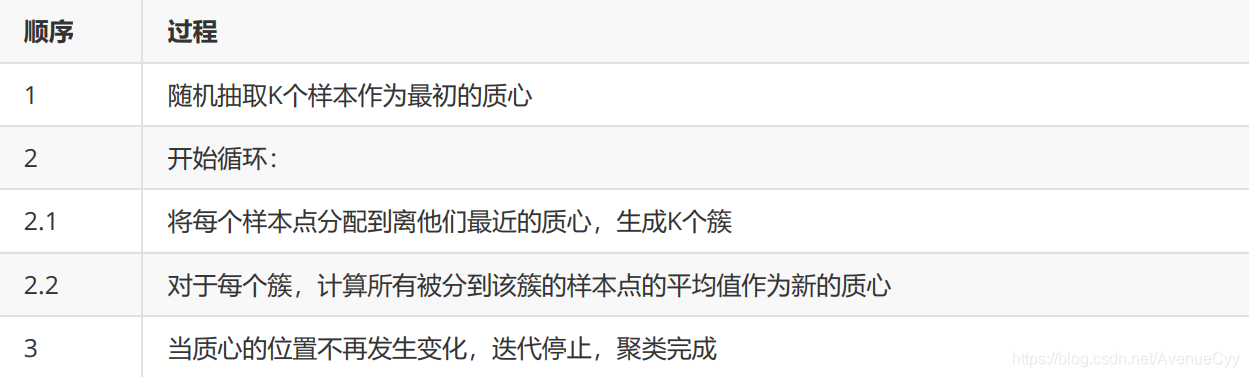
Como se muestra a continuación.
- K muestras se seleccionan aleatoriamente como el centroide inicial. De esta manera, hay K diferentes grupos.
- Calcule el valor medio de todos los puntos de muestra en cada grupo y use este punto medio como el nuevo centroide.
- Calcule la distancia de todas las muestras a estos centroides y seleccione el punto más cercano al centroide de un grupo como el nuevo punto de muestra en el grupo. (Debido a que el centro de masa en el grupo cambia, es necesario redistribuir los puntos de muestra en cada grupo).
- Repita 2-3 hasta que la posición del centro de masa ya no cambie, deje de iterar y complete la agrupación.

Se puede ver aquí que, dado que el centroide se selecciona aleatoriamente, aunque el efecto deseado se puede lograr a través de iteraciones continuas, el costo de cálculo será muy grande. Al mismo tiempo, se calcula la distancia de todas las muestras al centroide, lo que indudablemente aumenta El costo de capacitación, por lo tanto, ha producido múltiples algoritmos de optimización de K-means.
K-significa optimización
K-Means ++ inicialización y optimización
La estrategia del algoritmo K-Means ++ para inicializar el centroide es la siguiente. (Se siente como una proyección de los puntos centroides iniciales primero ...)

Optimización de cálculo de distancia K-Means elkan K-Means
La idea de usar el algoritmo de elkan K-Means es usar la naturaleza del triángulo cuya suma de dos lados es mayor o igual que el tercer lado, y la diferencia entre los dos lados es menor que el tercer lado , para lograr el propósito de reducir el cálculo de la distancia.
Las siguientes son las dos reglas

utilizadas por el algoritmo K-Means de elkan: Usando las dos reglas anteriores, la velocidad de iteración del algoritmo de agrupación K-Means tradicional se puede mejorar en cierta medida. Sin embargo, si las características de la muestra son escasas y faltan valores , el algoritmo no se puede usar porque algunas distancias no se pueden calcular
Big Batch Optimizado Mini Batch K-Means
Incluso si se utiliza el algoritmo optimizado de elkan K-Means, la sobrecarga computacional es muy grande. Especialmente en esta era de big data. Por lo tanto, surgió el algoritmo Mini Batch K-Means. (Algunas muestras se usan para cálculos múltiples para reducir la velocidad de carrera y mejorar la precisión)

