First, the primer
1, data dependencies between the instructions to solve different problems.
Last lecture, I explained to you the structure of the data adventure and adventure, as well as two solutions to deal with these two adventure. One solution is to increase the resources by adding instruction and data caches, let us access to instructions and data can be carried out simultaneously.
This approach helps solve the CPU resource conflict between instruction fetch and data access. Another solution is direct to wait. By insertion of the NOP instruction is invalid such, before waiting for instructions to complete. So that we can resolve data dependencies between different instruction issue
2, the last lecture of these two programs both scenarios are a bit stupid.
Anxious people, watching a talk on these two scenarios, you may have to jump up and asked: "This can be considered the solution it?" Indeed, these two programs are a bit stupid.
The first solution, like in the software development process, the efficiency is not found, then head of research and development, said: " We need to double the manpower and R & D resources ." The second solution, like you mention needs when the person in charge of R & D tells you: "too late to do, you have to wait
. we demand schedule," you should know very well, "heap resources" and "such as schedule" such a solution and not really improve our efficiency, but avoid upset conflict.
That pipeline for adventure, we have no more advanced or more efficient solution? Neither so simple to spend money to add hardware "heap resources" , nor is it complete this task before the pure wait "and schedule" .
The answer of course is yes. This lesson, we will look at the principles of computer composition, a more sophisticated solution, before pushing operands
Two, NOP instruction alignment operation and
To understand the technology before pushing operands, let's take a look at, talk about the fifth off, R under the MIPS architecture, I, J three types of instruction, as well as Lecture 20 in the five-stage pipeline "instruction fetch (IF ) - instruction decode (ID) - instruction execution (EX) - memory access (MEM) - data write-back
(WB) ". I put to the corresponding picture, you can look at. If the impression is not deep, I suggest you go back to review the two sections, look at today's content
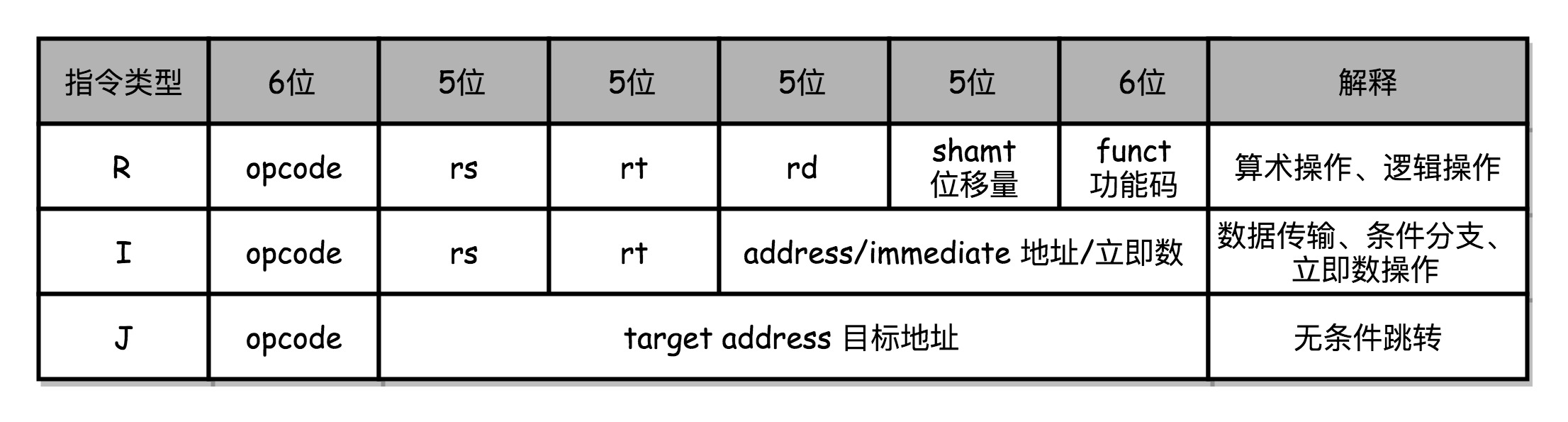
, Different types of instructions will perform different operations at different stages of the pipeline in the MIPS architecture.
