Introduction
The KMP algorithm is a string matching algorithm. String matching is widely used, such as web page text search, finding all occurrences of a pattern in text, searching for specific sequences in DNA sequences, etc. This algorithm was designed by Knuth, Morris and Pratt and is an algorithm that can match strings in linear time. Other matching algorithms include brute force algorithm, Rabin-Karp algorithm, finite automaton algorithm (used for regular expressions, lexical analysis, etc.). Below we mainly introduce the KMP algorithm
the complexity
Set the length of the main string to n and the length of the pattern string to m.
Matching time complexity O(n)
auxiliary function calculation time complexity O(m)
auxiliary function space complexity O(m)
auxiliary function records the pattern string in the next array The prefix and suffix information avoids backtracking of the main string during the string matching process, thereby achieving a matching time complexity of O(n)
Detailed Algorithm
1. next array
The next array is the setting next*[i] = k for the pattern string P, which represents the maximum number of characters k with the same prefix and suffix in the substring of the pattern string P from subscript 0 to subscript i, where k < = i - 1.
The next array is shifted one position to the right relative to the next* array as a whole, and the first bit is supplemented by -1. This is mainly for convenience of use. The KMP algorithm can also be performed using the next* array.
Example:
| pattern string P | a | b | a | b | a | b | c | b |
|---|---|---|---|---|---|---|---|---|
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| next* | 0 | 0 | 1 | 2 | 3 | 4 | 0 | THAT |
| next | -1 | 0 | 0 | 1 | 2 | 3 | 4 | 0 |
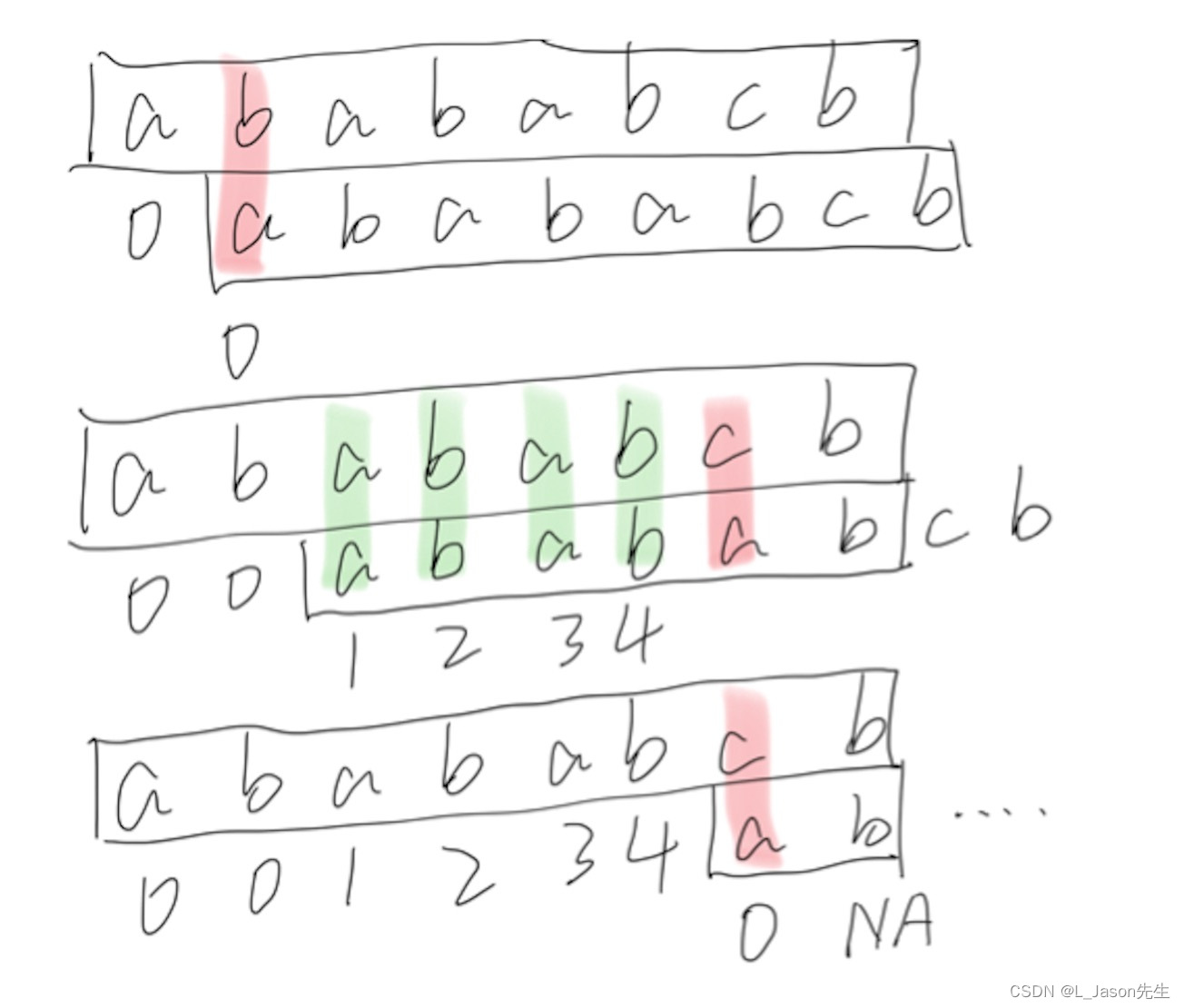
next*[0] = 0, the suffix and suffix are empty strings
next*[1] = 0, the suffix and suffix are different
next*[2] = 1, there is the longest identical suffix and suffix "a"
next*[3] = 2. The longest identical suffix "ab" exists
next*[4] = 3. The longest identical suffix "aba" exists
next*[5] = 4. The longest identical suffix "abab" exists
next*[6] = 0, neither the suffix nor the suffix are the same
next* array solution process
2. KMP algorithm
In the matching process

above, the main string will not be traced back. If a match fails, the pattern string matching position will be adjusted according to the next data. The position where the main string fails to match may be matched multiple times, but the overall complexity is not the same. It will not exceed O(n). There is an amortization analysis of the time complexity of the KMP algorithm in the introduction to the algorithm. If you are interested, you can take a look.
Implement code
1. Solve the next array code
void getNext(char * p, int * next) {
next[0] = -1;
int i = 0, j = -1;
while (i < (int)strlen(p)) {
if (j == -1 || p[i] == p[j]) {
++i;
++j;
next[i] = j;
} else {
j = next[j];
}
}
}
2. KMP matching
int kmp(char * t, char * p) {
int i = 0;
int j = 0;
while (i < (int)strlen(t) && j < (int)strlen(p)) {
if (j == -1 || t[i] == p[j]) {
i++;
j++;
} else {
j = next[j];
}
}
if (j == strlen(p))
return i - j;
else
return -1;
}