Medida de similitud
Después de la agrupación, se requiere que la similitud de las muestras dentro de las agrupaciones sea grande, y la similitud entre las agrupaciones es pequeña. Es decir , la diferencia dentro del clúster es pequeña y la diferencia fuera del clúster es grande . Esta similitud / diferencia generalmente se mide por la distancia desde el punto de muestra a su centroide.
Para un grupo, cuanto menor es la suma de las distancias desde todos los puntos de muestra al centro de masa, creemos que cuanto más similares sean las muestras en este grupo, menor será la diferencia dentro del grupo.
Las medidas de distancia son generalmente las siguientes. Generalmente elegimos la distancia euclidiana.
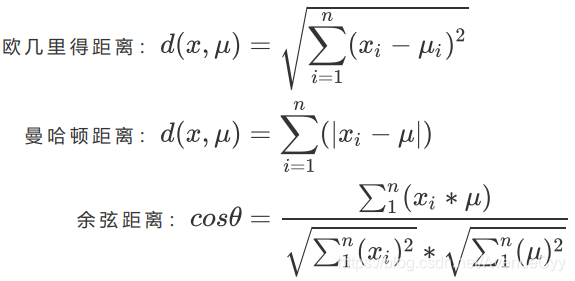
¿K-means tiene una función de pérdida?
Lo que KMeans busca es encontrar un centroide que minimice la suma de cuadrados dentro del grupo. Al ver la minimización, lo primero que viene a la mente es la optimización de la función de pérdida, pero a través de la siguiente descripción, podemos saber que debido a que K-means y los árboles de decisión no necesitan resolver parámetros, K-means y los árboles de decisión no tienen función de pérdida.

Índice de evaluación del algoritmo de agrupamiento
Debido a que el objetivo final de la clasificación es: pequeñas diferencias dentro de los grupos y grandes diferencias fuera de los grupos , podemos medir el efecto de la agrupación midiendo las diferencias dentro de los grupos .
Anteriormente, usábamos ** para minimizar la suma de cuadrados dentro del grupo, ** para medir esto. Sin embargo, este indicador tiene los siguientes problemas:
- No está acotado . No sabemos cuál es la suma de cuadrados dentro del grupo el límite de este modelo.
- El cálculo se ve fácilmente afectado por la cantidad de características . En vista de las características del cálculo de K-medias, cuando los datos se hacen cada vez más grandes, la cantidad de cálculo explotará, lo que no es adecuado para evaluar el modelo una y otra vez.
- Susceptible a ultra-parámetro K . Cuanto mayor sea K, menor será la suma de los cuadrados en el grupo, pero no es que cuanto mayor sea K, mejor será el efecto de agrupamiento.
- Hay suposiciones sobre la distribución de datos . Se supone que los datos satisfacen la distribución convexa (es decir, los datos se ven como una función convexa en una imagen plana bidimensional), y se supone que los datos son isotrópicos, es decir, los atributos de los datos son diferentes. La dirección representa el mismo significado . Pero los datos reales a menudo no son el caso. Por lo tanto, el uso de la suma de cuadrados dentro de un grupo como un índice de evaluación hará que el algoritmo de agrupación funcione mal en algunos grupos alargados, grupos circulares o colectores de forma irregular.
Los siguientes dos casos se utilizan para evaluar el algoritmo de agrupamiento.
Cuando se conoce la etiqueta real
Factor de contorno
Aunque no ingresamos etiquetas reales en el clúster, esto no significa que los datos que tenemos no deben tener etiquetas reales, o no debe haber información de referencia. Si tenemos etiquetas reales, preferimos usar algoritmos de clasificación. Pero no excluye la posibilidad de que aún podamos usar algoritmos de agrupamiento.
Si tenemos datos sobre la agrupación real de las muestras, podemos medir el efecto de la agrupación en los resultados del algoritmo de agrupación y los resultados reales. ( Esto es bueno para entender. Generalmente, se hará directamente por clasificación. Las siguientes etiquetas verdaderas son desconocidas para ser procesadas ) . Los siguientes tres métodos se usan comúnmente:

Cuando la etiqueta real es desconocida
La agrupación depende enteramente de evaluar la densidad de las agrupaciones (pequeñas diferencias dentro de las agrupaciones) y el grado de dispersión entre las agrupaciones (grandes diferencias fuera de las agrupaciones) para evaluar el efecto de la agrupación. El coeficiente de contorno es el índice de evaluación del algoritmo de agrupación más utilizado. Se define para cada muestra, y se puede medir al mismo tiempo: de