We LOAD MIPS, so read data from memory to the instruction register, for example, take a closer look, it needs to go through five complete lines. STORE this to memory write command data from the register, there is no need to write back to the register operation,
that is, no data write-back pipeline stage. As for the addition and subtraction instructions such as ADD and SUB, all operations are completed in the register, there is no actual memory access (MEM) operation.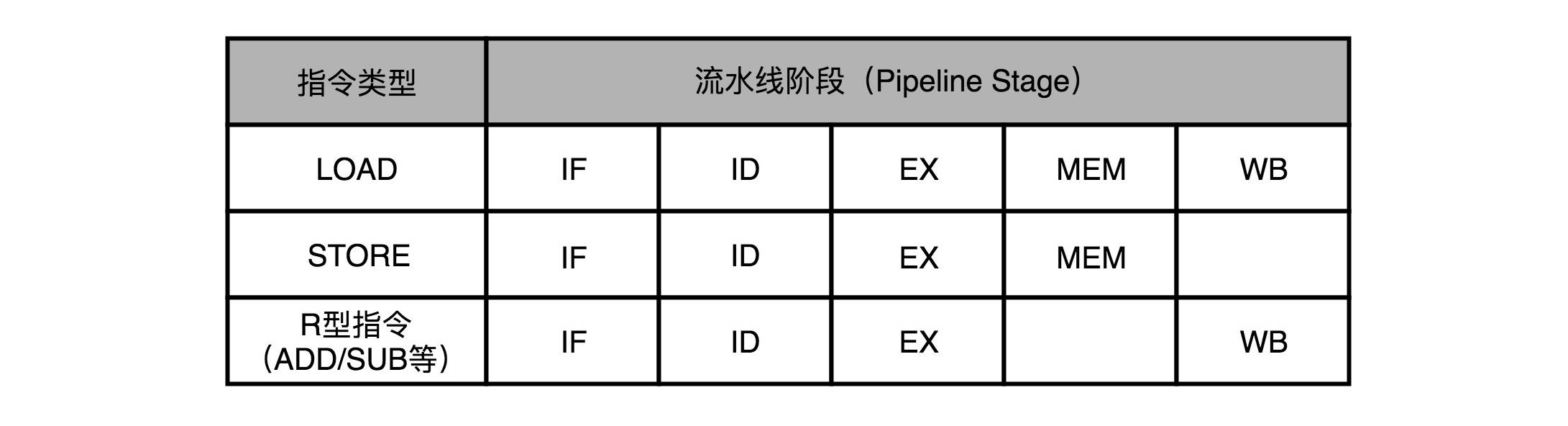
Some instructions have no corresponding pipeline stage, but we can not skip directly to the next stage of the corresponding phase. Otherwise, if we have to execute a LOAD instruction and an ADD instruction, it will happen WB stage WB stage and ADD instructions LOAD instruction,
occur in the same clock cycle. In this way, the equivalent of a structural hazards triggered event, resulting in a competition for resources.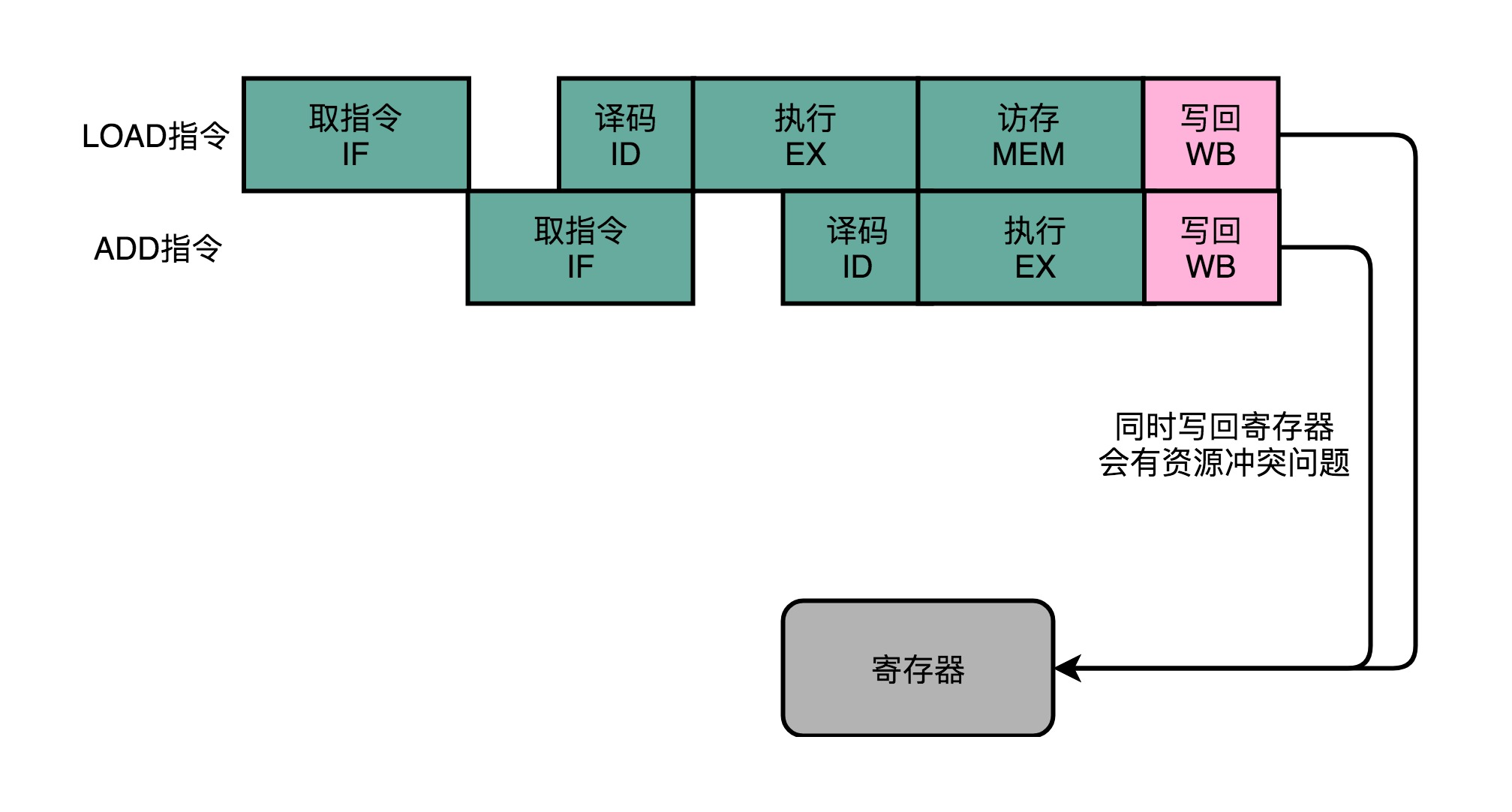
