String matching is one of the fundamental tasks of computers.
For example, there is a string "BBC ABCDAB ABCDABCDABDE", I want to know, does it contain another string "ABCDABD"?

Many algorithms can accomplish this task, and the Knuth-Morris-Pratt algorithm (KMP for short) is one of the most commonly used. It is named after three inventors, the first K is the famous scientist Donald Knuth.

This algorithm is not easy to understand, there are many explanations online , but it is very laborious to read. I didn't really understand this algorithm until I read Jake Boxer 's article. Below, I use my own language to try to write an easy-to-understand explanation of the KMP algorithm.
1.

First, the first character of the string "BBC ABCDAB ABCDABCDABDE" is compared with the first character of the search term "ABCDABD". Because B does not match A, the search term is shifted back one place.
2.

Because B does not match A, the search term is moved further back.
3.

And so on until the string has one character that is the same as the first character of the search term.
4.

Then compare the string with the next character of the search term, again the same.
5.

Until the string has one character that is not identical to the character corresponding to the search term.
6.

At this time, the most natural reaction is to move the entire search term back one place, and then compare them one by one from the beginning. This works, but it's very inefficient, because you have to move the "search position" to the position that has already been compared, and repeat the comparison.
7.
A basic fact is that when the space doesn't match the D, you actually know that the first six characters are "ABCDAB". The idea of the KMP algorithm is to try to take advantage of this known information and not move the "search position" back to where it has already been compared, but keep moving it backwards, which improves efficiency.
8.
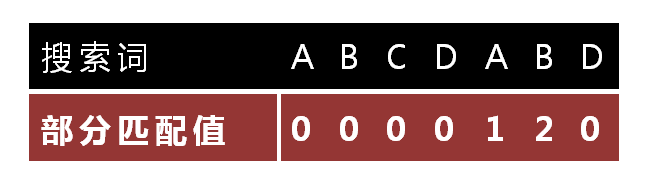
How to do this? A Partial Match Table can be calculated for the search term. How this table is generated will be introduced later, as long as you can use it here.
9.
The first six characters "ABCDAB" are matched when a space is known not to match D. Looking up the table, it can be seen that the "partial matching value" corresponding to the last matching character B is 2, so the number of digits shifted backward is calculated according to the following formula:
Number of shifts = number of characters matched - corresponding partial match value
Because 6 - 2 equals 4, move the search term back 4 places.
10.

Because the space does not match the C, the search term continues to move backwards. At this time, the number of matched characters is 2 ("AB"), and the corresponding "partial match value" is 0. So, shift bits = 2 - 0, the result is 2, so the search term is shifted back 2 bits.
11.
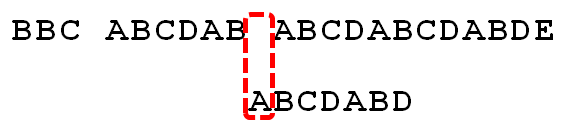
Since the space does not match the A, continue to move backward one bit.
12.

Compare bit by bit until C and D do not match. So, move the number of bits = 6 - 2, continue to move the search term backward by 4.
13.

Bit by bit comparison, until the last bit of the search term, an exact match is found, so the search is complete. If you want to continue the search (that is, find all matches), move the number of bits = 7 - 0, and then move the search term back 7 bits, and it will not be repeated here.
14.

The following describes how the Partial Match Table is generated.
First, there are two concepts to understand: "prefix" and "suffix". "Prefix" refers to all head combinations of a string except the last character; "suffix" refers to all tail combinations of a string except the first character.
15.
The "partial match value" is the length of the longest common element of "prefix" and "suffix". Take "ABCDABD" as an example,
- The prefix and suffix of "A" are empty sets, and the length of the common elements is 0;
- The prefix of "AB" is [A], the suffix is [B], and the length of the common elements is 0;
- The prefix of "ABC" is [A, AB], the suffix is [BC, C], and the length of common elements is 0;
- The prefix of "ABCD" is [A, AB, ABC], the suffix is [BCD, CD, D], and the length of the common elements is 0;
- The prefix of "ABCDA" is [A, AB, ABC, ABCD], the suffix is [BCDA, CDA, DA, A], the common element is "A", and the length is 1;
- The prefix of "ABCDAB" is [A, AB, ABC, ABCD, ABCDA], the suffix is [BCDAB, CDAB, DAB, AB, B], the common element is "AB", and the length is 2;
- The prefix of "ABCDABD" is [A, AB, ABC, ABCD, ABCDA, ABCDAB], the suffix is [BCDABD, CDABD, DABD, ABD, BD, D], and the length of the common elements is 0.
16.
The essence of "partial match" is that sometimes, there will be repetitions at the beginning and end of the string. For example, if there are two "AB" in "ABCDAB", then its "partial match value" is 2 (the length of "AB"). When the search word moves, the first "AB" moves backward by 4 bits (string length - partial matching value), and the second "AB" can be reached.
Reprinted from: Ruan Yifeng