Preface:
Remember that the code was not learned how algorithms, but learn to do problems.
Algorithm is able to really learn to teach others.
Cited Example: Given two strings S and T, if T Q S belongs to the sub-string.
This is the basic string matching problem, we can easily think of brute force method.
Brute force method:
For ease of description and understanding, we call the main strings strings S, T string of pattern strings.
In the beginning the main string enum pattern string, if the character is the same match continued backwards, different starting point is to update and re-start a match.
Definition of a pointer i, j
i: is the i-th main string match character
j: the former has matched string pattern j characters
The initial state
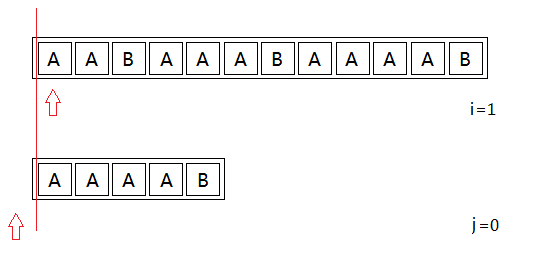
Main string of characters to be matched s [i] = 'A' and a mode character string identical t [j + 1] = 'A', the match succeeds. After the pointer moves, i ++; j ++.
Similarly, then after a match,
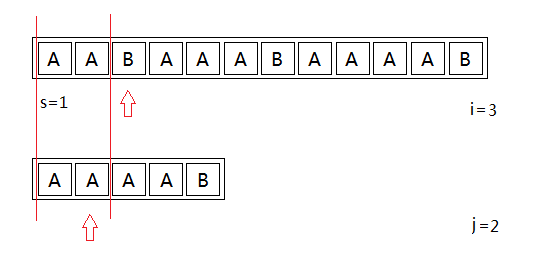
S main string to be matched character string of the next character t [i] = 'B' and Mode [j + 1] = 'A ' different from, the match fails. Update enumeration starting point i = 2, the matching is restarted, until the pattern until the number of characters matched string j == len (pattern string length).
Estimated time complexity: O (n * m)
KMP algorithm:
The nature of KMP algorithm is optimized brute force method. Deletion operation is invalid, the re-use information available.
Let's continue the simulation of the process described above,

After several updates starting point and match, we get more than the state. In accordance with the brute force method of procedure, at the moment the match fails, the i = 4, starting from the enumeration, thus updating the starting point to i = 5.
But do not actually need such an operation, we observed:
设k,s[i-k]..s[i-2]s[i-1]=t[1]..t[k-1]t[k](s<i-k<=i-1)
If k does not exist, then any point d (s <d <= i-1) as the starting point can not match the pattern string. ①
If k exists:
If t [k + 1]! = S [i], it can not match the pattern string. ②
若t[k+1]=s[i],则有可能以i-k为起点匹配出模式串。
①:都会因s[i-1]或之前的某个字符失配而断掉。
②:会因s[i]失配而断掉。

图1:不存在满足条件的k,从任意起点p(s<p<=i-1)都因某字符q匹配不到i-1

图2:存在满足条件的k,但t[k+1]!=s[i],因字符i匹配不到i-1
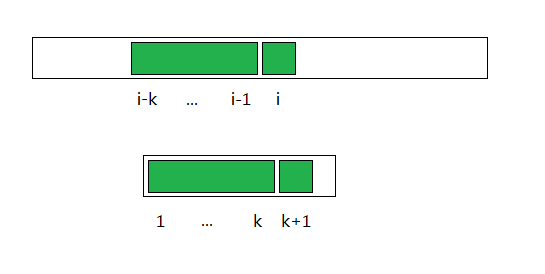
图3:既存在满足条件的k,t[k+1]=s[i],那么则有可能以i-k为起点匹配出模式串
因而,当匹配失败时,只需找到满足条件的k的最大值。若存在,主串向后匹配,以i-k为起点;若不存在,主串也向后匹配,寻找新的起点。
请思考,选择最大的k是否会漏掉可能的匹配起点?(答案见下文)
算法实现:
我们知道:s[s]..s[i-2]s[i-1]=t[1]..t[j-1]t[j]
因为s<i-k<=i-1,
所以s[i-k]..s[i-2]s[i-1]=t[j-k+1]..t[j-1]t[j]
因而我们只需要在模式串已匹配部分寻找k即可。
由于通常情况下模式串长度比较小,我们可以初始化出模式串中每个位置的k值。我们常用next[]数组存储模式串中每个位置的k值。
那么如何求得next[i]?
其实我们求得next[i]的过程等价于用模式串匹配自身的过程。为位置i寻找最长前缀后缀,可以想成用i前面的字符串去匹配模式串,到i最多能够匹配多长。这样以来问题就迎刃而解了,我们只需要进行两次匹配,一次求得next数组,一次匹配模式串。
注意:满足条件的k是指由i-k到i-1能够匹配模式串前k个字符,同时s[i+1]=t[k+1]!
算法流程:
1.初始化指针i=1,j=0
2.循环枚举主串待匹配字符i
3.枚举一个字符就对模式串进行一次匹配:
若s[i]=t[j+1],则模式串第j+1个字符匹配成功,i++;j++
若s[i]!=t[j+1],匹配失败,则更新j等于最长的满足条件的k,i++
4.当j=len时,匹配成功,跳出循环。
代码如下:
1 void get_next() 2 { 3 int i,j; 4 j=0; 5 next[1]=0; 6 for(i=2;i<=lent;i++){ 7 while(j>0&&t[j+1]!=t[i])j=next[j]; 8 if(t[j+1]==t[i])j++; 9 next[i]=j; 10 } 11 } 12 13 void KMP() 14 { 15 int i,j; 16 j=0; 17 for(i=1;i<=lens;i++){ 18 while(j>0&&t[j+1]!=s[i])j=next[j]; 19 if(t[j+1]==s[i])j++; 20 if(j==lent)ans[++cnt]=i-j+1; 21 } 22 }
next数组的求得很关键,这几天要期末考试,学业繁重。日后加图完善!