So, in practice, each instruction does not need a stage, and does not skip, but will run once a NOP operation. After inserting through a NOP operation, we can make an instruction of each Stage, and certainly not the same Stage previous instruction executed in one clock cycle.
In this way, has two instructions would not have happened in the same competition in the same clock cycle resources to produce the structural risk.
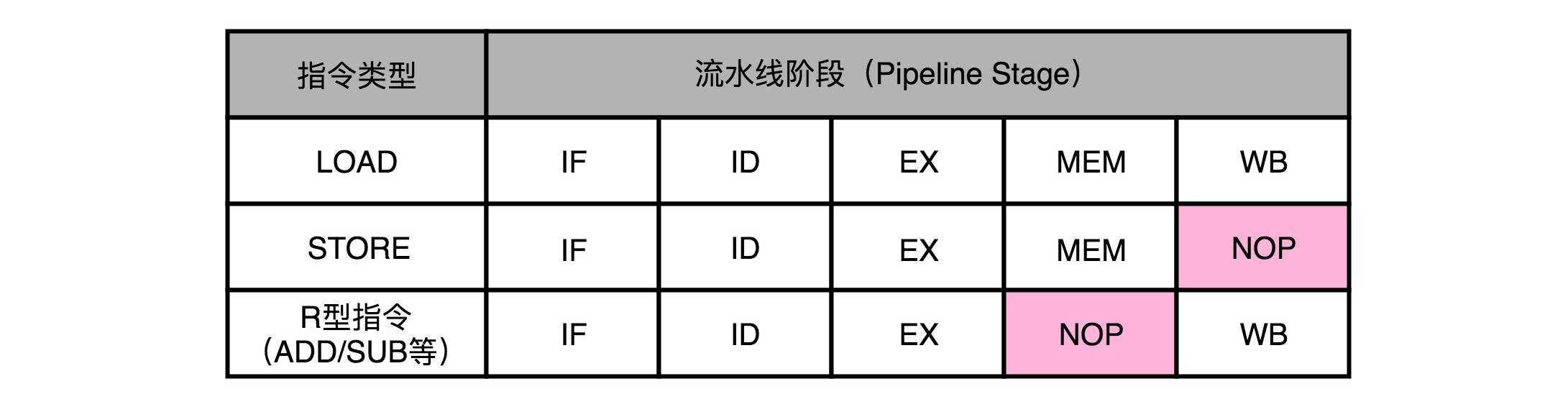
Third, the pipeline in the relay race: former operand push
Aligned by NOP operation, we are in the pipeline, the problem will not encounter structural hazards created a competition for resources. In addition to solve structural hazards, the NOP operation, we also talked about pipeline stalls before the insertion of the corresponding operations.