acuerdo con los requisitos de la agrupación, "la diferencia dentro del grupo es pequeña, la diferencia fuera del grupo es grande", esperamos que b sea siempre mayor que a, y cuanto mayor sea mejor .
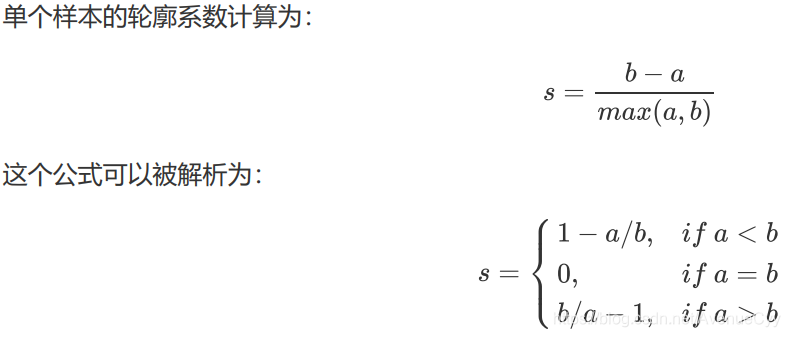
Después de analizar la fórmula, el rango del coeficiente de contorno es (-1,1). Cuanto más cercano sea el coeficiente de contorno a 1, mejor será el efecto de agrupamiento, y cuanto más cerca de -1, peor será el efecto de agrupamiento.
En sklearn, usamos la clase silhouette_score en las métricas del módulo para calcular el coeficiente de contorno. Devuelve el promedio de los coeficientes de contorno de todas las muestras en un conjunto de datos . Pero también tenemos el silhouette_sample en el módulo de métricas . Sus parámetros son consistentes con los coeficientes de contorno, pero devuelve los coeficientes de contorno de cada muestra en el conjunto de datos .
Las ventajas y desventajas del coeficiente de la biblioteca de ruedas :

Índice Kalinsky-Harabas
Además de los coeficientes de contorno más comúnmente utilizados, también tenemos el índice de Kalinski-Harabaz (CHI para abreviar, también conocido como el estándar de relación de varianza), el índice de Davis-Burdin y la matriz de contingencia pueden usarse .

Aquí nos centramos en el Índice Kalinsky-Harabas. Cuanto mayor sea el índice de Calinski-Harabaz, mejor. La fórmula es la siguiente: cuanto
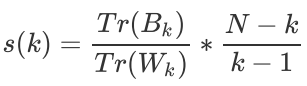
mayor es la dispersión entre grupos, mayor es Bk; menor es la dispersión dentro de los grupos, menor es Wk. Por lo tanto, cuanto mayor sea el valor de esta fórmula, mejor será el propósito de la agrupación: la diferencia dentro del grupo es pequeña y la diferencia fuera del grupo es grande.

El índice de calinski-Harabaz no tiene límites, y la agrupación de datos convexos también mostrará una altura imaginaria. Pero en comparación con el coeficiente de contorno, tiene una gran ventaja, es decir, el cálculo es muy rápido (es rápido con el cálculo de la matriz ).
Comparación entre el algoritmo K-Means y KNN
Similitudes : 1. El algoritmo de agrupación K-Means y KNN (algoritmo vecino más cercano a K) encuentran el punto más cercano a un punto determinado, es decir, ambos usan la idea del líder más cercano- Diferencias: el
algoritmo de agrupación de K-Means es un algoritmo de aprendizaje no supervisado sin salida de muestra; KNN es un algoritmo de aprendizaje supervisado con la salida correspondiente de la categoría
1. K-Means encuentra el mejor centroide de las categorías K en el proceso iterativo, por lo tanto Determine las categorías de clúster K;
2.KNN es encontrar los puntos K más cercanos a un cierto punto en el conjunto de entrenamiento
Ventajas y desventajas del algoritmo K-Means
- Ventajas:
1. Velocidad de convergencia del algoritmo simple y fácil de entender (velocidad de convergencia ...)
2. Fuerte capacidad de interpretación del algoritmo - Desventajas:
1. La selección del valor K generalmente requiere experiencia a priori (experiencia experta)
2. Usando el método iterativo, los resultados obtenidos son solo óptimos locales
3. Dado que la distancia desde el centroide a todos los puntos necesita ser calculada, es más sensible al ruido y puntos anormales
4. Si la cantidad de datos de cada categoría oculta está seriamente desequilibrada, o la varianza de cada categoría oculta es diferente, el efecto de agrupamiento no es bueno
Referencias
https://www.bilibili.com/video/BV1vJ41187hk?from=search&seid=15670729090205346470
https://blog.csdn.net/weixin_46032351/article/details/104565711
