Recently, I encountered a string matching algorithm on Likou. Although some solutions are simple, KMP string matching algorithm can be used to improve efficiency. The specific questions are as follows
Given two strings, A and B.
The rotation operation of A is to move the leftmost character of A to the rightmost. For example, if A ='abcde', the result will be'bcdea' after one move. If after several rotations, A can become B, then return True.
Example 1:
Input: A ='abcde', B ='cdeab'
Output: true
Example 2:
Input: A ='abcde', B ='abced'
Output: false
Note: The
length of A and B does not exceed 100.
Source: LeetCode
Link: https://leetcode-cn.com/problems/rotate-string
At the beginning, I used direct matching, but from the answers I saw that some people used the KMP algorithm, I will explain the KMP algorithm below.
Refer to the video explanation https://www.bilibili.com/video/BV1Px411z7Yo

As shown in the figure above, to find the subsequence matching the string P in the string T
If you match directly, you need to match one by one. When the fourth string b in p does not match a in T, p moves backward by one position and continues to match, which is very troublesome.

Especially in the following situations, the algorithm is the worst in this case.

The KMP algorithm first needs to list the prefixes of the strings to be matched, and then treat them as independent strings.

Then find out the longest prefix and the longest suffix of these strings respectively, as shown in the figure below.

It is found that the longest prefix and the longest suffix are different, and then the lengths of the prefix and suffix need to be subtracted by one bit respectively, and it is found that the prefix and suffix match at this time, and both are ab.

List their public largest prefixes and suffixes separately

Generally, when starting with zero, the last paragraph is not needed, so remove the last paragraph and add a -1 at the top.

List this column of numbers as prefix table numbers, and correspond to the string to be matched from front to back one by one


Then align the prefix table with the string to be matched, and mark the letter subscripts (letter subscripts start from 0). Next, we are ready to match
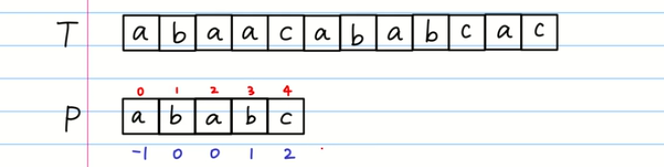
When the fourth character is not the same, the match fails. Observe that the number in the prefix table is 1.

Align the character at position 1 in the matching string with the character that just failed to match and the subscript is 1, as shown in the figure below

Then continue to match from the position where the string just failed to match, and it is found that it still does not match, and the subscript is 0 at this time

Continue the process just now, align the position 0 of the string to be matched with the position that just failed

At this time, the matching is successful, and then the matching is performed later, and the matching is found to be failed (c does not correspond to a). At this time, repeat the process just now and continue to find the prefix table subscript of the failed position. At this time, it is 0, and the 0th character is added. Align with it

At this time, a and c do not match. At this time, the prefix table is -1, and the -1 number of the string to be matched is aligned (the -1 number is not in the
In the string, but it can be represented by adding before), which is equivalent to one bit in parallel.


At this time, the -1 bit is blank, there is nothing, and then the next bit is matched

Then match one by one until the match is successful!

However, it should be noted that sometimes a string may contain multiple strings to be matched. At this time, the last character in the string to be matched will start to execute the algorithm with the corresponding character in the prefix table, as shown below Shown:

Until the match is complete, find all the matching strings!