However, plugging in too many NOP operation, means that we are always in the CPU idle, dry food does not work. So, we have no way, as little as possible to insert some NOP does it work? Do not worry,
here we are with two ADD instruction has occurred as an example, see if you can find some good solutions.
add $t0, $s2,$s1 add $s2, $s1,$t0
These instructions are simple.
1. The first instruction, the register inside s1 and s2 of the data added to t0 is stored in the register inside.
2. The second instruction, the register inside t0 s1 and adding data, stored in the register inside the s2.
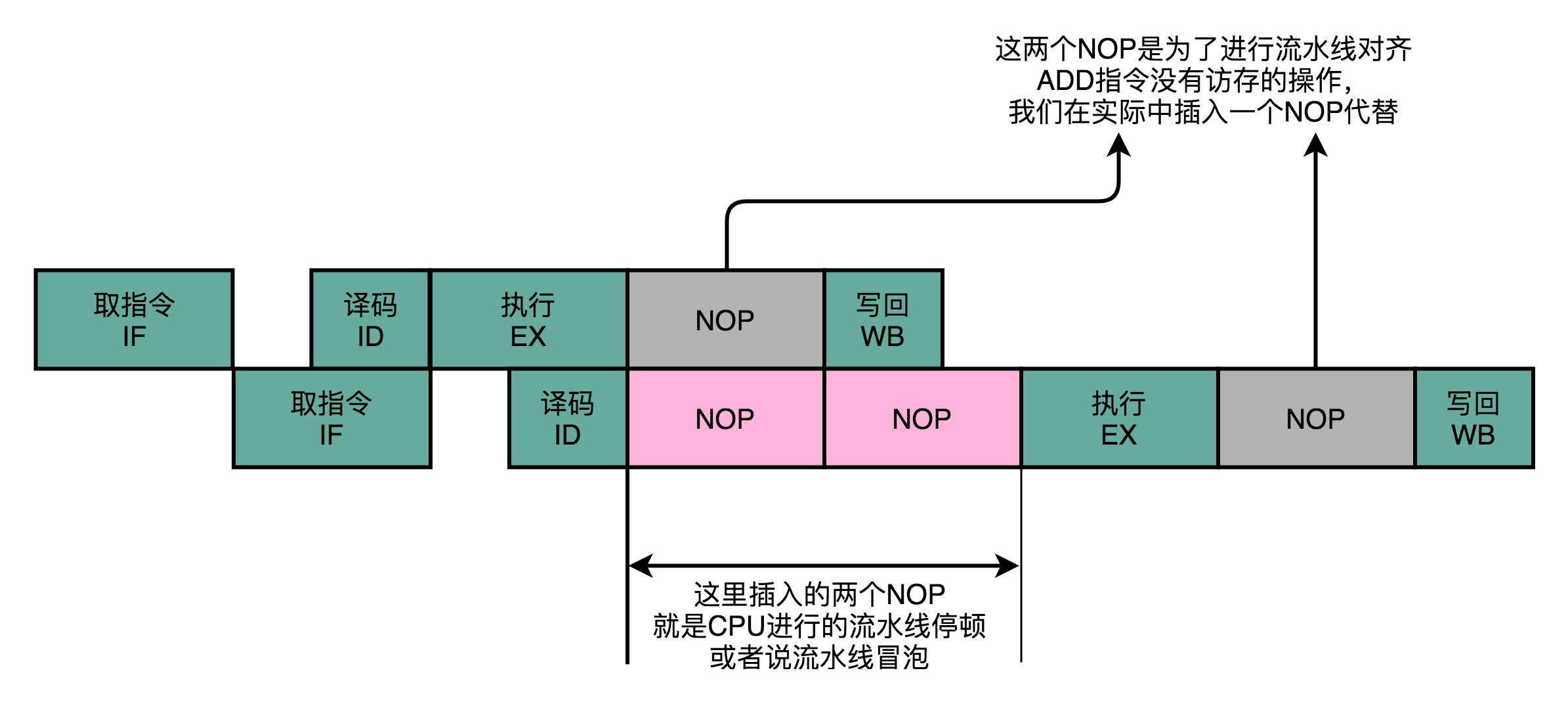
After an add instruction because, in dependence of the value of the register t0. Inside the value t0, and the calculation result from the previous instruction. So after an instruction, an instruction to wait before data is written back after the completion of stage to perform.
Like the last lecture I talked about it, we encountered a data-dependent type of adventure. So we have to take risks to solve this problem by pipeline stalls. We want to after the second instruction decode stage, insert the NOP instruction corresponding,
after the previous day instruction until the data is written back to complete in order to proceed. This program solves the problem of data adventure, but also wasted two clock cycles. Our second instruction, in fact, spent more than two clock cycles, a NOP operation twice running idle.
But, in fact, our second instruction execution, the first instruction may not have to wait for the completion of the write-back, can take place. If we first instruction execution result can be transmitted directly to the second instruction execution stage, as the input, then we second instruction,
will not have to register from the inside, once the data is then read out separately, come code execution.
We can after the first instruction execution phase is completed, the results directly to the next instruction data to the ALU. Then, the next instruction do not need to insert two NOP stage, you can go to continue normal execution stage.
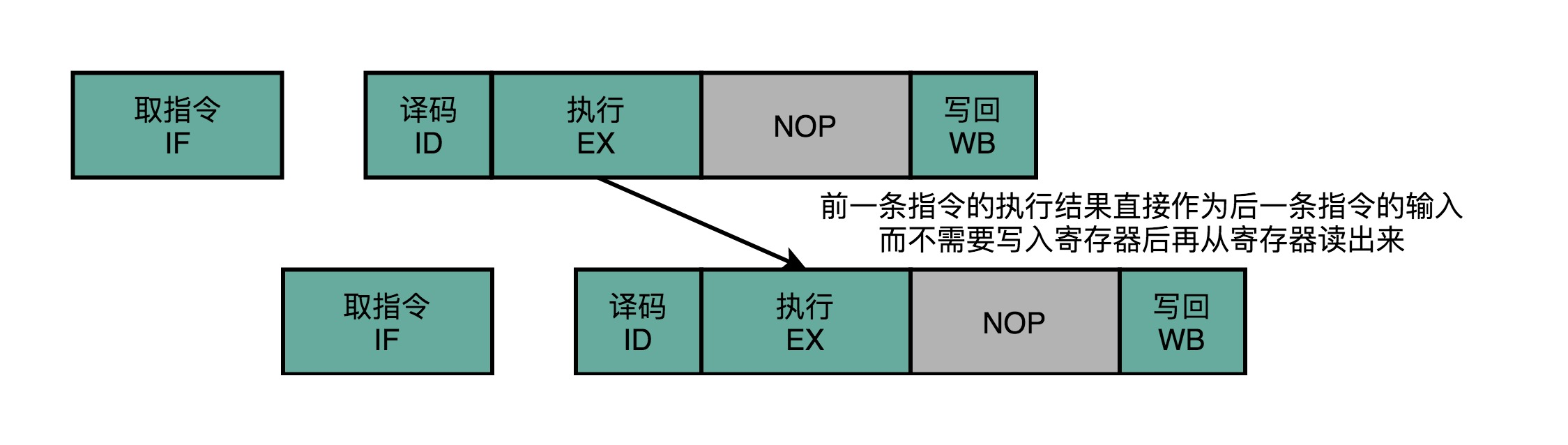
Such a solution, we are called operands push (Operand Forwarding) before, or the number of bypass operations (OperandBypassing). In fact, I think a more appropriate name should be called operand forwarding. Forward Here,
in fact, when we write Email "forward" (Forward) mean. However, existing classic textbook of Chinese translation is generally called "pushed forward", we could not begin to rectify this "Forward" (Forward) mean. However, existing classic textbook of Chinese translation is generally called "pushed forward", we could not begin to correct this statement, and do you understand that just fine.
Forwarding, in fact, is the technology of logical implication , that is, the results of the first instruction directly "forward" to the second ALU instruction as input. Another name, bypass (Bypassing), is the technology of hardware meanings . In order to enable herein, "forward",
we CPU hardware which is required to pull a signal transmission line separate out, such that the ALU, the ALU can be input back to the inside. Such a line is our "bypass." It crossed (Bypass) register write, the process is again read from the register, but also save us two clock cycles.
Operand before pushing only solutions may be used alone, and may also be used with a pipeline bubble. Sometimes, though we can forward to the next instruction operand, but still need to pause the next instruction is one clock cycle. For example, we go to execute a LOAD instruction, go to the ADD instruction execution. LOAD instruction fetch stage to read out the data, so the next instruction execution stage, it is necessary after memory access stage is completed, can take place.
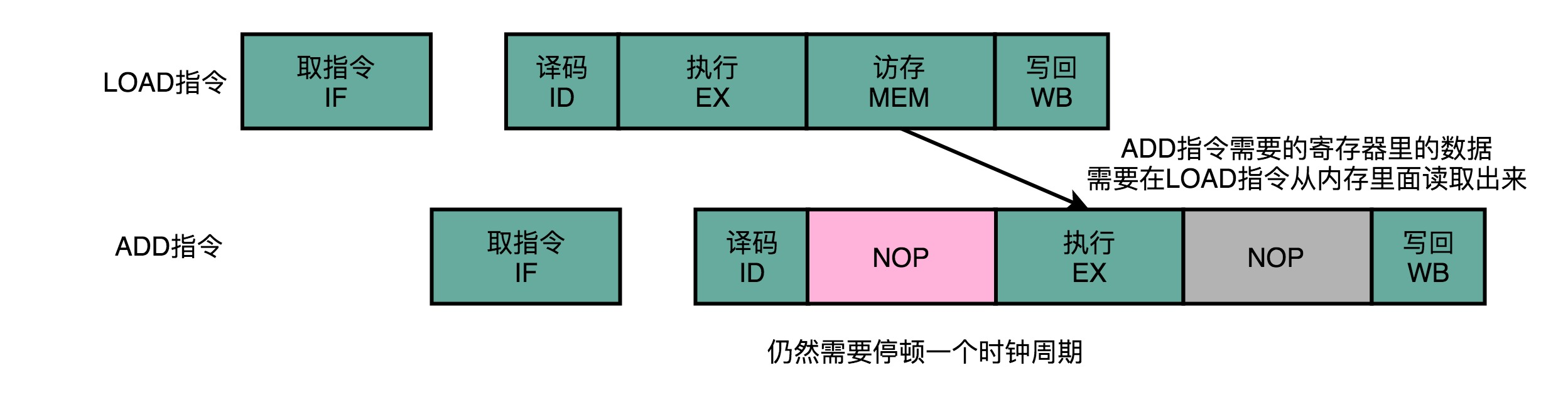
Overall, the number of operations pushed former solution than the pipeline stall goes a step further.
Pipeline stall the program, a bit like the way the relay swimming competition. An athlete after the next, we need to play the whole previous athlete to touch the pool wall before departure.
The number of operations pushed before, as if the sprint relay. After a player can grab ahead run, and run before an athlete will be more active period of the transfer bar to pass to him.
IV Summary extension
This lecture, I introduce you to a more advanced, and more complex problem to solve data adventure program, that is, before the operand push, or call the number of bypass operations.
Front push operands, a bypass is manufactured by the hardware level, so that the results of a calculation instruction, the next instruction may be transmitted directly, without the need for "write-back instruction register 1, the instruction register 2 then reads" This unnecessary operation.
The benefits of such transmission is direct, subsequent instructions can reduce or even eliminate the need to pass the original pipeline stalls, in order to solve the problem of data adventure.
Pushing the former solution, not only can be used alone, and may also be explained through the foregoing pipeline bubble combination. Because sometimes, before we push operand does not reduce all the "bubble" can only remove part of it.
We still need to insert some "bubble" to solve the problem of adventure.
By pushing the front operands, we further enhance the operational efficiency of the CPU. So, we are not'll find other ways to further reduce waste it? After all, see now, we still have a lot of NOP and ultimately, to insert the "bubble."
Then you continue to adhere to learn it. Next time, we take a look, CPU is how order execution through to further reduce the "bubble" of.